






Gshard伪代码如下:
# -------------------------------------------------------------------------------------
# 1.通过gate,计算每个token去到每个expert的概率
#
# 【input】:Attention层输出的一整个batch的token,其尺寸为(seq_len, batch_size, M),
# 其中M表示token_embedding
# 【reshaped_input】:由input做reshape而来,尺寸为(S, M), 其中S = seq_len * batch_size
# 【Wg】: gate的权重,尺寸为(M, E),其中E表示MoE-layer层的专家总数
# 【gates】: 每个token去到每个expert的概率,尺寸为(S, E)
# -------------------------------------------------------------------------------------
M = input.shape[-1]
reshape_input = input.reshape(-1, M)
gates = softmax(enisum("SM, ME -> SE"), reshape_input, Wg)
# -------------------------------------------------------------------------------------
# 2. 确定每个token最终要去的top2Expert,并返回对应的weight和mask
#
# 【combine_weights】:尺寸为(S, E, C),其中C表示capacity(Expert buffer)。
# 表示对每个token(S)而言,它对每个专家(E)的weight,而这个weight按照
# 该token在buffer中的位置(C)存放,不是目标位置的地方则用0填充
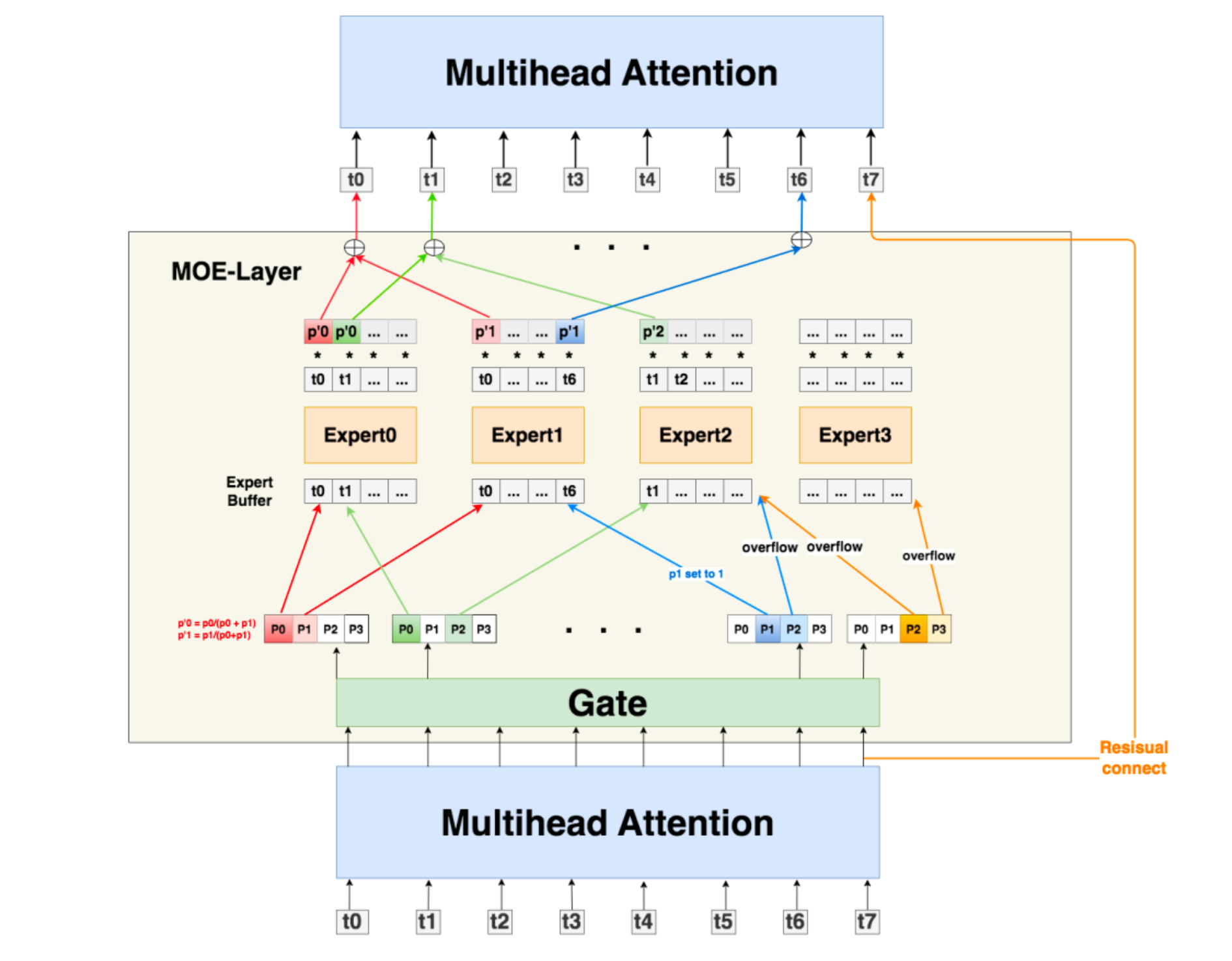
# 例如图中token1,它将被发送到expert0和expert2,且它在expert0的buffer中排在
# 1号位置,在expert2中排在0号位置,那么token1的combine_weights就是:
# [[0., p0, 0., 0.],
# [0. , 0., 0., 0.],
# [p2, 0., 0., 0.],
# [0., 0., 0., 0.]]
# 最后再复习一下weight和gates所表示的prob的区别:前者是在后者基础上,
# 做了random + normalize,确定最终的top2Expert后返回的对应结果
#
# 【dispatch_mask】: 尺寸为(S,E,C),它等于combine_weights.bool(), 也就是对combine_weights
# 为0的地方设为False,为1的地方设为True。
# dispatch_mask后续将被用在zero padding上
# -------------------------------------------------------------------------------------
# (S, E, C) (S, E, C)
combine_weights, dispatch_mask = Top2Gating(gates)
