






 本文记录了深度学习训练营中关于不同优化器的对比实验,涉及数据集划分、标准化处理和CNN网络构建。作者复习了torch库的DataLoader和random_split方法,以及解决了一个训练过程中的错误。
本文记录了深度学习训练营中关于不同优化器的对比实验,涉及数据集划分、标准化处理和CNN网络构建。作者复习了torch库的DataLoader和random_split方法,以及解决了一个训练过程中的错误。
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍦 参考文章:365天深度学习训练营-第11周:优化器对比实验(训练营内部成员可读)
- 🍖 原作者:
K同学啊|接辅导、项目定制
一. 前期准备
1. 设置GPU
与前面的一致
2. 导入数据
与p3一致
输出结果

复习了一下glob()的用法.
打印classeNames列表,显示每个文件所属的类别名称。这一次相比于上一次仔细看了列表,显示了数量,以及transform.compose()下的参数。
学习到了,需要标准化处理,以达到更容易收敛的目的。
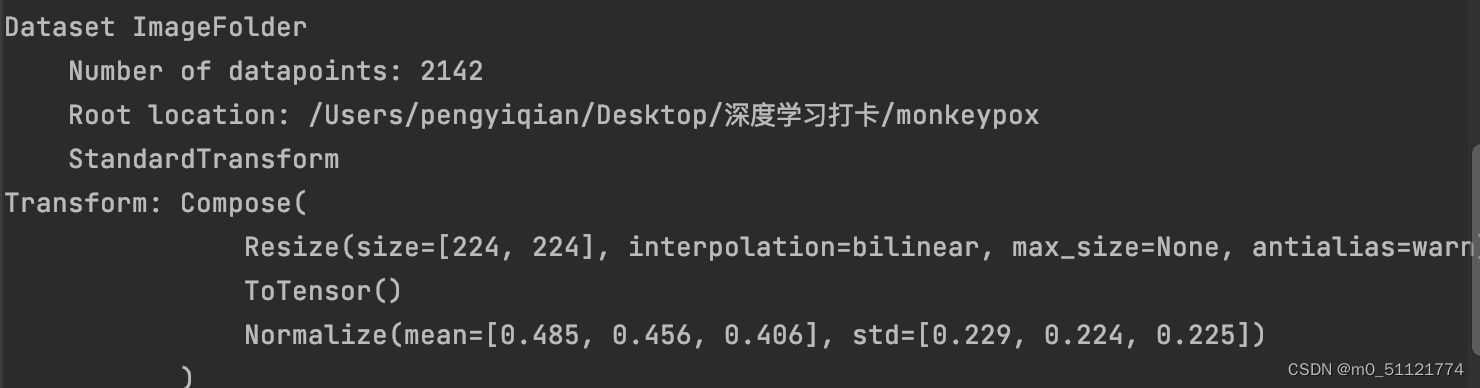

3. 划分数据集
学习到了可以直接通过len函数得到dataset创建的对象的图片总数。
本课程又介绍了一遍torch.utils.data.DataLoader()参数详解。这次根据程序推断出了输出结果是:
然后我发现了在p3忽略掉的torch.utils.data.random_split()的用法:
该方法将总体数据total_data按照指定的大小比例([train_size, test_size])随机划分为训练集和测试集,并将划分结果分别赋值给train_dataset和test_dataset两个变量。
二. 构建简单cnn网络/训练模型
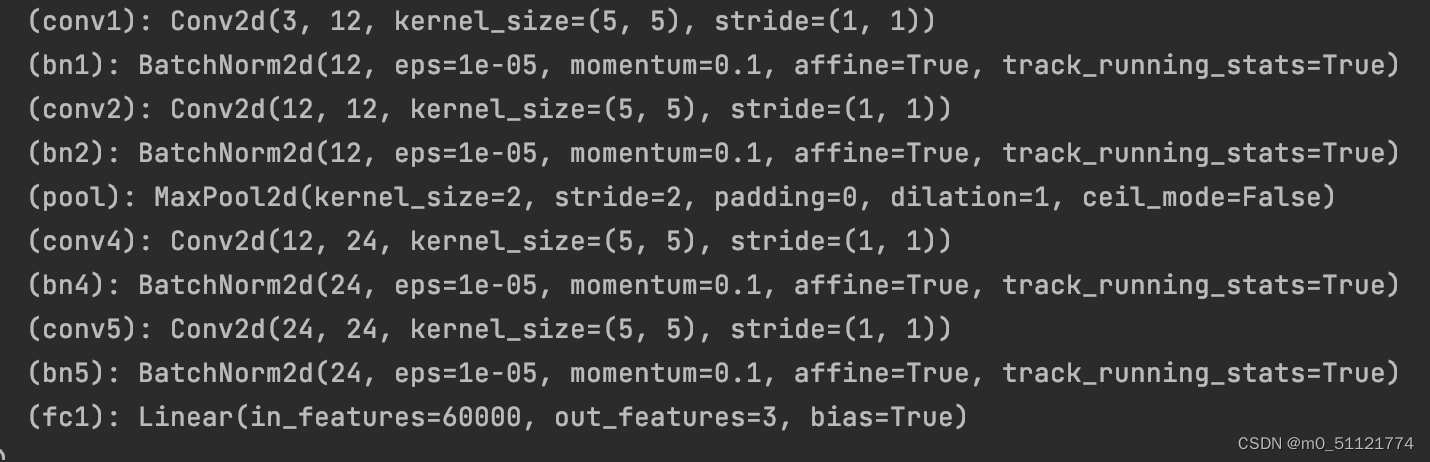
此次代码复现报错,RuntimeError:省略.. The "freeze_support()" line can be omitted if the program ...
通过加 if name == 'main': 语句,解决问题。
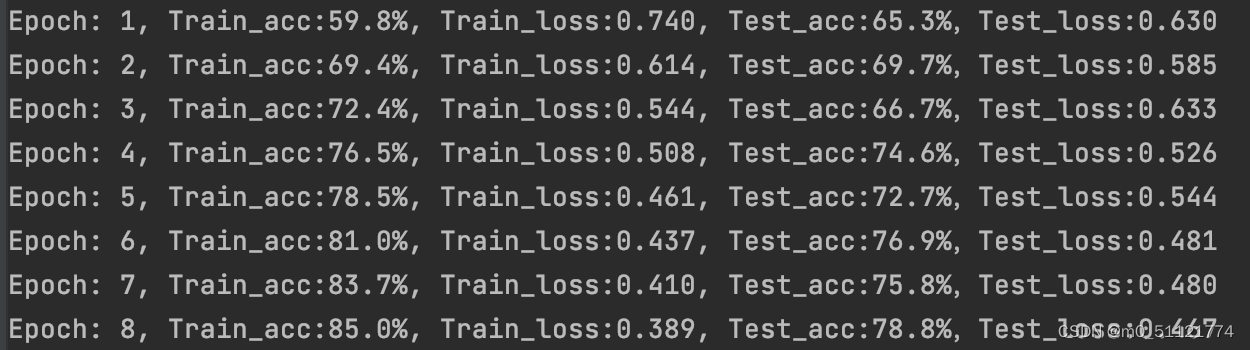
epoch划分了20个,这里仅展示8个:

















 142
142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









