




POI推荐任务概述
POI(兴趣点):指代例如商场、学校、家等各种可能吸引到用户的有意义的区域。
序列推荐任务,根据用户的历史轨迹序列,预测出将来某个时间点用户可能感兴趣的POI.
Next-POI推荐的两种范式
本文提出的即为下边的新范式
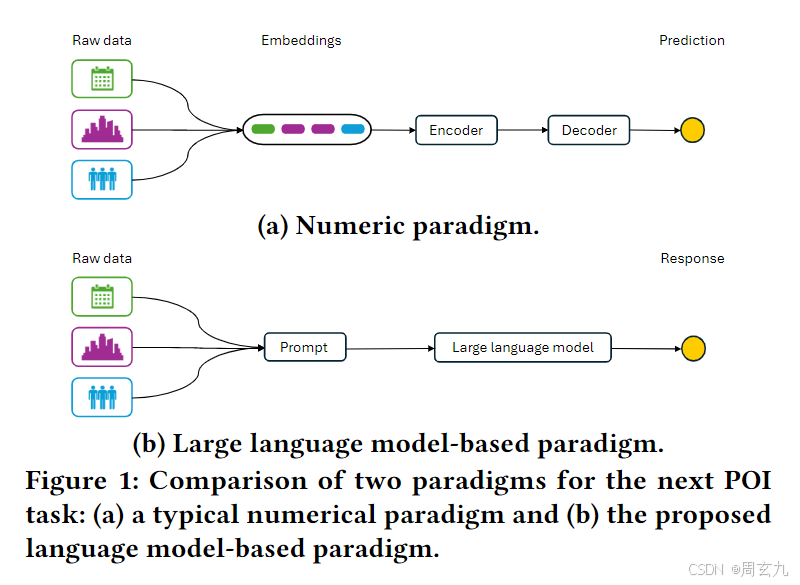
传统的POI推荐将原始异构数据直接映射成Embedding, 然后对embedding进行融合,通过编码解码结构获得下一个POI推荐,这种方法被认为是有信息损失的
新兴的架构将原始数据汇聚成Prompt提示词,而后经过大语言模型处理,最后得到下一个POI推荐
模型解决的问题
- 如何利用多种数据中丰富的语义信息,先前都是直接转化成数值然后做embedding,是没有有效进行融合的。【如何理解?多源数据在向量embedding空间进行融合是无依据的融合,但是LLM是处理文本的高手,我们如果能把多源数据以文本的形式给LLM,我们就认为它能够对信息进行无损整合】
- 包含了常识性信息,进而能够理解上下文含义
- 使用键-值相似度匹配来缓解冷启动问题
模型缺点
- 模型训练时间和推理时间慢
- 由于LLM语料库的限制,部分数据是用不了的
介绍
- 当前工作主要解决短轨迹问题和冷启动问题,没有注意到如何深度融合多源数据,这些数据如果很好融合就能够精确建模用户行为,甚至推断出数据中没有体现的信息,比如在教学时间访问教学楼的频率可以推断出用户是教师还是学生,显然,这两种群体在假期时间要访问的POI也不同。
- 之前工作存在的弊端:
- 没有充分融合语境信息
- 过度依赖人工设计模式、难以理解复杂模式(主要是统计学习的问题,深度学习解决的挺好)
