






BEVFormer
论文链接:BEVFormer-中文版.pdf (有中文版大家就不要吃那个苦啦)
官方链接:BEVFormer
老规矩,看一下效果

前置信息
这次代码我是在ubuntu上跑的,因为windows上搞mmlab很麻烦,在文章的结尾我会写一下如何安装运行环境。
在学这个之前,最好学一下DERT和可变DERT的知识,DERT我之前有写过,可变DERT我后续可能会写一篇。
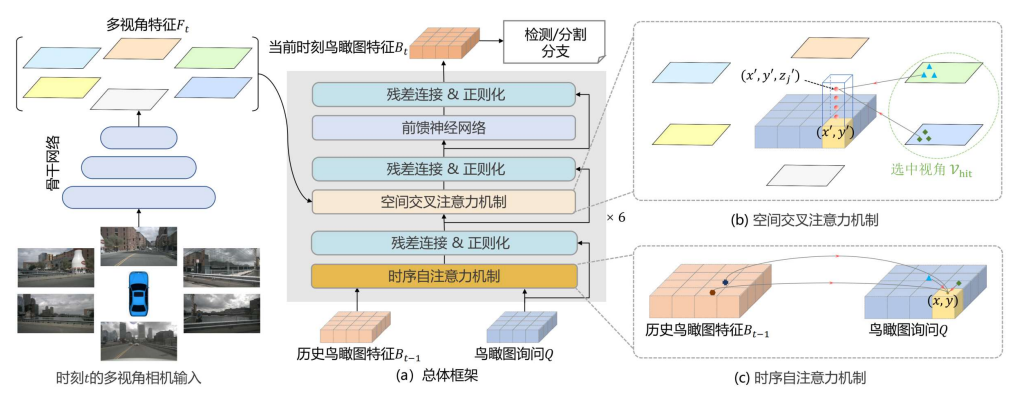
总体框架
BEV要解决的问题,如何将驾驶过程中,多个摄像头的数据融合在一起。传统方法,比如前融合和后融合,效果一般。BEVFormer 采用基于 Transformer 的跨视角融合机制,可以高效聚合多个相机的特征。它会将多个摄像头的2D图像特征,通过 Transformer 结构,汇总到BEV queries的3D空间上。而且,当你有了BEV空间特征可以更容易拓展下游任务。
BEVFormer还考虑了时序特征。比如你想象一下,开车的时候左前方有一辆车a,但是下一秒这辆车被另一辆车b挡住了,那a凭空消失了吗?显然没有,所以这个a仍然需要要被检测到,尽管你看不见它。BEVFormer利用这些历史帧信息提升感知精度,而且拥有了时序特征,还可以去预测目标的速度、轨迹、分割等任务。
既然利用了时序特征,那肯定会遇到一些因为时间变化导致的问题。比如车转弯了或者路比较颠簸,那你前一时刻的位置肯定和当前时刻的位置有偏移啊,你得想办法把位置对齐,即自身的运动补偿。此外,不同的摄像头的采样频率、数据传输延迟等因素,会导致时间的差异问题,这也需要进行对齐。最终,不同摄像头的结果会映射到同一坐标系上,这空间位置特征也要对齐。
BEVFormer最核心的内容就是构建一个特征空间,即bev queries。在这个空间里,会以一个上帝视角来看不同摄像头的图像,从而做一些下游任务。那么如何构建bev queries呢?首先,我们来设置一下这个空间的大小,论文中设置的是200×200的网格(其实相当于有4w个查询点,每个查询点的维度为246),网格的间隔设置的是0.512m。这个网格大小,间隔大小主要取决于你硬件咋样,还有你想做到的精度多高。比如我下面讲代码环境,我用的网格是50×50的,是我不想做200×200的吗?错!是我的硬件不允许。
那如何计算这个bev queries呢?论文中摄像头的数量一共是6个,假设每个摄像头的图像size为100×100,如果这1w个点(还是往小了说的)与bev queries里4w个点做计算,还要算6个摄像头,这计算量已经有点爆炸了。所以我们要简化计算,如何简化呢?bev queries里4w个点跟每个摄像头的每个点都有关系吗?那显然不是啊。摄像头1可能只有400个点跟bev queries有关,摄像头2可能有500个… 那我只计算和bev queries有关的点,而那些无关的点mask掉,不做计算。
计算点和点的关系肯定缺不了Transformer,BEVFormer当然也做了自注意力和交叉注意力,它用的方法就是可变DERT的东西(所以强烈推荐先了解一下可变DERT模型)。我这里不具体说了,简单说一下是怎么做的。这自注意力计算大家应该很熟悉了,特征图上每个点与每个点计算一下关系。一张特征图size为N×N,那需要计算 N 2 N^2 N2个点与 N 2 N^2 N2个点之间的关系,这计算量也是不小。但是可变DERT表示,no。我每个点啊,我只采样4个点来做计算。那这4个点的位置怎么选择呢?也有讲究的,如下图。
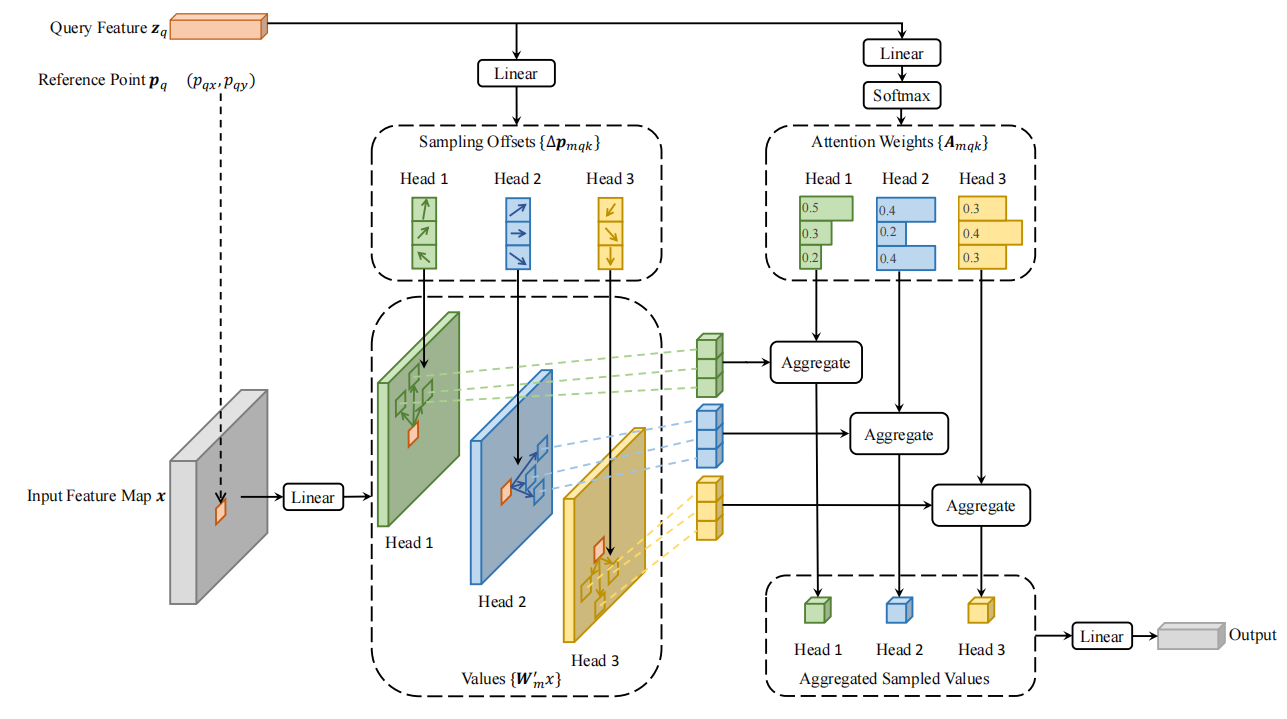
这特征图上的每个点肯定是有维度的,我连两个全连接,一个全连接帮我输出4个偏移量xy(以当前点为中心,偏移的位置xy),另一个全连接帮我输出4个权重。这样我不仅有4个点的位置,我还有了4个点的重要性。那肯定有人表示疑惑,4个点,也太少了吧?那效果能好吗?诶,神经网络的玄学你不懂,看实验结果,如下图。
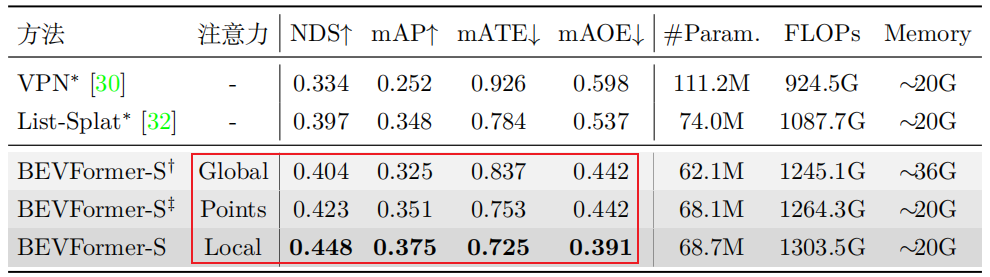
全局采样和单个点采样的效果不如采样4个的。而且之前还有人做过实验,采样8个点的效果也不如采样4个点的,你说玄学不玄学。
