






引言
本文主要是对基于MaxKB的知识库问答系统二次开发前的部署过程记录,之前在Ubuntu虚拟机上进行部署时因为虚拟机上对显卡的限制,尝试在Windows环境的部署。
本文中主要涉及内容包括:
- Postgresql数据库的安装。
- Postgresql数据库的vector拓展的配置。
- Python环境搭建。
- 源码启动MaxKB项目。
- Windows下Ollama的安装及大模型的拉取。
- MaxKB对接Ollama模型,尝试得到简易的知识库问答系统。
相关链接:
MaxKB官方部署指南
MaxKB项目地址
Postgresql下载地址
pgvector项目地址
Ollama下载地址
一、Postgresql数据库的安装
1. 安装过程
Postgresql各版本下载地址:Postgresql
在当前最新版本MaxKB中,建议使用的是Postgresql15.x版本,本文即下载Postgresql15.10。
Windows下的Postgresql安装较为简单,基本上一直Next即可:
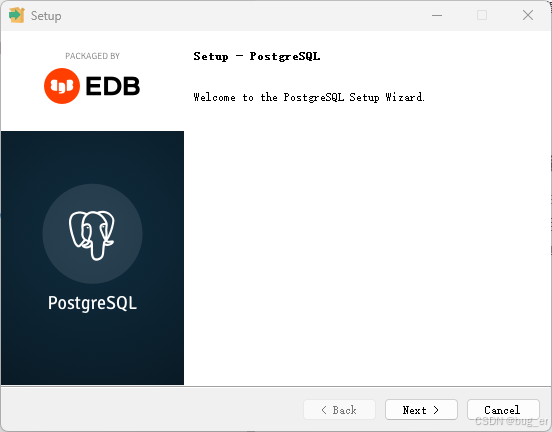
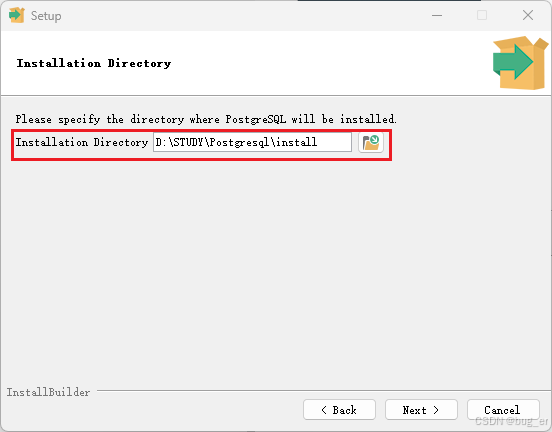
选择安装目录:
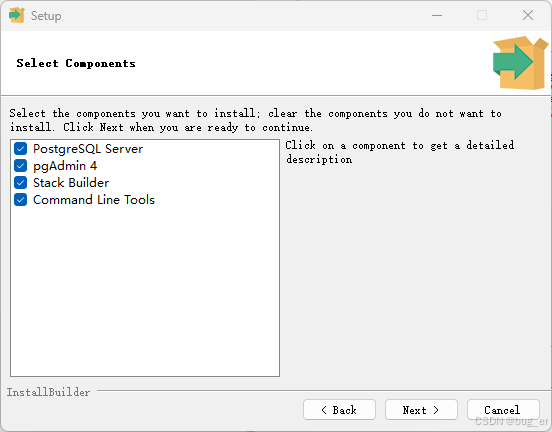
选择数据存储目录(默认即可):
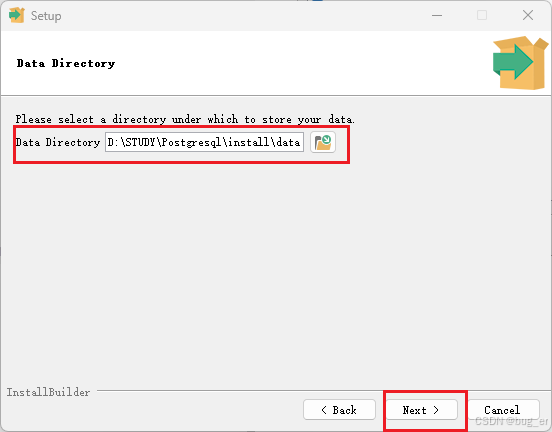
设置管理员密码(务必记住):
设置端口(默认5432,建议不修改,保持与MaxKB配置文件中一致):
选择地区:
点击Next,开始安装(需要一定时间):
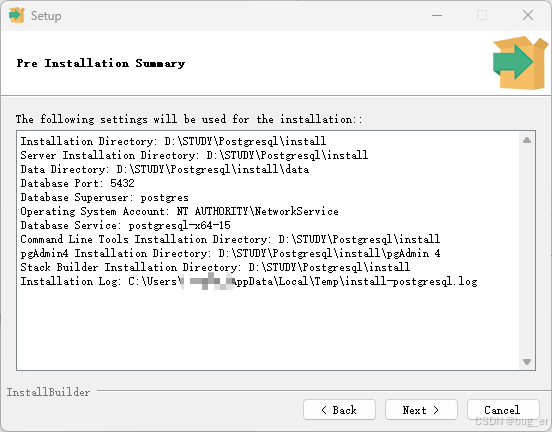
注意,在安装过程中可能出现如下警告:
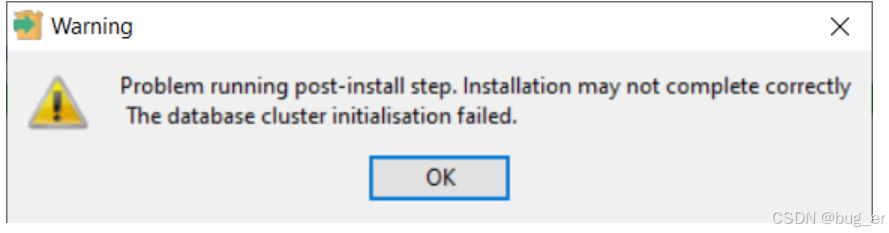
进行下面的步骤(为方便运行,可以在这里先进行下面的第二步,配置环境变量后方便一些,否则这一步的命令要在bin下面运行):
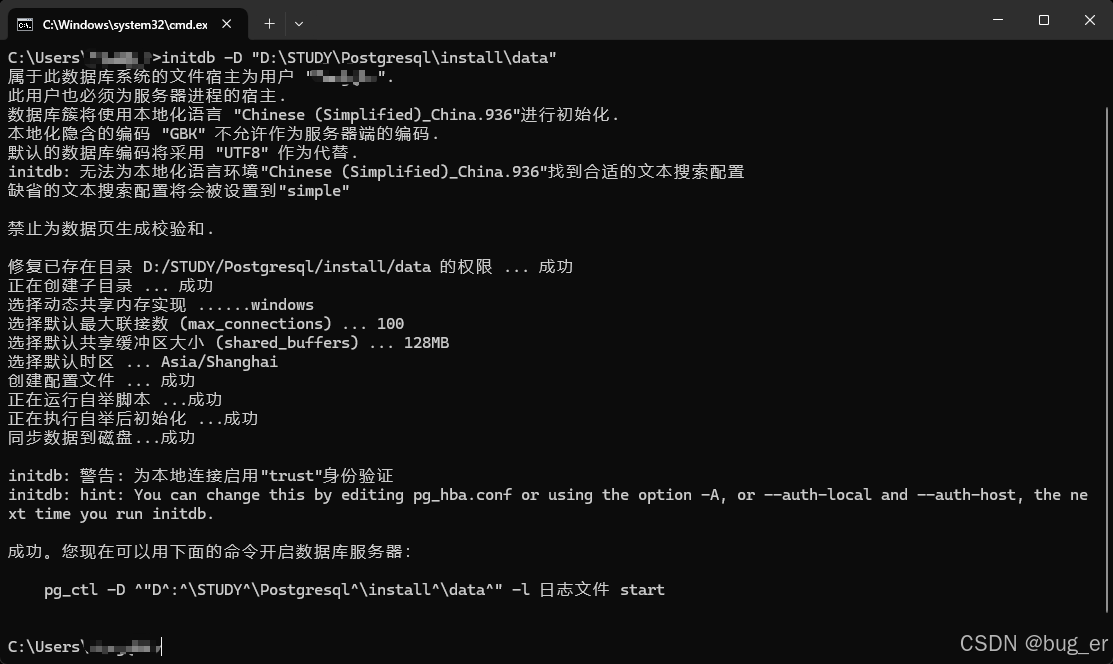