- 充分融合语境信息有两个挑战
- 需要从原始数据中直接进行信息的提取,避免embedding融合时候的信息损失
- 需要常识推断能力,能够逻辑推理出原始数据中并不直接包含的信息
针对挑战1:本文将不同的语境信息以一定格式的自然语言整理成<question>
针对挑战2:本文将整理好的<question> 给到预训练好的大模型中,让大模型去理解这些信息
方法论
原始数据用于生成提示词和进行提示词相似度匹配,为LLM的提示词由相似度匹配的结果以及原始数据共同构成,而后训练过程根据上述给出的prompt进行微调
Trajectory Prompting
将多源异质数据整理成下面prompt里所属的格式,红色代表当下,紫色代表过去轨迹,橙色代表指令,蓝色代表目标回答。

对于用户轨迹数据中的一个点𝑞 = (𝑢, 𝑝, 𝑐, 𝑡, 𝑔)
- u 用户id
- p poi id
- c poi 种类
- t 时间
- g 地理位置点
将其整理为了上边表格中check-in record的格式,注意到其中g被省略了,因为需要节省token
,并且如果不对地图数据进行专门微调,LLM也无法区分地理坐标
注意:对于当前轨迹,只能有来自于当前用户的一条轨迹,而对于历史轨迹,可以有来自任意用户的任意条轨迹,其中来自其他用户的轨迹是通过相似度匹配加上去的,用户解决短轨迹问题和冷启动问题,具体的匹配过程会在方法论第二节讲到
目标块是用户当前轨迹的最后一个点,在训练的过程中被排除了出去
文章尝试过在目标块中加入POI种类信息,企图让模型更加关注POI ID和POI 种类之间的关联,但是发现没有显著的效果,可能模型已经隐性学到了。
