







Hive介绍
一、Hive是什么
Hive是基于Hadoop的一个数据仓库工具,实质就是一个工具,用来操作数据库和数据表,可以将结构化的数据文件映射成一张表,并提供类SQL查询。
理解Hive是构建在Hadoop之上的:
第一、利用HDFS存储数据
第二、默认利用MapReduce进行计算
二、Hive的作用
Hive在Hadoop上架了一层SQL接口,可以将SQL语言翻译成MapReduce在Hadoop上执行,
这样就使得数据开发和分析人员很方便的使用SQL来完成海量数据的统计和分析,
而不必使用编程语言开发MapReduce。
三、Hive的优缺点
优点:
1)入门简单,使用类SQL语法,避免使用编程语言开发MapReduce,减少开发人员的学习成本
2)统一的元数据管理,可与impala/spark等共享元数据
3)灵活性和扩展性好,支持UDF.自定义存储格式
4)支持在不同的框架上运行(MR,Tez,Spark)
5) 提供了简单的优化模型
6) 适合离线数据处理,稳定可靠(真实生产环境)
7)有庞大的活跃社区
缺点:
1)执行比较低,由于Hive是基于Hadoop,Hadoop本身是一个批处理,高延迟的计算框架,
计算是通过MapReduce,具有高延迟性
2)不适合对实时的,对响应要求及时性高的海量数据批量计算,就是查询,统计分析。
3)不适合迭代算法
四、Hive数据类型
(一)、基本数据类型
| 数据类型 | 长度 | 示例 |
|---|---|---|
| TINYINT | 1byte(字节)有符号整数,只能存储0-255的整数 | 20 |
| SMALINT | 2byte 有符号整数,存储范围–32768 到 32767 | 20 |
| INT | 4byte 有符号整数,存储范围-2147483648到2147483647 | 20 |
| BIGINT | 8byte 有符号整数,存储范围-2^ 63到 2^63-1 | 20 |
| BOOLEAN | 布尔类型,true 或者 false | TRUE FALSE |
| FLOAT | 4个字节,单精度浮点数 | 3.1415 |
| DOUBLE | 8个字节,双精度浮点数 | 3.1415 |
| STRING | 字符串,可以使用单引号或者双引号。 | ‘this is string type’,“this is string type” |
| date | 时间类型 | 2020-12-31 |
| TIMESTAMP | 时间戳 | ‘2020-12-31 00:11:22.333’ |
| BINARY | 字节数组 |
注: Float和double区别
1)取值范围不同
单精度浮点数的表示范围:-3.40E+38~3.40E+38
双精度浮点数的表示范围:-1.79E+308~-1.79E+308
2)在程序中处理速度不同
CPU处理单精度浮点数的速度比处理双精度浮点数快,默认小数为double类型,
所以如果要用float的话,必须进行强转
例如:float a=1.3; 会编译报错,正确的写法:
float a = (float)1.3;或者float a = 1.3f;(f或F都 可以不区分大小写)
(二)、集合数据类型
| 数据类型 | 描述 | 语法示例 |
|---|---|---|
| STRUCT | 字段集合,类型可以不同 | struct<name:string,age:int> |
| MAP | 一组键-值对元组集合 | map<string,int> |
| ARRAY | 数组是一组具有相同类型和名称的变量的集合。这些变量称为数组的元素,每个数组元素都有一个编号,编号从零开始 | array<string> |
五、Hive基本操作
(一)、数据库
①
即表的集合,在HDFS中表现为一个文件夹,默认在hive.metastore.warehouse.dir下 ,
在创建表之前应该先选择数据库,使用 use 数据库名,若不指定数据库,则默认使用default数据库。
② 常用数据库命令:
| 命令 | 介绍 |
|---|---|
| create database if not exists myhive; | 创建数据库 |
| use myhive; | 选择数据库 |
| show databases; | 查看所有数据库 |
| describe database myhive; | 可以查看数据库更多的描述信息 |
| drop database if exists myhive; | 删除数据库前提是数据库为空 |
| drop database test1 cascade; | 如果数据库不为空,可以采用 cascade 命令,强制删除。 |
| select current_database(); | 查询当前使用的数据库,在 hive-site.xml 文件中添加如下配置信息,就可以实现永久显示当前数据库。<property>< name>hive.cli.print.current.db</name><value>true</value></property> |
(二)、数据表
1、分类介绍
(1)、 内部表:(管理表)
1)在HDFS中为属数据库目录下的子文件加
2)数据由Hive管理,在删除表时会删除数据
(2)、 外部表
1)外部表不由Hive管理,可以是hdfs或者hbase
2)删除表时只是删除了创建的表结构,真实数据不会被删除
(3)、 分区表
(4)、 分桶表
2、表操作
以下操作需要的数据,如有需要自行下载
链接:https://pan.baidu.com/s/1AZH17J4OJzJ9RPrV22KJGQ
提取码:czkv
3、加载数据
load data local inpath '/root/hadooptmp/employee_hr.txt' overwrite into table employee_hr;
load: 用于在Hive中移动数据,移动到建表时指定的目录下,使用后原目录下的文件就不存在了,可以看作是剪切
local:指定的数据在本地文件系统,执行后为拷贝,如果没有则指定的文件在HDFS中(加不加看具体文件的位置)
overwrite:加表示覆盖表中的现有数据,不加则表示在表中追加数据
