






RT-DETRv3: Real-time End-to-End Object Detection with Hierarchical Dense Positive Supervision
RT-DETRv3: Real-time End-to-End Object Detection with Hierarchical Dense Positive Supervision
RT-DETRv3:具有层次化密集正向监督的实时端到端目标检测
摘要
RT-DETR是首个基于变换器的实时端到端目标检测器。其高效性来源于框架设计和匈牙利匹配。然而,与YOLO系列等密集监督检测器相比,匈牙利匹配提供的监督更加稀疏,导致模型训练不足,难以实现最佳结果。为了解决这些问题,我们提出了一种基于RT-DETR的层次化密集正向监督方法,命名为RT-DETRv3。首先,我们引入了一个基于CNN的辅助分支,提供密集的监督,并与原始解码器协作,以增强编码器的特征表示。其次,为了解决解码器训练不足的问题,我们提出了一种新颖的学习策略,涉及自注意力扰动。该策略通过多组查询对正样本进行多样化标签分配,从而丰富正向监督。此外,我们还引入了一个共享权重的解码器分支,用于密集正向监督,确保更多高质量的查询匹配每个真实标签。值得注意的是,所有上述模块仅用于训练。我们进行了大量实验,证明了我们方法在COCO val2017上的有效性。RT-DETRv3显著超越了现有的实时检测器,包括RT-DETR系列和YOLO系列。例如,RT-DETRv3-R18相比RT-DETR-R18/RT-DETRv2-R18,AP提升了1.6%/1.4%,同时保持相同的延迟。此外,RT-DETRv3-R101可以达到令人印象深刻的54.6% AP,超越了YOLOv10-X。代码将发布在 https://github.com/clxia12/RT-DETRv3
介绍
目标检测是计算机视觉中的一个重要基础问题,主要集中在获取图像中物体的位置和类别信息。实时目标检测对算法性能有更高的要求,例如推理速度要大于30 FPS。在自动驾驶、视频监控和物体跟踪等实际应用中,实时目标检测具有巨大的价值。近年来,由于其高效的推理速度和优越的检测准确性,实时目标检测引起了研究人员和工业界专业人士的广泛关注。在这些方法中,基于CNN的单阶段实时目标检测器最为流行,例如YOLO系列。它们都采用了一对多标签分配策略,设计了高效的推理框架,并使用非最大抑制(NMS)来过滤冗余的预测结果。尽管这种策略引入了额外的延迟,但它们在准确性和速度之间实现了折衷。
