



 本文详细介绍了循环单链表和循环双链表的定义,重点讲解了它们的初始化、判空以及判断表尾节点的方法,并指出两者的操作相似但循环特性带来便利。
本文详细介绍了循环单链表和循环双链表的定义,重点讲解了它们的初始化、判空以及判断表尾节点的方法,并指出两者的操作相似但循环特性带来便利。
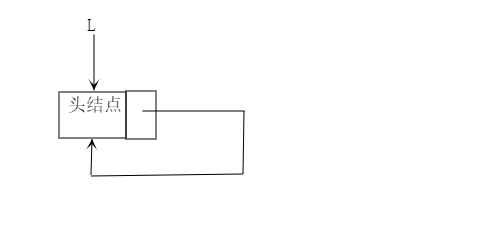
一、循环单链表
1.定义
链表最后一个结点的next指针指向头结点(注意不是指向首元结点)。这种循环的结构就使得我们知道链表中任意一个结点就可以通过遍历访问它的所有结点,而对于普通单链表来说,这种操作是不可行的,普通单链表访问不了给定结点前面的结点,除非你有它的头结点。
typedef struct LNode
{
ElemType data;
struct LNode* next;
}LNode, *LinkList;
2.操作
①初始化
bool InitList(LinkList &L)
{
L = new LNode; //创建一个头结点
if (L == NULL)
return false; //内存不足,分配失败
L->next = L; //头结点next指向自己
return true;
}
②判空
bool Empty(LinkList L)
{
if (L->next == L)
return true; //如果头指针指向自己则为空表
else
return false;
}
③判断结点p是否为循环单链表的表尾结点
bool isTail(LinkList L, LNode* p)
{
if (p->next == L)
return true;
else
return false;
}
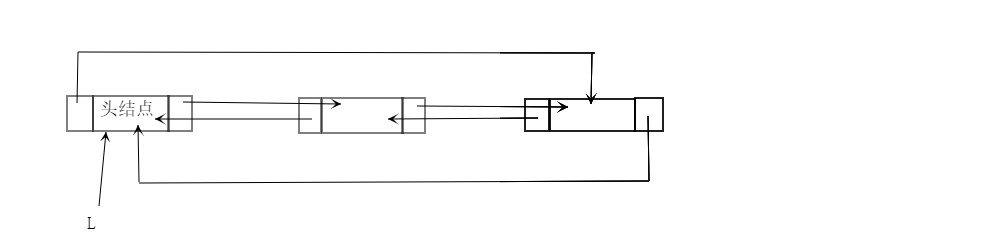
二、循环双链表
1.定义
链表中每个结点依然有两个指针,区别于双链表,循环双链表的头结点的前驱指针指向表尾结点,而表尾结点的后继指针指向头结点。
typedef struct LNode
{
ElemType data;
struct LNode *prior, *next;
}DNode, *DLinkList;
2.操作
①初始化
bool InitDLinkList(DLinkList &L)
{
L = new LNode; //创建一个头结点
if (L == NULL)
return false; //内存不足,分配失败
L->prior = L //头结点的prior指向自己
L->next = L; //头结点的next指向自己
return true;
}
②判空
bool Empty(DLinkList L)
{
if (L->next == L) //把L->next换成L->prior也行
return true; //如果头指针指向自己则为空表
else
return false;
}
③判断结点p是否为循环单链表的表尾结点
bool isTail(DLinkList L, DNode* p)
{
if (p->next == L) //换成if (L->prior == p)也行
return true;
else
return false;
}
总结
写循环链表感觉没什么好写的,居然也单开了一个帖子,写完才发现属实没什么必要,循环链表和普通链表的操作大差不大,只需要弄清楚循环链表是首尾相接,可以方便遍历就行了。

















 1629
1629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