进入到前面指定的安装目录下的数据文件夹,发现为空,此时没有初始化数据库信息。

初始化数据库信息:
initdb -D "D:\STUDY\Postgresql\install\data"
(其中的D:\STUDY\Postgresql\install\data为安装时选择的数据文件路径)
启动服务 (注意输入自己的路径):
pg_ctl start -D "D:\STUDY\Postgresql\install\data" -l logfile

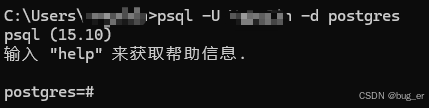
这个时候还没有postgres信息,手动创建 postgres 角色(这里的已存在的超级用户就是自己电脑用户,也就是C:\User\xxx的xxx):
psql -U <其他已存在的超级用户> -d postgres
创建角色并设置密码:
CREATE ROLE postgres WITH SUPERUSER LOGIN PASSWORD 'yourpassword';
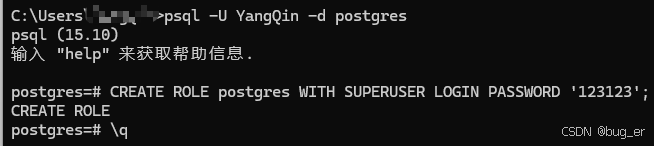
即进入了postgresql的命令行界面并创建了postgres角色,后面配置MaxKB时也是使用postgres角色,输入\q以退出;
登录验证:
psql -U postgres -d postgres
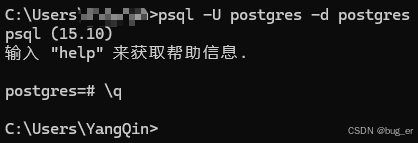
在命令行中运行以下命令列出当前的数据库:
psql -U postgres -l

2. 设置环境变量
找到Postgresql安装目录,复制bin文件路径:(样例:D:\STUDY\Postgresql\install为我的安装目录,复制路径D:\STUDY\Postgresql\install\bin)
桌面右键 此电脑 -> 属性 -> 高级系统设置 -> 环境变量,双击系统变量中的Path变量,新建,填入Postgresql安装目录下的bin目录:
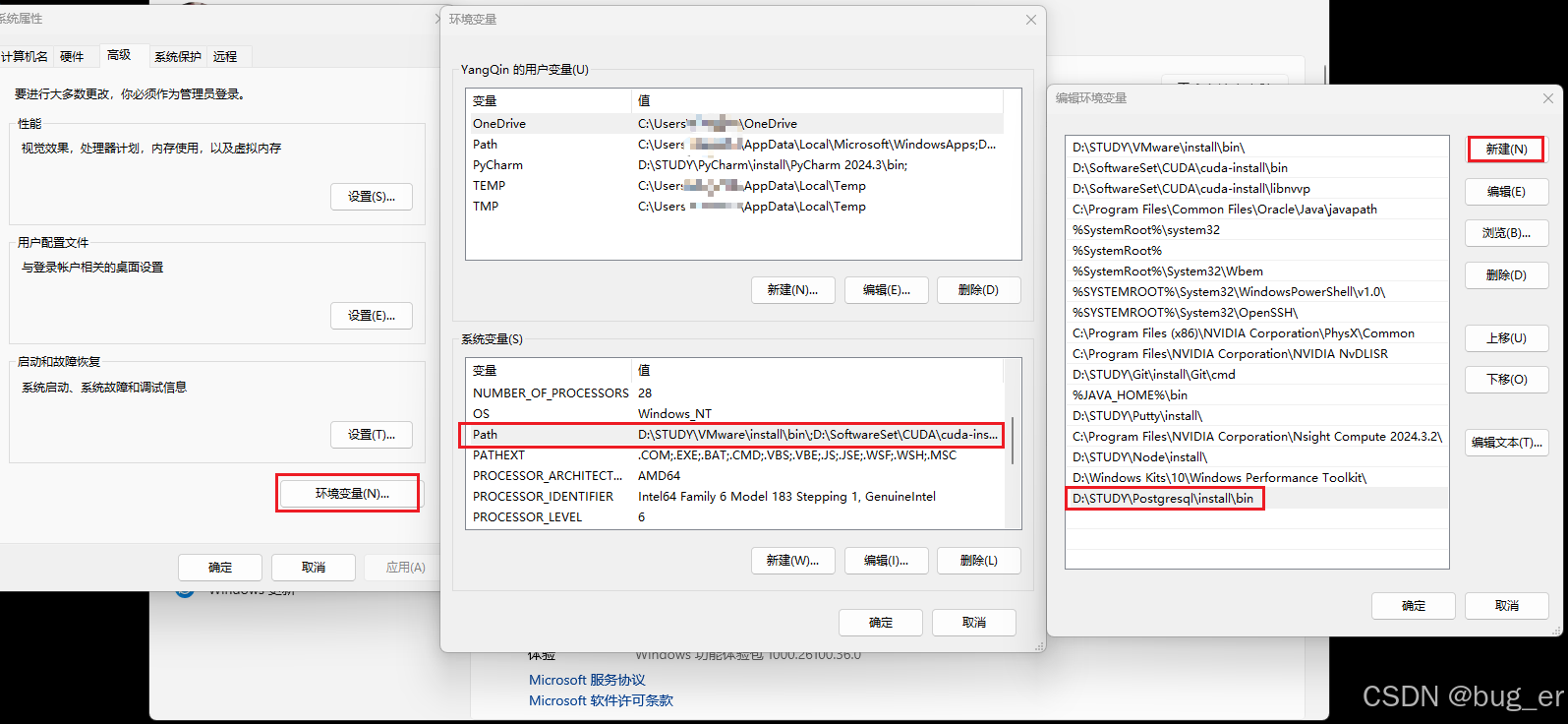
依次点击确定。
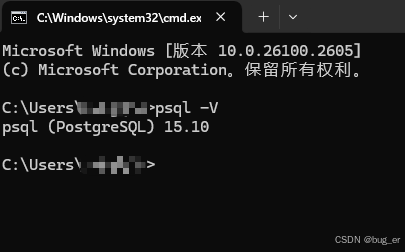
3. 验证