DETR是第一个基于变换器的端到端目标检测算法。它采用集合预测,并通过匈牙利匹配策略进行优化,消除了NMS后处理的需求,从而简化了目标检测过程。随后的DETR系列(如DAB-DETR、DINO和DN-DETR等)进一步引入了迭代细化方案和去噪训练,有效加速了模型的收敛速度,并提高了其性能。然而,它的高计算复杂度显著限制了其实际应用。
RT-DETR是第一个基于变换器的实时端到端目标检测算法。它设计了高效的混合编码器和IoU感知查询选择模块,以及可扩展的解码器层,取得了比其他实时检测器更好的结果。然而,匈牙利匹配策略在训练过程中提供了稀疏的监督,导致编码器和解码器的训练不足,限制了该方法的最佳性能。RT-DETRv2通过优化训练策略进一步增强了RT-DETR的灵活性和实用性,在不牺牲速度的情况下提高了性能,尽管需要更长的训练时间。为了有效解决目标检测中的稀疏监督问题,我们提出了一种层次化密集正向监督方法,通过在训练过程中引入多个辅助分支,能够有效加速模型收敛并增强模型性能。我们的主要贡献如下:
基于CNN的实时目标检测
当前基于CNN的实时目标检测器主要是YOLO系列。YOLOv4和YOLOv5优化了网络架构(例如,采用了CSPNet和PAN),同时还利用了Mosaic数据增强。YOLOv6进一步优化了结构,包括使用了RepVGG主干网络、解耦头、SimSPPF和更有效的训练策略(例如,SimOTA等)。YOLOv7引入了E-ELAN注意力模块,以更好地整合不同层次的特征,并采用自适应锚点机制以改善小物体检测。YOLOv8提出了C2f模块,用于有效的特征提取和融合。YOLOv9提出了一种新的GELAN架构,并设计了PGI以增强训练过程。PP-YOLO系列是基于百度的PaddlePaddle框架提出的实时目标检测解决方案。该系列算法在YOLO系列的基础上进行了优化和改进,旨在提高检测准确性和速度,以满足实际应用场景的需求。
基于变换器的实时目标检测
