







- 实验题目
数据可视化
- 实验目的
掌握数据分析中基本的绘图⽅法,包括:
1. 使⽤ matplotlib 、 Pandas 、 Seaborn 和 plotly 包绘制图形。
2. 掌握散点图、折线图、柱状图、直⽅图、箱线图等图形的绘制、分析。
三、实验内容与实现
实验要求1:
1. 绘制吉林省C、D两个模型按点击日期的点击数散点图。
2. 绘制全国每个模型按模型日期的成交数散点图。
3. 请选择任一绘图方法,给出计算、绘图的语句,连同输出结果截图及简要的分析写入实验报告。
程序代码:
1.
# 引⼊包
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from plotly.offline import iplot, init_notebook_mode
import plotly.express as px
# 设置plotly
init_notebook_mode(connected=True)
#中文显示问题
plt.rcParams['font.sans-serif']=['Simhei']
#符号显示问题
plt.rcParams['axes.unicode_minus'] = False # 显示负号
# 加载数据
dfModelData = pd.read_csv('./labs/model_data.csv', header=0,
parse_dates=['model_date', 'click_date'],
dtype={'p_id': 'str_'})
# 获取吉林省所有模型的统计数据
dfJLModel = dfModelData.groupby(['model_id', 'p_id', 'model_date']).sum(
).reset_index().query("p_id=='0090'")
# 获取CD模型数据
dfJLModelC = dfJLModel.groupby(['model_id', 'model_date']).sum(
).reset_index().query("model_id=='C'")
dfJLModelD = dfJLModel.groupby(['model_id', 'model_date']).sum(
).reset_index().query("model_id=='D'")
plt.figure(figsize=(10, 6))
#中文显示问题
plt.rcParams['font.sans-serif']=['Simhei']
#符号显示问题
plt.rcParams['axes.unicode_minus'] = False # 显示负号
plt.scatter(dfJLModelC.model_date, dfJLModelC.clicks, marker='o', c='orange', label='C')
plt.scatter(dfJLModelD.model_date, dfJLModelD.clicks, marker='o', c='red', label='D')
plt.xlabel('⽇期')
plt.ylabel('数量')
plt.legend()
plt.xticks(rotation=45)
plt.show()
2.
px.scatter(dfModelData.groupby(['model_id', 'model_date']).sum(
).reset_index(), x='model_date', y='succs', color='model_id',
size='succs', title='全国各模型成交数统计', width=1000, height=600)
实验结果:
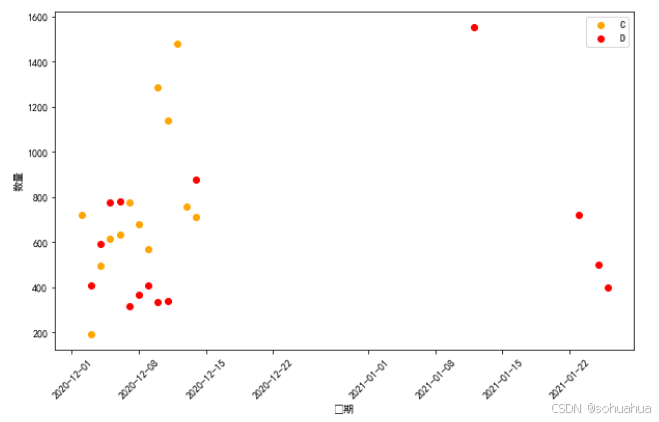
1.
2.