win+R,任意位置打开cmd窗口,输入:
psql -V
输出得到Postgresql版本信息,即安装成功。
4. 注册 PostgreSQL 为 Windows 服务(非必要)
在我的电脑上,发现在services.msc服务中没有postgresql服务,这导致每次重启电脑后需要使用命令pg_ctl start -D "D:\STUDY\Postgresql\install\data" -l logfile手动启动,所以这一步骤就在Windows上创建这个服务。以便后面启动。
如果希望 PostgreSQL 在电脑重启后自动启动,需要将其注册为 Windows 服务。
创建服务:(注意这里需要使用管理员启动cmd,否则可能会出现:pg_ctl: 无法打开服务管理器)
pg_ctl register -N Postgresql -D "D:\STUDY\Postgresql\install\data"
net start Postgresql # 启动Postgresql服务
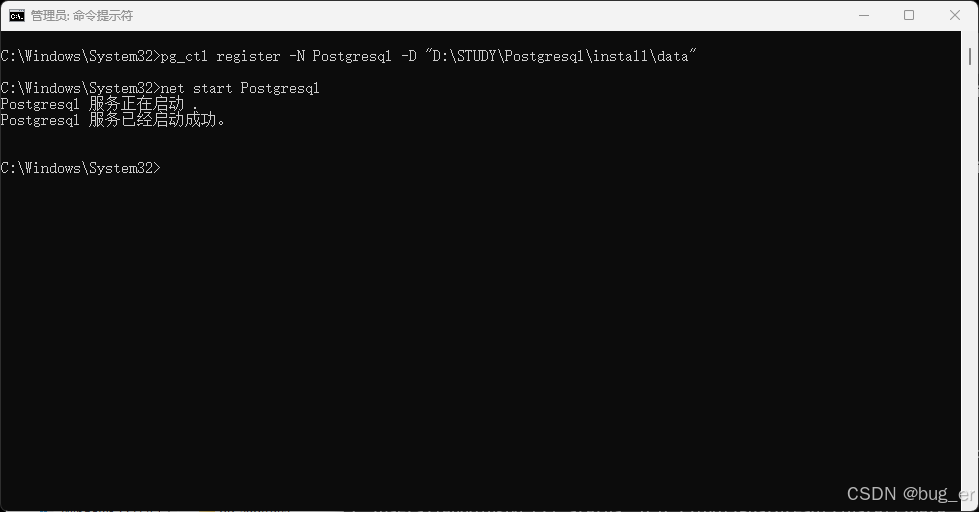
此时就能在Windows的服务中看到已经创建了Postgresql服务。
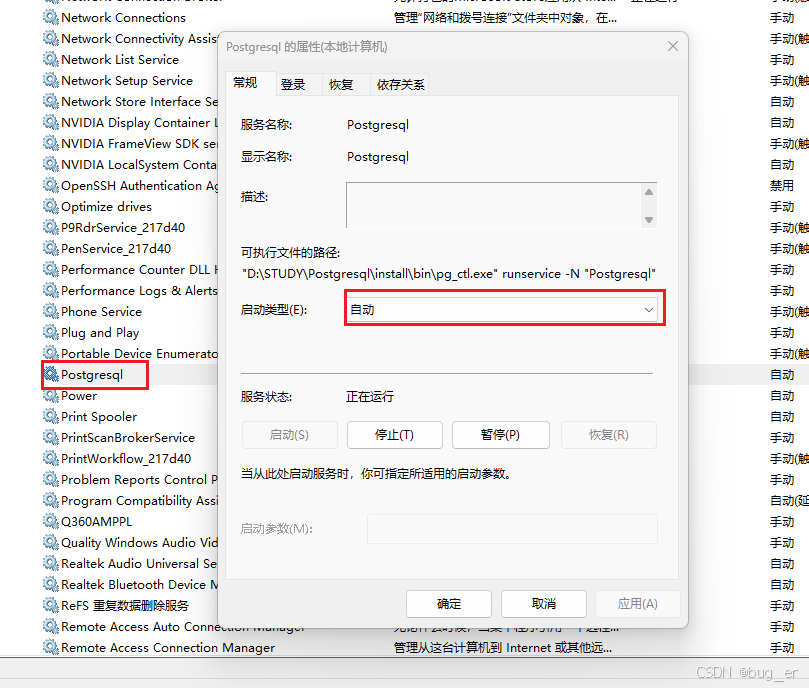
这里可以右键 -> 属性,将其设置为自动,在之后重启电脑,这个服务依旧在运行(如果不希望闲时占用内存,可以设置手动,通过net start Postgresql启动)。
二、pgvector向量数据插件的配置
由于后期使用MaxKB时,Postgresql需要配置vector拓展,这里先行安装配置。
注意: 这里需要用到make工具进行编译。
1. 拉取pgvector项目
在github上的pgvector项目地址拉取代码,建议拉取位置为Postgresql安装目录的上级目录(样例:D:\STUDY\Postgresql\pgvector)。
git clone git@github.com:pgvector/pgvector.git
2. 编译vector插件
因为我这里已经下载安装过Visual Studio 2022,这里直接使用Visual Studio安装好的make工具。
