







所有步骤按顺序执行即可
环境配置
本机环境是Python=3.11.4 | CUDA=12.2 | torch=2.1.0
先下载代码,创建环境llm4poi(python==3.11.4)。还需要下载数据集,解压后得先在根目录建个文件夹data,具体结构见预处理后示意图,不过此时应该各个数据集都没有Preprocess文件夹,不用慌。
仓库里少个库文件,需要自己下载完放根目录。
pip install 'numpy<2'
pip install pandas
pip install shapely
python -m pip install torch-sparse -f https://pytorch-geometric.com/whl/torch-2.1.0+cu121.html
python -m pip install torch-scatter -f https://pytorch-geometric.com/whl/torch-2.1.0+cu121.html
python -m pip install torch-cluster -f https://pytorch-geometric.com/whl/torch-2.1.0+cu121.html
python -m pip install torch-spline-conv -f https://pytorch-geometric.com/whl/torch-2.1.0+cu121.html
python -m pip install torch-geometric
pip install pyyaml
pip install tensorboard
pip install einops
--- 安装flash-attn出错
# 需要更新torch版本,原本torch是2.0.1,但是flash-atten库必须torch≥2.1,这里选择的是2.1.0
# 使用源码安装,https://github.com/Dao-AILab/flash-attention/releases找到对应版本下载whl文件
# 源码安装,如果下载太慢可以先下到本地直接安装
pip install https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.2.post1/flash_attn-2.7.2.post1+cu11torch2.1cxx11abiFALSE-cp311-cp311-linux_x86_64.whl
pip install tiktoken
pip install blobfile
pip install sentencepiece
pip install bitsandbytes
模型下载
鸣谢大哥提供的jio本,从HF镜像下载模型:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com" # 设置为hf的国内镜像网站
from huggingface_hub import snapshot_download
model_name = "Yukang/Llama-2-7b-longlora-32k-ft"
model_path = os.path.join(os.getcwd(), model_name)
print(model_path)
# while True 是为了防止断联
while True:
try:
snapshot_download(
repo_id=model_name,
local_dir_use_symlinks=False, # 在local-dir指定的目录中都是一些“链接文件”
cache_dir=model_path,
token="", # huggingface的token
resume_download=True
)
break
except:
pass
代码调整
LLM4POI-main/preprocessing/utils/pipeline_util.py
将开始的包头注释掉,并添加函数实现:
# from metric import (
# recall,
# ndcg,
# map_k,
# mrr
# )
def recall(label, pred, k):
"""
计算召回率 @ k
:param label: 真实标签,形状 (batch_size, n)
:param pred: 排名预测,形状 (batch_size, n)
:param k: 推荐数量
:return: 召回率
"""
batch_size = label.size(0)
recall_score = 0.0
for i in range(batch_size):
relevant_items = label[i] # 真实的 POI
recommended_items = pred[i, :k] # 前 k 个推荐
# 计算召回,找到推荐的 POI 中有多少是相关的
recall_score += torch.sum(torch.isin(recommended_items, relevant_items)).float()
return recall_score / batch_size
def ndcg(label, pred, k):
"""
计算 NDCG@k
:param label: 真实标签,形状 (batch_size, n)
:param pred: 排名预测,形状 (batch_size, n)
:param k: 推荐数量
:return: NDCG@k
"""
batch_size = label.size(0)
ndcg_score = 0.0
for i in range(batch_size):
relevant_items = label[i] # 真实的 POI
recommended_items = pred[i, :k] # 前 k 个推荐
# 计算 Discounted Cumulative Gain (DCG)
dcg = 0.0
for j, item in enumerate(recommended_items):
if item in relevant_items:
dcg += 1 / torch.log2(torch.tensor(j + 2.0)) # +2 to avoid log(0)
# 计算 Ideal DCG (IDCG),理想情况下,相关项排在前面
ideal_dcg = 0.0
for j in range(k):
if relevant_items[j] in recommended_items:
ideal_dcg += 1 / torch.log2(torch.tensor(j + 2.0))
# 计算 NDCG
ndcg_score += dcg / (ideal_dcg + 1e-8) # 防止除以零
return ndcg_score / batch_size
def map_k(label, pred, k):
"""
计算 MAP@k
:param label: 真实标签,形状 (batch_size, n)