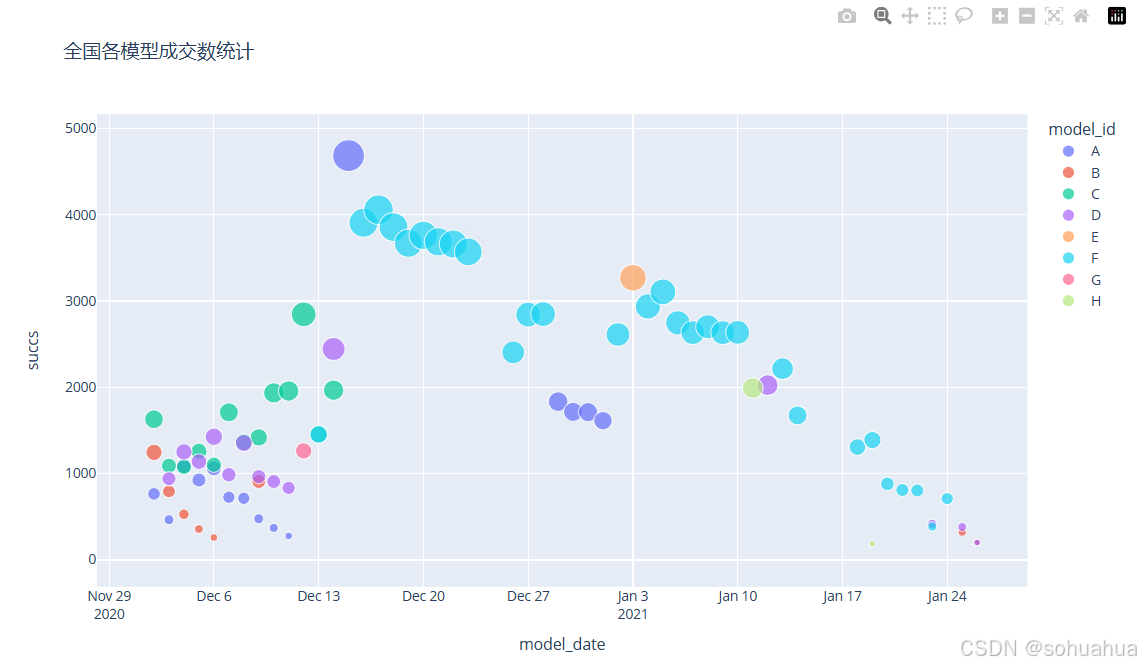
简要分析:
使用plotly绘制散点图,从上述图中可以看出每个模型的成交数分布。每个模型使⽤了不同的颜色加以区分,同时根据具体的成交数多少绘制了大小不等的点。模型F从数量上看成交数较多,说明F模型的效果相较其它模型要好一些
实验要求2:
1. 绘制吉林省C、D两个模型按点击日期的点击数折线图。
2. 绘制全国每个模型按模型日期的成交数折线图。
3. 请选择任一绘图方法,给出绘图的语句,连同输出结果截图写入实验报告。
程序代码:
1.
ax = dfJLModelC.plot(kind='line', x='model_date', y='clicks', marker='o', color='orange', label='C', figsize= (20, 8))
dfJLModelD.plot(kind='line', x='model_date', y='clicks', marker='o', color='blue', label='D',ax=ax)
plt.xlabel('date')
plt.ylabel('数量')
plt.xticks(rotation=45)
plt.title('吉林省CD模型点击数折线图')
plt.show()
2.