在拉取到的pgvector目录下打开cmd命令行窗口(输入cmd,回车):
在命令行窗口依次输入以下命令:
注意:以下命令执行时所处的路径为拉取的pgvector的路径:
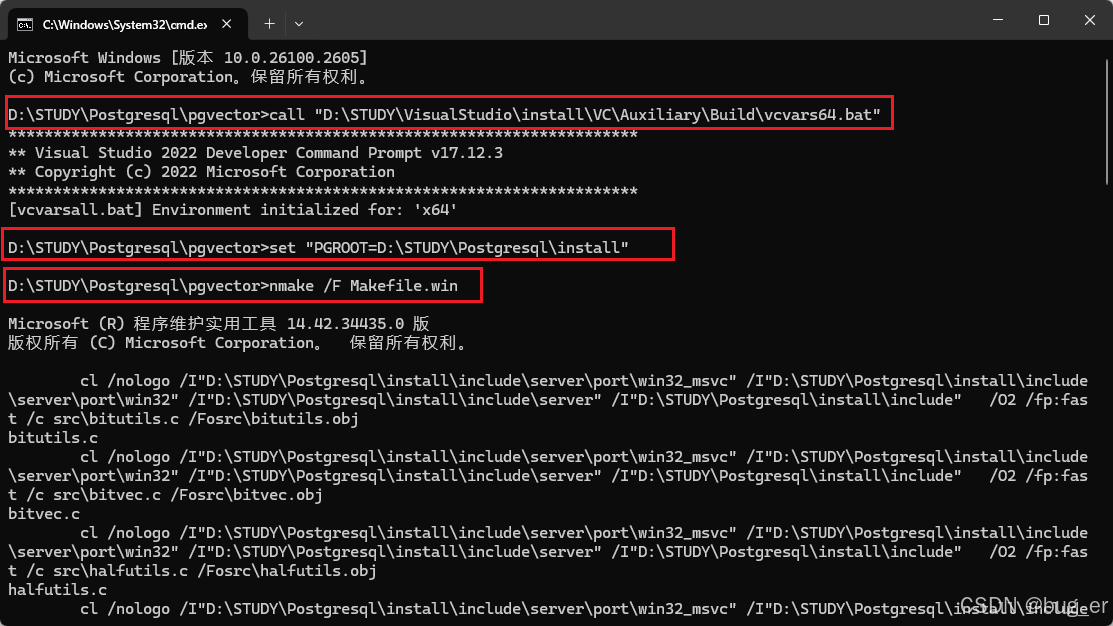
call "D:\STUDY\VisualStudio\install\VC\Auxiliary\Build\vcvars64.bat"
set "PGROOT=D:\STUDY\Postgresql\install"
nmake /F Makefile.win
nmake /F Makefile.win install
以上命令中:D:\STUDY\VisualStudio\install\VC\Auxiliary\Build\vcvars64.bat为我电脑上的vcvars64.bat的路径;PGROOT=D:\STUDY\Postgresql\install为Postgresql的安装路径(如果采用默认路径安装,则这里结尾应该是xxx\PostgreSQL\16)
在执行最后一条命令时,可能会由于权限问题报错:
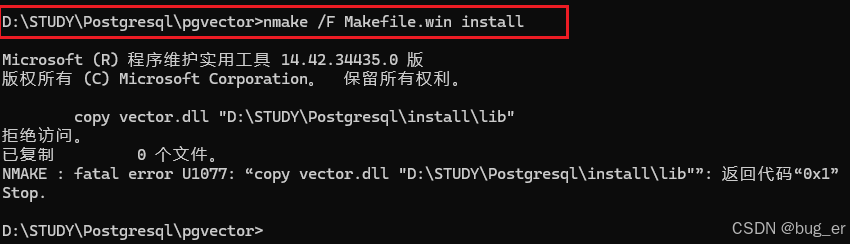
原因是不能把生成的vector.dll复制到 \Postgresql\install\lib 中,这个时候手动复制粘贴即可(即将在pgvctor目录中新生成的vector.dll复制到Postgresql中的lib目录下);
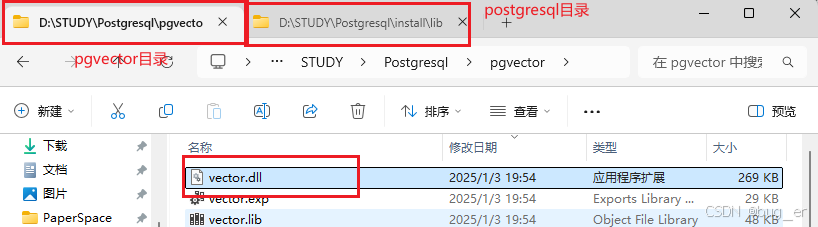
此时完成了Postgresql安装和pgvector向量数据插件即完成了。
三、python环境搭建
1. conda虚拟环境搭建
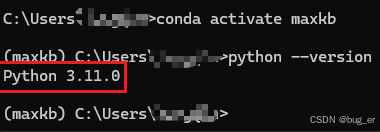
在MaxKB官方文档中推荐的python版本为3.11.x,因此使用Anaconda新建MaxKB专属的虚拟环境。
conda create --name maxkb python==3.11
2. 拉取MaxKB项目源代码
git clone git@github.com:1Panel-dev/MaxKB.git
