







一、实验环境
Windows 10/Ubuntu 20.04
二、实验内容与步骤
1.查找资料,用bash编写一个图片批处理脚本,实现以下功能:
(1)支持命令行参数方式使用不同功能。
(2)支持对指定目录下所有支持格式的图片文件进行批处理。
(3)支持以下常见图片批处理功能的单独使用或组合使用。
- 支持对jpeg格式图片进行图片质量压缩。
- 支持对jpeg/png/svg格式图片在保持原始宽高比的前提下压缩分辨率。
- 支持对图片批量添加自定义文本水印。
- 支持批量重命名(统一添加文件名前缀或后缀,不影响原始文件扩展名)。
- 支持将png/svg图片统一转换为jpg格式图片。
本实验是用vscode ssh远程登录ubuntu完成的,图片处理主要使用imagemagick
实验目标图片以及shell脚本:
图片都为:
(1)查看shell脚本的-help内置脚本帮助信息:
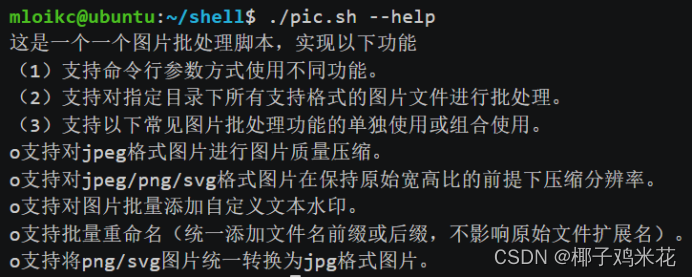
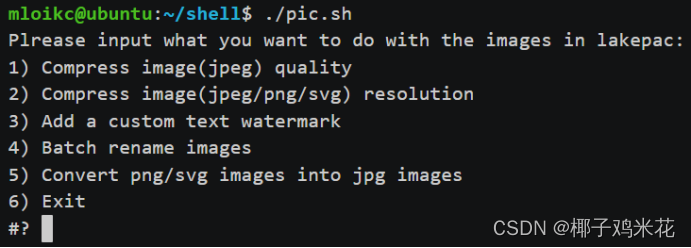
(2)运行脚本,可根据输入参数运行不同功能:
用分支语句实现
(3)对jpeg格式图片进行图片质量压缩:
convert -quelity 比例 原图 改后的图

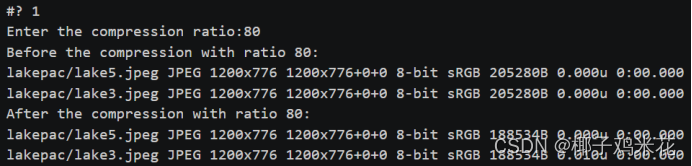
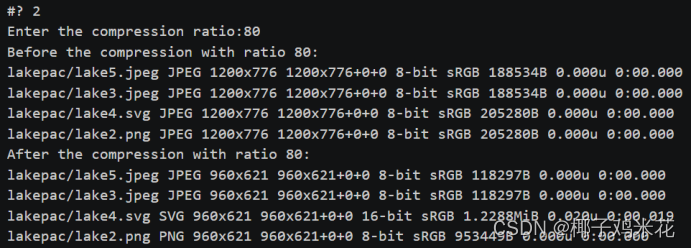
(4)对jpeg/png/svg格式图片在保持原始宽高比的前提下压缩分辨率:
convert-resize 比例 原图 改后的图

(5)对图片批量添加自定义文本水印:
convert -fill green -pointsize 50 -draw ‘text 10,50 “Made by Mloikc”‘ $ing $img。表示在距离图片左上角10*50的位置处,用白色的文字写下Made by Mloikc