dfModelDataA = dfModelDataALL.groupby(['model_id', 'model_date']).sum(
).reset_index()
px.line(dfModelDataA, x='model_date', y='succs', color='model_id',
title='全国各模型成交数统计', width=1000, height=600)
实验结果:
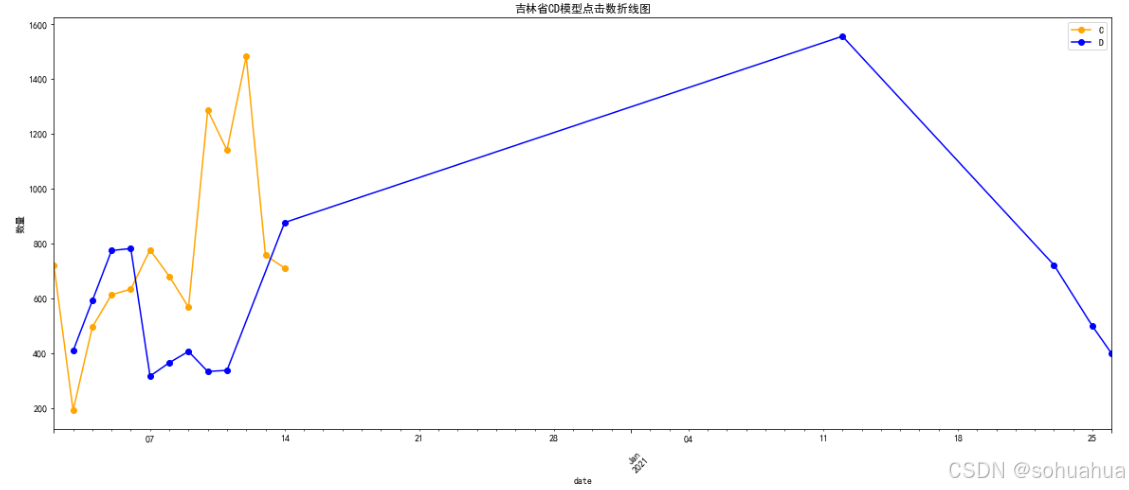
1.
2.
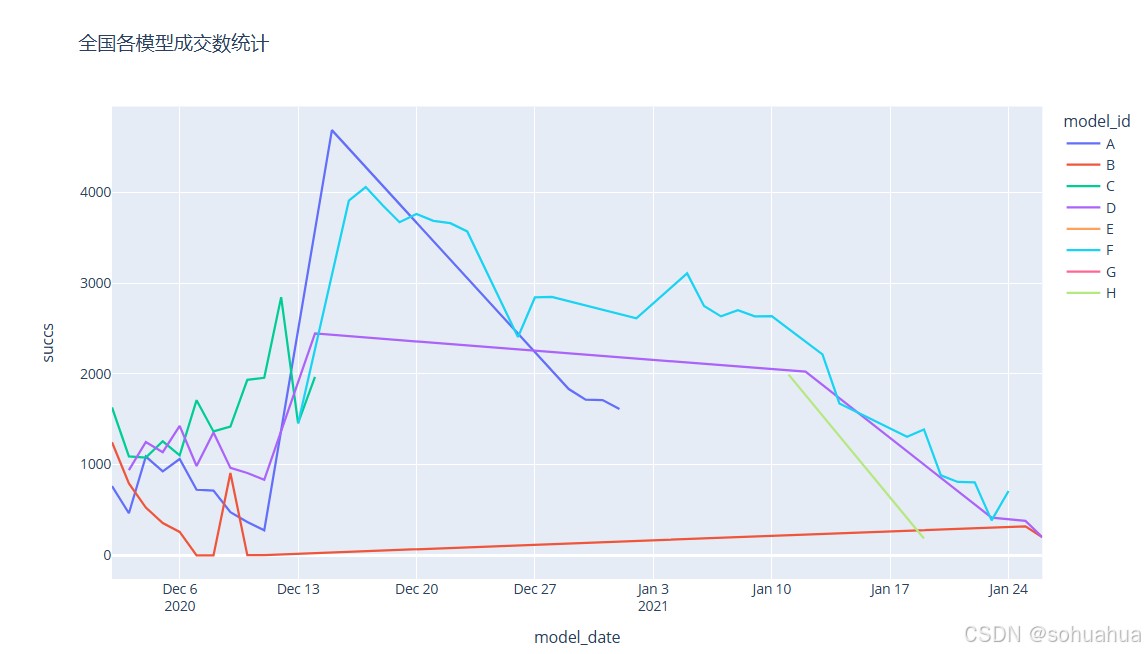
简要分析:
从图中看到B模型的成交量基本最少,A、F模型处于优势状态。
实验要求3:
请选⽤任⼀绘图⽅法绘制A模型各省市成交数对⽐条形图。
程序代码:
# 获取A模型数据
dfModelA = dfModelData.groupby(['model_id','p_name']).sum(
).reset_index().query("model_id=='A'")
px.bar(data_frame=dfModelA,
x='p_name', y='succs',
title='A模型各省市成交数对⽐条形图',
width=800, height=500)
实验结果:
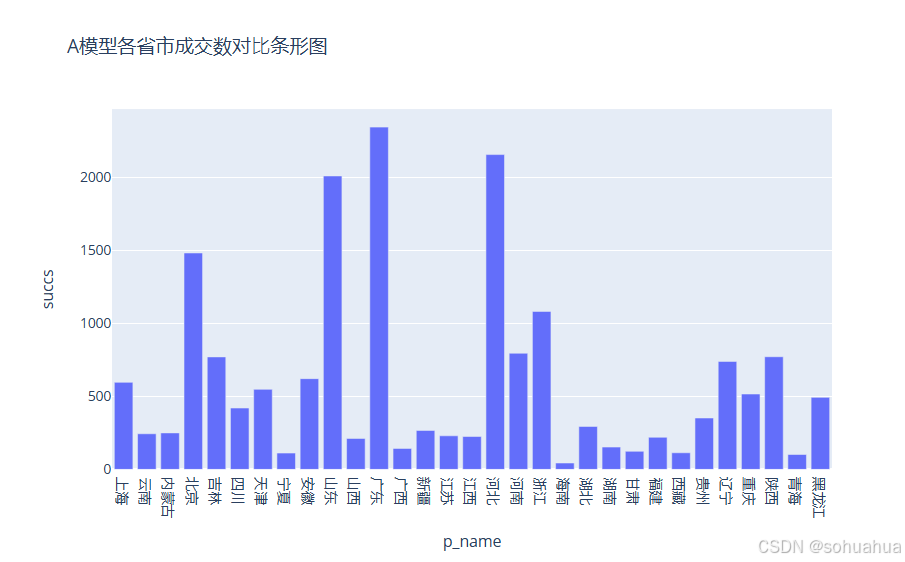