根据自己的编程习惯,本教程使用的IDE为Pycharm Professional;
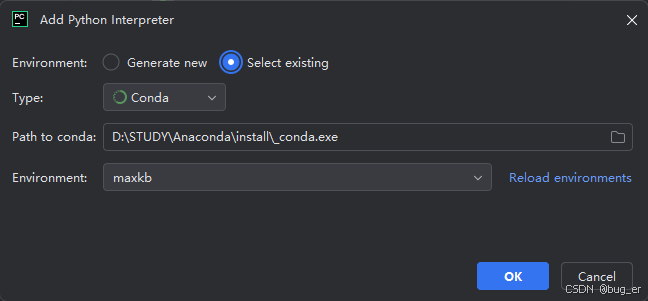
打开Pycharm设置,
搜索Interpreter,右侧点击Add Interpreter,添加并应用刚刚创建的maxkb虚拟环境(这一步 每个人配置的方式可能不一样,只要能切换到虚拟环境即可)。
3. 依赖下载
项目的依赖下载需要分别下载前端和后端依赖。这里先介绍前端依赖。
前端依赖
MaxKB项目的前端项目位于ui目录下,这里使用Pycharm自带的Terminal进入ui目录(和cmd一样的,如果使用cmd,记得切换虚拟环境):
cd .\ui\
安装依赖需要使用较新版本的npm,我这里使用的node.js版本为22.12.0,npm版本为10.9.0;
输入命令:
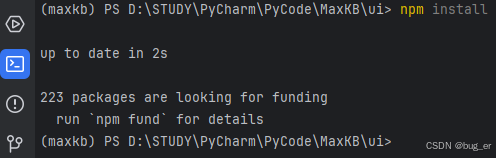
npm install
安装前端依赖(需要一定时间),需要注意目录信息,是在MaxKB项目的ui目录下。
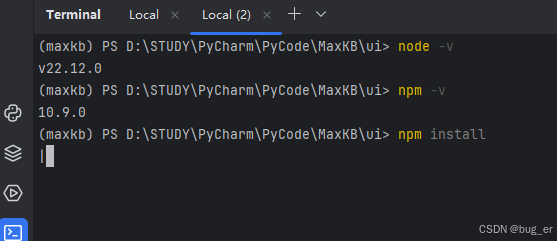
等待依赖安装,结束后可按上键再次执行npm install,有以下信息即前端依赖安装完成。
后端依赖
由于这里已经使用了Pycharm,就不再像官方文档中一样创建venv了,如果需要,可以前往官方部署文档查看。
在Pycharm中新开Terminal,使用conda或者pip安装poetry包管理器。
Note:在这一步,我是创建了一个新的虚拟环境maxkb,python版本为3.11.11,之后的安装环境都是在maxkb虚拟环境下进行的。
conda install poetry
(可能在这里使用conda安装poetry会升级python的版本,只要维持在3.11.x版本内没关系。样例:3.11.0 -> 3.11.11);
使用poetry -V可以查看版本信息并确认安装了poetry:

使用命令安装后端相关依赖:
注意命令路径在项目根路径下(即MaxKB目录下):
poetry install