RT-DETR是第一个实时端到端目标检测器。该方法设计了一种高效的混合编码器,通过解耦尺度内交互和跨尺度融合,有效处理多尺度特征,并提出了IoU感知查询选择,通过为解码器提供更高质量的初始物体查询,进一步提升了性能。其准确性和速度优于同期的YOLO系列,并受到了广泛关注。RT-DETRv2进一步优化了训练策略,包括动态数据增强和优化的采样操作,便于部署,进一步提高了模型性能。然而,由于其一对一的稀疏监督,导致了收敛速度和最终效果的限制。因此,引入一对多标签分配策略可以进一步提升模型的性能。
辅助训练策略
Co-DETR提出了多个并行的一对多标签分配辅助头训练策略(例如,ATSS和Faster RCNN),这些策略可以轻松增强端到端检测器中编码器的学习能力。例如,ViT-CoMer与Co-DETR的结合在COCO检测任务上取得了最先进的性能。DAC-DETR、MS-DETR和GroupDETR主要通过向模型的解码器添加一对多监督信息来加速模型的收敛。这些方法通过在模型的不同位置添加额外的辅助分支来加速收敛或提高模型的性能,但它们并不是实时目标检测器。受到这些方法的启发,我们在RT-DETR的编码器和解码器中引入了多个一对多辅助密集监督模块。这些模块增强了RT-DETR的收敛速度,并提高了整体性能。由于这些模块仅在训练阶段参与,它们不会影响RT-DETR的推理延迟。
方法
总体架构
RT-DETRv3的整体结构如图2所示。我们保留了RT-DETR的整体框架(黄色高亮部分),并进一步引入了我们提出的层次化解耦密集监督方法(绿色高亮部分)。首先,输入图像通过CNN主干网络(例如,ResNet)和一个特征融合模块,称为高效混合编码器,处理以获取多尺度特征{C3、C4和C5}。这些特征随后被并行输入到基于CNN的一对多辅助分支和基于变换器的解码器分支中。
对于基于CNN的一对多辅助分支,我们直接采用现有的最先进的密集监督方法,如PP-YOLOE,以协同监督编码器的表示学习。在基于变换器的解码器分支中,首先将多尺度特征展平并进行拼接。接着,我们使用查询选择模块从中选择前k个特征,以生成物体查询。在解码器内,我们引入了一个掩膜生成器,生成多个随机掩膜集合。这些掩膜被应用到自注意力模块中,影响查询之间的关联,从而区分正查询的分配。每个随机掩膜集合与一个对应的查询配对,如图2中的◎Q.2.-1,…,◎Q.2.-n所示。此外,为了确保每个真实标签有更多高质量的查询匹配,我们在解码器中加入了一对多标签分配分支。以下各节将详细描述本文提出的模块。
