






NICE SLAM 论文阅读
NICE-SLAM
论文引用:Zhu Z, Peng S, Larsson V, et al. Nice-slam: Neural implicit scalable encoding for slam[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022: 12786-12796.
简介:
目前的方法,使用简单的MLP网络,场景表达过于平滑,难以扩展到大场景。NICE SLAM引入分层场景表达(hierarchical scene representation),利用预训练的几何先验优化这类表达,便于扩展到大场景。
1.Introduction
SLAM需要实时,有能力预测未观测的部分,能扩展到大场景,对噪声具有鲁棒性。
传统SLAM能实时,适用大场景,但难以对未观测的区域进行合理的预测;基于学习的方法,有一定的预测能力,可以更好处理噪声和异常,但是只能在小场景工作。IMAP具有良好的追踪和建图效果,但场景扩大效果大大降低。
iMAP的缺陷源于单个MLP,只能根据新的观测进行全局更新预测。基于多级网格特征可以帮助保存几何细节和重建复杂的场景,但这些都是没有实时功能的离线方法[37,48]。
NICE SLAM,将分层场景表示的优势与神经隐式表示的优势结合起来,以完成密集 RGB-D SLAM 任务
- 用层次特征网格来表示场景的几何形状和外观,并结合在不同空间分辨率下预训练的神经隐式解码器的归纳偏差(inductive biases)。
- 通过从占用率和彩色解码器输出中得到的渲染后的深度和彩色图像,我们可以通过最小化重渲染损失(re-rendering losses),只在可视范围内优化特征网格。
2.Related Work
稠密视觉SLAM:该方法的地图表述分为视觉中心和世界中心。
视觉中心:将三维几何嵌入至关键帧,例如DTAM。很多基于深度学习的方法采用DTAM框架,进行深度和姿态回归。
世界中心:在统一的世界坐标系中锚定几何形状。可以进一个划分为面元,体素。
本文工作: 使用体素表达,存储几何图形的隐式潜在编码,并在MAPPING过程中直接优化,该方法允许我们以较低的网格分辨率实现更精确的几何图形
隐式神经表达: 近期关于NeRF的工作,可以实现场景建模等功能,但是依靠给出的相机位姿。另一方面,有工作解决了相机姿态优化问题,但需要一个相当长的优化过程
iMAP,给定一个RGB-D序列,使用单一的多层感知器(MLP)紧凑地表示完整的场景。iMAP不能产生详细的场景几何形状和精确的摄像机跟踪。NICE SLAM提供了一个类似于iMAP的可扩展的解决方案,它结合可学习的潜在嵌入和预先训练的连续隐式解码器,重建复杂的几何形状和为更大的室内场景预测详细的纹理,同时保持更少的计算和更快的收敛。
3.方法
简要说明: 使用4个特征网络以及对应的解码器表述场景的几何结构和外观。同时使用估计的相机校准跟踪每个像素的观察光线。利用光线采样点和查询网络,渲染该光线的深度和颜色。最小化深度和颜色的重新渲染损失,以交替方式优化选定关键帧的相机姿态和场景几何体。
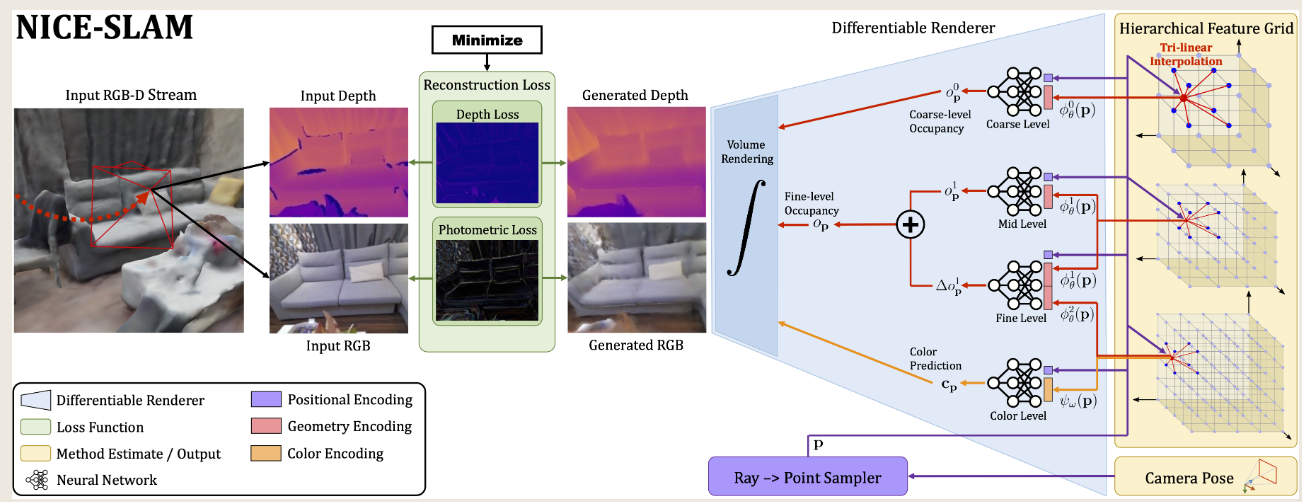
图2:输入RGB-D图像流,输出位姿和分层特征网络所表述的场景。从右向左,通过给定的场景表示和相机位姿,利用生成模型渲染当前的深度和图像。从左向右,通过利用可微分渲染器,解决图片,深度损失逆问题来估计场景表示和相机位姿。这两个过程在交替优化中估计:MAPPING,反向传播仅更新场景表示;TRACKING,反向传播仅更新相机位姿。
3.1分层场景表示
通过3个编码器
和对应的MLP解码器