# -------------------------------------------------------------------------------------
# 3. 将输入数据按照expert的顺序排好,为下一步送去expert计算做准备(很重要)
#
# 【dispatch_mask】:尺寸为(S, E, C),定义参见2
# 【reshape_input】:尺寸为(S, M),定义参见1
# 【dispatched_expert_input】:本步的输出结果,表示按专家排序好的输入数据,尺寸为(E, C, M)
# 这个结果表示,每个专家(E)的buffer(C)下要处理的token_embedding(M),
# 例如dispatched_expert_input[0]就表示expert0 buffer中的情况
# 注意:
# (1)每个专家buffer中的token是按顺序排列好的,
# 回到图中的例子,expert0 buffer下0号位置排的是token0,
# 3号位置排的是token6,以此类推。dispatch_mask就起到了维护这种顺序的作用
# (2)当对应专家接收的token数不足buffer长度C时,不足的地方用0向量填充。
# -------------------------------------------------------------------------------------
dispatched_expert_input = einsum("SEC, SM -> ECM", dispatched_mask, reshape_input)
# -------------------------------------------------------------------------------------
# 4. 将排序好的input送入expert进行计算。
# 同正常的FFN层一样,每个expert也由2个线形层Wi, Wo组成
# 【dispatched_expert_input】:按专家顺序和专家buffer中的token顺序排好的输入数据,
# 尺寸为(E, C, M),具体定义见3
# 【Wi】:experts的Wi层,尺寸为(E,M, H),
# 【Wo】:experts的Wo层,尺寸为(E, H, M)
# 【expert_outputs】:experts的输出结果,不含加权处理,尺寸为(E, C, M)
# -------------------------------------------------------------------------------------
h = enisum("ECM, EMH -> ECH", dispatched_expert_input, Wi)
h = relu(h)
expert_outputs = enisum("ECH, EHM -> ECM", h, Wo)
# -------------------------------------------------------------------------------------
# 5. 最后,进行加权计算,得到最终MoE-layer层的输出
# -------------------------------------------------------------------------------------
outputs = enisum("SEC, ECM -> SM", combine_weights, expert_outputs)
outputs_reshape = outputs.reshape(input.shape) # 从(S, M)变成(seq_len, batch_size, M)
1. 输入维度的变化过程
Step 1: Reshape 输入
输入 (input)
input.shape = (seq_len, batch_size, M)
- 这是 Transformer 里常见的 token 表示,每个 token 有
M维的 embedding。 - 需要处理一整个 batch 的 token,因此
seq_len * batch_size表示所有 token 的总数。
变换:展开 batch 维度
reshape_input = input.reshape(-1, M) reshape_input.shape = (S, M) # 其中 S = seq_len * batch_size
为什么要这样做?