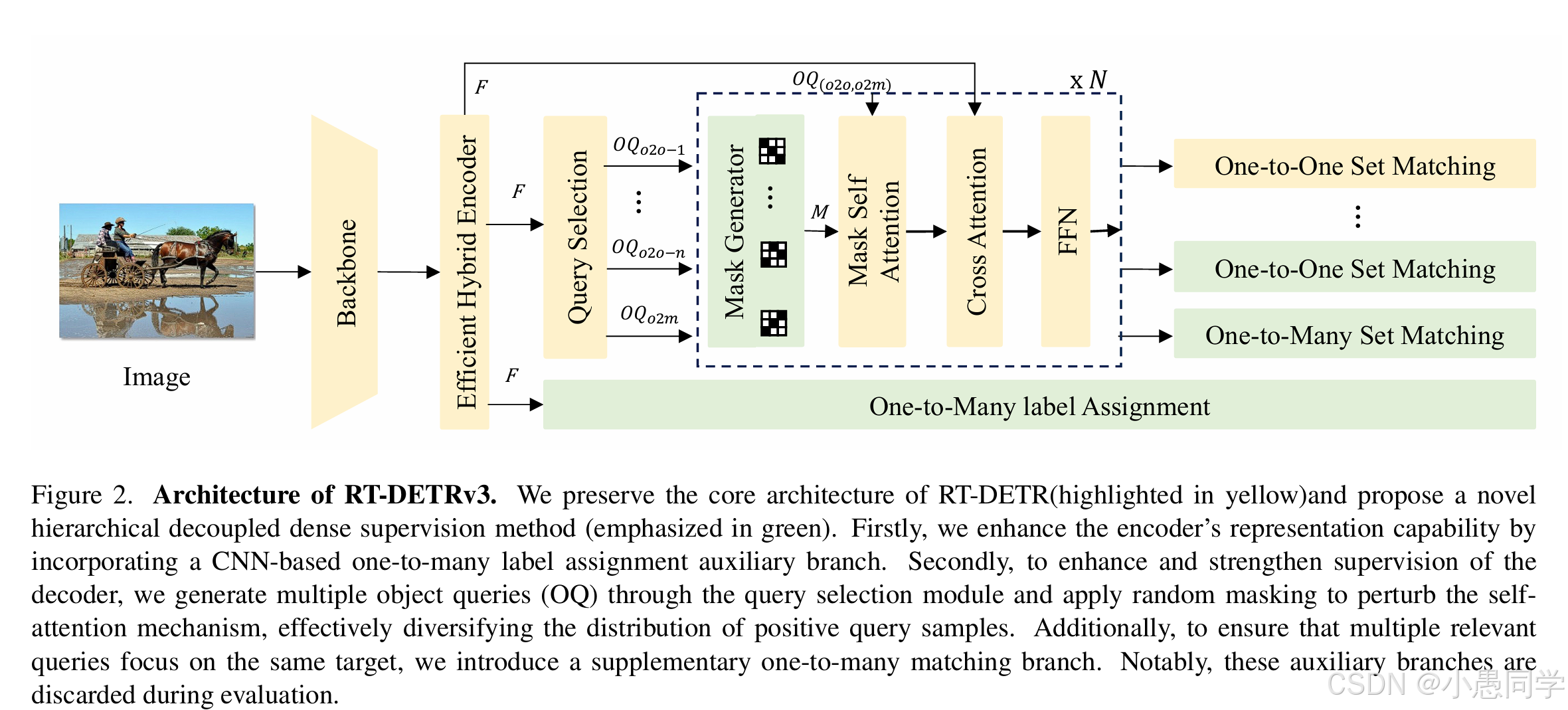
图2. RT-DETRv3的架构。我们保留了RT-DETR的核心架构(黄色高亮部分),并提出了一种新颖的层次化解耦密集监督方法(绿色高亮部分)。首先,我们通过引入基于CNN的一对多标签分配辅助分支来增强编码器的表示能力。其次,为了增强并强化对解码器的监督,我们通过查询选择模块生成多个物体查询(OQ),并应用随机掩膜来扰动自注意力机制,有效多样化正查询样本的分布。此外,为确保多个相关查询关注相同目标,我们引入了一个补充的一对多匹配分支。值得注意的是,这些辅助分支在评估过程中会被丢弃。
RT-DETR综述
RT-DETR是为目标检测任务设计的实时检测框架。它结合了DETR的端到端预测优势,同时优化了推理速度和检测准确性。为了实现实时性能,RT-DETR将编码器模块替换为轻量级的CNN主干网络,并设计了高效的混合编码器模块,用于高效的特征融合。RT-DETR提出了一个不确定性最小化查询选择模块,用于选择高置信度特征作为物体查询,从而减少查询优化的难度。随后,解码器的多个层通过自注意力、交叉注意力和前馈网络(FFN)模块增强这些查询,预测结果由MLP层生成。在训练优化过程中,RT-DETR采用匈牙利匹配进行一对一分配。在损失计算方面,RT-DETR使用L1损失和GIoU损失来监督框回归,并使用变焦损失(VFL)来监督分类任务的学习。
基于CNN的一对多辅助分支
为了解决由于解码器的一对一集合匹配方案导致编码器输出的稀疏监督问题,我们引入了一个具有一对多分配的辅助检测头,例如PP-YOLOE。该策略可以有效加强编码器的监督,使其具备足够的表示能力,从而加速模型的收敛。具体而言,我们将编码器的输出特征{C3、C4和C5}直接集成到PP-YOLOE头中。
对于一对多匹配算法,我们遵循PP-YOLOE头的配置,在训练初期使用ATSS匹配算法,随后切换到TaskAlign匹配算法。在分类和定位任务的学习中,分别选择了VFL和分布式聚焦损失(DFL)。其中,VFL使用IoU得分作为正样本的目标,这使得具有高IoU的正样本在损失中占据较大比重,从而使得模型在训练过程中更关注高质量样本,而不是低质量样本。具体来说,解码器头部也使用VFL损失,以确保任务定义的一致性。我们将CNN辅助分支的总体损失表示为Laux,且相应的损失权重表示为α。
