






2023Mixtral引领潮流。技术报告表明Mixtral的MoE的技术
一 技术架构
- Sparse Mixture of Experts
- 公式
- 整合
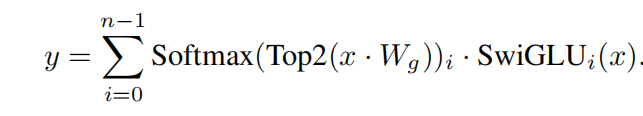
- K = 2
- replace all FFN sub-blocks by MoE layers while GShard replaces every other block, and that GShard uses a more elaborate gating strategy for the second expert assigned to each token.
- 公式
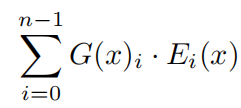
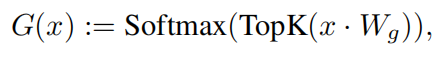
二 结果
- 任务数据集

- 解释一下shot 是什么意思
- “shot” 指的是在评估任务中提供的示例(Example)的数量
- 0-shot(零样本学习):模型在没有任何示例的情况下直接回答问题。例如,直接输入问题:“Who discovered gravity?” → “Isaac Newton”
- 1-shot(单样本学习):给模型提供一个示例,再让它回答。例如
-
Example:
Q: Who discovered relativity?
A: Albert EinsteinNow answer:
Q: Who discovered gravity?
A: …
-
- Few-shot(少样本学习,例如 3-shot, 5-shot):给模型提供多个示例,让它学习模式。例如
- Example
-
Example 1:
Q: Who discovered relativity?
A: Albert EinsteinExample 2:
Q: Who proposed the theory of evolution?
A: Charles DarwinExample 3:
Q: Who discovered gravity?
A: …
-
- Example
- 总结
- 在大模型评测中,不同任务会用不同的 shot 方式:
- 0-shot:测试模型的泛化能力,不提供示例,直接让模型推理
- 5-shot:提供 5 个示例,让模型学习任务模式,测试少样本学习能力