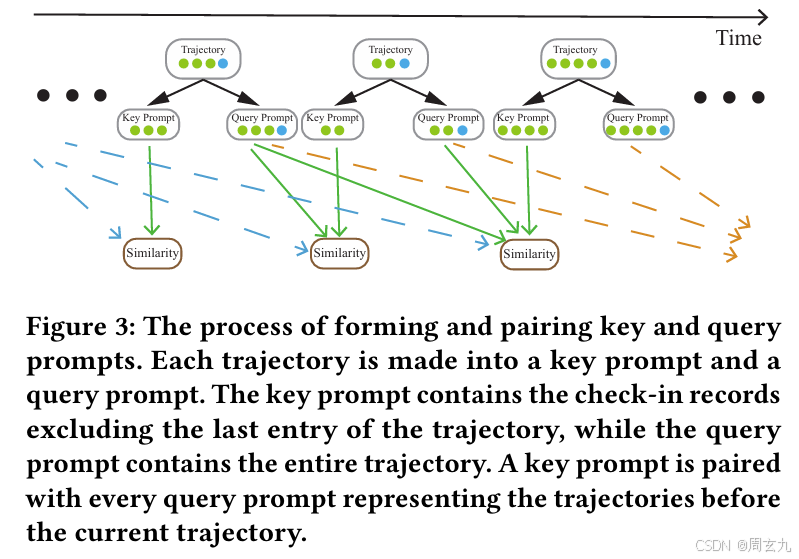
Key-Query Pair Similarity
这一个模组,用于筛选可能和用户行为相似的历史轨迹,参与模型的训练
如下图所示,每一条轨迹都会被整理成key 和 query, Query比Key多一条,就是最后一个,在训练的时候key会和所有比当前轨迹早的轨迹进行匹配。
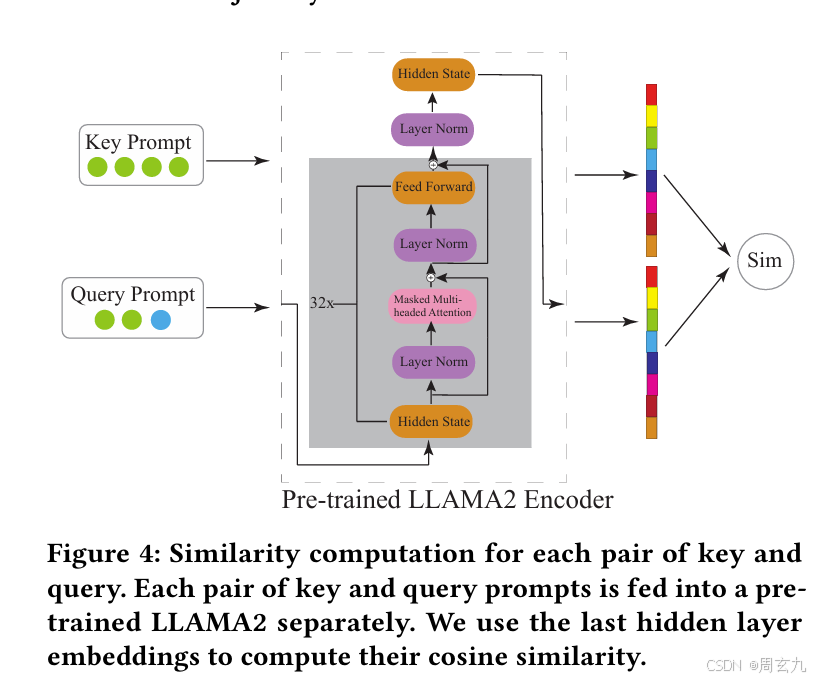
具体的匹配过程如下,Key和Query都会经过Encoder映射到隐空间,然后进行余弦相似度匹配(具体是取多少条文章里这个部分没说)
Supervised Fine-tuning
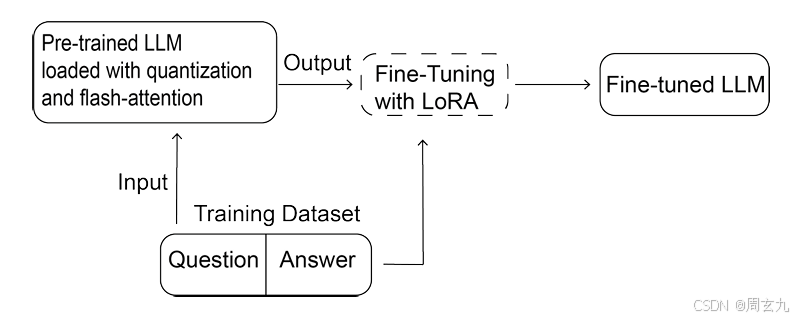
这里使用三个技巧:
LoRA:快速进行微调的方法
Quantization:减少GPU压力
FlashAttention:在原始的prompt中由于历史轨迹很长,普通的attention满足不了需求,我们使用flash-attention.
实验部分
数据处理
- 删除被访问次数小于10的POI
- 删除访问记录少于10条的用户
- 将用户的轨迹按24小时的间隔进行切分,排除只有一条访问记录的轨迹
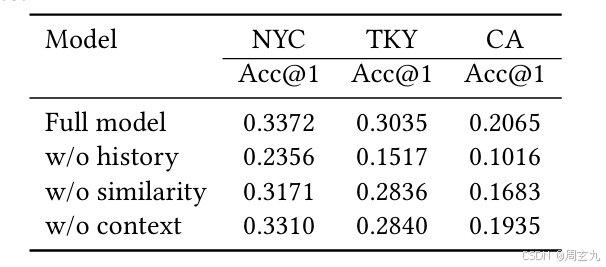
实验
- 最毛坯的版本既没有来自其他用户的轨迹(健值匹配),也没有自己的历史轨迹
- 装修版本1提示词里有了有了自己的历史轨迹
- 装修版本2两个都加上了
结果证明是在变好的
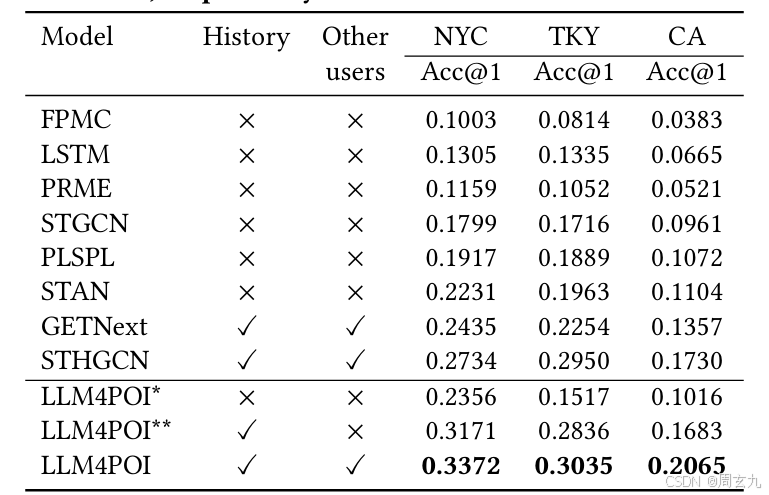