在时间注意力模块上,不同帧中车和周围物体都会有偏移,这怎么搞呢?学呗,学一下它偏移到哪去了,如下图。
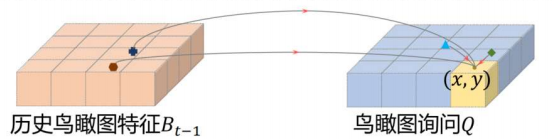
在历史的bev中,红色的点和黑色的点在下一时刻的bev中应该位于哪里呢?学个位置偏移x1y1、x2y2,再学个权重w1、w2,然后加权求和得到当前时刻bev的(x,y)。当前的bev是通过前一个时刻的bev初始化的,那是不是就是融入了历史信息。
在空间注意力模块上,这里做的是交叉注意力,和刚刚上面自注意力的计算过程差不多,只不过这次不是自己和自己做计算,而是bev queries上的点与摄像头图片上的点做计算(当然也不是全部的点,上面有说过只跟与关系的点做计算,可能一张图上只有四五百个点有关系)。这篇论文上啊提了一个特别的东西,这个bev queries不仅是200×200的2D空间,它还有一个高度,如下图,往上还有4个格子,是包含高度维度(Z 轴)的 3D 查询点,200×200×4。
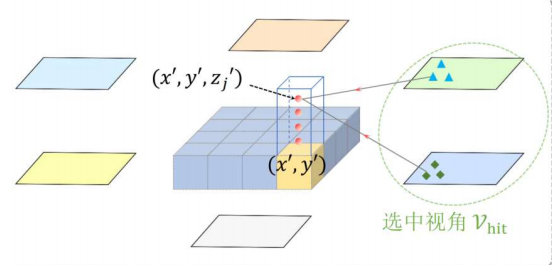
传统 BEV 方法默认所有特征都投影到同一平面上,容易丢失高度信息,导致难以区分不同高度上的物体(话是这么说,但到底是不是谁也说不清,毕竟我也没咋见过有别人这么干)。官方的解释就是,让BEV表征不仅仅局限于2D平面感知,而是可以捕捉一定程度的3D空间信息。
后续有人在bevformer上做了改进,bevformer++。这个到没有论文出处,是有人在竞赛上做的东西,它恐怖的点在于比bevformer高了20个点,有兴趣的可以去了解一下。
BEVFormer的具体流程如下图。
数据集
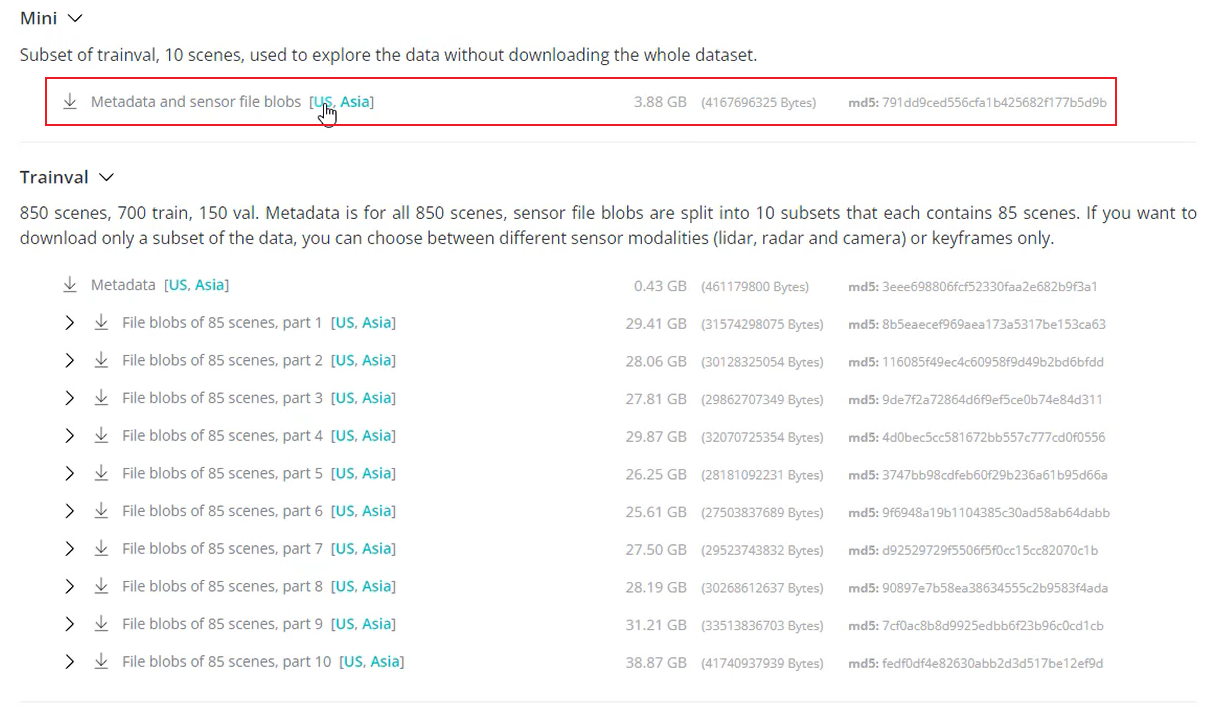
数据集官方有提供,是NuScenes。但是这个数据集吧,非常的大,快有300个G了,如果只是学习的话,不至于下这么大血本,下个mini版的就行。
官方链接:Prepare Dataset
我这提供个网盘下载链接吧:夸克网盘分享
代码
参数配置
首先配置一下参数,这里只需要配置config就行,直接输入形参
your/path/BEVFormer/projects/configs/bevformer/bevformer_tiny.py
这里换成自己文件所在位置的绝对路径
这里我使用的是bevformer_tiny,大家可以根据自己电脑的性能选择更好的。本来想跑base的,但是需要显存28G,我电脑显存只有16G跑不了。base中会有多尺度的计算过程,tiny和small都没有,索性直接跑tiny了。所以下面代码里我都是按tiny讲的。
bevformer_tiny.py中需要改一下参数,数据集的位置
data_root = 'your/path/BEVFormer/data/nuscenes/'
如果用的是bevformer_small.py、bevformer_base.py的,还需要修改预训练模型的位置
load_from = 'your/path/PycharmProjects/BEVFormer/ckpts/yourpretrain.pth'
forward_train
debug路径tool/train.py
来到projects/mmdet3d_plugin/bevformer/detectors/bevformer.py的BEVFormer下的方法forward_train中。这里先只贴一部分,因为self.obtain_history_bev会走很长的路,等你回过神已经忘了下面的代码了。
def forward_train(self,
points=None,
img_metas=None,
gt_bboxes_3d=None,
gt_labels_3d=None,
gt_labels=None,
gt_bboxes=None,
img=None,
proposals=None,
gt_bboxes_ignore=None,
img_depth=None,
img_mask=None,
):
len_queue = img.size(1)
prev_img = img[:, :-1, ...]
