







一、前言
Standalone集群有2个重要组成部分,分别是:
Master(RM):是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责;
Worker(NM):是一个进程,一个Worker运行在集群中的一台服务器上,主要负责两个职责,一个是用自己的内存存储RDD的某个或某些partition;另一个是启动其他进程和线程(Executor),对RDD上的partition进行并行的处理和计算。
二、Master 源码
org.apache.spark.deploy.master.Master2.1 Master伴生对象
启动Master的入口为Master伴生对象的main方法
private[deploy] object Master extends Logging {
val SYSTEM_NAME = "sparkMaster"
val ENDPOINT_NAME = "Master"
// 启动 Master 的入口函数
def main(argStrings: Array[String]) {
Utils.initDaemon(log)
val conf = new SparkConf
// 构建用于参数解析的实例 --host hadoop102 --port 7077 --webui-port 8080
val args = new MasterArguments(argStrings, conf)
// 启动 RPC 通信环境和 MasterEndPoint(通信终端)
val (rpcEnv, _, _) = startRpcEnvAndEndpoint(args.host, args.port, args.webUiPort, conf)
rpcEnv.awaitTermination()
}
/**
* Start the Master and return a three tuple of:
* 启动 Master 并返回一个三元组
* (1) The Master RpcEnv
* (2) The web UI bound port
* (3) The REST server bound port, if any
*/
def startRpcEnvAndEndpoint(
host: String,
port: Int,
webUiPort: Int,
conf: SparkConf): (RpcEnv, Int, Option[Int]) = {
val securityMgr = new SecurityManager(conf)
// 创建 Master 端的 RpcEnv 环境 参数: sparkMaster hadoop201 7077 conf securityMgr
// 实际类型是: NettyRpcEnv
val rpcEnv: RpcEnv = RpcEnv.create(SYSTEM_NAME, host, port, conf, securityMgr)
// 创建 Master对象, 该对象就是一个 RpcEndpoint, 在 RpcEnv中注册这个RpcEndpoint
// 返回该 RpcEndpoint 的引用, 使用该引用来接收信息和发送信息
val masterEndpoint: RpcEndpointRef = rpcEnv.setupEndpoint(ENDPOINT_NAME,
new Master(rpcEnv, rpcEnv.address, webUiPort, securityMgr, conf))
// 向 Master 的通信终端发送请求,获取 BoundPortsResponse 对象
// BoundPortsResponse 是一个样例类包含三个属性: rpcEndpointPort webUIPort restPort
val portsResponse: BoundPortsResponse = masterEndpoint.askWithRetry[BoundPortsResponse](BoundPortsRequest)
(rpcEnv, portsResponse.webUIPort, portsResponse.restPort)
}
}2.2 RpcEnv的创建
真正的创建是调用NettyRpcEnvFactory的create方法创建的.
创建 NettyRpcEnv的时候, 会创建消息分发器, 收件箱和存储远程地址与发件箱的 Map
RpcEnv.scala
def create(
name: String,
bindAddress: String,
advertiseAddress: String,
port: Int,
conf: SparkConf,
securityManager: SecurityManager,
clientMode: Boolean): RpcEnv = {
// 保存 RpcEnv 的配置信息
val config = RpcEnvConfig(conf, name, bindAddress, advertiseAddress, port, securityManager,
clientMode)
// 创建 NettyRpcEvn
new NettyRpcEnvFactory().create(config)
}
<*******************************create*****************************************>
private[rpc] class NettyRpcEnvFactory extends RpcEnvFactory with Logging {
def create(config: RpcEnvConfig): RpcEnv = {
val sparkConf = config.conf
// Use JavaSerializerInstance in multiple threads is safe. However, if we plan to support
// KryoSerializer in future, we have to use ThreadLocal to store SerializerInstance
// 用于 Rpc传输对象时的序列化
val javaSerializerInstance: JavaSerializerInstance = new JavaSerializer(sparkConf)
.newInstance()
.asInstanceOf[JavaSerializerInstance]
// 实例化 NettyRpcEnv
val nettyEnv = new NettyRpcEnv(
sparkConf,
javaSerializerInstance,
config.advertiseAddress,
config.securityManager)
if (!config.clientMode) {
// 定义 NettyRpcEnv 的启动函数
val startNettyRpcEnv: Int => (NettyRpcEnv, Int) = { actualPort =>
nettyEnv.startServer(config.bindAddress, actualPort)
(nettyEnv, nettyEnv.address.port)
}
try {
// 启动 NettyRpcEnv
Utils.startServiceOnPort(config.port, startNettyRpcEnv, sparkConf, config.name)._1
} catch {
case NonFatal(e) =>
nettyEnv.shutdown()
throw e
}
}
nettyEnv
}
}2.3 Master伴生类(Master 端的 RpcEndpoint 启动)
Master是一个RpcEndpoint.