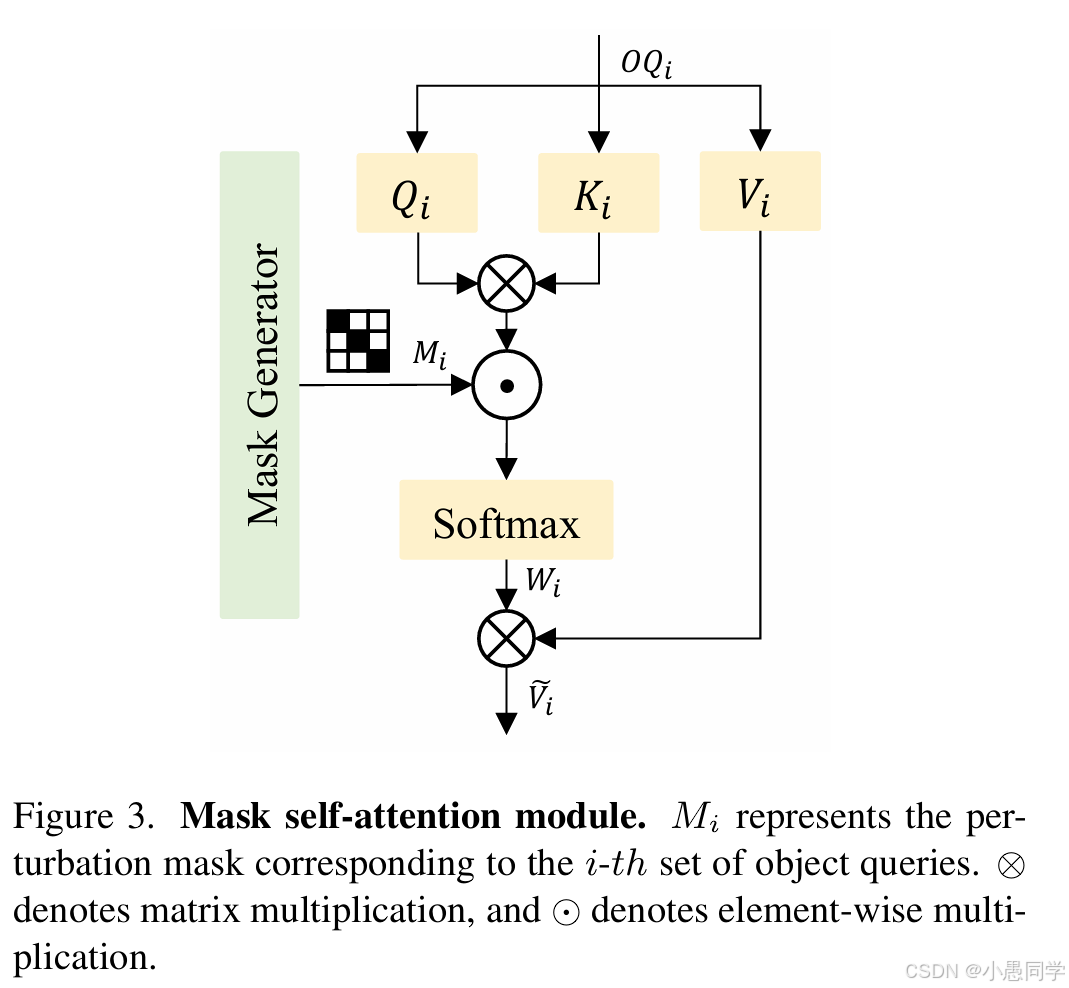
图3. 掩膜自注意力模块。Mi表示对应第i组物体查询的扰动掩膜。⊗表示矩阵乘法,⊙表示逐元素乘法。
基于变换器的多组自注意力扰动分支
解码器由一系列变换器块组成,每个块包含自注意力、交叉注意力和FFN(前馈网络)模块。最初,查询通过自注意力模块相互作用,以增强或削弱它们的特征表示。随后,每个查询通过交叉注意力模块从编码器的输出特征中提取信息来更新自身。最后,FFN预测与每个查询对应的目标的类别和边界框坐标。然而,在RT-DETR中采用的一对一集合匹配方式导致了稀疏的监督信息,最终损害了模型的性能。
为了确保与同一目标相关的多个查询有机会参与正样本学习,我们提出了基于掩膜自注意力的多组自注意力扰动模块。该扰动模块的实现细节如图2所示。首先,我们通过查询选择模块生成多个物体查询集,表示为OQi(i=1…N,其中N是查询集的数量)。然后,我们使用掩膜生成器为每一组OQi生成一个随机扰动掩膜Mi。OQi和Mi一起输入到掩膜自注意力模块,生成扰动和融合后的特征。
掩膜自注意力模块的详细实现如图3所示。首先,OQi通过线性投影得到Qi、Ki和Vi。然后,Qi和Ki相乘计算注意力权重,接着与Mi相乘,并通过softmax函数得到扰动后的注意力权重。最后,将扰动后的注意力权重与Vi相乘,得到融合后的结果˜Vi。该过程可以表示为:
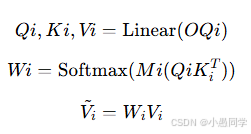
多个随机扰动集的引入使得查询特征多样化,从而允许多个与同一目标相关的查询有机会被分配为正样本查询,进而丰富了监督信息。在训练过程中,多个查询集被连接在一起并输入到单个解码器分支,从而实现参数共享并提高训练效率。损失计算和标签分配方案与RT-DETR保持一致。我们将第i组的损失表示为Lossi_o2o,N组扰动集的总损失计算如下:
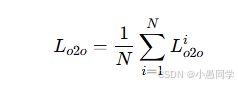
对应的损失权重记为 β。
基于变换器的一对多密集监督分支