img = img[:, -1, ...]
prev_img_metas = copy.deepcopy(img_metas)
prev_bev = self.obtain_history_bev(prev_img, prev_img_metas)
输入的img的size为(1,3,6,3,480,800),分别表示(batch,前两个时刻和当前时刻,6个摄像头,rgb通道,H,W)。pre_img和img分别存放前两个时刻的历史信息和当前信息,因此size分别为(1,2,6,3,480,800)、(1,6,3,480,800)。现在我们通过self.obtain_history_bev获取历史BEV特征。
obtain_history_bev
def obtain_history_bev(self, imgs_queue, img_metas_list):
self.eval()
with torch.no_grad():
prev_bev = None
bs, len_queue, num_cams, C, H, W = imgs_queue.shape
imgs_queue = imgs_queue.reshape(bs * len_queue, num_cams, C, H, W)
img_feats_list = self.extract_feat(img=imgs_queue, len_queue=len_queue)
for i in range(len_queue):
img_metas = [each[i] for each in img_metas_list]
if not img_metas[0]['prev_bev_exists']:
prev_bev = None
# img_feats = self.extract_feat(img=img, img_metas=img_metas)
img_feats = [each_scale[:, i] for each_scale in img_feats_list]
prev_bev = self.pts_bbox_head(
img_feats, img_metas, prev_bev, only_bev=True)
self.train()
return prev_bev
先通过self.extract_feat提取图像特征。
extract_img_feat
def extract_img_feat(self, img, img_metas, len_queue=None):
B = img.size(0)
if img is not None:
if img.dim() == 5 and img.size(0) == 1:
img.squeeze_()
elif img.dim() == 5 and img.size(0) > 1:
B, N, C, H, W = img.size()
img = img.reshape(B * N, C, H, W)
if self.use_grid_mask:
img = self.grid_mask(img)
img_feats = self.img_backbone(img)
if isinstance(img_feats, dict):
img_feats = list(img_feats.values())
else:
return None
if self.with_img_neck:
img_feats = self.img_neck(img_feats)
img_feats_reshaped = []
for img_feat in img_feats:
BN, C, H, W = img_feat.size()
if len_queue is not None:
img_feats_reshaped.append(img_feat.view(int(B / len_queue), len_queue, int(BN / B), C, H, W))
else:
img_feats_reshaped.append(img_feat.view(B, int(BN / B), C, H, W))
return img_feats_reshaped
先获取img的一些信息,将2个时间序列和6个摄像头维度放在一起,size变为(12,3,480,800),通过self.grid_mask对图像随机生成规则遮挡的网格,做一下数据增强。看一下self.grid_mask的形式
self.grid_mask = GridMask(True, True, rotate=1, offset=False, ratio=0.5, mode=1, prob=0.7)
这里就不直接跳到GridMask里debug了,我直接解释一下做了啥。在垂直和水平方向应用遮挡、允许随机旋转、不启用随机偏移、遮挡比例为0.5、遮挡为部分为白色、应用遮挡的概率为0.7(遮挡概率可以随着训练的进行逐步增加)。
然后经过self.img_backbone提取图片特征,这里用的就是ResNet50,输出(12,2048,15,25)。
这里的self.img_neck是做一个FPN多尺度特征提取的,但是tiny只做了单尺度特征,base里的会做4层的多尺度特征提取。因此在tiny里相当于特征融合或通道降维,把 2048 维降到 256 维,输出size为(12,256,15,25)。
然后经过一个for循环reshape回原来的时间序列和摄像头维度,size为(1,2,6,256,15,25)。因为tiny做的是单尺度的,所以第一个维度是1。
=======================================================================
好,我们回到obtain_history_bev继续往下看。
进入一个for循环,然后分两次处理一个刚刚返回的图像特征,看看self.pts_bbox_head做了啥。
pts_bbox_head
来到projects/mmdet3d_plugin/bevformer/dense_heads/bevformer_head.py的BEVFormerHead下的forward看看怎么个事。代码太长了,这里只先展示部分。
def forward(self, mlvl_feats, img_metas, prev_bev=None, only_bev=False):
bs, num_cam, _, _, _ = mlvl_feats[0].shape
dtype = mlvl_feats[0].dtype
object_query_embeds = self.query_embedding.weight.to(dtype)
bev_queries = self.bev_embedding.weight.to(dtype)
bev_mask = torch.zeros((bs, self.bev_h, self.bev_w),
device=bev_queries.device).to(dtype)
bev_pos = self.positional_encoding(bev_mask).to(dtype)
if only_bev: # only use encoder to obtain BEV features, TODO: refine the workaround
return self.transformer.get_bev_features(
mlvl_feats,
bev_queries,
self.bev_h,
self.bev_w,
grid_length=(self.real_h / self.bev_h,
self.real_w / self.bev_w),
bev_pos=bev_pos,
img_metas=img_metas,
prev_bev=prev_bev,
)
这里仅使用编码器获取BEV特征,所以不管这个object_query_embeds。论文里的bev_queries设置的是200×200,不过我们用的是tiny的,缩小为了50×50,因此size为(2500,256)。2500个BEV位置,每个位置有256维向量。
然后初始化bev的mask和pos位置编码,mask具体是干啥的后面代码用到了讲。然后进入到self.transformer.get_bev_features看看怎么个事。
get_bev_features
在路径projects/mmdet3d_plugin/bevformer/modules/transformer.py的PerceptionTransformer下的get_bev_features方法中。代码太长了,我分开来讲吧。
def get_bev_features(
self,
mlvl_feats,
bev_queries,
bev_h,
bev_w,
grid_length=[0.512, 0.512],
bev_pos=None,
prev_bev=None,
**kwargs):
bs = mlvl_feats[0].size(0)
bev_queries = bev_queries.unsqueeze(1).repeat(1, bs, 1)
bev_pos = bev_pos.flatten(2).permute(2, 0, 1)
# obtain rotation angle and shift with ego motion
delta_x = np.array([each['can_bus'][0]
for each in kwargs['img_metas']])
delta_y = np.array([each['can_bus'][1]
for each in kwargs['img_metas']])
ego_angle = np.array(
[each['can_bus'][-2] / np.pi * 180 for each in kwargs['img_metas']])
grid_length_y = grid_length[0]
grid_length_x = grid_length[1]
translation_length = np.sqrt(delta_x ** 2 + delta_y ** 2)
translation_angle = np.arctan2(delta_y, delta_x) / np.pi * 180
bev_angle = ego_angle - translation_angle
shift_y = translation_length * \
np.cos(bev_angle / 180 * np.pi) / grid_length_y / bev_h
shift_x = translation_length * \
np.sin(bev_angle / 180 * np.pi) / grid_length_x / bev_w
shift_y = shift_y * self.use_shift
shift_x = shift_x * self.use_shift
shift = bev_queries.new_tensor(