Note,如果输入poetry install命令后报错:The Poetry configuration is invalid: - [source.0] Additional properties are not allowed (‘priority’ was unexpected);则进入项目根目录下的pyproject.toml文件,将最后一行的priority = "explicit"注释掉:
...
[[tool.poetry.source]]
name = "pytorch"
url = "https://download.pytorch.org/whl/cpu"
# priority = "explicit"
安装依赖过程需要一定时间。
四、源码启动MaxKB项目
1. 配置项
复制项目根目录下的config_example.yml到**D:\opt\maxkb\conf**下,修改为如下内容(注意其中的密码为前面配置postgres角色时候自己设置的密码,我这里是123123):
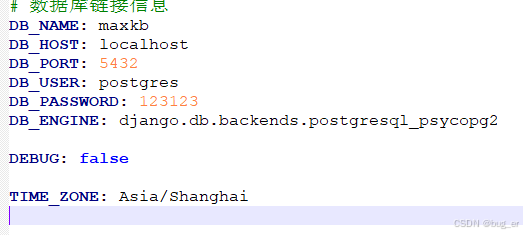
# 数据库链接信息
DB_NAME: maxkb
DB_HOST: localhost
DB_PORT: 5432
DB_USER: postgres
DB_PASSWORD: 123123
DB_ENGINE: django.db.backends.postgresql_psycopg2
DEBUG: false
TIME_ZONE: Asia/Shanghai
2. 配置数据库
在MaxKB项目根目录下,有installer文件夹帮助部署,其中有一个init.sql,内容如下:
CREATE DATABASE "maxkb";
\c "maxkb";
CREATE EXTENSION "vector";
需要在Postgresql中执行后才能正常启动。
3. 启动前后端项目
后端:
在MaxKB项目根目录执行命令:
python main.py dev
前端:
在MaxKB项目中ui目录下执行命令:
npm run dev
浏览器打开http://localhost:3000进入MaxKB,
用户名:admin
密码:MaxKB@123..
