




 本文深入探讨了Apache Spark的四大核心特点:高速运行能力、简易编程接口、广泛的兼容性和跨平台部署灵活性。同时,详细介绍了Spark的主要模块,包括Spark Core、Spark SQL、Spark Streaming和Spark ML,为读者提供了一个全面的Spark技术概览。
本文深入探讨了Apache Spark的四大核心特点:高速运行能力、简易编程接口、广泛的兼容性和跨平台部署灵活性。同时,详细介绍了Spark的主要模块,包括Spark Core、Spark SQL、Spark Streaming和Spark ML,为读者提供了一个全面的Spark技术概览。
1.Spark的主要特点
1.1 速度快
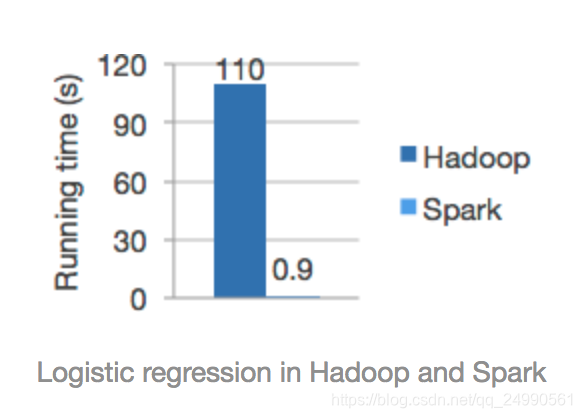
Spark 使用DAG 调度器、查询优化器和物理执行引擎,能够在批处理和流数据获得很高的性能。根据官方的统计,它的运算速度是hadoop的100x倍,应该是有一定的条件吧!
1.2 使用简单
Spark的易用性主要体现在两个方面。一方面,我们可以用较多的编程语言来写我们的应用程序,比如说Java,Scala,Python,R 和 SQL;另一方面,Spark 为我们提供了超过80个高阶操作,这使得我们十分容易地创建并行应用,除此之外,我们也可以使用Scala,Python,R和SQL shells,以实现对Spark的交互。
df = spark.read.json("logs.json") df.where("age > 21") .select("name.first").show()
**Spark's Python DataFrame API
Read JSON files with automatic schema inference**
1.3 通用性强
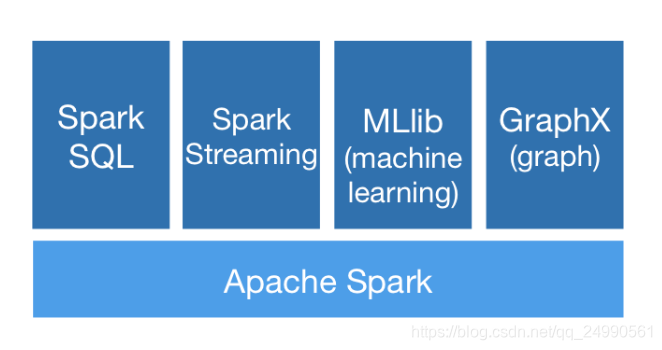
与其说通用性高,还不如说它集成度高,如图所示:以Spark为基础建立起来的模块(库)有Spark SQL,Spark Streaming,MLlib(machine learning)和GraphX(graph)。我们可以很容易地在同一个应用中将这些库结合起来使用,以满足我们的实际需求。
1.4 到处运行
Spark应用程度可以运行十分多的框架之上。它可以运行在Hadoop,Mesos,Kubernetes,standalone,或者云服务器上。它有多种多种访问源数据的方式。可以用standalone cluster模式来运行Spark应用程序,并且其应用程序跑在Hadoop,EC2,YARN,Mesos,或者Kubernates。对于访问的数据源,我们可以通过使用Spark访问HDFS,Alluxio,Apache Cassandra,HBase,Hive等多种数据源。

2.Spark主要包含的模块
2.1 Spark Core
2.2 Spark SQL
2.3 Spark Streaming
2.4 Spark ML

















 1684
1684





 到【灌水乐园】发言
到【灌水乐园】发言