[shift_x, shift_y]).permute(1, 0) # xy, bs -> bs, xy
img_metas['can_bus']里存放了当前时间戳的运动信息,包括它的旋转角度和运动距离。计算它的偏移量shift,相当于BEV视角运动补偿,用于修正BEV特征图的空间对齐,对齐车的坐标系。
if prev_bev is not None:
if prev_bev.shape[1] == bev_h * bev_w:
prev_bev = prev_bev.permute(1, 0, 2)
if self.rotate_prev_bev:
for i in range(bs):
# num_prev_bev = prev_bev.size(1)
rotation_angle = kwargs['img_metas'][i]['can_bus'][-1]
tmp_prev_bev = prev_bev[:, i].reshape(
bev_h, bev_w, -1).permute(2, 0, 1)
tmp_prev_bev = rotate(tmp_prev_bev, rotation_angle,
center=self.rotate_center)
tmp_prev_bev = tmp_prev_bev.permute(1, 2, 0).reshape(
bev_h * bev_w, 1, -1)
prev_bev[:, i] = tmp_prev_bev[:, 0]
一开始肯定还没有prev_bev,这是前一帧的BEV特征。这部分代码主要是对前一帧的BEV特征进行旋转补偿,校正前一帧BEV特征,使其对齐当前帧的视角。BEV视角是固定的,但车辆会旋转移动,如果历史BEV特征如果不校正,就会错位。
can_bus = bev_queries.new_tensor(
[each['can_bus'] for each in kwargs['img_metas']]) # [:, :]
can_bus = self.can_bus_mlp(can_bus)[None, :, :]
bev_queries = bev_queries + can_bus * self.use_can_bus
can_bus存放了当前时间戳车的18个状态指标,然后通过全连接self.can_bus_mlp映射成256维向量。为什么256呢,因为bev queries每个位置有256维向量,bev queries需要加上它们,使自己能够感知车的状态信息。
feat_flatten = []
spatial_shapes = []
for lvl, feat in enumerate(mlvl_feats):
bs, num_cam, c, h, w = feat.shape
spatial_shape = (h, w)
feat = feat.flatten(3).permute(1, 0, 3, 2)
if self.use_cams_embeds:
feat = feat + self.cams_embeds[:, None, None, :].to(feat.dtype)
feat = feat + self.level_embeds[None,
None, lvl:lvl + 1, :].to(feat.dtype)
spatial_shapes.append(spatial_shape)
feat_flatten.append(feat)
feat_flatten = torch.cat(feat_flatten, 2)
spatial_shapes = torch.as_tensor(
spatial_shapes, dtype=torch.long, device=bev_pos.device)
level_start_index = torch.cat((spatial_shapes.new_zeros(
(1,)), spatial_shapes.prod(1).cumsum(0)[:-1]))
feat_flatten = feat_flatten.permute(
0, 2, 1, 3) # (num_cam, H*W, bs, embed_dims)
bev_embed = self.encoder(
bev_queries,
feat_flatten,
feat_flatten,
bev_h=bev_h,
bev_w=bev_w,
bev_pos=bev_pos,
spatial_shapes=spatial_shapes,
level_start_index=level_start_index,
prev_bev=prev_bev,
shift=shift,
**kwargs
)
return bev_embed
这里for循环遍历每个尺度,但tiny是单尺度的,所以跟没有for循环一样。先将特征的维度转为(6,1,375,256),375=15×25。加上摄像头的特征维度,和FPN的层级特征(因为tiny是单尺度的,就等于加了个偏置项)。然后将不同层级的给拼接在一个维度里(因为tiny是单尺度的,没有别的层级给它拼接),level_start_index存储拼接过程中每个层级开始的index(tiny只有一层,所以只有一个0)。
ok,现在我们来到self.encoder看看怎么个事。
BEVFormerEncoder
来到路径projects/mmdet3d_plugin/bevformer/modules/encoder.py的BEVFormerEncoder下的forward。代码太长了,分段讲解。
def forward(self,
bev_query,
key,
value,
*args,
bev_h=None,
bev_w=None,
bev_pos=None,
spatial_shapes=None,
level_start_index=None,
valid_ratios=None,
prev_bev=None,
shift=0.,
**kwargs):
output = bev_query
intermediate = []
ref_3d = self.get_reference_points(
bev_h, bev_w, self.pc_range[5] - self.pc_range[2], self.num_points_in_pillar, dim='3d', bs=bev_query.size(1),
device=bev_query.device, dtype=bev_query.dtype)
ref_2d = self.get_reference_points(
bev_h, bev_w, dim='2d', bs=bev_query.size(1), device=bev_query.device, dtype=bev_query.dtype)
先分别计算了BEV queries的3D视图和2D视图,到self.get_reference_points看看怎么做的。
get_reference_points
def get_reference_points(H, W, Z=8, num_points_in_pillar=4, dim='3d', bs=1, device='cuda', dtype=torch.float):
# reference points in 3D space, used in spatial cross-attention (SCA)
if dim == '3d':
zs = torch.linspace(0.5, Z - 0.5, num_points_in_pillar, dtype=dtype,
device=device).view(-1, 1, 1).expand(num_points_in_pillar, H, W) / Z
xs = torch.linspace(0.5, W - 0.5, W, dtype=dtype,
device=device).view(1, 1, W).expand(num_points_in_pillar, H, W) / W
ys = torch.linspace(0.5, H - 0.5, H, dtype=dtype,
device=device).view(1, H, 1).expand(num_points_in_pillar, H, W) / H
ref_3d = torch.stack((xs, ys, zs), -1)
ref_3d = ref_3d.permute(0, 3, 1, 2).flatten(2).permute(0, 2, 1)
ref_3d = ref_3d[None].repeat(bs, 1, 1, 1)
return ref_3d
# reference points on 2D bev plane, used in temporal self-attention (TSA).
elif dim == '2d':
ref_y, ref_x = torch.meshgrid(
torch.linspace(
0.5, H - 0.5, H, dtype=dtype, device=device),
torch.linspace(
0.5, W - 0.5, W, dtype=dtype, device=device)
)
ref_y = ref_y.reshape(-1)[None] / H
ref_x = ref_x.reshape(-1)[None] / W
ref_2d = torch.stack((ref_x, ref_y), -1)
ref_2d = ref_2d.repeat(bs, 1, 1).unsqueeze(2)
return ref_2d
分别生成BEV视角下的3D和2D参考点。zs生成4个高度离散点,xs生成水平方向 (x轴) 的归一化坐标,ys生成垂直方向 (y轴) 的归一化坐标,size都为(4,50,50)。通过stack和维度转换,最终ref_3d的size为(1,4,2500,3),分别表示(batch,高度,bev queries,xyz),每个batch共享相同的参考点。ref_2d和ref_3d的过程差不多,只是少了zs的计算,ref_2d的size为(1,2500,1,2)。
=======================================================================
ok,回到BEVFormerEncoder接着看
reference_points_cam, bev_mask = self.point_sampling(ref_3d, self.pc_range, kwargs['img_metas'])
self.point_sampling的作用是将bev queries的3D坐标系转换到摄像头的2D坐标系,并筛选出投影到图像上的有效点。通俗的说就是,我这2500×4个点到底对应你摄像头图片里哪些点了?以及对应的点的位置在哪?我们来看看是怎么操作的。
point_sampling
代码太长了,分批次讲解。
def point_sampling(self, reference_points, pc_range, img_metas):