为了最大化多组自注意力扰动分支的收益,我们在解码器中引入了一个具有共享权重的额外密集监督分支。这确保了每个真实标签有更多高质量的查询匹配。具体而言,我们使用查询选择模块生成一组独特的物体查询。在样本匹配阶段,通过将训练标签复制 mm 倍(默认值为4)来生成一个扩展的目标集合。这个扩展集合随后与查询的预测结果进行匹配。损失计算与原始检测损失保持一致,我们将该分支的损失函数记为 Lo2m,其对应的损失权重为 γ。
总损失
综上所述,我们提出的方法的整体损失函数如下:

实验
数据集与评估指标
我们选择了MS COCO 2017目标检测数据集作为我们方法的评估基准。该数据集包含115k张训练图片和5k张测试图片。我们采用了与RT-DETR相同的评估指标,即平均精度(AP)。
我们将RT-DETRv3的性能与其他实时目标检测器进行了比较,这些检测器包括基于变换器和基于CNN的实时目标检测器,主要从收敛效率、推理速度和效果方面进行对比。此外,我们对本文提到的模块进行了消融研究。所有的实验细节和结果将在接下来的章节中详细说明。
实现细节
我们将提出的层次化密集监督分支集成到RT-DETR框架中。基于CNN的密集监督辅助分支直接采用了PP-YOLOE头,其样本匹配策略、损失计算和所有其他配置均与PP-YOLOE一致。我们复用了RT-DETR解码器结构作为主分支,并额外添加了三个共享参数的自注意力扰动分支。这些分支的样本匹配方法与主分支一致,均使用匈牙利匹配算法。
此外,我们还添加了一个共享参数的一对多匹配分支,其中每个真实标签默认与四个物体查询匹配,总共设置了300个物体查询。我们使用了AdamW优化器,结合权重衰减因子0.0001,确保所有其他训练配置严格遵循RT-DETR,包括数据增强和预训练。
对于较小的主干网络(R18,R34),我们采用了10倍(120个epoch)的训练计划;对于较大的主干网络(R50,R101),我们采用了6倍(72个epoch)的训练计划。我们的训练在四张NVIDIA A100 GPU上进行,批量大小为64。此外,所有模型的推理延迟均使用TensorRT FP16在T4 GPU上进行测试,与RT-DETR保持一致。
我们观察到,与大多数需要更长训练周期的检测器相比,RT-DETRv3仅需72个epoch即可达到更高的准确性。
