






前言
基于Python的大众点评数据爬取、分析及推荐系统是一个复杂但有趣的项目。下面将分别介绍这三个部分。
一、大众点评数据爬取
大众点评的数据爬取可以通过Python的requests库发送请求,并使用BeautifulSoup或lxml库来解析网页。以下是一个基本的爬取流程:
确定目标:确定需要爬取的数据,如商家的名称、评分、地址、价格等。
安装库:使用pip安装所需的库,如requests、BeautifulSoup4等。
发送请求:使用requests库发送HTTP请求,获取网页内容。
解析网页:使用BeautifulSoup或lxml解析网页内容,提取所需数据。
存储数据:将提取的数据存储到CSV文件、数据库或其他存储介质中。
在实际操作中,需要注意大众点评的反爬虫机制。过于频繁的请求可能会导致IP被封锁。因此,可以通过设置请求头、使用代理IP、添加延时等方式来规避这个问题。
详细视频演示
文章底部名片,联系我看更详细的演示视频
一、项目介绍
开发语言:Python
python框架:Django
软件版本:python3.7/python3.8
数据库:mysql 5.7或更高版本
数据库工具:Navicat11
开发软件:PyCharm/vs code
前端框架:vue.js
二、功能介绍
数据分析部分可以使用Python的pandas库来处理数据。以下是一些基本的数据分析步骤:
读取数据:使用pandas读取存储的数据,如CSV文件。
数据清洗:处理缺失值、重复值等,确保数据的准确性和一致性。
数据探索:使用统计方法、可视化工具等探索数据的分布、特征等。
数据分析:根据业务需求进行数据分析,如计算平均评分、统计各区域的商家数量等。
三、核心代码
部分代码:
def users_login(request):
if request.method in ["POST", "GET"]:
msg = {'code': normal_code, "msg": mes.normal_code}
req_dict = request.session.get("req_dict")
if req_dict.get('role')!=None:
del req_dict['role']
datas = users.getbyparams(users, users, req_dict)