# NOTE: close tf32 here.
allow_tf32 = torch.backends.cuda.matmul.allow_tf32
torch.backends.cuda.matmul.allow_tf32 = False
torch.backends.cudnn.allow_tf32 = False
lidar2img = []
for img_meta in img_metas:
lidar2img.append(img_meta['lidar2img'])
lidar2img = np.asarray(lidar2img)
lidar2img = reference_points.new_tensor(lidar2img) # (B, N, 4, 4)
从元数据img_metas里取出lidar2img,然后匹配成reference_points的dtype为(1,6,4,4),分别表示(batch,摄像头,4x4矩阵)。lidar2img就是已经准备好的4x4坐标变换矩阵,用于将3D点投影到2D图像平面。
reference_points = reference_points.clone()
reference_points[..., 0:1] = reference_points[..., 0:1] * \
(pc_range[3] - pc_range[0]) + pc_range[0]
reference_points[..., 1:2] = reference_points[..., 1:2] * \
(pc_range[4] - pc_range[1]) + pc_range[1]
reference_points[..., 2:3] = reference_points[..., 2:3] * \
(pc_range[5] - pc_range[2]) + pc_range[2]
reference_points = torch.cat(
(reference_points, torch.ones_like(reference_points[..., :1])), -1)
reference_points = reference_points.permute(1, 0, 2, 3)
D, B, num_query = reference_points.size()[:3]
num_cam = lidar2img.size(1)
reference_points = reference_points.view(
D, B, 1, num_query, 4).repeat(1, 1, num_cam, 1, 1).unsqueeze(-1)
lidar2img = lidar2img.view(
1, B, num_cam, 1, 4, 4).repeat(D, 1, 1, num_query, 1, 1)
reference_points_cam = torch.matmul(lidar2img.to(torch.float32),
reference_points.to(torch.float32)).squeeze(-1)
eps = 1e-5
bev_mask = (reference_points_cam[..., 2:3] > eps)
reference_points_cam = reference_points_cam[..., 0:2] / torch.maximum(
reference_points_cam[..., 2:3], torch.ones_like(reference_points_cam[..., 2:3]) * eps)
reference_points_cam[..., 0] /= img_metas[0]['img_shape'][0][1]
reference_points_cam[..., 1] /= img_metas[0]['img_shape'][0][0]
给reference_points从(x, y, z)扩展成(x, y, z, 1),以支持坐标变换计算,(1,4,2500,3)->(1,4,2500,4)。再经过一个维度转变为(4,1,2500,4)。因为bev queries要计算每个摄像头对应的点,所以扩展维度至6个摄像头(4,1,6,2500,4)。同理,扩展一下lidar2img为(4,1,6,2500,4),这样lidar2img与reference_points做矩阵乘法,获得转换的坐标系。此时它的size还是(4,1,6,2500,4),z坐标系上的数据还残留着,还未对应上摄像头。这个bev_mask一会说。下面reference_points_cam做了一个除以的操作,是除掉了z坐标系的数据,计算x和y的坐标,得到(4,1,6,2500,2),这时就只有xy的坐标了。此时reference_points_cam的理解为,bev queries上2500×4个点对应于6个摄像头的实际图像位置xy。通俗一点,每个BEV查询点在不同摄像头视角下的投影2D坐标。然后做个归一化。
bev_mask = (bev_mask & (reference_points_cam[..., 1:2] > 0.0)
& (reference_points_cam[..., 1:2] < 1.0)
& (reference_points_cam[..., 0:1] < 1.0)
& (reference_points_cam[..., 0:1] > 0.0))
if digit_version(TORCH_VERSION) >= digit_version('1.8'):
bev_mask = torch.nan_to_num(bev_mask)
else:
bev_mask = bev_mask.new_tensor(
np.nan_to_num(bev_mask.cpu().numpy()))
reference_points_cam = reference_points_cam.permute(2, 1, 3, 0, 4)
bev_mask = bev_mask.permute(2, 1, 3, 0, 4).squeeze(-1)
torch.backends.cuda.matmul.allow_tf32 = allow_tf32
torch.backends.cudnn.allow_tf32 = allow_tf32
return reference_points_cam, bev_mask
ok,现在我们来讲一下这个bev_mask。这bev queries上的点投影到了每个摄像头上,但是并不是每个点都是有效的,对于这些无效的点给mask掉,减少计算。一开始先过滤掉z <= 0的点,避免投影到相机后方,做一下简单的过滤。然后进一步过滤掉超出 (0,1) 范围的点,保证它们落在图像内部,因为刚刚reference_points_cam不是做的归一化操作了,它的范围就在(0,1)。后面就是简单的处理掉NaN,防止后续计算异常,然后再转换一下维度返回回去。reference_points_cam和bev_mask最终的size为(6,1,2500,4,2)和(6,1,2500,4)。
=======================================================================
回到BEVFormerEncoder,我们继续往下看。
shift_ref_2d = ref_2d.clone()
shift_ref_2d += shift[:, None, None, :]
# (num_query, bs, embed_dims) -> (bs, num_query, embed_dims)
bev_query = bev_query.permute(1, 0, 2)
bev_pos = bev_pos.permute(1, 0, 2)
bs, len_bev, num_bev_level, _ = ref_2d.shape
if prev_bev is not None:
prev_bev = prev_bev.permute(1, 0, 2)
prev_bev = torch.stack(
[prev_bev, bev_query], 1).reshape(bs * 2, len_bev, -1)
hybird_ref_2d = torch.stack([shift_ref_2d, ref_2d], 1).reshape(
bs * 2, len_bev, num_bev_level, 2)
else:
hybird_ref_2d = torch.stack([ref_2d, ref_2d], 1).reshape(
bs * 2, len_bev, num_bev_level, 2)
shift是之前帧的视角偏移量。调整bev_query和bev_pos维度为(1,2500,256)。检查一下有没有前一帧的bev特征,如果有就给拼接在一起,然后将偏移后的bev视角与原始bev视角拼接在一起。如果还没有前一帧的数据,就直接将ref_2d复制两份,因为后续的操作里会做一个平均。
for lid, layer in enumerate(self.layers):
output = layer(
bev_query,
key,
value,
*args,
bev_pos=bev_pos,
ref_2d=hybird_ref_2d,
ref_3d=ref_3d,
bev_h=bev_h,
bev_w=bev_w,
spatial_shapes=spatial_shapes,
level_start_index=level_start_index,
reference_points_cam=reference_points_cam,
bev_mask=bev_mask,
prev_bev=prev_bev,
**kwargs)
这for循环的说道可深了,我们进去看看做了啥。
encoder
来到路径projects/mmdet3d_plugin/bevformer/modules/encoder.py下BEVFormerLayer的forward。
def forward(self,
query,
key=None,
value=None,
bev_pos=None,
query_pos=None,
key_pos=None,
attn_masks=None,
query_key_padding_mask=None,
key_padding_mask=None,
ref_2d=None,
ref_3d=None,
bev_h=None,
bev_w=None,
reference_points_cam=None,
mask=None,
spatial_shapes=None,
level_start_index=None,
prev_bev=None,
**kwargs):
norm_index = 0
attn_index = 0
ffn_index = 0
identity = query
if attn_masks is None:
attn_masks = [None for _ in range(self.num_attn)]
elif isinstance(attn_masks, torch.Tensor):
attn_masks = [
copy.deepcopy(attn_masks) for _ in range(self.num_attn)
]
warnings.warn(f'Use same attn_mask in all attentions in '
f'{self.__class__.__name__} ')
else:
assert len(attn_masks) == self.num_attn, f'The length of ' \
f'attn_masks {len(attn_masks)} must be equal ' \
f'to the number of attention in ' \
f'operation_order {self.num_attn}'
for layer in self.operation_order:
# temporal self attention
if layer == 'self_attn':
query = self.attentions[attn_index](
query,
prev_bev,
prev_bev,
identity if self.pre_norm else None,
query_pos=bev_pos,
key_pos=bev_pos,
attn_mask=attn_masks[attn_index],
key_padding_mask=query_key_padding_mask,
reference_points=ref_2d,
spatial_shapes=torch.tensor(
[[bev_h, bev_w]], device=query.device),
level_start_index=torch.tensor([0], device=query.device),