分析
冷启动分析
为了验证冷启动部分的有效性,使用STHGCN进行对比(该模型设法解决冷启动问题)
将用户按照轨迹条数分为三类群体,前30%为非常活跃用户,中间40%为中等活跃用户,最后30%为不活跃用户,对比如下
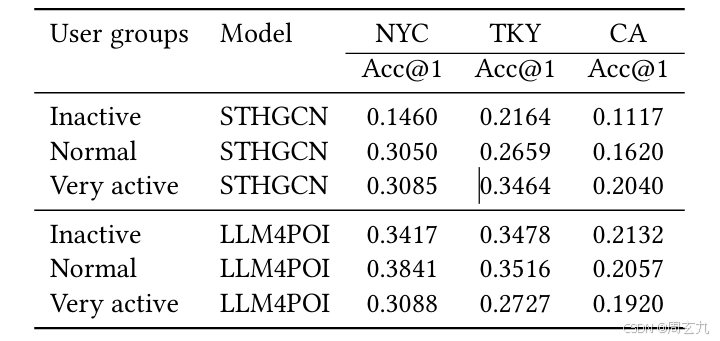
发现在非常活跃用户上效果反而不好,可能是由于进行K-Q匹配的时候基本来源于自己,导致轨迹模式单一化,推荐不是很准确
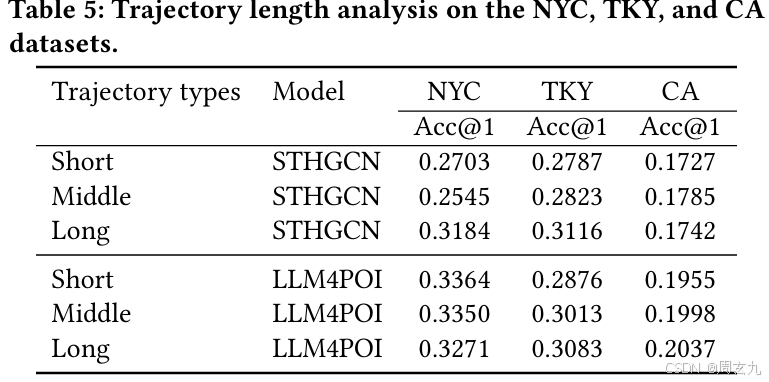
轨迹长度分析
由于语境信息限制,在预测的时候,如果当前轨迹很长,会导致历史轨迹变短;如果当前轨迹短则反之;所以不同的轨迹长度预测效果应该不太一样【token长度限制】。定义前30%长的是长轨迹,最后30%是短轨迹,中间为中轨迹,看效果:
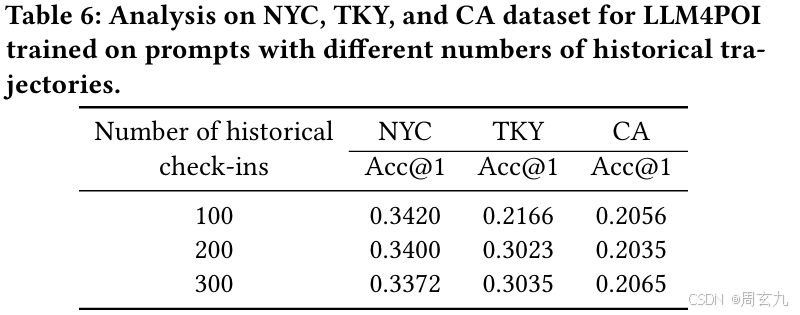
历史轨迹条数
终于说到了这个,看样子不同轨迹在这里没有做定长处理,而之前的深度学习模型都是会去把轨迹限制到一个定长方便训练; 轨迹不定长,所以用历史的轨迹点去衡量历史轨迹的数目
结论是增长活降低历史轨迹点数目和性能的提升没有必然关系,所以模型不如选一个比较低的历史点数目,加快训练速度
模型泛化分析
文章提到,由于使用的是大语言模型生成,结果并非产生概率输出,所以天然具有应用到未见场景的能力,在一个数据集上微调就可以放在其他数据集上进行测试
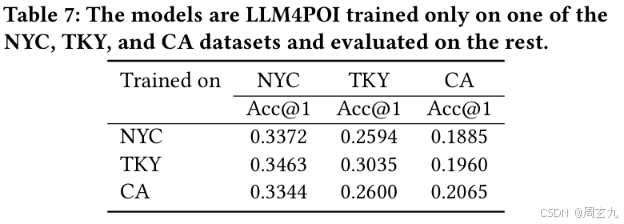
有趣的是,在NYC上微调然后来预测TKY反而比TKY上微调预测TKY好,为啥这么好效果?