:param pred: 排名预测,形状 (batch_size, n)
:param k: 推荐数量
:return: MAP@k
"""
batch_size = label.size(0)
map_score = 0.0
for i in range(batch_size):
relevant_items = label[i] # 真实的 POI
recommended_items = pred[i, :k] # 前 k 个推荐
# 计算平均精度
avg_precision = 0.0
hits = 0
for j, item in enumerate(recommended_items):
if item in relevant_items:
hits += 1
avg_precision += hits / (j + 1)
if hits > 0:
avg_precision /= hits
map_score += avg_precision
return map_score / batch_size
def mrr(label, pred):
"""
计算 MRR
:param label: 真实标签,形状 (batch_size, n)
:param pred: 排名预测,形状 (batch_size, n)
:return: MRR
"""
batch_size = label.size(0)
mrr_score = 0.0
for i in range(batch_size):
relevant_items = label[i] # 真实的 POI
recommended_items = pred[i] # 排名预测
# 计算第一个相关项的排名
for j, item in enumerate(recommended_items):
if item in relevant_items:
mrr_score += 1 / (j + 1)
break
return mrr_score / batch_size
LLM4POI-main/preprocessing/utils/sys_util.py
获取目录函数get_root_dir():更改如下:
def get_root_dir():
dirname = os.getcwd()
dirname_split = dirname.split("/")
# index = dirname_split.index("preprocessing")
dirname_split.append('preprocessing')
# dirname = "/".join(dirname_split[:index + 1])
return dirname
LLM4POI-main/preprocessing/preprocess/preprocess_main.py
修改预处理函数preprocess():更改如下:
def preprocess(cfg: Cfg):
root_path = os.path.dirname(get_root_dir())
dataset_name = cfg.dataset_args.dataset_name
data_path = osp.join(root_path, 'data', dataset_name)
preprocessed_path = osp.join(data_path, 'preprocessed')
sample_file = osp.join(preprocessed_path, 'sample.csv')
train_file = osp.join(preprocessed_path, 'train_sample.csv')
validate_file = osp.join(preprocessed_path, 'validate_sample_with_traj.csv')
test_file = osp.join(preprocessed_path, 'test_sample_with_traj.csv')
keep_cols = [
'check_ins_id', 'UTCTimeOffset', 'UTCTimeOffsetEpoch', 'pseudo_session_trajectory_id',
'UserId', 'Latitude', 'Longitude', 'PoiId', 'PoiCategoryId',
'PoiCategoryName'
]
if not osp.exists(preprocessed_path):
os.makedirs(preprocessed_path)
# Step 1. preprocess raw files and create sample files including
# 1. data transformation; 2. id encoding; 3.train/validate/test splitting; 4. remove unseen user or poi
# if not osp.exists(sample_file):
if 'nyc' == dataset_name:
keep_cols += ['trajectory_id']
preprocessed_data = preprocess_nyc(data_path, preprocessed_path)
elif 'tky' == dataset_name or 'ca' == dataset_name:
preprocessed_data = preprocess_tky_ca(cfg, data_path)
else:
raise ValueError(f'Wrong dataset name: {dataset_name} ')
preprocessed_result = remove_unseen_user_poi(preprocessed_data)
preprocessed_result['sample'].to_csv(sample_file, index=False)
preprocessed_result['train_sample'][keep_cols].to_csv(train_file, index=False)
preprocessed_result['validate_sample'][keep_cols].to_csv(validate_file, index=False)
preprocessed_result['test_sample'][keep_cols].to_csv(test_file, index=False)
# Step 2. generate hypergraph related data
# if not osp.exists(osp.join(preprocessed_path, 'ci2traj_pyg_data.pt')):
# generate_hypergraph_from_file(sample_file, preprocessed_path, cfg.dataset_args)
logging.info('[Preprocess] Done preprocessing.')