4、内部表(可以看作mysql中普通表)
创建一张内部表-----(下面的分区以及分桶表会用到)
create table if not exists employee_hr(
name string,
id int,
num string,
time2 string
)
row format delimited
fields terminated by '|';
向内部表中加载数据
load data local inpath '/root/hadooptmp/employee_hr.txt' overwrite into table employee_hr;
5、外部表
create external table employee_external(
name string,
work_place array<string>,
sex_age struct<sex:string,age:int>,
skills_score map<string,int>,
depart_title map<string,array<string>>
)
row format delimited
fields terminated by '|' //指定每个字段的分隔符
collection items terminated by ',' //指定struct分隔符
map keys terminated by ':' //指定Map类型分隔符
lines terminated by '\n' //指定行分隔符,默认,可以不加
stored as textfile //文件的存储格式
location '/kb10/employee_external'; //表数据存在HDFS上的位置(不写会有默认路径),后面可以直接将数据
//上传到该路径,hive就可以直接将该路径下的数据映射为一张表
//hdfs dfs -put 文件名 /kb10/employee_external
//(使用这种方法就不用load,但是这种方法一般不使用,用load)
如果用上面的语法建表:建表后可以直接使用命令:
hdfs dfs -put employee.txt /kb10/employee_external
这句命令的意思是将文件 employee.txt 上传到建表时指定的文件目录,
这样刚刚建的表结构就可以直接将这个文件映射为一张表
6、分区表
??? 什么是 分区表:
分区表实际上对应一个 HDFS 文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。
Hive 中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。
什么意思呢?
就是如果数据量特别大,可以按照业务的需求将其分割成一个个的小文件,比如按sex(性别)分(男/女),那么分区过后就会生成两个文件夹,sex=男 和 sex=女
在查询时通过 WHERE 子句中的表达式选择查询所需要的指定的分区,就会在指定的分区下进行查找,这样的查询效率会提高很多
(1)、静态分区
创建单级静态分区表:
create table if not exists employee_hr_partition(
name string,
id int,
num string,
time2 string
)
partitioned by (month string) //设置分区字段
row format delimited
fields terminated by '|'
;
加载数据到分区表:(employee_hr.txt文件在本地,所以加local)
load data local inpath '/root/hadooptmp/employee_hr.txt' into table employee_hr_partition partition(month='202012');
查询结果:会在hive默认的目录下创建一个month=202012的目录名来存放employee_hr.txt
也可以给分区表在添加分区其他:alter table employee_hr_partition add partition(month='202011')
创建多级静态分区表:
create table if not exists employee_hr_partition2(
name string,
id int,
num string,
time2 string
)
partitioned by (month string,date string)
row format delimited fields terminated by '|'
;
加载数据:
load data local inpath '/root/hadooptmp/employee_hr.txt' into table employee_hr_partition2
partition(month='202012',date='01');
添加多个分区:
alter table employee_hr_partition2 add
partition(month='202011',date='01')
partition(month='202011',date='02')
partition(month='202012',date='01')
partition(month='202012',date='02');
(2)、动态分区
什么是动态分区?
在插入数据时,不指定具体的分区列值,而是仅仅指定分区字段
一般动态分区在默认情况下是禁用的,所以需要将 hive.exec.dynamic.partition 设为 true。
默认情况下,用户必须至少指定一个静态分区列,这是为了避免意外覆盖分区。
要禁用此限制,可以设置分区模式为非严格模式(即将 hive.exec.dynamic.partition.mode 设为 nonstrict,默认值为 strict)。
可以选择在命令行终端方式设置:
set hive.exec.dynamic.partition=true
set hive.exec.dynamic.partition.mode=nonstrict
创建动态分区表:
create table if not exists employee_hr_partition3(
name string,
id int,
num string,
time2 string
)
partitioned by (month string,date string)
row format delimited fields terminated by '|'
;
加载数据到动态分区表:(通过查询的方法动态插入)
insert into employee_hr_partition3 partition(month,date)
select
name,
id,
num,
time2,
month(time2) m,
date(time2) d
from
employee_hr;
(3)、动态分区和静态分区的区别
同:
建表方式一致
异:
a、建表时默认为静态分区,需要手动开启动态分区,且要设置非严格模式
b、静态分区只能通过load方式一次一个分区加载数据
动态分区不仅可以使用load的方法,而且还可以通过查询方式一次可以插入多个动态分区的数据
:insert into table partition_table partition(partition_fields...) select ...from table
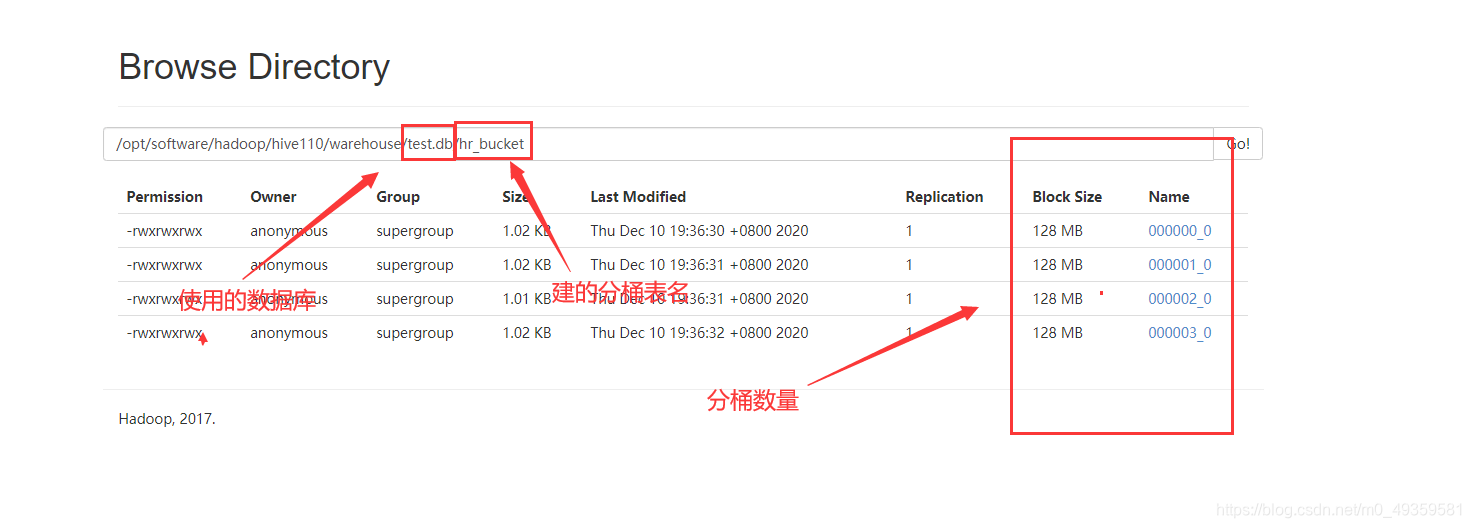
7、分桶表
打开分桶:
set hive.enforce.bucketing=true;
建表举例:
create table if not exists hr_bucket(
name string,
id int,
num string,
time2 string
)
clustered by(id) into 4 buckets (将分到4个分桶中, 就会生成4文件夹)
row format delimited
fields terminated by '|';
插入数据(从最初创建的内部表中查询插入)
insert into table hr_bucket
select * from employee_hr;
查询(抽样查询)
基于分桶字段id抽样查询:
select * from hr_bucket
tablesample(bucket 2 out of 4 on id) s;
基于整行数据随机抽样查询 rand() :
select * from hr_bucket
tablesample(bucket 2 out of 4 on rand()) s;
(三)、Hive的视图
(一)、了解视图
Lateral view 与用户定义的表生成函数(如 explode())一起使用。正如在内置的表生成函数中提到的,UDTF 为每个输入行生成零个或多个输出行。Lateral view首先将 UDTF 应用于基表的每一行,然后将产生的输出行连接到输入行,形成一个具有提供的表别名的虚拟表。即使侧视图通常不会生成一行,用户也可以指定可选的 OUTER 关键字来生成行。当使用的 UDTF 不生成任何行时,就会发生这种情况。在这种情况下,源行永远不会出现在结果中。可以使用 OUTER 来防止这种情况,并在来自 UDTF的列中使用空值生成行。Outer 关键字可以把不输出的 UDTF 的空结果,输出成 NULL,防止丢失数据。
(二)、视图操作
重要,要求掌握:
创建视图:
create view view_hr as
select name,id from employee_hr where id>10;
查询视图内容
select * from view_hr;
查询视图结构
show create table view_hr;
删除视图
drop view view_hr;
--侧视图 lateral view explode(列转行)
select
name,wps, skill,score
from employee_external
lateral view explode(work_splace)workplace as wps
lateral view explode(skills_score)sks as skill,score;
--cte 查询
with
r1 as (select * from employee_external limit 1),
r2 as (select * from employee_external where name='Will') //r1,r2,相当于定义两张表
select * from r1 union all select * from r2; //合并r1,r2
with
r1 as (select * from employee_external limit 1),
r2 as (select * from employee_external where name='Will')
select * from r1 union all select * from r2;
--Hive join 关联查询
内:只查询两张表都有的字段内容
左:查询左边表字段全内容,右表没有则为空
右:查询右边表字段全内容,左表没有则为空
交叉连接:笛卡尔积(关联查询时没有加on条件)
join 发生在where子句之前
将数据从表中插入到文件
--//默认分隔符
from employee
insert overwrite local directory
'/root/out1' select *;
--//指定分隔符
from employee
insert overwrite local directory
'/root/out1'
row format delimited
fields terminated by ','
select *;
export table employee to '/kb10/output'
查询生成的元数据
hdfs dfs -cat /kb10/output/_metadata
查询生成的文件
hdfs dfs -cat /kb10/output/employee.txt

















 1022
1022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