表示几何,3个网络分别表示粗,中,细的场景;通过1个编码器
和对应的解码器
表示场景外观。其中, θ 和 ω 表示几何和颜色的可优化参数,即网格中的特征和颜色解码器中的权重。
中-细几何场景表示
使用中-细的网格表示观测到的场景几何(32cm-16cm,16cm-8cm)。先使用中网络重建场景几何,再使用细网络细化场景几何。
对于中网络,对任意点
,特征直接使用MLP解码为占用值:
其中,
表示特征网格在p点处被三线性插值。使用较粗的网络可以有效优化网格特征以此适应观测。
—————————————————————————————————————————————
对于细网络,加入残差方式,以此捕捉场景中的高频细节。特征解码器将对应的中级特征和精细级特征作为输入,并输出从中层占用的偏移量:
最终的占用率表示如下:
综上,解码器f1,f2,为预训练,在整个优化过程中仅优化特征网络
。这有助于稳定优化和学习一致的几何图形。
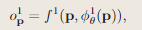
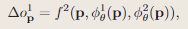
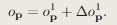
粗几何场景表示
粗级特征网捕获场景的高层几何形状(例如墙壁、地板等)与中-细独立优化。该网格(2m)用于预测观察到的几何图形外的近似占用。同理,通过插值特征和MLP直接解码p处的占用值:
在追踪时,粗网络的占用值只用于预测场景中未被观测的部分,且预测的结果可以用于追踪。
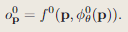
预训练特征解码器
在算法中,使用3个不同的固定的MLP解码器,将网格特征解码为占用值。对于粗中层,作为 ConvONet [37](由 CNN 编码器和 MLP 解码器组成由 CNN 编码器和 MLP 解码器组成) 的一部分进行预训,使用预测值和真实值之间的二元交叉熵损失来训练编码器/解码器。结束训练后,取其中的MLP解码器,用于直接优化特征,以此适应MAPPING中的观测值。该方法,可以利用在训练集中学的特定于分辨率先验,解码优化后的特征。
同理,细解码器也是这样的策略,只是该解码器的输入为中-细特征网格的连接。
颜色表示
通过编码颜色信息,用于RGB渲染,为跟踪添加附加信息。同理,为了编码场景颜色,我们引入一个特征网格
和解码器
,占据率表示如下:
其中,w表示优化过程中的可学习参数。不同于几何结构的固定解码器,颜色网格联合优化颜色与解码器,可以提高跟踪性能。同iMAP,该方法可能导致遗忘问题,颜色只在局部保持一致。如果要可视化整个场景的颜色,可以进行全局优化。
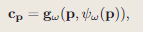
网络设计
所有MLP解码器,采用32和5道德全连接块的隐藏特征维度。除粗层,在MLP解码器输入前,点p引入可学习的高斯位置编码,该方法可以发现几何和外观的高频细节。
3.2深度和颜色渲染
使用可微分渲染的方法,集成3.1中预测场景的占用率和颜色。
通过给定的相机位姿和内参,可以计算某像素坐标的视线朝向。首先,沿射线进行
个点的分层采样,同时在深度附近进行
个点的均匀采样,每条射线一共进行
个点的采样。
pi = o + dir, i ∈ {1, · · · , N } (di表示深度)
对于每个点p,可以 分别计算其在各个网格中的占用概率值和颜色值。
我们在点pi上建模射线的终止概率(termination probability),在粗糙层上:
在精细层上:
粗,细层的深度,颜色信息渲染如下:
同时,计算每条射线的深度方差:
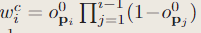
