






这篇论文提出了KLOTSKI,一种高效的混合专家(MoE)推理引擎,旨在通过专家感知的多批次管道范式来减少推理过程中的气泡,从而提高推理效率。
MoE (Mixture-of-Experts) 模型凭借其稀疏结构,使得语言模型可以扩展至万亿级参数,同时避免了计算成本的大幅增长。最近,基于 MoE 结构的模型备受关注,例如,近日火爆的DeepSeek V3和R1均采用MoE 架构,以较低的成本实现了更强的能力。然而,庞大的参数规模给推理带来了挑战,尤其是 GPU 内存增长速度难以匹配参数的增长。尽管卸载技术能够减少 GPU 内存需求,但由于 MoE 模型计算与 I/O 负载高度不均衡,推理过程中往往会出现大量层间和层内气泡,影响系统吞吐。
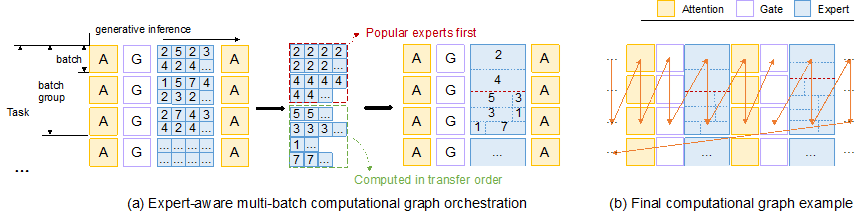
为此,本文提出Klotski,一款专为 MoE 设计的推理引擎。Klotski 通过构建专家感知的多batch流水线,有效消除推理过程中的气泡,大幅提升资源受限环境下的推理吞吐。其核心策略是在多个 batch 之间共享权重,从而延长计算时间,使其完全覆盖下一层的加载时间。然而,与密集模型不同,多 batch 计算会增加输入 token 数量,从而激活更多专家,可能引入额外的层间气泡。为此,Klotski 设计了一种MoE适配的多批次推理调度策略,仅预取高频使用的热门专家,并利用这些专家的计算时间隐藏其他专家的加载开销,以减少层内气泡。此外,Klotski 还会测量硬件能力,并根据存储资源及计算与 I/O 速度的差异,自动搜索最优推理策略。实验结果表明,与现有方法相比,Klotski 在吞吐-延迟权衡方面表现更优,吞吐量最高可提升85.12×。
研究背景
- 背景介绍: 这篇文章的研究背景是混合专家(MoE)模型由于其稀疏结构,能够在不显著增加计算成本的情况下扩展语言模型的规模。然而,大规模参数带来的内存瓶颈限制了其在资源受限环境中的应用。
- 研究内容: 该问题的研究内容包括提出一种新的专家感知的多批次管道范式,以减少推理过程中的气泡,从而提高推理效率。具体来说,通过优化计算和I/O时间的平衡,减少管道中的气泡。
- 文献综述: 该问题的相关工作包括MoE模型的研究,如GPT-4、Gemini 1.5和Mixtral-8x7B等。此外,还有一些关于MoE模型优化的研究,如DeepSpeed-MoE和Lina等。现有工作主要集中在提高MoE训练效率上,而KLOTSKI则专注于内存优化。
研究方法
这篇论文提出了KLOTSKI,用于解决MoE模型推理中的气泡问题。具体来说,
- 专家感知的多批次管道范式: 该方法通过考虑多个批次的计算来延长当前层的计算时间,以便与下一层的加载时间重叠。通过调整推理顺序,减少气泡。
- 约束敏感的I/O-计算规划器: 设计了一个I/O-计算规划器,根据当前的硬件约束制定执行计划,以最小化管道中的气泡。
- 自适应张量放置: 构建了一个多级异构内存空间,包括VRAM、DRAM和磁盘,以适应资源受限环境下的存储需求。
- 相关性感知的专家预取器: 设计了一个数据感知的专家相关性表,以识别当前多批次任务中倾向于选择的专家。
实验设计
- 硬件环境: 在两个不同的环境中评估KLOTSKI的性能:环境1使用NVIDIA RTX 3090和Intel Xeon Gold 5318Y,环境2使用NVIDIA H800和Intel Xeon Platinum。
- 模型和数据集: 使用开源的MoE模型Mixtral-8x7B和Mixtral-8x22B进行评估。输入数据来自wikitext-103,使用批量大小从4到64,序列输入长度为512,输出序列长度为32。
- 基线: 使用Hugging Face Accelerate、DeepSpeed-FastGen、FlexGen、MoE-Infinity和Fiddler作为基线进行比较。
结果与分析
- 吞吐量: KLOTSKI在所有实验场景中均表现出色,相比基线方法,吞吐量提高了85.12倍、15.45倍、2.23倍、19.06倍和9.53倍。
- 吞吐量-延迟权衡: KLOTSKI在相同的预算时间内实现了超过三倍的吞吐量,优于FlexGen、Accelerate、FastGen、MoE-Infinity和Fiddler。
- 内存使用: KLOTSKI在推理过程中减少了超过94.1%的GPU内存使用,进一步优化后减少了74.5%的内存使用。
- 气泡减少: KLOTSKI通过多批次计算和专家计算的重新排序,有效减少了管道中的气泡。
结论
这篇论文提出了KLOTSKI,一种高效的MoE推理引擎,能够在资源受限的环境中进行高吞吐量的推理。通过专家感知的多批次管道范式,KLOTSKI显著减少了推理过程中的气泡,提供了优越的吞吐量-延迟权衡。实验结果表明,KLOTSKI在吞吐量和内存使用方面均优于现有的最先进技术。
这篇论文为MoE模型的推理优化提供了新的思路,具有重要的应用价值。
参考资料
- https://zhuanlan.zhihu.com/p/26885710862
- https://mp.weixin.qq.com/s/pK7zZ_WZ8iLMFYXgCLlZIg


















 78
78

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









