






2019年,Houlsby N等人将Adapter引入NLP领域,作为全模型微调的一种替代方案。Adapter主体架构下图所示。
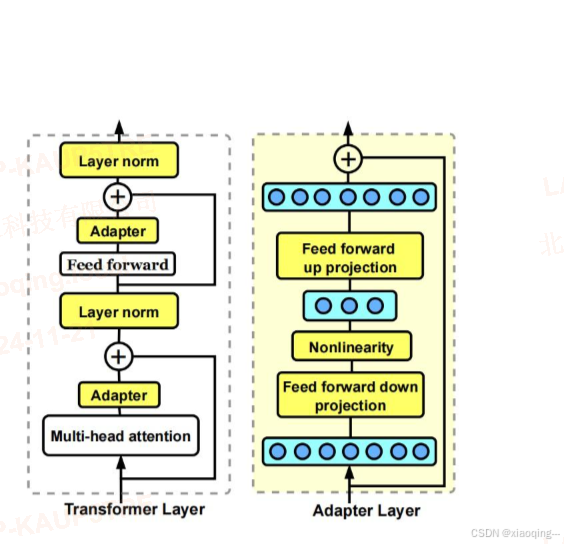
在预训练模型每一层(或某些层)中添加Adapter模块(如上图左侧结构所示),微调时冻结预训练模型主体,由Adapter模块学习特定下游任务的知识。每个Adapter模块由两个前馈子层组成,第一个前馈子层将Transformer块的输出作为输入,将原始输入维度d投影到m,通过控制m的大小来限制Adapter模块的参数量,通常情况下m<<d。在输出阶段,通过第二个前馈子层还原输入维度,将m重新投影到d,作为Adapter模块的输出(如上图右侧结构)。通过添加Adapter模块来产生一个易于扩展的下游模型,每当出现新的下游任务,通过添加Adapter模块来避免全模型微调与灾难性遗忘的问题。Adapter方法不需要微调预训练模型的全部参数,通过引入少量针对特定任务的参数,来存储有关该任务的知识,降低对模型微调的算力要求。
结构与工作原理
-
结构:
-
下采样层:将输入特征向量从高维(d)投影到低维(r),r << d。这一步骤减少了参数量。
-
非线性变换层:通常是一个ReLU激活函数,用于引入非线性。
-
上采样层:将低维特征向量(r)重新映射回高维(d),以匹配原始模型的输出维度。
-
跳过连接:将输入特征直接加到最终输出上,以保持模型的初始行为。
-
-
工作流程:
-
在每个Transformer层中,Adapter模块被插入到多头注意力机制之后和前馈网络之后。 在微调过程中,只训练Adapter模块的参数,而原始模型的参数保持不变
-
适配器模块的插入:
from transformers import BertModel
from adapters import AdapterConfig, BertAdapterModel
# 加载预训练的BERT模型
model = BertModel.from_pretrained("bert-base-uncased")
# 定义Adapter配置
adapter_config = AdapterConfig(mh_adapter=True, output_adapter=True, reduction_factor=16, non_linearity="relu")
# 将模型转换为支持Adapter的模型
model = BertAdapterModel(model)
# 添加一个名为"task_adapter"的Adapter
model.add_adapter("task_adapter", config=adapter_config)
# 激活Adapter进行训练
model.train_adapter("task_adapter")训练:
from transformers import TrainingArguments, Trainer
# 定义训练参数
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=64,
warmup_steps=500,
weight_decay=0.01,
logging_dir="./logs",
)
# 创建Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
)
# 开始训练
trainer.train()Adapter算法改进
2020年,Pfeiffer J等人对Adapter进行改进,「提出AdapterFusion算法,用以实现多个Adapter模块间的最大化任务迁移」(其模型结构如下图所示)。
AdapterFusion将学习过程分为两个阶段:
● 1.「知识提取阶段」:训练Adapter模块学习下游任务的特定知识,将知识封装在Adapter模块参数中。
● 2.「知识组合阶段」:将预训练模型参数与特定于任务的Adapter参数固定,引入新参数学习组合多个Adapter中的知识,提高模型在目标任务中的表现。
作者通过将适配器的训练分为知识提取和知识组合两部分,解决了灾难性遗忘、任务间干扰和训练不稳定的问题。Adapter模块的添加也导致模型整体参数量的增加,降低了模型推理时的性能
实现细节
1. 定义和插入Adapter模块:
from transformers import BertModel
from adapters import AdapterConfig, BertAdapterModel
# 加载预训练的BERT模型
model = BertModel.from_pretrained("bert-base-uncased")
# 定义Adapter配置
adapter_config = AdapterConfig(mh_adapter=True, output_adapter=True, reduction_factor=16, non_linearity="relu")
# 将模型转换为支持Adapter的模型
model = BertAdapterModel(model)
# 添加多个任务的Adapter模块
tasks = ["task1", "task2", "task3"]
for task in tasks:
model.add_adapter(task, config=adapter_config)2. 定义融合机制:
from adapters import AdapterFusionConfig
# 定义AdapterFusion配置
fusion_config = AdapterFusionConfig()
# 添加AdapterFusion模块
model.add_fusion(tasks, config=fusion_config)3.激活Adapter和融合机制进行训练:
model.train_adapter_fusion(tasks)4.训练:
from transformers import TrainingArguments, Trainer
# 定义训练参数
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=64,
warmup_steps=500,
weight_decay=0.01,
logging_dir="./logs",
)
# 创建Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
)
# 开始训练
trainer.train()
















 4281
4281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