他的生命周期方法是:
constructor -> onStart -> receive* -> onStoponStart 主要代码片段
// 创建 WebUI 服务器
webUi = new MasterWebUI(this, webUiPort)
// 按照固定的频率去启动线程来检查 Worker 是否超时. 其实就是给自己发信息: CheckForWorkerTimeOut
// 默认是每分钟检查一次.
checkForWorkerTimeOutTask = forwardMessageThread.scheduleAtFixedRate(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
// 在 receive 方法中对 CheckForWorkerTimeOut 进行处理
self.send(CheckForWorkerTimeOut)
}
}, 0, WORKER_TIMEOUT_MS, TimeUnit.MILLISECONDS)
//自己对自己发送的消息,self.senf ===> receive(用receive接受)
override def receive: PartialFunction[Any, Unit] = {
.....
case CheckForWorkerTimeOut =>
timeOutDeadWorkers()
....
}
<********************************timeOutDeadWorkers******************************>
处理Worker是否超时的方法
private def timeOutDeadWorkers(): Unit = {
// Copy the workers into an array so we don't modify the hashset while iterating through it
//获取系统当前时间
val currentTime = System.currentTimeMillis()
// 把超时的 Worker 从 Workers 中移除
val toRemove = workers.filter(_.lastHeartbeat < currentTime - workerTimeoutMs).toArray
for (worker <- toRemove) {
if (worker.state != WorkerState.DEAD) {
val workerTimeoutSecs = TimeUnit.MILLISECONDS.toSeconds(workerTimeoutMs)
logWarning("Removing %s because we got no heartbeat in %d seconds".format(
worker.id, workerTimeoutSecs))
removeWorker(worker, s"Not receiving heartbeat for $workerTimeoutSecs seconds")
} else {
if (worker.lastHeartbeat < currentTime - ((reaperIterations + 1) * workerTimeoutMs)) {
workers -= worker // we've seen this DEAD worker in the UI, etc. for long enough; cull it
}
}
}
}三、worker 启动源码
3.1 Worker 源码
org.apache.spark.deploy.worker.Worker3.2 Worker伴生对象
启动流程基本和 Master 一致.
private[deploy] object Worker extends Logging {
val SYSTEM_NAME = "sparkWorker"
val ENDPOINT_NAME = "Worker"
def main(argStrings: Array[String]) {
Utils.initDaemon(log)
val conf = new SparkConf
// 构建解析参数的实例
val args = new WorkerArguments(argStrings, conf)
// 启动 Rpc 环境和 Rpc 终端
val rpcEnv = startRpcEnvAndEndpoint(args.host, args.port, args.webUiPort, args.cores,
args.memory, args.masters, args.workDir, conf = conf)
rpcEnv.awaitTermination()
}
def startRpcEnvAndEndpoint(
host: String,
port: Int,
webUiPort: Int,
cores: Int,
memory: Int,
masterUrls: Array[String],
workDir: String,
workerNumber: Option[Int] = None,
conf: SparkConf = new SparkConf): RpcEnv = {
// The LocalSparkCluster runs multiple local sparkWorkerX RPC Environments
val systemName = SYSTEM_NAME + workerNumber.map(_.toString).getOrElse("")
val securityMgr = new SecurityManager(conf)
// 创建 RpcEnv 实例 参数: "sparkWorker", "hadoop102", 8081, conf, securityMgr
val rpcEnv = RpcEnv.create(systemName, host, port, conf, securityMgr)
// 根据传入 masterUrls 得到 masterAddresses. 就是从命令行中传递过来的 Master 地址
val masterAddresses = masterUrls.map(RpcAddress.fromSparkURL(_))
// 最终实例化 Worker 得到 Worker 的 RpcEndpoint
rpcEnv.setupEndpoint(ENDPOINT_NAME, new Worker(rpcEnv, webUiPort, cores, memory,
masterAddresses, ENDPOINT_NAME, workDir, conf, securityMgr))
rpcEnv
}
}3.3 Worker伴生类
override def onStart() {
// 第一次启动断言 Worker 未注册
assert(!registered)
// 创建工作目录
createWorkDir()
// 启动 shuffle 服务
shuffleService.startIfEnabled()
// Worker的 WebUI
webUi = new WorkerWebUI(this, workDir, webUiPort)
webUi.bind()
workerWebUiUrl = s"http://$publicAddress:${webUi.boundPort}"
// 向 Master 注册 Worker
registerWithMaster()
//资源注册(自己有多少资源)
metricsSystem.registerSource(workerSource)
metricsSystem.start()
}
<*******************************registerWithMaster*********************************>
private def registerWithMaster(): Unit = {
// onDisconnected may be triggered multiple times, so don't attempt registration
// if there are outstanding registration attempts scheduled.