简要分析:
A模型成交数对比图可以直观看到:广东、河北、山东、北京、浙江为前五城市。
实验要求4:
1. 使用任一法绘制A模型成交数直方图。
程序代码:
px.histogram(data_frame=dfModelA, x='succs', nbins=30,
marginal='box', title='A模型成交数直⽅图', width=800, height=600)
实验结果:
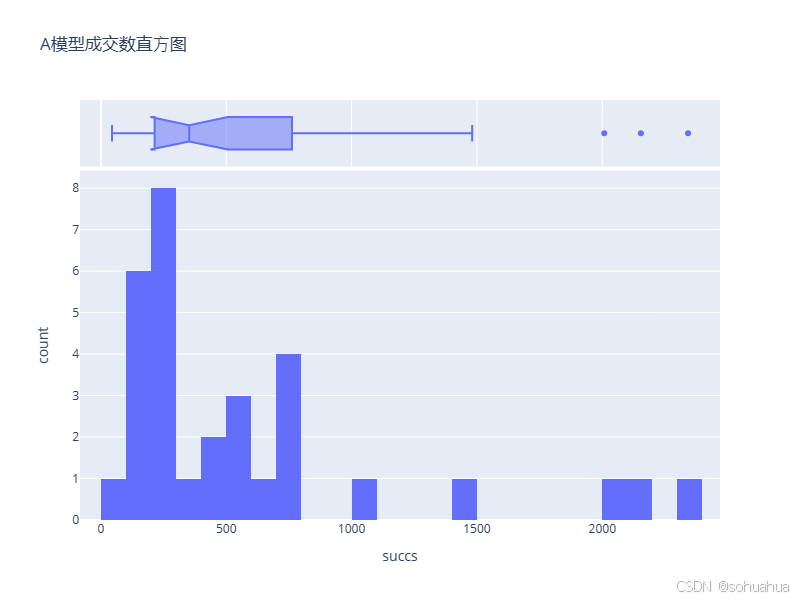
简要分析:
从结果可以看出,[200,299]这三段的点击数最多,2000以上有两个异常值。
5.实验要求5:
1. 请选⽤任⼀⽅法绘制A模型各省市点击数箱线图。
程序代码:
dfModelAA = dfModelData.groupby(['model_id','p_name','model_date']).sum().reset_index().query("model_id=='A'")
px.box(data_frame=dfModelAA, x='p_name', y='clicks', width=800, height=600)
实验结果:
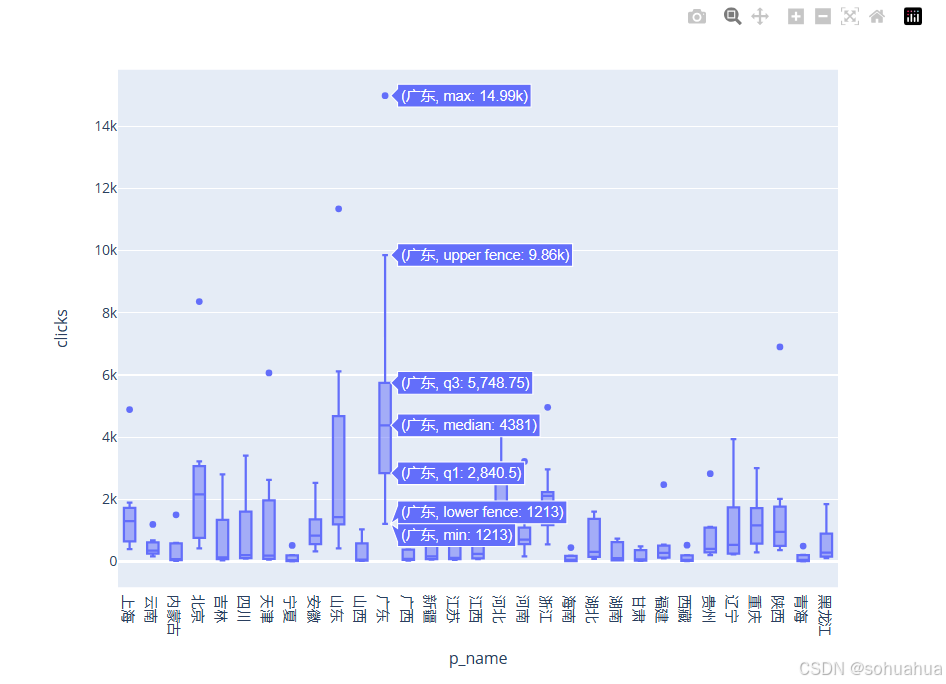
