







 本文介绍了如何在PyTorch中使用计算图求梯度,包括误差反向传播算法的应用,grad_fn的概念,以及如何控制梯度跟踪。通过实例演示了如何计算神经网络中权重和偏置的梯度,并提到了禁用梯度跟踪的两种方法及其应用场景。
本文介绍了如何在PyTorch中使用计算图求梯度,包括误差反向传播算法的应用,grad_fn的概念,以及如何控制梯度跟踪。通过实例演示了如何计算神经网络中权重和偏置的梯度,并提到了禁用梯度跟踪的两种方法及其应用场景。
主要内容:
在计算图中求梯度的一些概念。总代码放在文末。
PS:在看这篇文章之前,请大家先去了解一下误差逆传播算法,自己动手推导一下。
可以直接看这篇文章:神经网络后向传播计算过程
训练神经网络时,最常用的是误差反向传播算法,模型参数就是根据损失函数对给定参数的梯度来进行调整的。为了计算梯度,就出现了torch.autograd,它支持对任何计算图进行梯度计算。
举例说明:
import torch
# 一个单层的神经网络例子
x = torch.ones(5) # input tensor
y = torch.zeros(3) # expected output
# require_grad=True表明这个向量需要计算梯度
w = torch.randn(5, 3, requires_grad=True)
b = torch.randn(3, requires_grad=True)
z = torch.matmul(x, w)+b # torch.matmul矩阵相乘
# 用于计算二元交叉熵损失的函数 z是预测值,y是真实值
loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)图中代码实际定义了如下计算图:
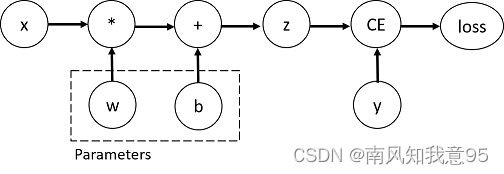
确定w和b则需要求出loss对于w和b的梯度,因而在代码中需要将require_grad设置为True。
那么如何计算梯度呢?调用 loss.backward(),然后从 w.grad 和 b.grad 中获取数值
loss.backward() # 向后传播
# 得到计算好的梯度
print(w.grad)
print(b.grad)介绍一下grad_fn,讯飞星火认知大模型给出的答案
grad_fn 是 PyTorch 中的一个属性,用于表示计算图中的梯度函数。在 PyTorch 中,当我们对一个张量进行操作时,PyTorch 会自动构建一个计算图来记录这些操作。每个节点(张量)都有一个与之关联的 grad_fn 对象,它包含了关于该节点的操作信息。通过访问 grad_fn,我们可以查看计算图中的操作序列以及梯度计算的过程。
print('Gradient function for z =', z.grad_fn)
print('Gradient function for loss =', loss.grad_fn)禁止梯度跟踪
默认情况下,所有带有require_grad=True的tensor都在跟踪它们的计算历史并支持梯度计算。然而,在某些情况下,我们不需要这样做,例如,我们只想通过网络进行前向计算。我们可以通过用torch.no_grad()块包围我们的计算代码来停止跟踪计算,或者在tensor上使用detach()方法
# 法一:
z = torch.matmul(x, w)+b
print(z.requires_grad) # True
with torch.no_grad():
z = torch.matmul(x, w)+b
print(z.requires_grad) # Flase
# 法二:
z = torch.matmul(x, w)+b
z_det = z.detach()
print(z_det.requires_grad) # Flase官网上给出的禁用梯度跟踪的原因:
- 将神经网络中的一些参数标记为冻结参数。这是对预训练的网络进行微调的一个非常常见的情况。
- 当你只做前向传递时,为了加快计算速度,对不跟踪梯度的tensor的计算会更有效率。
总代码:
import torch # 一个单层的神经网络例子 x = torch.ones(5) # input tensor y = torch.zeros(3) # expected output w = torch.randn(5, 3, requires_grad=True) # require_grad=True表明这个向量需要计算梯度 b = torch.randn(3, requires_grad=True) z = torch.matmul(x, w)+b # torch.matmul矩阵相乘 # 用于计算二元交叉熵损失的函数 z是预测值,y是真实值 loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y) print('Gradient function for z =', z.grad_fn) print('Gradient function for loss =', loss.grad_fn) loss.backward() # 向后传播 # 得到计算好的梯度 print(w.grad) print(b.grad)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