- 结果
- 性能
- 与LLAMA系列对比
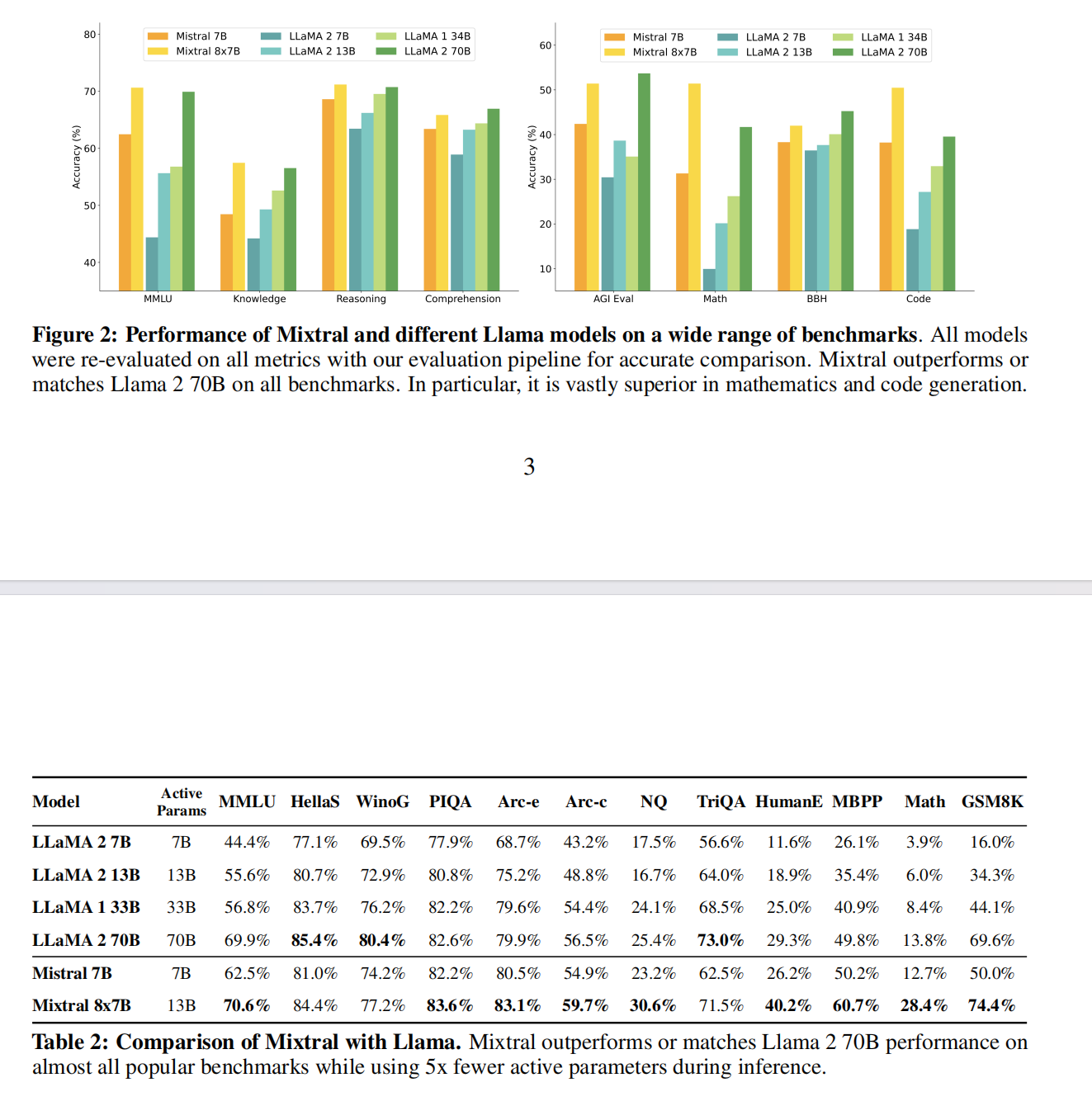
- 从结果上看只能说各有千秋,Mistral在大多数标准上好点
- 大小和效率
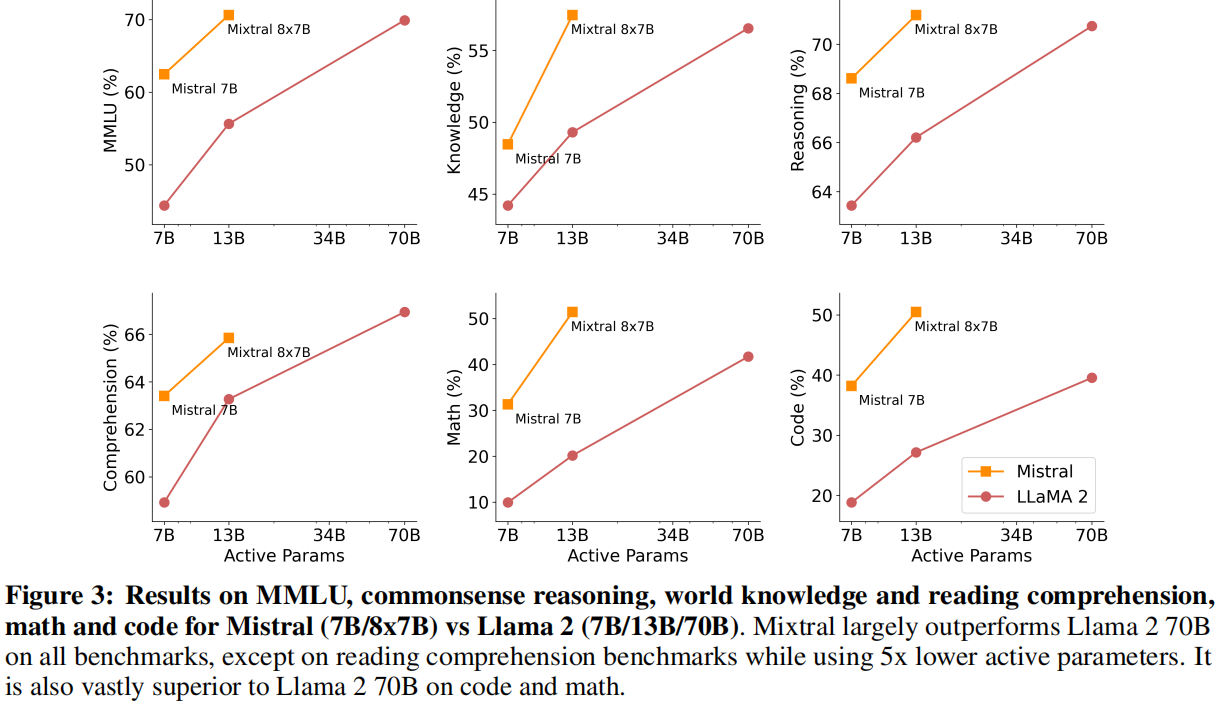
- MoE模型大小看上去大,但是激活的参数量少,效果更好
- 与GPT系列对比
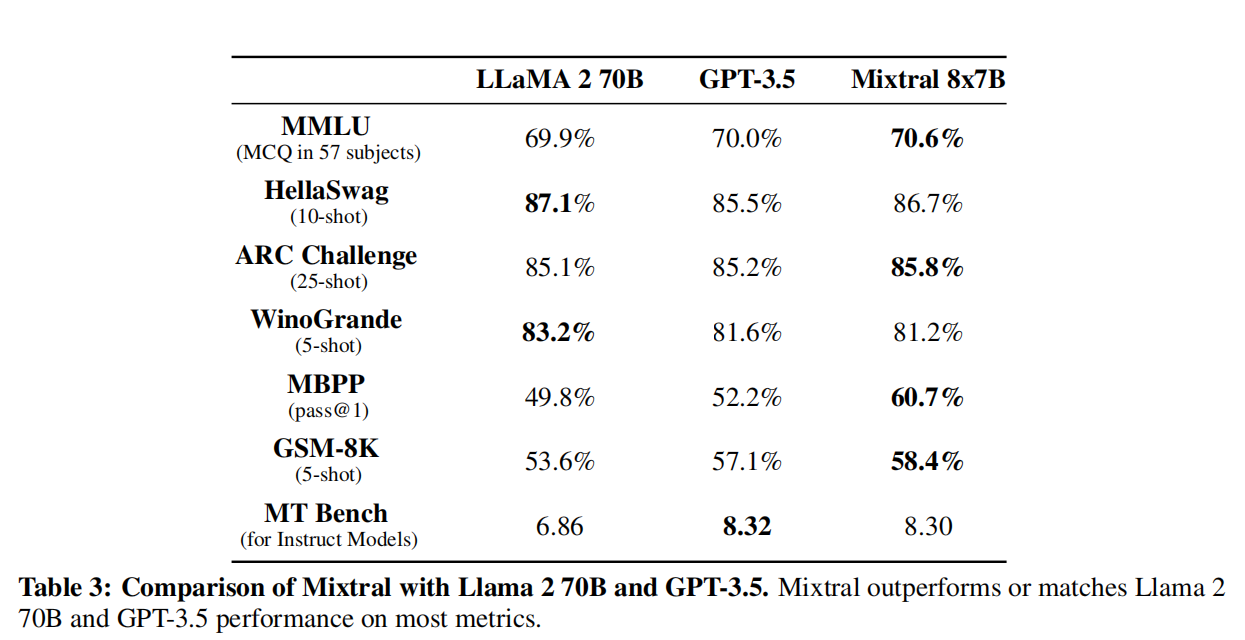
- 相当于gpt-3.5-turbo-1106
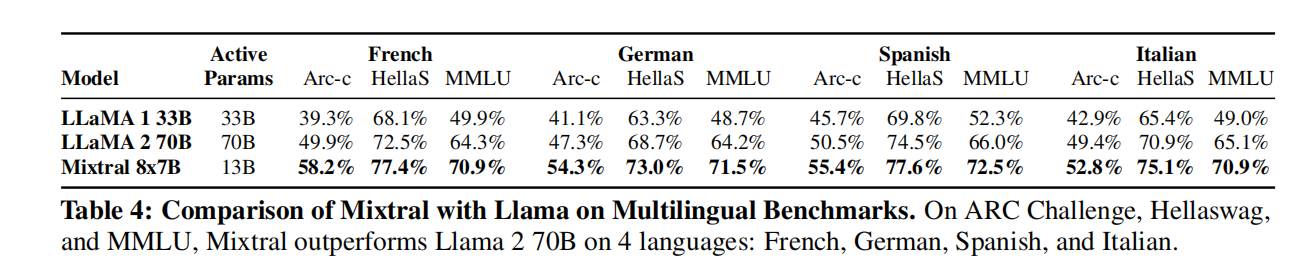
- Multilingual benchmarks
- 碾压
- 碾压
- 剩下的很多实验都说明mistral性能好
- 后面表明专家的选择大部分是根据语法而不是领域的区别
- 性能
三 缺点
- 只是说了基本原理,没有介绍一些核心技术,比如负载均衡怎么设计的
- 只说了使用专家并行,没有涉及相关细节


















 774
774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