简要分析:从上图可以看出,广东的最大值为14.99k,最小值为1213,中位数为4381。对比所有城市,广东的中位数是最大的。
四、实验心得
在本次实验中,我学习了如何使用matplotlib、Pandas、Seaborn和plotly等包来绘制数据可视化图形。通过实践,我掌握了散点图、折线图、柱状图、直方图和箱线图等常见图形的绘制方法和分析技巧。
在绘制散点图时,我可以通过scatter函数将数据点按照坐标位置绘制出来,从而观察变量之间的关系和趋势。折线图可以通过plot函数绘制,对于时间序列数据的可视化非常有用。柱状图可以通过bar函数绘制,可以直观地比较不同类别之间的差异。直方图可以通过hist函数绘制,用于展示数据的分布情况。箱线图可以通过boxplot函数绘制,可以显示数据的中位数、四分位数和异常值,有助于发现数据的异常情况。
在实验过程中,我发现数据可视化对于数据分析非常重要。通过图形化展示数据,我可以更好地理解数据的特征和规律,从而做出更准确的分析和决策。同时,选择合适的图形形式和颜色搭配也是很重要的,可以使得图形更加清晰和易于理解。
总的来说,本次实验让我对数据可视化有了更深入的了解和掌握。通过练习和实践,我相信我可以更好地应用数据可视化技术来分析和解释数据。


















 7249
7249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