修改函数preprocess_nyc():更改如下:
def preprocess_nyc(raw_path: bytes, preprocessed_path: bytes) -> pd.DataFrame:
df_train = pd.read_csv(osp.join(raw_path, 'NYC_train.csv'))
df_val = pd.read_csv(osp.join(raw_path, 'NYC_val.csv'))
df_test = pd.read_csv(osp.join(raw_path, 'NYC_test.csv'))
df_train['SplitTag'] = 'train'
df_val['SplitTag'] = 'validation'
df_test['SplitTag'] = 'test'
df = pd.concat([df_train, df_val, df_test])
df.columns = [
'UserId', 'PoiId', 'PoiCategoryId', 'PoiCategoryCode', 'PoiCategoryName', 'Latitude', 'Longitude',
'TimezoneOffset', 'UTCTime', 'UTCTimeOffset', 'UTCTimeOffsetWeekday', 'UTCTimeOffsetNormInDayTime',
'pseudo_session_trajectory_id', 'UTCTimeOffsetNormDayShift', 'UTCTimeOffsetNormRelativeTime', 'SplitTag'
]
# data transformation
df['trajectory_id'] = df['pseudo_session_trajectory_id']
df['UTCTimeOffset'] = df['UTCTimeOffset'].apply(lambda x: datetime.strptime(x[:19], "%Y-%m-%d %H:%M:%S"))
df['UTCTimeOffsetEpoch'] = df['UTCTimeOffset'].apply(lambda x: x.strftime('%s'))
df['UTCTimeOffsetWeekday'] = df['UTCTimeOffset'].apply(lambda x: x.weekday())
df['UTCTimeOffsetHour'] = df['UTCTimeOffset'].apply(lambda x: x.hour)
df['UTCTimeOffsetDay'] = df['UTCTimeOffset'].apply(lambda x: x.strftime('%Y-%m-%d'))
df['UserRank'] = df.groupby('UserId')['UTCTimeOffset'].rank(method='first')
df = df.sort_values(by=['UserId', 'UTCTimeOffset'], ascending=True)
# id encoding
df['check_ins_id'] = df['UTCTimeOffset'].rank(ascending=True, method='first') - 1
traj_id_le, padding_traj_id = id_encode(df, df, 'pseudo_session_trajectory_id')
df_train = df[df['SplitTag'] == 'train']
poi_id_le, padding_poi_id = id_encode(df_train, df, 'PoiId')
poi_category_le, padding_poi_category = id_encode(df_train, df, 'PoiCategoryId')
user_id_le, padding_user_id = id_encode(df_train, df, 'UserId')
hour_id_le, padding_hour_id = id_encode(df_train, df, 'UTCTimeOffsetHour')
weekday_id_le, padding_weekday_id = id_encode(df_train, df, 'UTCTimeOffsetWeekday')
# save mapping logic
with open(osp.join(preprocessed_path, 'label_encoding.pkl'), 'wb') as f:
pickle.dump([
poi_id_le, poi_category_le, user_id_le, hour_id_le, weekday_id_le,
padding_poi_id, padding_poi_category, padding_user_id, padding_hour_id, padding_weekday_id
], f)
# ignore the first for train/validate/test and keep the last for validata/test
df = ignore_first(df)
# df = only_keep_last(df)
return df
LLM4POI-main/data/nyc/preprocessedtraj_qk.py
更改main函数,更改如下:
def main():
# Create the argument parser
parser = argparse.ArgumentParser(description="Process dataset names.")