**kwargs)
attn_index += 1
identity = query
elif layer == 'norm':
query = self.norms[norm_index](query)
norm_index += 1
# spaital cross attention
elif layer == 'cross_attn':
query = self.attentions[attn_index](
query,
key,
value,
identity if self.pre_norm else None,
query_pos=query_pos,
key_pos=key_pos,
reference_points=ref_3d,
reference_points_cam=reference_points_cam,
mask=mask,
attn_mask=attn_masks[attn_index],
key_padding_mask=key_padding_mask,
spatial_shapes=spatial_shapes,
level_start_index=level_start_index,
**kwargs)
attn_index += 1
identity = query
elif layer == 'ffn':
query = self.ffns[ffn_index](
query, identity if self.pre_norm else None)
ffn_index += 1
return query
这部分主要是注意力机制模块的计算,在self.operation_order包括了('self_attn', 'norm', 'cross_attn','norm', 'ffn', 'norm'),可以看到需要依次做自注意力、交叉注意力和多尺度。我们分别进去看看怎么做的。
TemporalSelAttention
路径projects/mmdet3d_plugin/bevformer/modules/temporal_self_attention.py下TemporalSelAttention的forward。代码还是很长,分批次说。
def forward(self,
query,
key=None,
value=None,
identity=None,
query_pos=None,
key_padding_mask=None,
reference_points=None,
spatial_shapes=None,
level_start_index=None,
flag='decoder',
**kwargs):
if value is None:
assert self.batch_first
bs, len_bev, c = query.shape
value = torch.stack([query, query], 1).reshape(bs * 2, len_bev, c)
if identity is None:
identity = query
if query_pos is not None:
query = query + query_pos
if not self.batch_first:
# change to (bs, num_query ,embed_dims)
query = query.permute(1, 0, 2)
value = value.permute(1, 0, 2)
bs, num_query, embed_dims = query.shape
_, num_value, _ = value.shape
assert (spatial_shapes[:, 0] * spatial_shapes[:, 1]).sum() == num_value
assert self.num_bev_queue == 2
query = torch.cat([value[:bs], query], -1)
value = self.value_proj(value)
if key_padding_mask is not None:
value = value.masked_fill(key_padding_mask[..., None], 0.0)
value = value.reshape(bs * self.num_bev_queue,
num_value, self.num_heads, -1)
valu将query复制两次,用于历史BEV和当前BEV,size为(2,2500,256)。query加上位置编码,再拼接上历史BEV和当前BEV,size为(2,2500,512)。给value连个全连接映射一下特征,不过输出还是256维度,所以size还是(2,2500,256)。给value做个reshape为(2,2500,8,32),这个8太熟悉了吧,一眼注意力头。
sampling_offsets = self.sampling_offsets(query)
sampling_offsets = sampling_offsets.view(
bs, num_query, self.num_heads, self.num_bev_queue, self.num_levels, self.num_points, 2)
attention_weights = self.attention_weights(query).view(
bs, num_query, self.num_heads, self.num_bev_queue, self.num_levels * self.num_points)
attention_weights = attention_weights.softmax(-1)
attention_weights = attention_weights.view(bs, num_query,
self.num_heads,
self.num_bev_queue,
self.num_levels,
self.num_points)
attention_weights = attention_weights.permute(0, 3, 1, 2, 4, 5) \
.reshape(bs * self.num_bev_queue, num_query, self.num_heads, self.num_levels, self.num_points).contiguous()
sampling_offsets = sampling_offsets.permute(0, 3, 1, 2, 4, 5, 6) \
.reshape(bs * self.num_bev_queue, num_query, self.num_heads, self.num_levels, self.num_points, 2)
if reference_points.shape[-1] == 2:
offset_normalizer = torch.stack(
[spatial_shapes[..., 1], spatial_shapes[..., 0]], -1)
sampling_locations = reference_points[:, :, None, :, None, :] \
+ sampling_offsets \
/ offset_normalizer[None, None, None, :, None, :]
elif reference_points.shape[-1] == 4:
sampling_locations = reference_points[:, :, None, :, None, :2] \
+ sampling_offsets / self.num_points \
* reference_points[:, :, None, :, None, 2:] \
* 0.5
else:
raise ValueError(
f'Last dim of reference_points must be'
f' 2 or 4, but get {reference_points.shape[-1]} instead.')
好,这里重点就是计算sampling_offsets和attention_weights,即偏移量和权重值。这部分内容和可变DETR是一样的,大家可以先学习一下可变DETR,再看这个会轻松很多。这里简单解释一下,自注意机制正常是计算每个点与其他所有点的关系,这显然计算量巨大,而且显然,每个点可能只和整个图片上部分点有关系,这计算了全部的点很多都是无用功。于是可变DETR提出,每个点采样4个点,只与这4个点做计算,而且这4个点还有一个可学习的权重值,来计算这四个点与这个点的重要性关系。
sampling_offsets生成采样偏移量,就是对于当前这个点的位置偏移多少,这个偏移的位置就是要采样的点。经过一个全连接size为(1,2500,128),然后view为(1,2500,8,2,1,4,2),分别表示(.,.,注意力头,历史+当前,单尺度,每个位置采样4个点,xy偏移坐标)。然后计算注意力权重,经过一个全连接size为(1,2500,64),接着view为(1,2500,8,2,4),然后再softmax一下。将sampling_offsets和attention_weights再reshape回原来的样子,分别为(2,2500,8,1,4,2)和 (2,2500,8,1,4)。
ok,现在每个点的偏移量计算出来了,就可以计算每个点的采样位置了。offset_normalizer是用来做归一化的,sampling_locations里存的就是采样位置,size为(2,2500,8,1,4,2)。
if torch.cuda.is_available() and value.is_cuda:
# using fp16 deformable attention is unstable because it performs many sum operations
if value.dtype == torch.float16:
MultiScaleDeformableAttnFunction = MultiScaleDeformableAttnFunction_fp32
else:
MultiScaleDeformableAttnFunction = MultiScaleDeformableAttnFunction_fp32
output = MultiScaleDeformableAttnFunction.apply(
value, spatial_shapes, level_start_index, sampling_locations,
attention_weights, self.im2col_step)
else:
output = multi_scale_deformable_attn_pytorch(
value, spatial_shapes, sampling_locations, attention_weights)
# output shape (bs*num_bev_queue, num_query, embed_dims)
# (bs*num_bev_queue, num_query, embed_dims)-> (num_query, embed_dims, bs*num_bev_queue)
output = output.permute(1, 2, 0)
# fuse history value and current value
# (num_query, embed_dims, bs*num_bev_queue)-> (num_query, embed_dims, bs, num_bev_queue)
output = output.view(num_query, embed_dims, bs, self.num_bev_queue)
output = output.mean(-1)
# (num_query, embed_dims, bs)-> (bs, num_query, embed_dims)
output = output.permute(2, 0, 1)
output = self.output_proj(output)
if not self.batch_first:
output = output.permute(1, 0, 2)
return self.dropout(output) + identity
调用 MultiScaleDeformableAttnFunction 进行注意力计算,输入value,采样点位置,采样点权重,输出output包含历史BEV和当前BEV的融合信息,size为(2,2500,256)。最后做一些维度转变,做个平均(这里就是我上面说的hybird_ref_2d在没有之前帧时会将red_2d复制两份的原因,因为后续会做个平均),连接全连接做个残差连接得到最终的结果。
ok,self_attn部分说完,我们再来看看cross_attn部分。
TemporalSelfAttention