if not datas:
msg['code'] = password_error_code
msg['msg'] = mes.password_error_code
return JsonResponse(msg)
req_dict['id'] = datas[0].get('id')
return Auth.authenticate(Auth, users, req_dict)
def users_register(request):
if request.method in ["POST", "GET"]:
msg = {'code': normal_code, "msg": mes.normal_code}
req_dict = request.session.get("req_dict")
error = users.createbyreq(users, users, req_dict)
if error != None:
msg['code'] = crud_error_code
msg['msg'] = error
return JsonResponse(msg)
def users_session(request):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code,"msg":mes.normal_code, "data": {}}
req_dict = {"id": request.session.get('params').get("id")}
msg['data'] = users.getbyparams(users, users, req_dict)[0]
return JsonResponse(msg)
def users_logout(request):
if request.method in ["POST", "GET"]:
msg = {
"msg": "退出成功",
"code": 0
}
return JsonResponse(msg)
def users_page(request):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code, "msg": mes.normal_code,
"data": {"currPage": 1, "totalPage": 1, "total": 1, "pageSize": 10, "list": []}}
req_dict = request.session.get("req_dict")
tablename = request.session.get("tablename")
try:
__hasMessage__ = users.__hasMessage__
except:
__hasMessage__ = None
if __hasMessage__ and __hasMessage__ != "否":
if tablename != "users":
req_dict["userid"] = request.session.get("params").get("id")
if tablename == "users":
msg['data']['list'], msg['data']['currPage'], msg['data']['totalPage'], msg['data']['total'], \