S表示所有 token 的总数,我们把所有 token 看成独立的单位,让 gating 机制独立地处理每个 token。
Step 2: 计算 gating scores
gating 权重 (Wg)
Wg.shape = (M, E) # M 维 token embedding 投影到 E 个 experts 的 logits
使用 einsum 计算 gating scores:
gates = softmax(einsum("SM, ME -> SE", reshape_input, Wg)) gates.shape = (S, E)
为什么是 (S, E)?
S个 token,每个 token 计算E个 experts 的归一化概率,决定它要去哪个 expert。
Step 3: 选择 top-2 experts 并构造 mask
Top2Gating 计算
combine_weights.shape = (S, E, C) # 每个 token 的 top-2 experts 权重 dispatch_mask.shape = (S, E, C) # 用于选择 token 进入 expert 的 mask
为什么多了一个维度 C?
C是 expert 的 buffer 容量,用于确保 tokens 在 expert 计算时按序排列。
Step 4: 分派数据到 experts
dispatched_expert_input = einsum("SEC, SM -> ECM", dispatch_mask, reshape_input) dispatched_expert_input.shape = (E, C, M)
维度变化原因:
S维度 token 被分派到E个 experts 中的C个 buffer 位置,每个 token 仍然是M维 embedding。- 这样每个 expert 处理的数据是
(C, M),即最多C个 token。
Step 5: Expert 计算
计算 hidden states
h = einsum("ECM, EMH -> ECH", dispatched_expert_input, Wi) h.shape = (E, C, H)
Wi.shape = (E, M, H),每个 expert 处理M维 embedding 并映射到H维隐层。ECH维度表示E个 experts,每个 expert 处理C个 token,输出H维隐藏层。
计算 expert 输出
expert_outputs = einsum("ECH, EHM -> ECM", h, Wo) expert_outputs.shape = (E, C, M)
Wo.shape = (E, H, M),隐藏层H映射回M维 token embedding。- 结果维度
ECM,表示每个 expert 计算后的 token 表示。
Step 6: 加权合并
outputs = einsum("SEC, ECM -> SM", combine_weights, expert_outputs) outputs.shape = (S, M)
SEC(S 个 token 在 experts 上的权重) 乘ECM(experts 计算出的 token 表示),得到SM(最终 token embedding)。
Step 7: 还原 batch 结构
outputs_reshape = outputs.reshape(input.shape) outputs_reshape.shape = (seq_len, batch_size, M)
- 还原到原始
input的形状,以便后续 Transformer 处理。
2. 为什么采用这些维度变化?
- 方便计算 gating 逻辑
- 把
input展开成(S, M),这样 gating 计算softmax(S, E)很自然,每个 token 都能独立计算专家分配。
- 把
- 确保 expert 计算高效
dispatch_mask (S, E, C)允许我们用einsum直接把 tokens 排列成(E, C, M),保证每个 expert 计算时数据是有序的。
- 支持 dynamic token assignment
- 每个 expert 处理的 token 数
C可能不同,但 MoE 机制确保所有 experts 接收的 token 对齐并填充空位。
- 每个 expert 处理的 token 数
- 最后合并回 batch 结构
- 通过
einsum("SEC, ECM -> SM")结合reshape(S, M) -> (seq_len, batch_size, M),确保 Transformer 结构一致。
- 通过
总结
维度变换的核心思路:
- 展开 tokens (
(seq_len, batch_size, M) -> (S, M))- 让每个 token 计算 gate,决定去哪些 experts。
- top-2 分派 (
(S, E) -> (S, E, C))- 确定 token 在 expert buffer 中的位置,维护顺序。
- 重新排列 (
(S, M) -> (E, C, M))- 让每个 expert 处理
C个 token,数据对齐。
- 让每个 expert 处理
- Expert 计算 (
(E, C, M) -> (E, C, H) -> (E, C, M))- 运行前馈网络,得到 expert 计算后的输出。
- 合并输出 (
(E, C, M) -> (S, M))- 按照 gate 权重加权求和,恢复 token 级输出。
- 恢复 batch 结构 (
(S, M) -> (seq_len, batch_size, M))- 让 Transformer 继续处理。
参考
- https://www.53ai.com/news/qianyanjishu/1642.html


















 142
142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