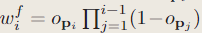
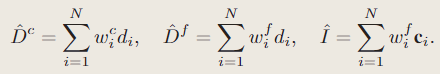
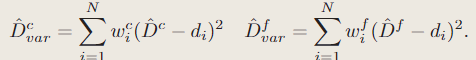
3.3建图与跟踪
介绍几何参数
、外观参数
、相机位姿优化
Mapping
从当前帧和所选关键帧中统一采样总共M个像素,以分阶段的方式进行优化,以最小化几何和光度损失。
几何损失:粗网格或细网格中观测与预测的差值(粗网络用于未观测部分的预测,那么它的Loss如何计算)
光度损失:M 个采样像素的渲染颜色和观察到的颜色值之间的损失
- 通过中间层的深度损失,优化中间层
- 通过精细层的深度损失,联合优化中间层和精细层
- 进行局部BA优化,共同优化所有层次的特征网格、颜色解码器以及K个选定关键帧的相机外参Ri,ti。
其中,λp 是损失权重因子
更高分辨率的外观和精细级特征可以依赖于来自中级特征网格的已经细化的几何形状, 这种分阶段的优化方法使得MAPPING更好的收敛, 这种分阶段的优化方法使MAPPING更好的收敛。
注意: 在三个线程中并行化我们的系统以加快优化过程:一个用于粗级映射的线程,一个用于中级几何和颜色优化,另一个用于相机跟踪。
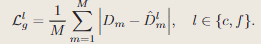
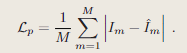
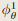
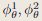
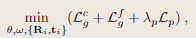
Tracking
在优化场景的同时,本文并行跟踪功能,以此优化当前帧的相机姿态。使用M个像素对应的光度损失和修改后的几何损失:
该几何损失降低了几何重建中不太确定区域的权重,摄像机跟踪最终被表述为以下最小化问题:
其中,粗层的特征网格能够对场景几何图形进行短程预测。当相机移动到以前未观察到的区域时,这种推算出的几何形状为跟踪提供了一个有意义的信号。使其对突然帧丢失或相机快速相机移动更加鲁棒。
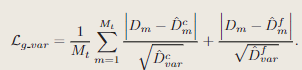
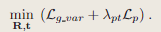
动态物体的鲁棒性
在优化跟踪的过程中,过滤掉大的深度/颜色重渲染损失,使得对动态对象更鲁棒。具体来说,在优化中删除(12)中损失大于当前帧所有像素的10倍损失中值。例如,图6出现了一个动态对象,将其忽略,不被渲染在RGB和深度图像中。
3.4关键帧选取
同iMAP,使用一组关键帧优化分层场景表示。维护全局关键帧列表,根据信息增益添加新的关键帧。不同于iMAP,仅在与当前帧有重叠的关键帧中优化场景几何。这种关键帧选取方式,确保视图外的几何保持静态,每次只优化必要参数,产生非常有效的优化问题。
在实际应用中,本文随机采样像素,并使用优化的相机姿态反向投影对应的深度。然后,将点云投影到全局关键帧列表中的每个关键帧上。从那些有投影点的关键帧中,随机选择了K−2帧。此外,还在场景表示优化中包括了最近的关键帧和当前帧,形成总共K个活动帧。关于关键帧选择策略的消融研究(Ablation Study),请参阅第4.4节。
4.实验
4.1实验设置
数据集:本文使用Replica、ScanNet、TUM RGB-D数据集、Co-Fusion数据集,以及一个有多个房间的获取的大公寓,遵循TUM RGB-D数据集相同的预处理步骤。
基准:与TSDF-Fusion的相机位姿进行比较,体素网格分辨率为256^3;DI-Fusion和iMAP也用于比较。