....
// 向所有的 Master 注册
registerMasterFutures = tryRegisterAllMasters()
connectionAttemptCount = 0
....
}
<*******************************tryRegisterAllMasters*********************************>
private def tryRegisterAllMasters(): Array[JFuture[_]] = {
masterRpcAddresses.map { masterAddress =>
// 从线程池中启动线程来执行 Worker 向 Master 注册
registerMasterThreadPool.submit(new Runnable {
override def run(): Unit = {
try {
// 根据 Master 的地址得到一个 Master 的 RpcEndpointRef, 然后就可以和 Master 进行通讯了.
val masterEndpoint = rpcEnv.setupEndpointRef(masterAddress, Master.ENDPOINT_NAME)
// 发送注册信息给master,进行通信
sendRegisterMessageToMaster(masterEndpoint)
} catch {
}
}
<*****************************sendRegisterMessageToMaster******************************>
private def sendRegisterMessageToMaster(masterEndpoint: RpcEndpointRef): Unit = {
masterEndpoint.send(RegisterWorker(
workerId,
host,
port,
self,
cores,
memory,
workerWebUiUrl,
masterEndpoint.address,
resources))
}
Master的receiveAndReply方法
override def receive: PartialFunction[Any, Unit] = {
........
case RegisterWorker(
......
//如果当前注册的Master为STANDBY
if (state == RecoveryState.STANDBY) {
//用worker的引用给worker发信息
workerRef.send(MasterInStandby)
// 如果要注册的 Worker 已经存在
} else if (idToWorker.contains(id)) {
//给worker发送信息,已经注册过了
workerRef.send(RegisteredWorker(self, masterWebUiUrl, masterAddress, true))
} else {
val worker = new WorkerInfo(id, workerHost, workerPort, cores, memory,
workerRef, workerWebUiUrl, workerResources)
// 注册成功(第一次注册)
if (registerWorker(worker)) {
persistenceEngine.addWorker(worker)
//给worker发送信息,注册成功(worker的handleRegisterResponse)
workerRef.send(RegisteredWorker(self, masterWebUiUrl, masterAddress, false))
schedule()
} else {
.................
}
}
}worker的handleRegisterResponse方法
private def handleRegisterResponse(msg: RegisterWorkerResponse): Unit = synchronized {
msg match {
case RegisteredWorker(masterRef, masterWebUiUrl, masterAddress, duplicate) =>
val preferredMasterAddress = if (preferConfiguredMasterAddress) {
masterAddress.toSparkURL
} else {
masterRef.address.toSparkURL
}
// there're corner cases which we could hardly avoid duplicate worker registration,
// e.g. Master disconnect(maybe due to network drop) and recover immediately, see
// SPARK-23191 for more details.