初次进入需要修改密码,建议与默认密码MaxKB@123..不一致,否则后续还会要求修改密码。
五、Ollama安装及拉取大模型
1. 安装
Ollama下载地址:Ollama下载
Ollama默认会安装在C盘,为了避免占用C盘空间,可以使用以下命令指定安装文件夹:
.\OllamaSetup.exe /DIR="D:\STUDY\Ollama\install"
/DIR 为指定的安装文件夹,(当然文件夹需要在OllamaSetup.exe所在目录运行)。
安装完成后可以通过命令ollama list判断Ollama是否成功安装。
ollama list
但是需要注意的是,Ollama默认拉取模型的路径在C盘,如果需要更改模型路径,则需要在系统变量中新增名为OLLAMA_MODELS变量,指向指定的模型存放路径(重启生效)。
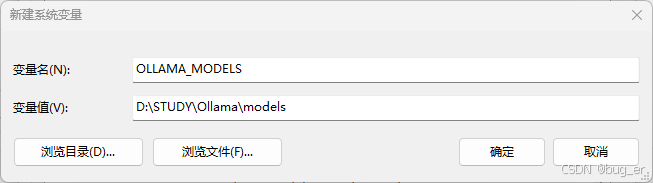
2. 拉取模型
这里以大小适中的llama3:8b模型为例,输入命令,ollama pull llama3:8b,拉取llama3:8b模型(这个过程需要下载约4.7G内容,需要一定时间):
ollama pull llama3:8b
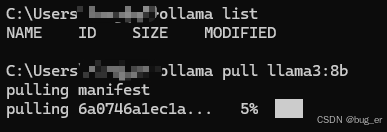
下载完成后,可以通过ollama list查看已经下载的模型,也可通过ollama run llama3:8b与模型进行对话。
六、MaxKB对接Ollama模型
浏览器进入http://localhost:3000/,即进入MaxKB主界面。
依次点击:
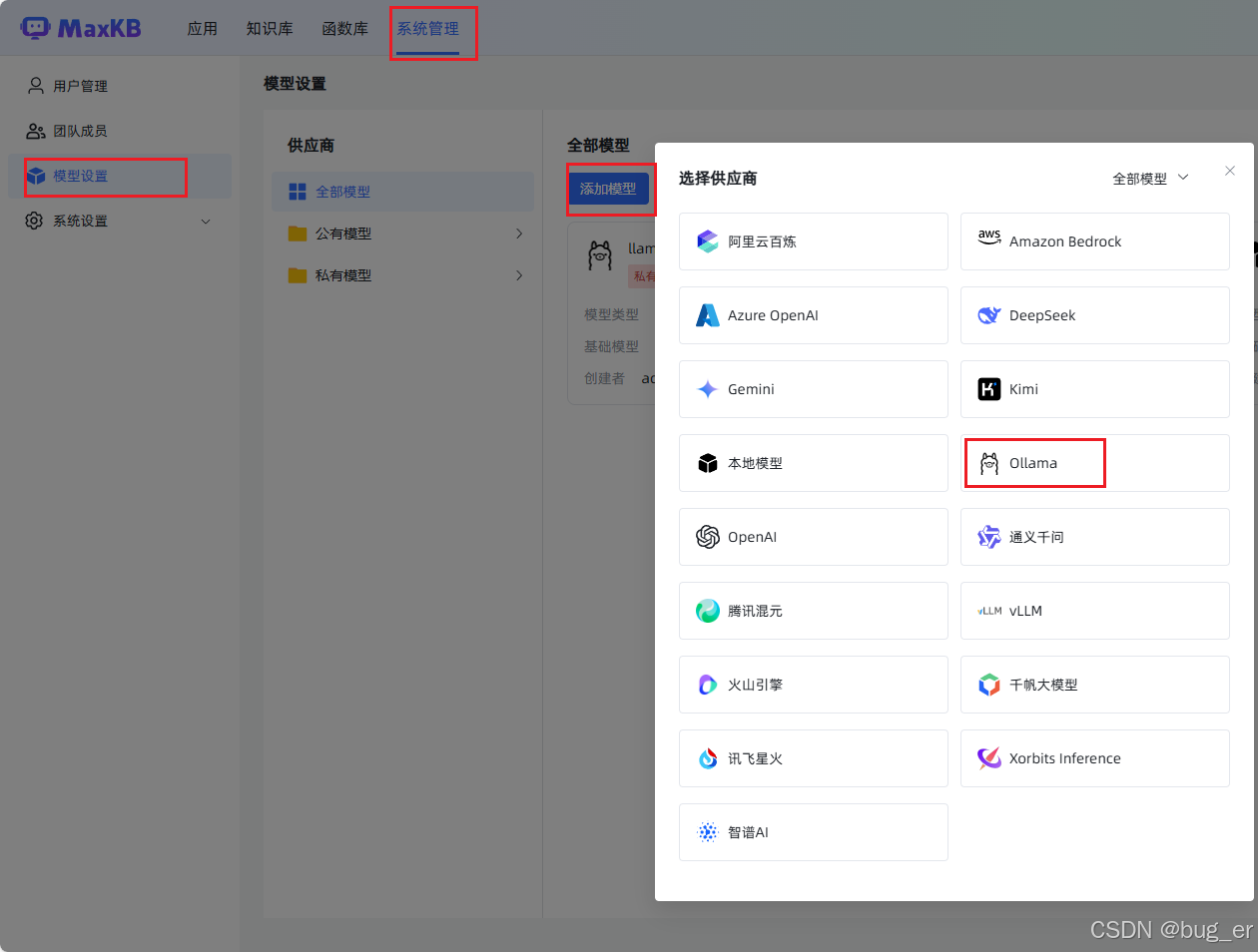
填写以下信息,添加时请保证Ollama正在运行,并且模型已经拉取。
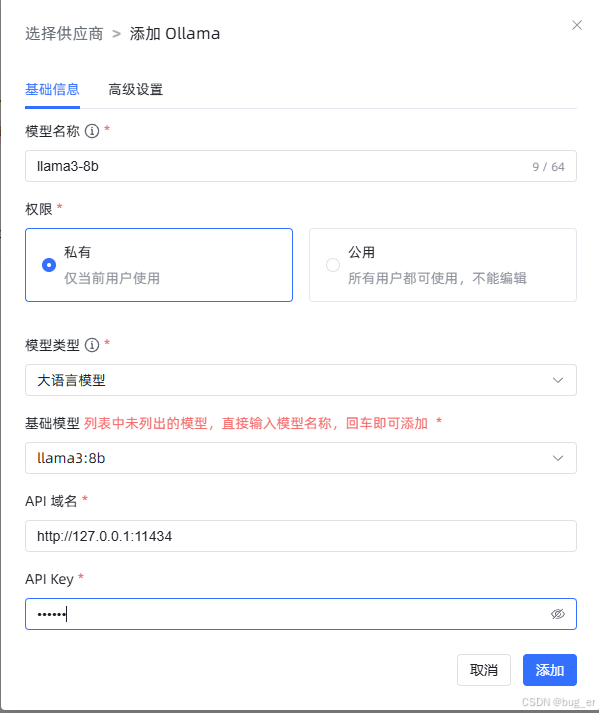
添加完成后即可看到全部模型信息,包含向量模型和llama3:8b大语言模型。
七、注意事项
- 结论:Windows下源码部署的坑很多,尝试完之后非常不建议。
- 在Postgresql安装部分,一定记得初始化数据文件夹data,以及之后使用make编译得到vector.dll,本来以为一次编译到任何机器上都能使用,重装pg发现不可行。
- 网上关于Postgresql的安装教程,乍一看安装过程就像安装QQ一样简单,但是后续的操作还有很多,包括注册服务什么的需要特别注意。
- 环境搭建部分,使用比较新的Nodejs可以很顺利的完成前端环境依赖,但是本文使用的在conda虚拟环境下安装poetry,再使用poetry安装后端依赖(这里的问题非常多,经历了换源、修改toml依赖很多操作,最后还是恢复原样,conda创建虚拟环境 -> 安装poetry ->
poetry install安装后端依赖,居然就差不多了?); - 在最后启动的部分,前端项目很好启动,使用
npm run dev即可启动。但是,在使用python main.py start时报错,提示没有pwd包,这时UNIX或者Mac环境下的用户账户信息的包,Windows下用不了,最后一些看了一些资料,说用python main.py dev可以正常运行,所以直接用python main.py dev启动吧。
报错信息如下:
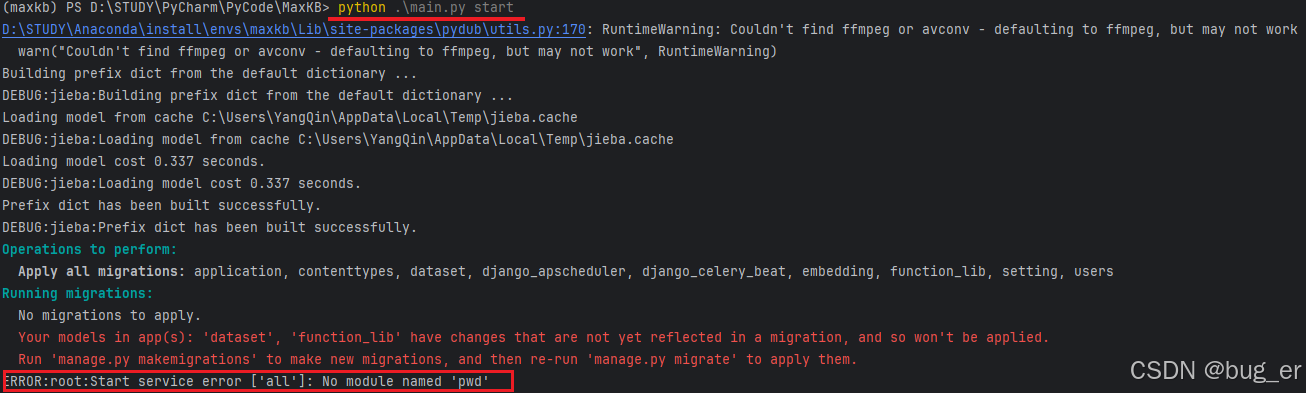