度量指标:分别使用2D和3D指标比较几何场景重建。
2D:评估了来自重建网格和地面实况网格的 1000 个随机采样深度图上的 L1 损失。同时,在计算平均 L1 损失之前将双边求解器 [2] 应用于 DI-Fusion [16] 和 TSDFFusion 来填充深度孔
3D:遵循iMAP论文的做法,考虑精度Accuracy[cm]、完成Completion[cm]和完成率[<5cm%],除删除了不在任何相机的观察障碍内的不可见区域。对于相机跟踪的评估,我们使用了ATE RMSE。
实现细节:在一台拥有3.80GHz Intel i7-10700K CPU与NVIDIA RTX 3090 GPU的台式电脑上运行SLAM系统
在所有的实验中,我们使用了射线 Nstrat=3和 Nimp=1上的采样点数,光度损失加权λp=0.2和λpt=0.5。对于小规模的合成数据集(Replica和Co-Fusion),选择K=5个关键帧和分别采样M=1000和Mt=200个像素。对于大规模的真实数据集(ScanNet和自捕获场景),我们使用K=10,M=5000,Mt=1000。对于具有挑战性的TUM RGB-D数据集,使用K=10,M=5000,Mt=5000。
4.2建图与跟踪评估
Replica数据集评估
使用与iMAP相同的RGB-D序列,通过分层场景表示,我们的方法能够在有限的迭代范围内精确地重建几何图形。
表1.Replica数据集上的重建结果。iMAP∗表示我们重新实现的iMAP。TSDF-Fusion使用来自NICE-SLAM的相机位姿。每个场景的详细度量标准可以在补充文件中找到。
图3.Replica数据集上的重建结果。iMAP∗是指我们重新实现的iMAP
由表1,NICE-SLAM在几乎所有指标上都显著优于baseline基准方法,同时保持了合理的内存消耗。定性地说,可以从图3中看到,本方法产生了更清晰的几何形状和更少的伪影。
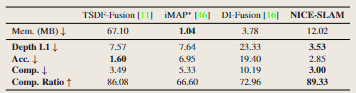

TUM RGB-D数据集评估
评估本算法在小型TUM RGB-D数据集上的相机跟踪性能。如表2所示,我们的方法优于iMAP和DI-Fusion,尽管我们的设计更适合大场景。可以注意到,跟踪最好的方法(BAD-SLAM,ORB-SLAM2)仍然优于基于隐式场景表示的方法(iMAP和我们的方法)。然而,本方法显著地减少了这两类方法之间的差距,同时保留了隐式表示的表征优势。
表2.TUM RGB-D数据集上的相机跟踪结果。 采用ATE RMSE[cm](↓)作为评价指标
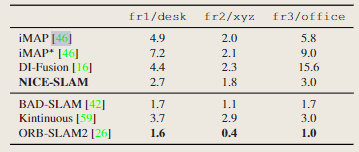
ScanNet数据集上的评估
从ScanNet中选择多个大型场景来基准测试不同方法的可扩展性。对于图4中所示的几何形状,可以清楚地注意到,比起TSDF-Fusion、DI-Fusion和iMAP,NICE-SLAM产生了更清晰、更详细的几何形状。在跟踪方面,我们可以观察到,iMAP和DI-Fusion要么完全失败,要么引入了较大的漂移,而NICE SLAM方法成功地重建了整个场景。
表3.ScanNet数据集上的相机跟踪结果,采用ATE RMSE(↓)作为评价度量
图4. ScanNet数据集上的3D重建和跟踪。 黑色轨迹是来自ScanNet,红色轨迹来自本文
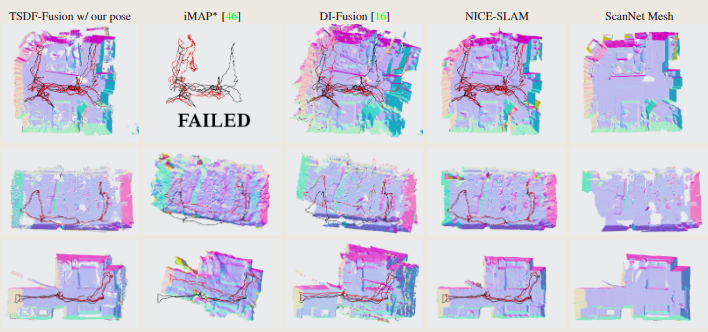
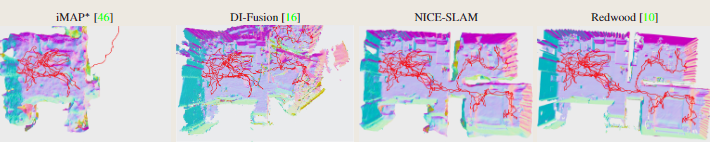
更大场景的评估