# Add an argument for the dataset name
parser.add_argument("-dataset_name", type=str, choices=['ca', 'nyc', 'tky'],
help="Name of the dataset (e.g., ca, nyc, tky)")
# Parse the arguments
args = parser.parse_args()
# Your processing code here
print(f"Processing dataset: {args.dataset_name}")
path = f'data/{args.dataset_name}/preprocessed/'
# Read the data
train_data = pd.read_csv(f'{path}train_sample.csv')
test_data = pd.read_csv(f'{path}test_sample_with_traj.csv')
train_data['PoiCategoryName'] = train_data['PoiCategoryName'].apply(simplify_poi_category)
# Save the modified DataFrame to a new CSV file
train_data.to_csv(f'{path}train_sample.csv', index=False)
test_data['PoiCategoryName'] = test_data['PoiCategoryName'].apply(simplify_poi_category)
# Save the modified DataFrame to a new CSV file
test_data.to_csv(f'{path}test_sample.csv', index=False)
# Generate the QA pairs
kq_pairs_train = generate_kq_pairs(train_data)
kq_pairs_test = generate_kq_pairs(test_data)
# Save the train QA pairs in JSON format
qa_dict_train = [{"key": q, "query": a, "traj_id": t, 'start_time':s, 'end_time':e} for q, a, t, s, e in kq_pairs_train]
print(len(qa_dict_train))
with open(f'{path}train_kq_pairs.json', 'w') as json_file:
json.dump(qa_dict_train, json_file)
qa_dict_test = [{"key": q, "query": a, "traj_id": t, 'start_time':s, 'end_time':e} for q, a, t, s, e in kq_pairs_test]
print(len(qa_dict_test))
with open(f'{path}test_kq_pairs.json', 'w') as json_file:
json.dump(qa_dict_test, json_file)
LLM4POI-main/data/nyc/preprocessed/traj_sim.py
这个需要自己改一下模型路径,以及model的调用代码(上面注释掉的是源代码,下面是更新后的代码):
################## 改 模型路径###################
# model_path = '/g/data/hn98/models/llama2/llama-2-7b-longlora-32k-ft/'
model_path = 'LLM4POI-main/Yukang/Llama-2-7b-longlora-32k-ft/models--Yukang--Llama-2-7b-longlora-32k-ft/snapshots/ab48674ffc55568ffe2a1207ef0e711c2febbaaf'
################## 改 模型调用###################
# Load model and tokenizer
# model = transformers.AutoModelForCausalLM.from_pretrained(
# model_path,
# device_map='auto',
# config=config,
# cache_dir=None,
# torch_dtype=torch.bfloat16,
# quantization_config=BitsAndBytesConfig(
# load_in_4bit=True,
# llm_int8_threshold=6.0,
# llm_int8_has_fp16_weight=False,
# bnb_4bit_compute_dtype=torch.bfloat16,
# bnb_4bit_use_double_quant=True,
# bnb_4bit_quant_type="nf4",
# ),
# )
model = transformers.AutoModelForCausalLM.from_pretrained(
model_path,
device_map='auto',
config=config,
cache_dir=None,
torch_dtype=torch.float16, # You can use float16 here or bfloat16
)
/home/yby/LLM4POI-main/llama_attn_replace.py【选改,如果要禁用flash_attn则改】
全局搜use_flash_attn=True,替换为use_flash_attn=False
预处理操作
执行代码:
python preprocessing/generate_ca_raw.py --dataset_name nyc
python preprocessing/generate_ca_raw.py --dataset_name ca
python preprocessing/generate_ca_raw.py --dataset_name tky
cd preprocessing/
python run.py -f best_conf/nyc.yml
python run.py -f best_conf/ca.yml
python run.py -f best_conf/tky.yml
python traj_qk.py -dataset_name nyc
python traj_qk.py -dataset_name ca
python traj_qk.py -dataset_name tky
cd ..
python traj_sim.py --dataset_name nyc
python traj_sim.py --dataset_name ca
python traj_sim.py --dataset_name tky
预处理之后,文件结构如图所示,每个数据集都多了一个preprocessed文件夹:
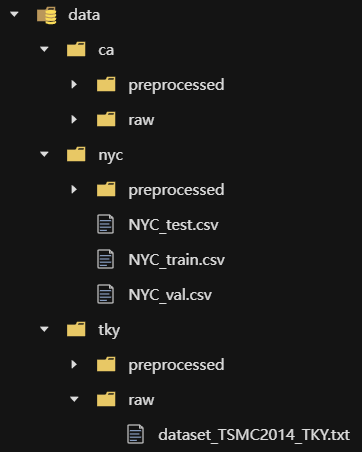
但是在运行python traj_sim.py --dataset_name nyc的时候,报错如下An error occurred: handle_0 INTERNAL ASSERT FAILED at "../c10/cuda/driver_api.cpp":15, please report a bug to PyTorch. 。可能是因为显存爆了。
运行代码
直接运行:

















 224
224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