msg['data']['pageSize'] = users.page(users, users, req_dict)
else:
msg['data']['list'], msg['data']['currPage'], msg['data']['totalPage'], msg['data']['total'], \
msg['data']['pageSize'] = [],1,0,0,10
return JsonResponse(msg)
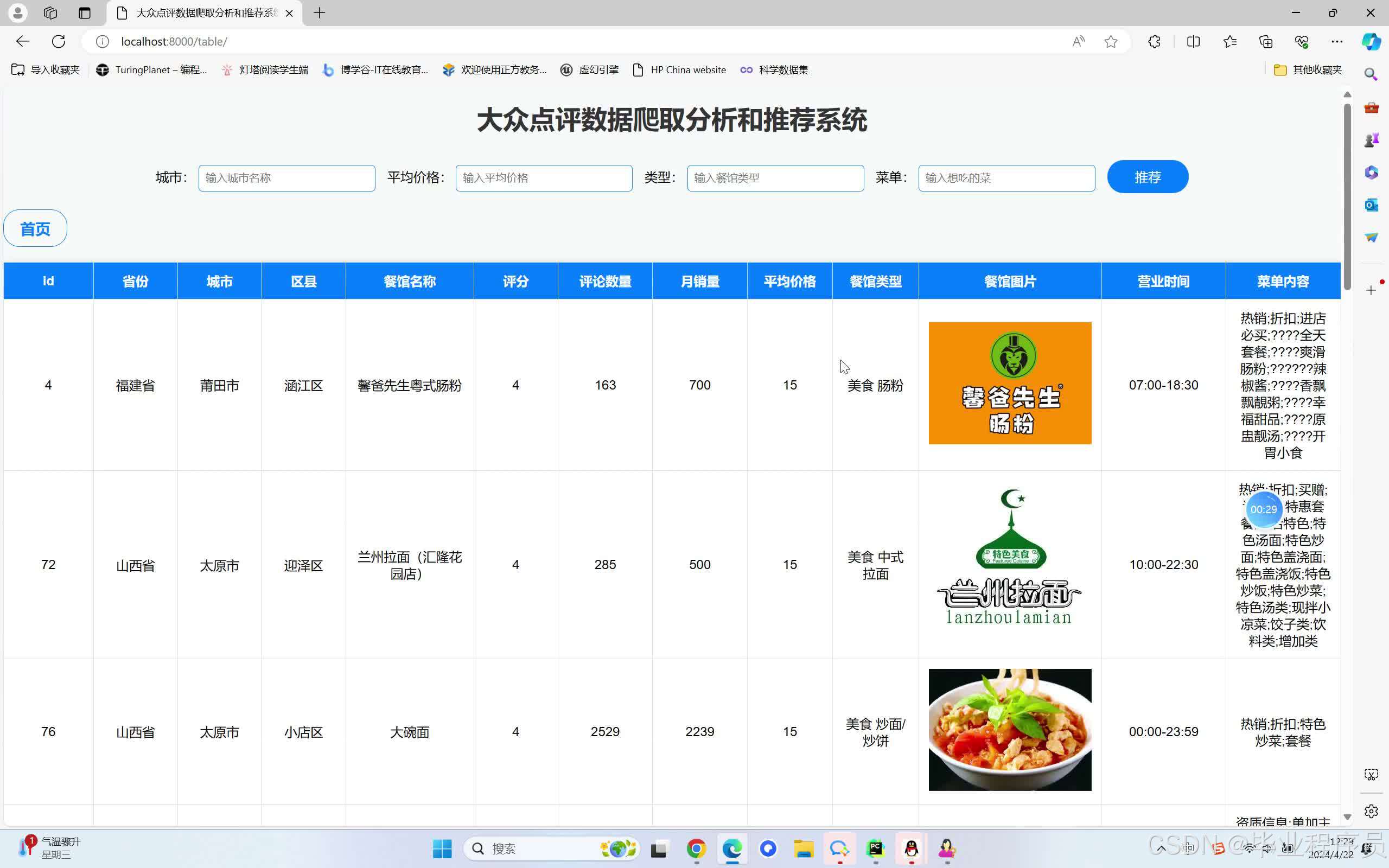
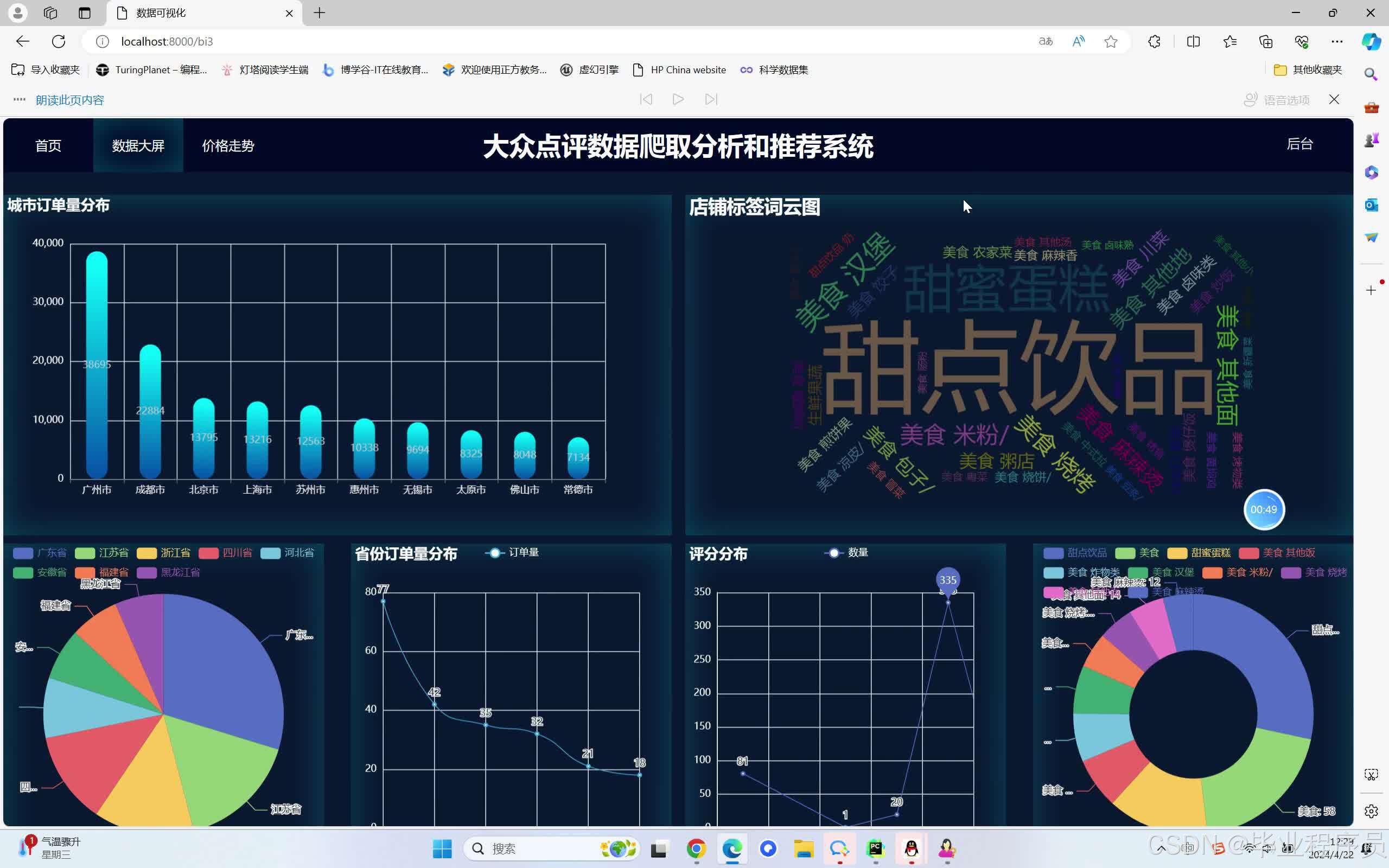
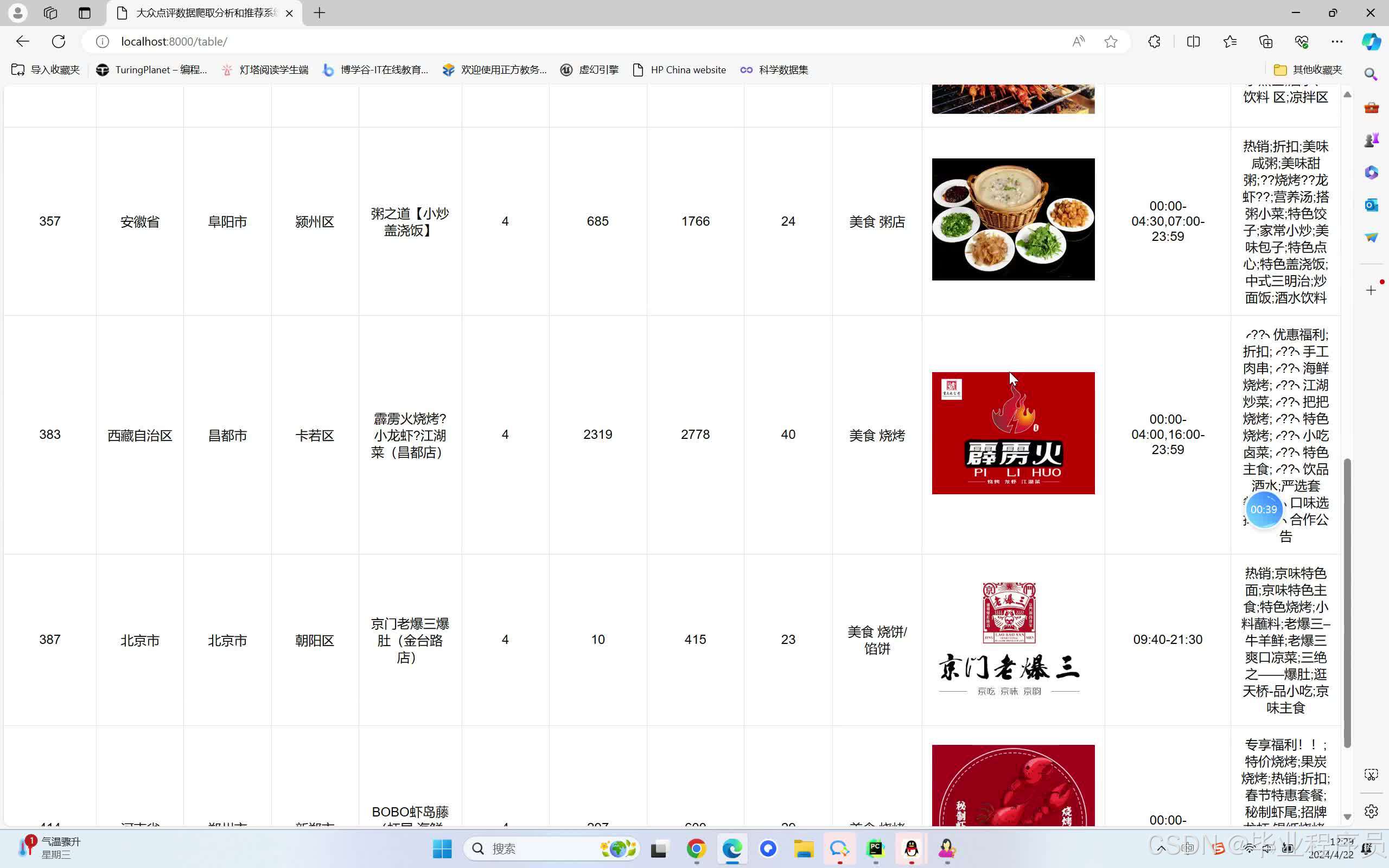
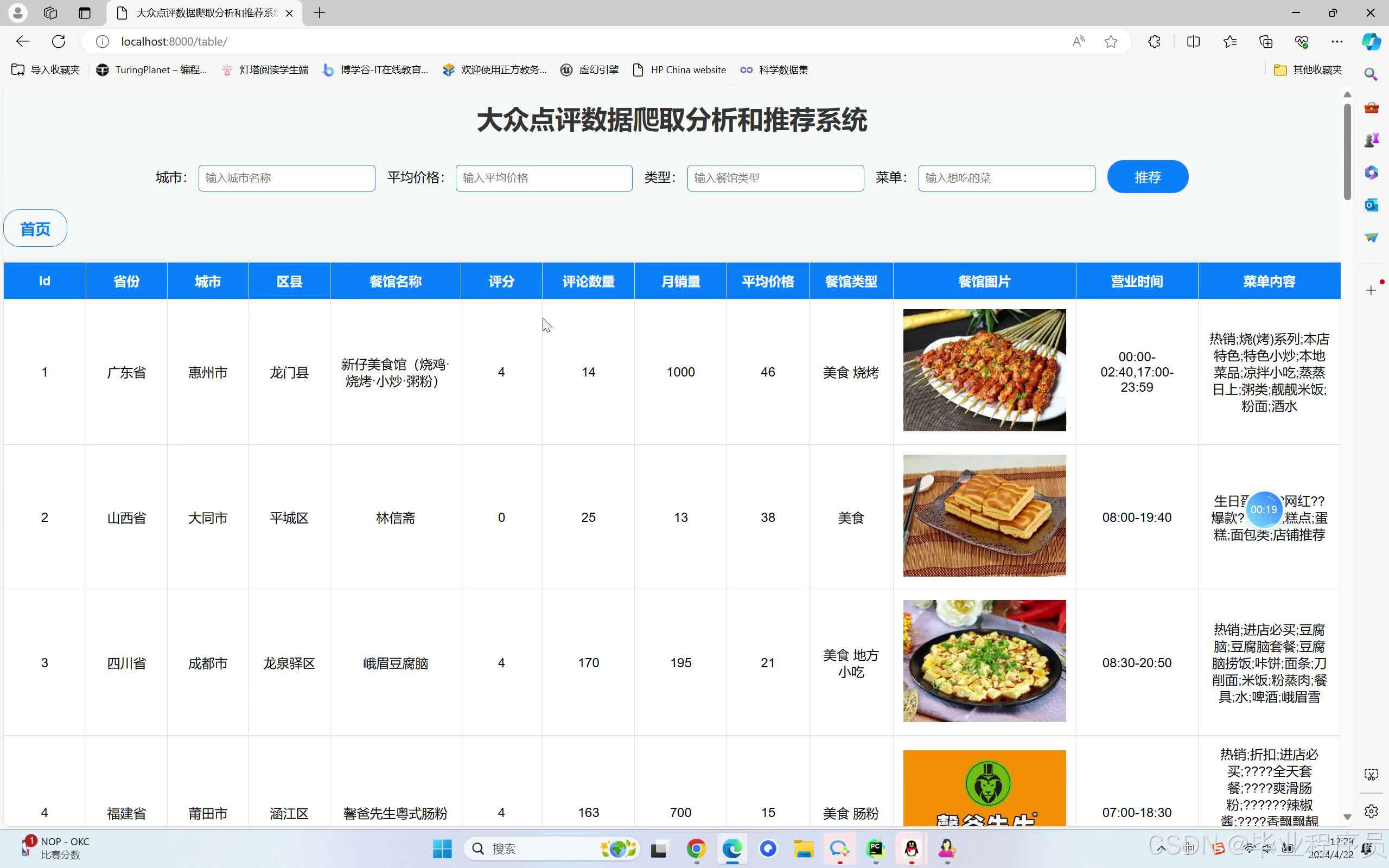
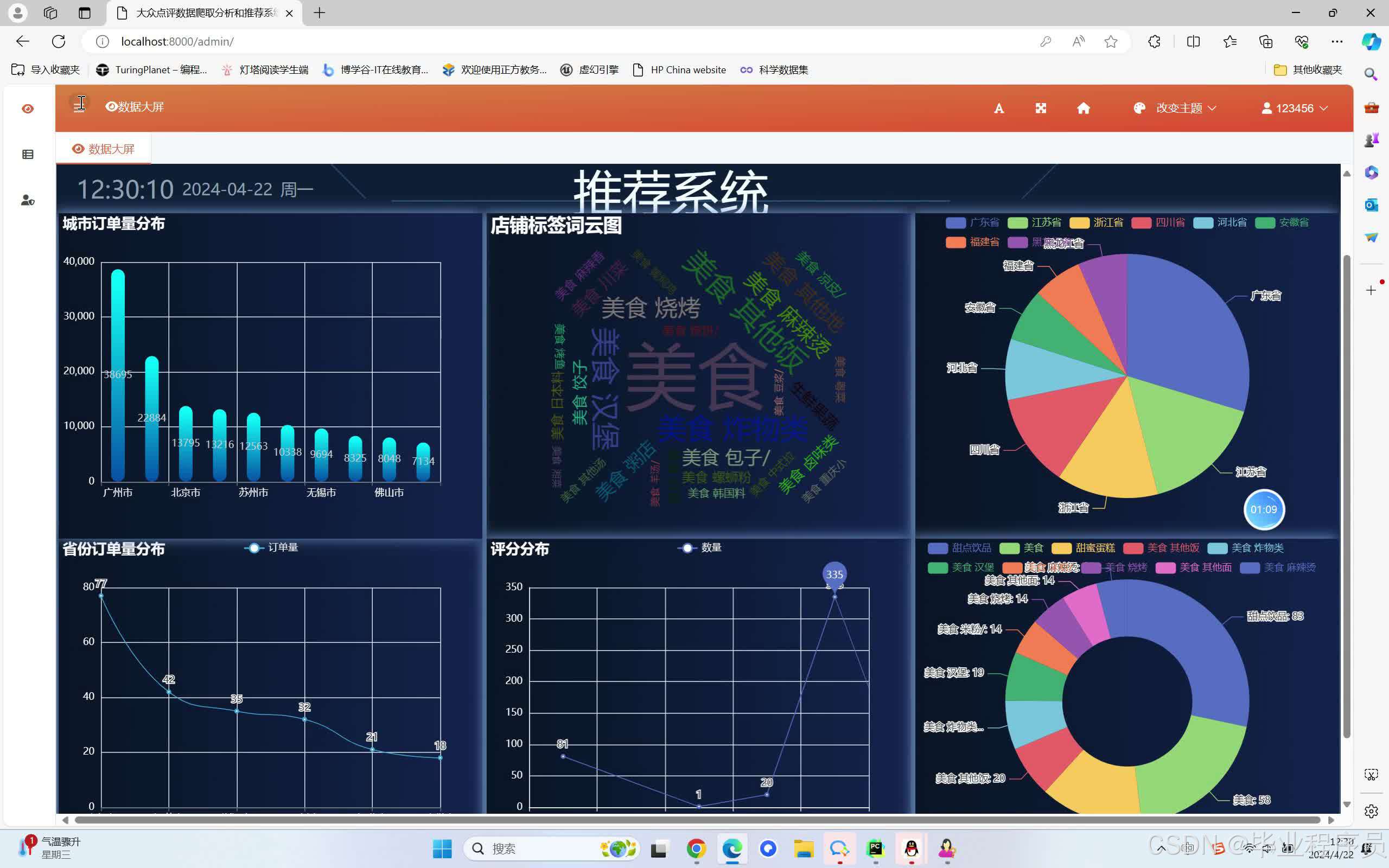
四、效果图



















 3468
3468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