路径projects/mmdet3d_plugin/bevformer/modules/spatial_cross_attention.py下TemporalSelfAttention的forward。代码较长,分批次讲解。
def forward(self,
query,
key,
value,
residual=None,
query_pos=None,
key_padding_mask=None,
reference_points=None,
spatial_shapes=None,
reference_points_cam=None,
bev_mask=None,
level_start_index=None,
flag='encoder',
**kwargs):
if key is None:
key = query
if value is None:
value = key
if residual is None:
inp_residual = query
slots = torch.zeros_like(query)
if query_pos is not None:
query = query + query_pos
bs, num_query, _ = query.size()
D = reference_points_cam.size(3)
indexes = []
for i, mask_per_img in enumerate(bev_mask):
index_query_per_img = mask_per_img[0].sum(-1).nonzero().squeeze(-1)
indexes.append(index_query_per_img)
max_len = max([len(each) for each in indexes])
for循环遍历每个摄像头,查找每个摄像头与BEV查询点有关的索引。比如index_query_per_img的size为393,表示这个摄像头的图片中有393个点与bev查询点有关。那么遍历每个摄像头,难免会有重复的,比如摄像头1和摄像头2都看上了bev上同一个查询点,不慌,下面会取平均。现在遍历完后,查询到的有效点索引放在indexes中,找到有效点最多的那个为max_len。
queries_rebatch = query.new_zeros(
[bs, self.num_cams, max_len, self.embed_dims])
reference_points_rebatch = reference_points_cam.new_zeros(
[bs, self.num_cams, max_len, D, 2])
for j in range(bs):
for i, reference_points_per_img in enumerate(reference_points_cam):
index_query_per_img = indexes[i]
queries_rebatch[j, i, :len(index_query_per_img)] = query[j, index_query_per_img]
reference_points_rebatch[j, i, :len(index_query_per_img)] = reference_points_per_img[j, index_query_per_img]
重新构建query为queries_rebatch,它的长度就为刚刚的max_len。这样的好处显而易见,原来的长度是2500,我现在为max_len,一定小于2500,节省了一些内存。因为初始化是零向量,所以那些不足max_len个有效点的补零。queries_rebatch和reference_points_rebatch的size分别为(1,6,max_len,256)和(1,6,max_len,4,2)。经过for循环,通过刚刚的有效点索引indexs,赋值给queries_rebatch和reference_points_rebatch。
num_cams, l, bs, embed_dims = key.shape
key = key.permute(2, 0, 1, 3).reshape(
bs * self.num_cams, l, self.embed_dims)
value = value.permute(2, 0, 1, 3).reshape(
bs * self.num_cams, l, self.embed_dims)
queries = self.deformable_attention(query=queries_rebatch.view(bs * self.num_cams, max_len, self.embed_dims),
key=key, value=value,
reference_points=reference_points_rebatch.view(bs * self.num_cams, max_len, D,
2),
spatial_shapes=spatial_shapes,
level_start_index=level_start_index).view(bs, self.num_cams, max_len,
self.embed_dims)
for j in range(bs):
for i, index_query_per_img in enumerate(indexes):
slots[j, index_query_per_img] += queries[j, i, :len(index_query_per_img)]
count = bev_mask.sum(-1) > 0
count = count.permute(1, 2, 0).sum(-1)
count = torch.clamp(count, min=1.0)
slots = slots / count[..., None]
slots = self.output_proj(slots)
return self.dropout(slots) + inp_residual
对key,value维度reshape一下,带入到self.deformable_attention计算每个摄像头对查询点的注意力,输出size为(1,6,max_len,256)。
slots的size为(1,2500,256),光看这个size就知道是用来存储query结果的。之前说过,BEV查询点可能与多个摄像头相关联,所以不能直接赋值给slots,需要将多个 queries 进行加权聚合。count用于统计每个BEV查询点涉及的摄像头数量,不过它的最小值为1,因为需要取平均,不能除以0。最后连一个全连接层,丢弃一些,做个残差连接,返回最终结果,size为(1,2500,256),表示融合了多摄像头特征的 BEV查询特征。
剩下的都是重复的东西了,在你疯狂debug下一步的时候,debug回了远古的bevformer.py下的obtain_history_bev,惊讶的发现,omg,刚刚做的一切都是计算历史信息的,而且计算的是前两帧的信息,而现在你要继续将原来的路走一遍取计算前一帧的信息。这部分内容甚至没有梯度下降,因为还没计算当前帧的信息。
=======================================================================
回到projects/mmdet3d_plugin/bevformer/detectors/bevformer.py下BEVFormer的forward_train,我们继续往下看。
img_metas = [each[len_queue - 1] for each in img_metas]
if not img_metas[0]['prev_bev_exists']:
prev_bev = None
img_feats = self.extract_feat(img=img, img_metas=img_metas)
losses = dict()
losses_pts = self.forward_pts_train(img_feats, gt_bboxes_3d,
gt_labels_3d, img_metas,
gt_bboxes_ignore, prev_bev)
losses.update(losses_pts)
return losses
坏消息,刚刚走了一圈计算的都是历史信息。好消息,现在计算真正的当前帧信息,要走的self.extract_feat与计算历史信息的路子一模一样,不用重复看啦!返回的img_feats,size为(1,6,256,15,25)。
这个时候,BEV queries已经做好了,而且每次都是参考前一次的BEV queries做的。做这个BEV queries的目的是啥,预测啊,归根到底就是要做目标检测,现在就要进入到decoder的过程啦。我们来看看self.forward_pts_train是怎么做的。
forward_pts_train
def forward_pts_train(self,
pts_feats,
gt_bboxes_3d,
gt_labels_3d,
img_metas,
gt_bboxes_ignore=None,
prev_bev=None):
outs = self.pts_bbox_head(
pts_feats, img_metas, prev_bev)
loss_inputs = [gt_bboxes_3d, gt_labels_3d, outs]
losses = self.pts_bbox_head.loss(*loss_inputs, img_metas=img_metas)
return losses
很显然啊,分了两步走,预测bbox和计算loss。这个 self.pts_bbox_head怎么那么眼熟啊,是不是刚刚在哪见过?没错,上面其实讲过这个方法了,但是这次我们走了另一条支线。我们进去看看怎么个事
pts_bbox_head
来到projects/mmdet3d_plugin/bevformer/dense_heads/bevformer_head.py的BEVFormerHead下的forward,代码较长,分批讲解。
def forward(self, mlvl_feats, img_metas, prev_bev=None, only_bev=False):
bs, num_cam, _, _, _ = mlvl_feats[0].shape
dtype = mlvl_feats[0].dtype
object_query_embeds = self.query_embedding.weight.to(dtype)
bev_queries = self.bev_embedding.weight.to(dtype)
bev_mask = torch.zeros((bs, self.bev_h, self.bev_w),
device=bev_queries.device).to(dtype)
bev_pos = self.positional_encoding(bev_mask).to(dtype)
if only_bev: # only use encoder to obtain BEV features, TODO: refine the workaround
return self.transformer.get_bev_features(
mlvl_feats,
bev_queries,
self.bev_h,
self.bev_w,
grid_length=(self.real_h / self.bev_h,
self.real_w / self.bev_w),
bev_pos=bev_pos,
img_metas=img_metas,
prev_bev=prev_bev,
)
else:
outputs = self.transformer(
mlvl_feats,
bev_queries,
object_query_embeds,
self.bev_h,
self.bev_w,
grid_length=(self.real_h / self.bev_h,
self.real_w / self.bev_w),
bev_pos=bev_pos,
reg_branches=self.reg_branches if self.with_box_refine else None, # noqa:E501
cls_branches=self.cls_branches if self.as_two_stage else None,
img_metas=img_metas,
prev_bev=prev_bev
)
这部分代码是不是很眼熟,我们之前走的是if only_bev:这条路,走完直接return回去了,而这一次,我们要走else:这条路。
这条路也有很多部分是重复的,比如自注意力、交叉注意力这些我就不重复说了,我主要讲一下不一样的地方。上次讲我说不管这个object_query_embeds,但这次就要管一管了。看一下它的size为(900,512),可以这样理解,我们现在需要找bbox在哪,于是雇佣了900个工人,每个工人的维度和query是一样的256,这里为什么是512呢,因为初始化的时候顺便排了个位置,后面会给分开的,ok开始干活。