文章做了个漂亮的解释:因为<Answer>一般出现在了<Question>里边,所以LLM微调学到的东西就是从<Question>里边理解逻辑,找出答案。 所以他实质上,学会的很多从问题里边找答案(POI ID这个事情 占很大比重,模型对POI category 理解不是特深刻,即便没有category,也会有还行的效果,下边也会说到)。
语境信息分析
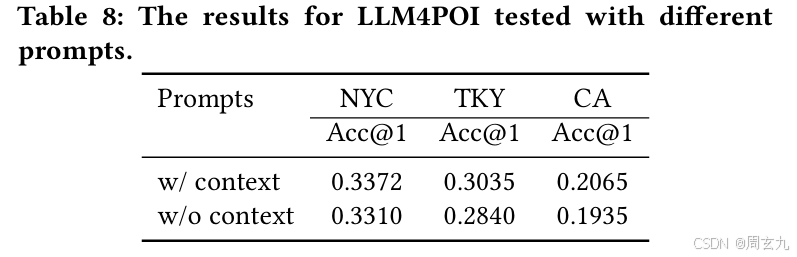
想测试模型对语境信息的理解程度对加深理解有何作用,文章试图把prompt中的POI category全都替换成空白的词语,最后发现效果确实变差了,证明这些语义信息对预测还是具有一定的作用
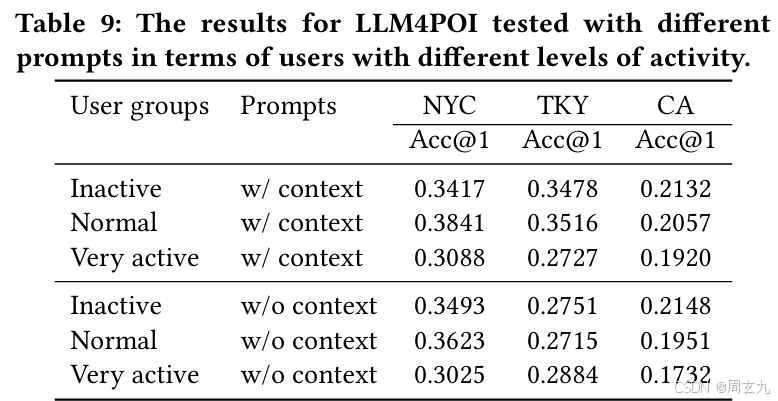
但是细看分类的结果,对于不同用户,NYC、CA两个并成一组,在Inactive上升,Normal 和active下降,TKY反之,需要探究一下这里的原因
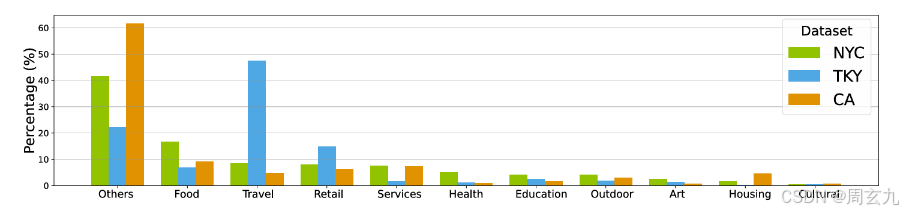
看看这,我们发现了这两组数据集的POI种类分布很不一样,所以模型在两组数据集上的行为不同,进而在上边展示出了不同模式,也侧面印证了模型确实是有学到语境相关信息的。
不同组件的影响
分别是:用户自己的历史轨迹、其他用户的历史轨迹、语境信息(POI种类)
总结
文章提出了使用LLM进行POI推荐,开创了一种新范式,达成了很好的效果;但也存在由于token不足问题无法有效利用geo数据。为POI推荐提供了一种新思路

















 313
313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