(6)批量重命名(统一添加文件名前缀或后缀,不影响原始文件扩展名):
添加前缀:mv -f $img `echo "前缀"$img`
添加后缀:mv -f $img `echo $img"后缀"` (这里我理解的意思可能有误)
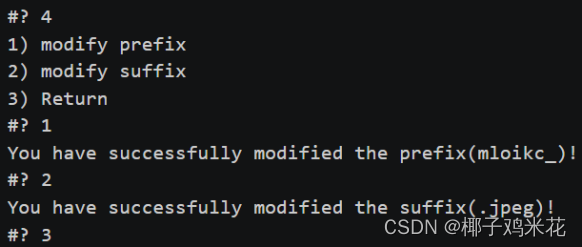
添加前缀: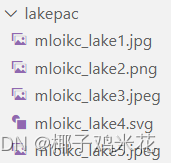
添加后缀: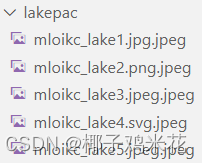
其实我感觉这里我做错了,应该添加后缀在文件名称的后面而不是拓展名的后面,请查看文档末的另一个人的博客来查看那样子的写法吧 shell脚本编程基础 | 烏巢 (hejueyun.github.io)
(7)将png/svg图片统一转换为jpg格式图片:
rename 's/\.png/\.jpg/' * 和 rename 's/\.svg/\.jpg/' *
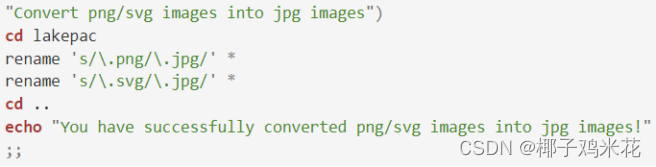

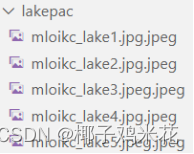
完整代码:
#!/bin/bash
if [[ $1 = "--help" ]] || [[ $1 = "-h" ]]
then
echo "这是一个一个图片批处理脚本,实现以下功能"
echo "(1)支持命令行参数方式使用不同功能。"
echo "(2)支持对指定目录下所有支持格式的图片文件进行批处理。"
echo "(3)支持以下常见图片批处理功能的单独使用或组合使用。"
echo "o支持对jpeg格式图片进行图片质量压缩。"
echo "o支持对jpeg/png/svg格式图片在保持原始宽高比的前提下压缩分辨率。"
echo "o支持对图片批量添加自定义文本水印。"
echo "o支持批量重命名(统一添加文件名前缀或后缀,不影响原始文件扩展名)。"
echo "o支持将png/svg图片统一转换为jpg格式图片。"
exit 0
fi
echo "Plrease input what you want to do with the images in lakepac:"
select i in "Compress image(jpeg) quality" "Compress image(jpeg/png/svg) resolution" "Add a custom text watermark" "Batch rename images" "Convert png/svg images into jpg images" Exit
do
case $i in
"Compress image(jpeg) quality")
ratio=0
read -p "Enter the compression ratio:" ratio
echo "Before the compression with ratio $ratio:"
for img in `find lakepac/ -name "*.jpeg"`
do
identify $img
done
echo "After the compression with ratio $ratio:"
for img in `find lakepac/ -name "*.jpeg"`
do
convert -quality $ratio% $img $img
identify $img
done
;;
"Compress image(jpeg/png/svg) resolution")
ratio=0
read -p "Enter the compression ratio:" ratio
echo "Before the compression with ratio $ratio:"
for img in `find lakepac/ -name "*.jpeg" -o -name "*.png" -o -name "*.svg"`
do
identify $img
done
echo "After the compression with ratio $ratio:"
for img in `find lakepac/ -name "*.jpeg" -o -name "*.png" -o -name "*.svg"`
do
convert -resize $ratio% $img $img
identify $img
done
;;
"Add a custom text watermark")
for img in lakepac/*
do
convert -fill white -pointsize 50 -draw 'text 10,50 "Made by Mloikc"' $img $img
done
echo "You have successfully added a watermark(Made by Mloikc)!"
;;
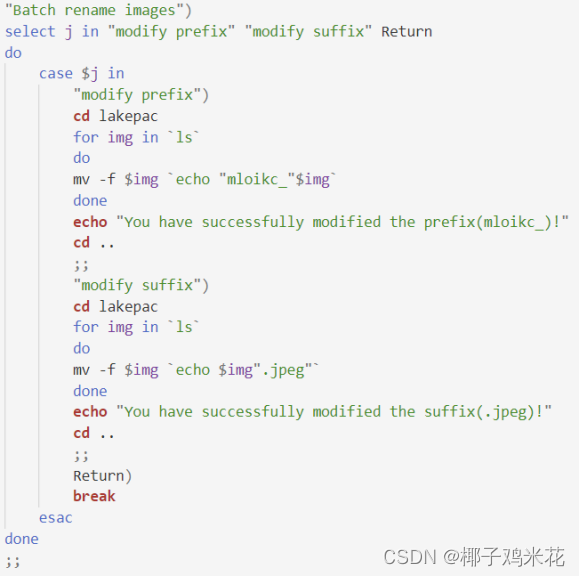
"Batch rename images")
select j in "modify prefix" "modify suffix" Return
do
case $j in
"modify prefix")
cd lakepac
for img in `ls`
do
mv -f $img `echo "mloikc_"$img`
done
echo "You have successfully modified the prefix(mloikc_)!"
cd ..
;;
"modify suffix")
cd lakepac
for img in `ls`
do
mv -f $img `echo $img".jpeg"`
done
echo "You have successfully modified the suffix(.jpeg)!"
cd ..
;;
Return)
break
esac
done
;;
"Convert png/svg images into jpg images")
cd lakepac
rename 's/\.png/\.jpg/' *
rename 's/\.svg/\.jpg/' *
cd ..
echo "You have successfully converted png/svg images into jpg images!"
;;
Exit)
echo "Thank you for using!"
exit
esac
done
2.用bash编写一个文本批处理脚本,对以下附件分别进行批量处理完成相应的数据统计任务:
- 统计不同年龄区间范围(20岁以下、[20-30]、30岁以上)的球员数量、百分比。
- 统计不同场上位置的球员数量、百分比。
- 名字最长的球员是谁?名字最短的球员是谁?
- 年龄最大的球员是谁?年龄最小的球员是谁?
先将下载好的tsv数据另存为以逗号分隔的csv文件:

要是文件数据量太大(超过一百万行)可以先导入mysql然后再以逗号分隔导出(里面有人名以空格分隔不方便使用)
然后通过宿主机传给虚拟机
(1)查看shell脚本的-help内置脚本帮助信息:
(2)统计不同年龄区间范围(20岁以下、[20-30]、30岁以上)的球员数量、百分比
cat查看文件内容,tail限制查看除第一行属性名称之外的数据,awk -F ‘,’查看以逗号分隔的某列数据,wc -l统计行数

运行结果:

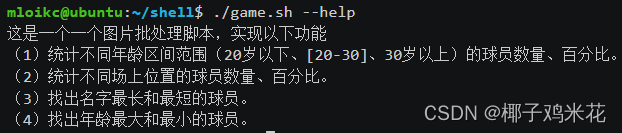
(3)统计不同场上位置的球员数量、百分比
用awk结合内部循环实现
![]()
运行结果:
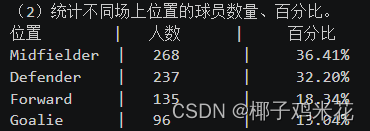
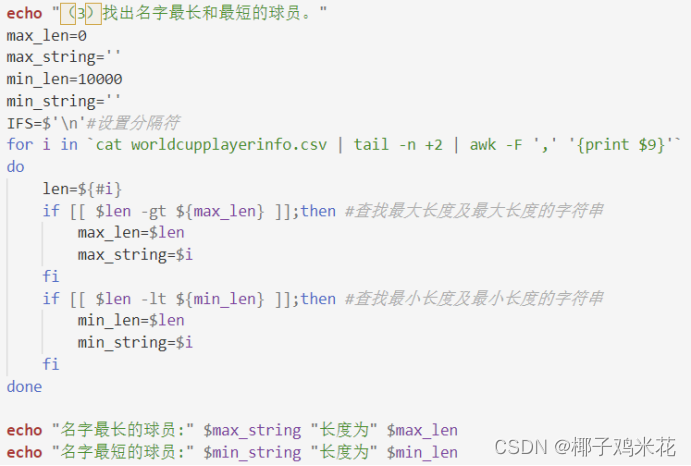
(4)名字最长的球员是谁?名字最短的球员是谁?
用for循环加条件判断实现
运行结果:

(5)年龄最大的球员是谁?年龄最小的球员是谁?
与上题类似,用for循环加条件判断实现

 运行结果:
运行结果:

完整代码:
#!/bin/bash
if [[ $1 = "--help" ]] || [[ $1 = "-h" ]]
then
echo "这是一个一个图片批处理脚本,实现以下功能"
echo "(1)统计不同年龄区间范围(20岁以下、[20-30]、30岁以上)的球员数量、百分比。"
echo "(2)统计不同场上位置的球员数量、百分比。"
echo "(3)找出名字最长和最短的球员。"
echo "(4)找出年龄最大和最小的球员。"
exit 0
fi
echo "(1)统计不同年龄区间范围(20岁以下、[20-30]、30岁以上)的球员数量、百分比。"
player_under20=`cat worldcupplayerinfo.csv | tail -n +2 | awk -F ',' '$6<20' | wc -l`
player_20to30=`cat worldcupplayerinfo.csv | tail -n +2 | awk -F ',' '$6>=20&&$6<=30' | wc -l`
player_upper30=`cat worldcupplayerinfo.csv | tail -n +2 | awk -F ',' '$6>30' | wc -l`
allplayer=`cat worldcupplayerinfo.csv | tail -n +2 | wc -l`
playerpercent_under20=`awk 'BEGIN{printf "%.2f%\n",('$player_under20'/'$allplayer')*100}'`
playerpercent_20to30=`awk 'BEGIN{printf "%.2f%\n",('$player_20to30'/'$allplayer')*100}'`
playerpercent_upper30=`awk 'BEGIN{printf "%.2f%\n",('$player_upper30'/'$allplayer')*100}'`
echo '年龄' " | " '人数' " | " '百分比'
echo '20岁以下' " | " $player_under20 " | " $playerpercent_under20
echo '[20-30]' " | " $player_20to30 " | " $playerpercent_20to30
echo '30岁以上' " | " $player_upper30" | " $playerpercent_upper30
echo "(2)统计不同场上位置的球员数量、百分比。"
echo '位置' " | " '人数' " | " '百分比'
cat worldcupplayerinfo.csv | tail -n +2 | awk -F ',' '{arr[$5]+=1} END{for (i in arr) {printf "%-12s|\t%-10d|\t%.2f%\n",i,arr[i],(arr[i]/'$allplayer')*100} }'
echo "(3)找出名字最长和最短的球员。"
max_len=0
max_string=''
min_len=10000
min_string=''
IFS=$'\n'#设置分隔符
for i in `cat worldcupplayerinfo.csv | tail -n +2 | awk -F ',' '{print $9}'`
do
len=${#i}
if [[ $len -gt ${max_len} ]];then #查找最大长度及最大长度的字符串
max_len=$len
max_string=$i
fi
if [[ $len -lt ${min_len} ]];then #查找最小长度及最小长度的字符串
min_len=$len
min_string=$i
fi
done
echo "名字最长的球员:" $max_string "长度为" $max_len
echo "名字最短的球员:" $min_string "长度为" $min_len
echo "(4)找出年龄最大和最小的球员。"
oldest=0
youngest=200
oldest_name=''
youngest_name=''
IFS=$'\n'#设置分隔符
for i in `cat worldcupplayerinfo.csv | tail -n +2 | awk -F ',' '{print $6}'`
do
if [[ $i -gt $oldest ]];then #查找最大长度及最大长度的字符串
oldest=$i
fi
if [[ $i -lt $youngest ]];then #查找最小长度及最小长度的字符串
youngest=$i
fi
done
oldest_name=`cat worldcupplayerinfo.csv | tail -n +2 | awk -F ',' '$6=='$oldest' {ORS=",";print $9}'`
youngest_name=`cat worldcupplayerinfo.csv | tail -n +2 | awk -F ',' '$6=='$youngest' {ORS=",";print $9}'`
echo "年龄最大的球员:" $oldest_name $oldest "岁"
echo "年龄最小的球员:" $youngest_name $youngest "岁"3.用bash编写一个文本批处理脚本,对以下附件分别进行批量处理完成网络安全保护相关的数据统计任务:
- 统计访问来源主机TOP 100和分别对应出现的总次数。
- 统计访问来源主机TOP 100 IP和分别对应出现的总次数。
- 统计最频繁被访问的URL TOP 100。
- 统计不同响应状态码的出现次数和对应百分比。
- 分别统计不同4XX状态码对应的TOP 10 URL和对应出现的总次数。
- 给定URL输出TOP 100访问来源主机。
参考:shell脚本编程基础 | 烏巢 (hejueyun.github.io)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