transformer
跳到路径projects/mmdet3d_plugin/bevformer/modules/transformer.py下PerceptionTransformer的forward。
def forward(self,
mlvl_feats,
bev_queries,
object_query_embed,
bev_h,
bev_w,
grid_length=[0.512, 0.512],
bev_pos=None,
reg_branches=None,
cls_branches=None,
prev_bev=None,
**kwargs):
bev_embed = self.get_bev_features(
mlvl_feats,
bev_queries,
bev_h,
bev_w,
grid_length=grid_length,
bev_pos=bev_pos,
prev_bev=prev_bev,
**kwargs) # bev_embed shape: bs, bev_h*bev_w, embed_dims
bs = mlvl_feats[0].size(0)
query_pos, query = torch.split(
object_query_embed, self.embed_dims, dim=1)
query_pos = query_pos.unsqueeze(0).expand(bs, -1, -1)
query = query.unsqueeze(0).expand(bs, -1, -1)
reference_points = self.reference_points(query_pos)
reference_points = reference_points.sigmoid()
init_reference_out = reference_points
query = query.permute(1, 0, 2)
query_pos = query_pos.permute(1, 0, 2)
bev_embed = bev_embed.permute(1, 0, 2)
inter_states, inter_references = self.decoder(
query=query,
key=None,
value=bev_embed,
query_pos=query_pos,
reference_points=reference_points,
reg_branches=reg_branches,
cls_branches=cls_branches,
spatial_shapes=torch.tensor([[bev_h, bev_w]], device=query.device),
level_start_index=torch.tensor([0], device=query.device),
**kwargs)
inter_references_out = inter_references
return bev_embed, inter_states, init_reference_out, inter_references_out
self.get_bev_features走的路子其实和之前是一样的,我就不重复去代码里讲了,我简单的讲一下干了啥,其实也都是刚刚干的事。输入的prev_bev是前一时刻的bev,bev_queries是当前时刻的bev,现在要做一个对齐,然后再平均一下。做完对齐后bev查询点与谁去算呢?就是这个mlvl_feats,跟6个摄像头的图去算。首先找到对应的位置,找到之后进行采样,采样完去走self_atten和cross_atten,来计算每个query的向量。
接着回来,将900个工人劈开,分为query_pos和query。给query_pos经过一个全连接self.reference_points,输出reference_points的size为(1,900,3),表示每个工人感兴趣的位置xyz。去看看self.decoder干了啥。
decoder
路径projects/mmdet3d_plugin/bevformer/modules/decoder.py下DetectionTransformerDecoder的forward。
def forward(self,
query,
*args,
reference_points=None,
reg_branches=None,
key_padding_mask=None,
**kwargs):
output = query
intermediate = []
intermediate_reference_points = []
for lid, layer in enumerate(self.layers):
reference_points_input = reference_points[..., :2].unsqueeze(
2) # BS NUM_QUERY NUM_LEVEL 2
output = layer(
output,
*args,
reference_points=reference_points_input,
key_padding_mask=key_padding_mask,
**kwargs)
output = output.permute(1, 0, 2)
if reg_branches is not None:
tmp = reg_branches[lid](output)
assert reference_points.shape[-1] == 3
new_reference_points = torch.zeros_like(reference_points)
new_reference_points[..., :2] = tmp[
..., :2] + inverse_sigmoid(reference_points[..., :2])
new_reference_points[..., 2:3] = tmp[
..., 4:5] + inverse_sigmoid(reference_points[..., 2:3])
new_reference_points = new_reference_points.sigmoid()
reference_points = new_reference_points.detach()
output = output.permute(1, 0, 2)
if self.return_intermediate:
intermediate.append(output)
intermediate_reference_points.append(reference_points)
if self.return_intermediate:
return torch.stack(intermediate), torch.stack(
intermediate_reference_points)
return output, reference_points
这里构建了两个list,一会构建一个级联网络,这里面会存放中间的结果。下面的这个for循环就是6个级联。上面有说过reference_points存放的是900个工人对bev queries感兴趣的xyz,这里的reference_points_input只取xy的,size为(1,900,1,2)。
这个ouput走的东西不在源码里,但其实走的过程和之前差不多,就对query做了self_attn,然后接着走cross_attn,最后输出的output的size为(900,1,256)。
reg_branches是来预测目标框的偏移参数。我刚刚不是说这是一个级联网络嘛,可以这样理解,这个偏移我不是一次就预测出来的,我分了六次,我每次都在前一次的基础上再调整调整。就像倒车一样,左边来一点,哎好,往后倒一点,停,再往左边来点…所以tmp存放着,以当前位置为基准的情况下,应该再往哪去偏。tmp的size为(1,900,10),表示900个工人,每个工人找到一个框,每个框包含10个参数,分别为目标框的xyz坐标、目标框的长宽高、θ旋转角度和xyz轴方向的速度。
因为之前做reference_points时,对其进行了sigmoid,所以这里进行一个逆变换inverse_sigmoid,将其转为实际的坐标位置。实际的位置再加上预测出来的偏移量,就得到了实际的偏移后的位置。[:2]预测的xy坐标偏移量,[4:5]预测的z坐标偏移量。得到了真实值后再做sigmoid,因为做注意力机制偏移的时候不能传进去的是绝对值,需要相对值。然后将刚刚的结果存放再那两个list里面,intermediate存放的是中间结果,ntermediate_reference_points存放的是中间的参考点。
再次for循环,layer输入的reference_points是刚刚校正之后的。循环结束,返回回去,得到预测目标框的结果。
测试及可视化展示
官方提供了一个测试,可视化展示的模块,我们来看看。
在tools/test.py。直接跑这个应该是跑不起来的,尤其对于单卡来说。不过官方提供了一个脚本dist_test.sh。
#!/usr/bin/env bash
CONFIG=$1
CHECKPOINT=$2
GPUS=$3
PORT=${PORT:-29503}
PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
python -m torch.distributed.launch --nproc_per_node=$GPUS --master_port=$PORT \
$(dirname "$0")/test.py $CONFIG $CHECKPOINT --launcher pytorch ${@:4} --eval bbox
需要配置CONFIG模型参数、CHECKPOINT预训练模型位置、GPUS个数。下图是我运行的参数,大家改成自己的路径就行。

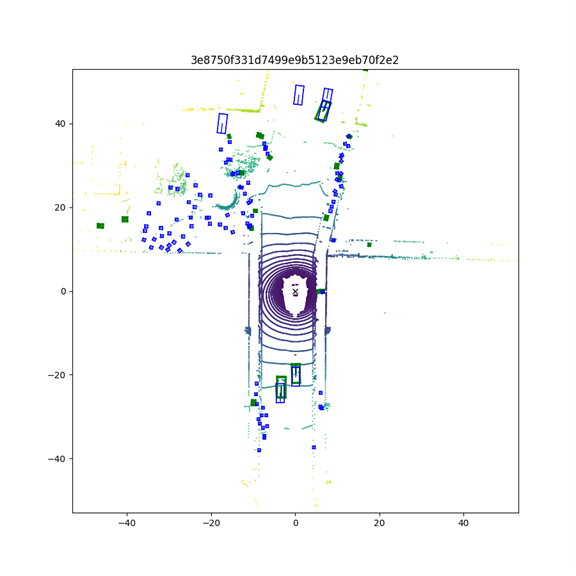
跑完后会在tools目录下生成一个test文件。官方还提供了可视化的文件,在tools/analysis_tools/visual.py,我们拖到最下面。
if __name__ == '__main__':
nusc = NuScenes(version='v1.0-trainval', dataroot='./data/nuscenes', verbose=True)
# render_annotation('7603b030b42a4b1caa8c443ccc1a7d52')
bevformer_results = mmcv.load('test/bevformer_base/Thu_Jun__9_16_22_37_2022/pts_bbox/results_nusc.json')
sample_token_list = list(bevformer_results['results'].keys())
for id in range(0, 10):
render_sample_data(sample_token_list[id], pred_data=bevformer_results, out_path=sample_token_list[id])
将dataroot和bevformer_results改为自己的绝对路径,运行!
给大家看一下绘制的图片

运行环境安装
环境的配置官方其实给了,主要是帮大家避一些坑。
官方安装链接:Installation
这里面用的版本都很老了,但是防止一些不必要的bug,还是老老实实的用吧。
这里用的cuda是11.1的,估计很多人现在用的都是12往上的版本了,给电脑重新安装一个更老的cuda肯定不合适的,所以这里直接在conda环境里安装一个就行。
conda install cudatoolkit=11.1 cudnn -c nvidia -c conda-forge
然后安装pytorch
conda install pytorch==1.9.1 torchvision==0.10.1 torchaudio==0.9.1 cudatoolkit=11.1 -c pytorch -c conda-forge
下面跟官方里的一样就行,不过在这里最好添加一步
git clone https://github.com/open-mmlab/mmdetection3d.git
cd mmdetection3
git checkout v0.17.1 # Other versions may not be compatible.
pip install -v -e . # 添加这一步
python setup.py install

















 1472
1472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