if (duplicate) {
logWarning(s"Duplicate registration at master $preferredMasterAddress")
}
logInfo(s"Successfully registered with master $preferredMasterAddress")
registered = true
changeMaster(masterRef, masterWebUiUrl, masterAddress)
//注册成功,以固有频率给自己发送信息(向Master发送心跳偶信息)
forwardMessageScheduler.scheduleAtFixedRate(
//自己给自己发信息,提示自己要Master发送心跳了
() => Utils.tryLogNonFatalError { self.send(SendHeartbeat) },
0, HEARTBEAT_MILLIS, TimeUnit.MILLISECONDS)
if (CLEANUP_ENABLED) {
logInfo(
s"Worker cleanup enabled; old application directories will be deleted in: $workDir")
forwardMessageScheduler.scheduleAtFixedRate(
() => Utils.tryLogNonFatalError { self.send(WorkDirCleanup) },
CLEANUP_INTERVAL_MILLIS, CLEANUP_INTERVAL_MILLIS, TimeUnit.MILLISECONDS)
}
val execs = executors.values.map { e =>
new ExecutorDescription(e.appId, e.execId, e.cores, e.state)
}
masterRef.send(WorkerLatestState(workerId, execs.toList, drivers.keys.toSeq))
case RegisterWorkerFailed(message) =>
if (!registered) {
logError("Worker registration failed: " + message)
System.exit(1)
}
case MasterInStandby =>
// Ignore. Master not yet ready.
}
}Worker的receive方法
override def receive: PartialFunction[Any, Unit] = synchronized {
case SendHeartbeat =>
if (connected) {
// 给 Master 发送心跳
sendToMaster(Heartbeat(workerId, self))
}
}
Master的receive方法
override def receive: PartialFunction[Any, Unit] = {
case Heartbeat(workerId, worker) =>
idToWorker.get(workerId) match {
case Some(workerInfo) =>
// 记录该 Worker 的最新心跳
workerInfo.lastHeartbeat = System.currentTimeMillis()
}
}
Master不断给Worker发送校验信息
Worke不断地给Master发送心跳四、Spark集群启动简单图解
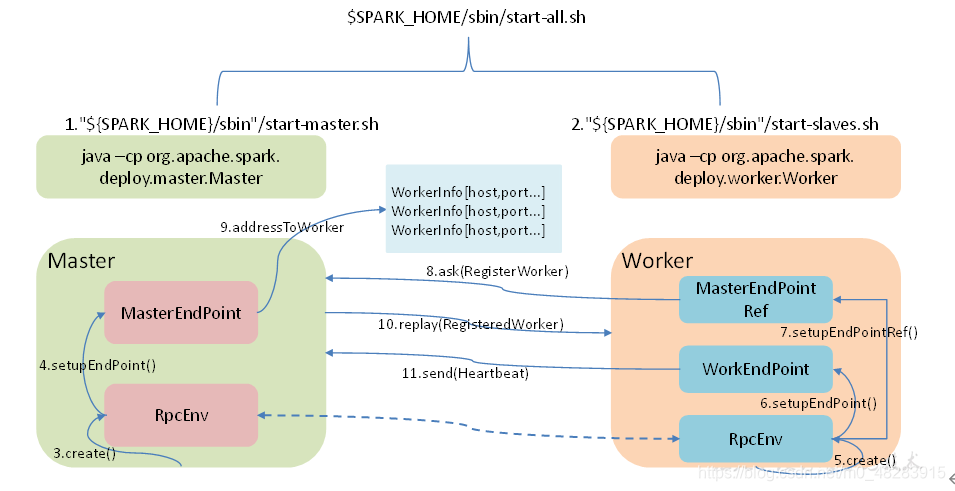
简单的启动流程:
start-all.sh脚本,实际是执行“java -cp Master”和“java -cp Worker”;
Master启动时首先创建一个RpcEnv对象,负责管理所有通信逻辑;
Master通过RpcEnv对象创建一个Endpoint,Master就是一个Endpoint,Worker可以与其进行通信;
Worker启动时也是创建一个RpcEnv对象;
Worker通过RpcEnv对象创建一个Endpoint;
Worker通过RpcEnv对象建立到Master的连接,获取到一个RpcEndpointRef对象,通过该对象可以与Master通信;
Worker向Master注册,注册内容包括主机名、端口、CPU Core数量、内存数量;
Master接收到Worker的注册,将注册信息维护在内存中的Table中,其中还包含了一个到Worker的RpcEndpointRef对象引用;
Master回复Worker已经接收到注册,告知Worker已经注册成功;
Worker端收到成功注册响应后,开始周期性向Master发送心跳。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