(maxkb) PS D:\STUDY\PyCharm\PyCode\MaxKB> python .\main.py start
D:\STUDY\Anaconda\install\envs\maxkb\Lib\site-packages\pydub\utils.py:170: RuntimeWarning: Couldn't find ffmpeg or avconv - defaulting to ffmpeg, but may not work
warn("Couldn't find ffmpeg or avconv - defaulting to ffmpeg, but may not work", RuntimeWarning)
Building prefix dict from the default dictionary ...
DEBUG:jieba:Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\YangQin\AppData\Local\Temp\jieba.cache
DEBUG:jieba:Loading model from cache C:\Users\YangQin\AppData\Local\Temp\jieba.cache
Loading model cost 0.337 seconds.
DEBUG:jieba:Loading model cost 0.337 seconds.
Prefix dict has been built successfully.
DEBUG:jieba:Prefix dict has been built successfully.
Operations to perform:
Apply all migrations: application, contenttypes, dataset, django_apscheduler, django_celery_beat, embedding, function_lib, setting, users
Running migrations:
No migrations to apply.
Your models in app(s): 'dataset', 'function_lib' have changes that are not yet reflected in a migration, and so won't be applied.
Run 'manage.py makemigrations' to make new migrations, and then re-run 'manage.py migrate' to apply them.
ERROR:root:Start service error ['all']: No module named 'pwd'
奇奇怪怪。
参考文档链接
MaxKB(一):windows10搭建maxkb开发环境(劝退指南)
本地源码方式部署启动MaxKB知识库问答系统,一篇文章搞定!
本地启动项目报错: No module named ‘pwd’

















 1404
1404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