图1和图5显示了使用NICE-SLAM、DI-Fusion和iMAP*获得的重建结果。作为参考,我们还展示了在Open3D中使用离线工具Redwoud的三维重建。我们可以看到,NICE-SLAM与离线方法具有相似的结果,而iMAP∗和DI-FusioN无法重建整个序列。
图5.多房间附加的三维重建与跟踪。摄像机跟踪轨迹用红色表示

4.3性能分析
计算复杂度
比较查询一个3D点的颜色和占用/体积密度所需的浮点运算(FLOPs)的数量,详细见表四,NICE SLAM方法所需的浮点数仅为iMAP的1/4。对于大场景,NICE SLAM的方法所需的浮点数不变。iMAP,使用单个MLP,在大场景下数量会增加。
运行时间
在表 4 中比较了使用相同数量像素样本(Mt = 200 用于跟踪,M = 1000 用于映射)的跟踪和映射的运行时间。可以注意到,NICE SLAM方法在跟踪和映射方面比 iMAP 快 2 倍和 3 倍。
表4.计算复杂度和运行时间
对动态对象的鲁棒性
考虑有动态特征的Co-Fusion数据集,如图6所示,NICE SLAM方法正确地识别和忽略落入动态的像素样本;此外,在相同的序列上与 iMAP进行比较,NICE SLAM的和 iMAP的 ATE RMSE 分数分别为 1.6cm 和 7.8cm
图6.对动态对象鲁棒性
图7.几何预测与孔洞填补白色区域是具有观察的区域,青色表示未观察到的但预测的区域。由于使用了粗略的场景先验,与 iMAP∗ 相比,NICE SLAM方法具有更好的预测能力。这又提高了我们的跟踪性能。



4.4消融实验
本节突出分层架构和颜色表示的重要性
分层架构
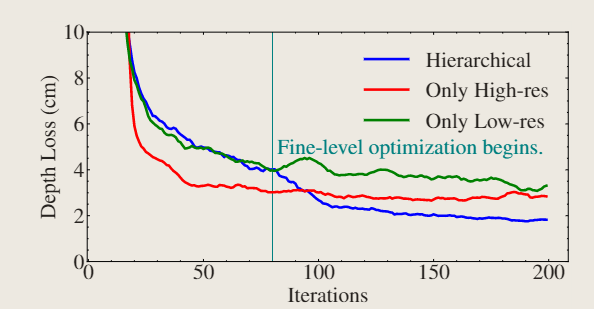
根据图八,分别比较仅使用精细级表示分辨的特征网、仅中层分辨率网络、分层网格结构,可以看出:精细级表示参与优化时,分层架构可以快速添加几何细节,这也会产生更好的收敛
图8.分层架构消融
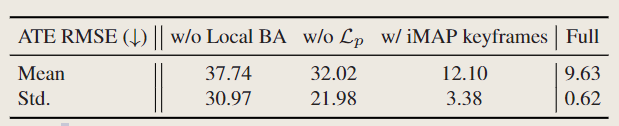
局部BA
在ScanNet[13]上验证了局部BA的有效性。不联合优化 K 个关键帧的相机姿势以及场景表,相机跟踪不不太准确,而且鲁棒性也较差。
表5 消融,该表研究了局部 BA、颜色表示以及我们的关键帧选择策略的有用性。我们运行每个场景 5 次并计算它们 ATE RMSE (↓) 的均值和标准差。
颜色表示
在表5中,比较加入光度损失和没光度损,结果表明,尽管由于优化预算有限且采样点不足,我们估计的颜色并不完美,但学习这种颜色表示对于准确的相机跟踪仍然起着重要作用。
关键帧选取
本文使用 iMAP 的关键帧选择策略(表 5 中的 w/ iMAP 关键帧)来测试NICESLAM的方法,iMAP从整个场景中选择关键帧。该策略对iMAP 是必要的,以防简单的 MLP 忘记先前的几何形状。然而,该方法会导致收敛速度慢和跟踪不准确。
5.结论
本文提出了 NICE-SLAM,这是一种密集的视觉 SLAM 方法,它结合了神经隐式表示的优点和基于分层网格的场景表示的可扩展性。与使用单个大 MLP 的场景表示相比,我们的实验表明,我们的表示(tiny MLP + 多分辨率特征网格)不仅保证了精细的映射和高跟踪精度,而且由于局部场景更新的好处,速度更快,计算量更少。此外,我们的网络能够填充小孔并将场景几何外推到未观察到的区域,从而稳定相机跟踪。
限制
NICE SLAM的预测能力仅限于粗略表示的规模。此外,NICESLAM方法不执行闭环。最后,虽然传统方法缺乏一些特征,但与需要关闭的基于学习的方法仍然存在性能差距。


















 1236
1236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











