






https://www.bilibili.com/video/BV1bV41177ap?p=2
https://zh-v2.d2l.ai/chapter_convolutional-modern/resnet.html
1. ResNet
这是用来解决网络退化问题的
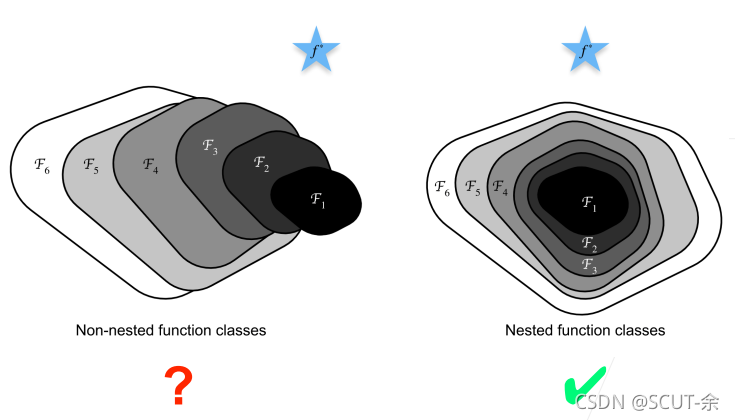
就比如左边这幅图,从F1到F6(都视为网络),虽然网络层数上升了,但层到目标f(蓝色五角星)的距离却变大了,就是效果变坏了,称之为网络退化,在统计机器学习里叫模型偏差
解决的想法就是:在构造模型的时候每一个模型都包含这前面的小模型,这样学习的效果就应该严格地比前面的更好(就像右边那张图一样),这样使得他能有很高的层数
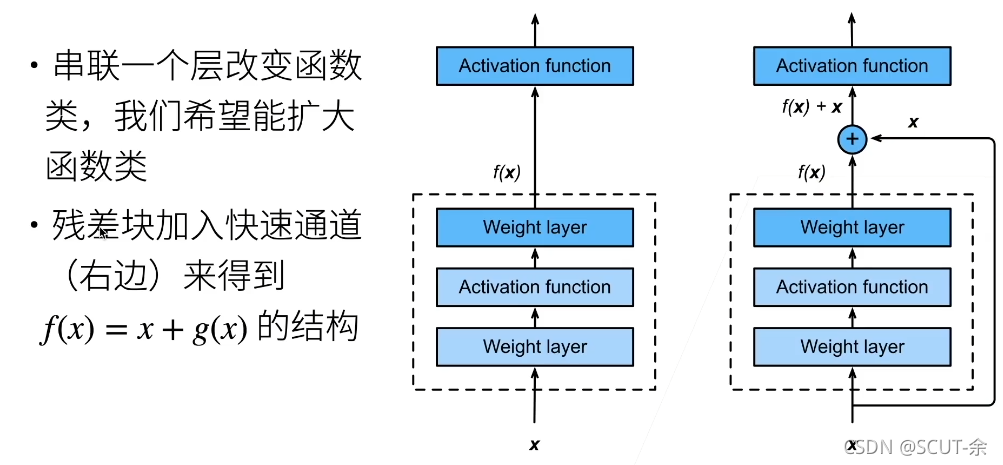
具体设计
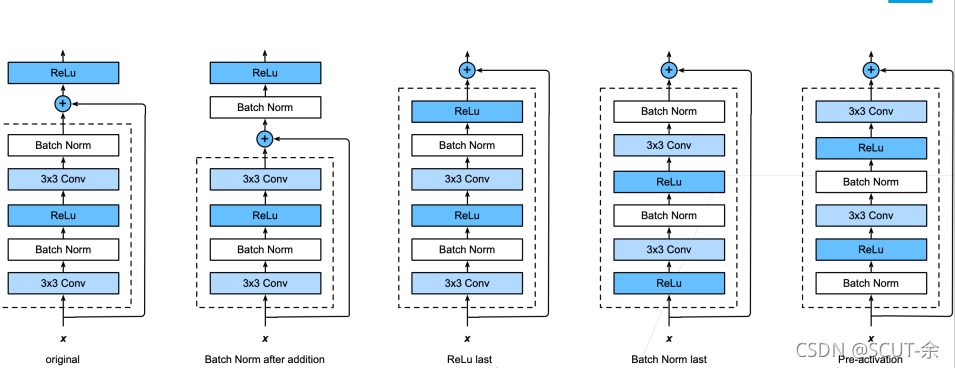
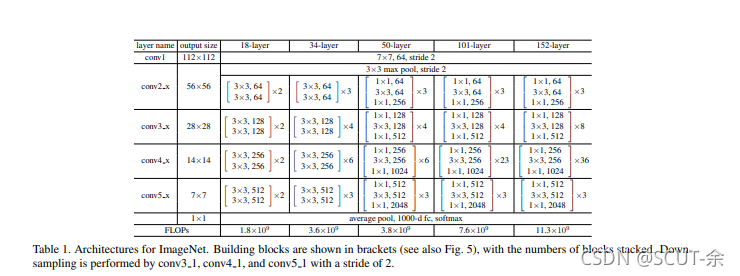
出了加出来的部分其他的跟VGG很像
1.2 代码
备注:我是按那个图片直接搭的,可能有错
from torch.nn import functional as F
import torch
import torch.nn as nn
from torchvision import datasets, transforms
from d2l import torch as d2l
import matplotlib.pyplot as plt
import torchvision
from torch.utils import data
class Residual(nn.Module):
def __init__(self,input_channels,
output_channels1, output_channels2, output_channels3,
use_1x1conv=False,strides=1):
super().__init__()
print(input_channels,
output_channels1, output_channels2, output_channels3)
self.conv1=nn.Conv2d(input_channels,output_channels1,
kernel_size=1,padding=0,stride=strides)
self.conv2=nn.Conv2d(output_channels1,output_channels2,
kernel_size=3,padding=1)
self.conv3=nn.Conv2d(output_channels2,output_channels3,
kernel_size=1,padding=0)
if use_1x1conv:
self.conv4=nn.Conv2d(input_channels,output_channels3,kernel_size=1,padding=0,stride=strides)
else:
self.conv4=None
self.bn1=nn.BatchNorm2d(output_channels1)
self.bn2=nn.BatchNorm2d(output_channels2)
self.bn3=nn.BatchNorm2d(output_channels3)
self.bn4 = nn.BatchNorm2d(output_channels3)
#上层网络nn.Conv2d中传递下来的tensor直接进行修改,这样能够节省运算内存,不用多存储其他变量。
self.relu=nn.ReLU(inplace=True)
def forward(self,x):
Y=self.conv1(x)
Y=F.relu(self.bn1(Y))
Y=F.relu(self.bn2(self.conv2(Y)))
Y=self.bn3(self.conv3(Y))
if self.conv4:
X=self.conv4(x)
else:
X=0
Y+=X
return F.relu(Y)
def resblock(input_channels,output_channels1, output_channels2, output_channels3,num_residuals,first_block=False):
blk=[]
for i in range(num_residuals):
#按原文每个convn_c都会造成高宽减半,一般在第一个卷积层完成变换
if i==0 and not first_block:
blk.append(Residual(input_channels,output_channels1, output_channels2, output_channels3,use_1x1conv=True,strides=2))
else:
blk.append(Residual(output_channels3,output_channels1, output_channels2, output_channels3))
return blk
def resblock_b2(input_channels,output_channels1, output_channels2, output_channels3,num_residuals,first_block=False):
blk=[]
for i in range(num_residuals):
#按原文每个convn_c都会造成高宽减半,一般在第一个卷积层完成变换
if i==0 and first_block:
blk.append(Residual(input_channels,output_channels1, output_channels2, output_channels3,use_1x1conv=True,strides=2))
else:
blk.append(Residual(output_channels3,output_channels1, output_channels2, output_channels3))
return blk
#res50
b1=nn.Sequential(
nn.Conv2d(1,128,kernel_size=7,stride=2,padding=3),
nn.BatchNorm2d(128),nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
b2=nn.Sequential(*resblock_b2(128,64,64,256,3,first_block=True))
b3=nn.Sequential(*resblock(256,128,128,512,3))
b4=nn.Sequential(*resblock(512,256,256,1024,3))
b5=nn.Sequential(*resblock(1024,512,512,2048,3))
net=nn.Sequential(b1,b2,b3,b4,b5,
nn.AdaptiveAvgPool2d(1),
nn.Flatten(), nn.Linear(2048, 10)
)
def load_data_mnist(batch_size, resize=None):
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
mnist_train = torchvision.datasets.MNIST(
root="D:\data", train=True, transform=trans, download=False)
mnist_test = torchvision.datasets.MNIST(
root="D:\data", train=False, transform=trans, download=False)
return (data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=0),
data.DataLoader(mnist_test, batch_size, shuffle=False,
num_workers=0))
def evaluate_accuracy_gpu(net, data_iter, device=None):
if isinstance(net, torch.nn.Module):
net.eval() # 设置为评估模式
if not device:
device = next(iter(net.parameters())).device
# 正确预测的数量,总预测的数量
metric = d2l.Accumulator(2)
for X, y in data_iter:
if isinstance(X, list):
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.Adam(net.parameters(),lr)
loss = nn.CrossEntropyLoss()
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# 训练损失之和,训练准确率之和,范例数
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
test_acc = evaluate_accuracy_gpu(net, test_iter)
loss_l.append(train_l)
train_a_l.append(train_acc)
test_a_l.append(test_acc)
print(f'epoch{epoch + 1},loss {train_l:.4f}, train acc {train_acc:.4f}, '
f'test acc {test_acc:.4f}')
if __name__ == '__main__':
loss_l = []
train_a_l = []
test_a_l = []
epoch_l = []
lr, num_epochs, batch_size = 0.001, 40, 32
train_iter, test_iter = load_data_mnist(batch_size)
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
# 集体打印,避免奇怪的userwarning毁掉观感
for i in range(int(len(loss_l))):
epoch_l.append(i + 1)
# 作图
plt.subplot(111)
# 加网线格子
plt.grid(linestyle=':')
plt.xlabel(r'$epoch$', fontsize=14)
plt.plot(epoch_l, train_a_l, c='dodgerblue', label=r'$train acc$')
plt.plot(epoch_l, test_a_l, c='orangered', label=r'$test acc$')
plt.legend()
plt.subplot(111)
plt.figure('loss', facecolor='lightgray')
plt.title('loss', fontsize=20)
plt.xlabel(r'$epoch$', fontsize=14)
plt.ylabel(r'$loss$', fontsize=14)
plt.plot(epoch_l, loss_l, c='limegreen', label=r'$loss$')
plt.show()
2.rnn
2.1基本名词
·时间步:t,不过t在这里(rnn)是正整数

















 763
763

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