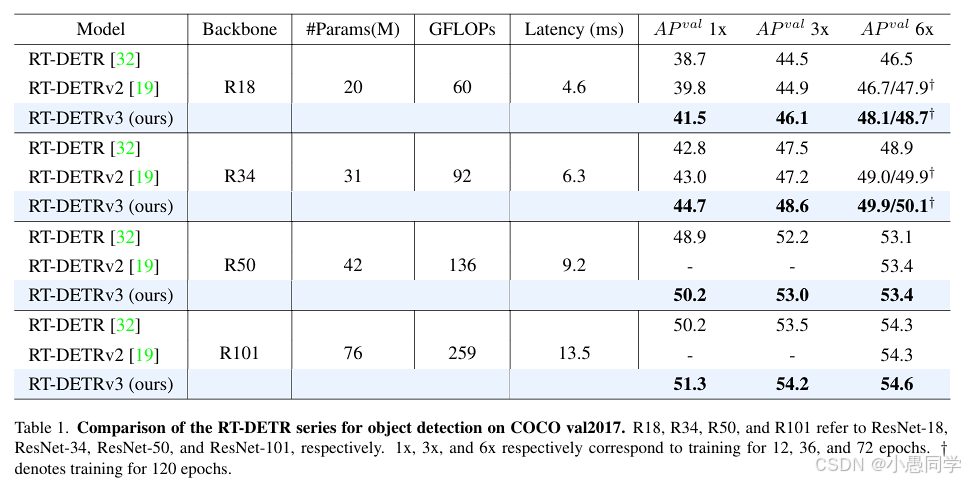
表1. RT-DETR系列在COCO val2017上的目标检测性能比较。R18、R34、R50和R101分别表示ResNet-18、ResNet-34、ResNet-50和ResNet-101主干网络。1x、3x和6x分别对应12、36和72个epoch的训练。†表示训练120个epoch。
与基于变换器的实时目标检测器的比较
推理速度与算法性能
基于变换器架构的实时目标检测器主要以RT-DETR系列为代表。表1展示了我们的方法与RT-DETR系列的比较结果。我们的方法在各种主干网络上均优于RT-DETR和RT-DETRv2。具体而言,相较于RT-DETR(使用6倍训练计划),我们的方法在R18、R34、R50和R101主干网络上的性能分别提升了1.6%、1.0%、0.3%和0.3%。
与RT-DETRv2相比,我们在R18和R34主干网络上分别使用6倍和10倍训练计划进行评估,性能分别提升了1.4%/0.8%和0.9%/0.2%。此外,由于我们提出的辅助密集监督分支仅在训练阶段使用,因此我们的推理速度与RT-DETR和RT-DETRv2保持一致。
收敛速度
我们的方法基于RT-DETR框架,通过引入基于CNN和变换器的一对多密集监督,不仅提升了模型性能,还加快了收敛速度。我们进行了大量实验以验证方法的有效性。表1展示了RT-DETRv3、RT-DETR和RT-DETRv2在不同训练计划下的对比分析。结果清楚地表明,我们的方法在任何训练计划中都表现出更快的收敛速度,并且只需要一半的训练周期即可达到与它们相当的性能。
过拟合分析
如图4所示,我们注意到随着模型规模的增加,RT-DETRv3倾向于表现出过拟合。我们认为这可能是由于训练数据集规模与模型规模之间的不匹配。为此,我们进行了多项实验(见表3)。当我们增加额外的训练数据时,RT-DETRv3在训练周期增加时性能持续提升,并且在相同训练周期下表现优于未增加额外数据的模型。
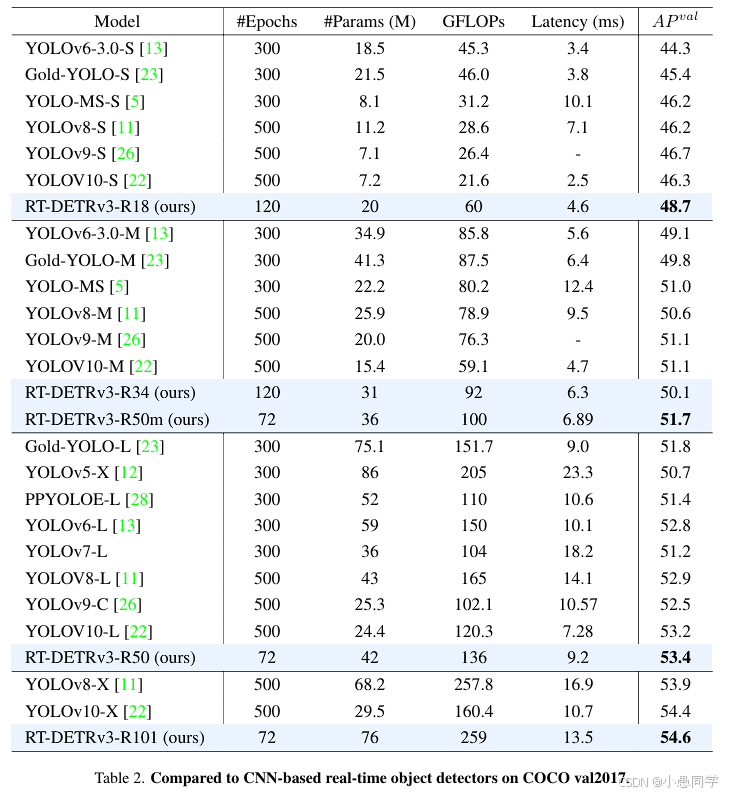
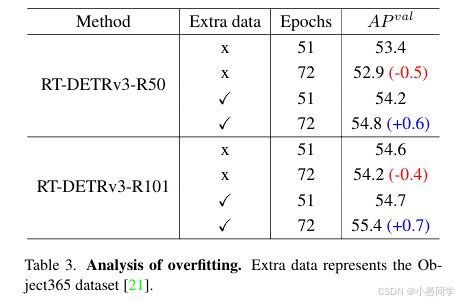
图4. RT-DETRv3在不同模型规模下的收敛曲线。⋆表示最佳AP值。
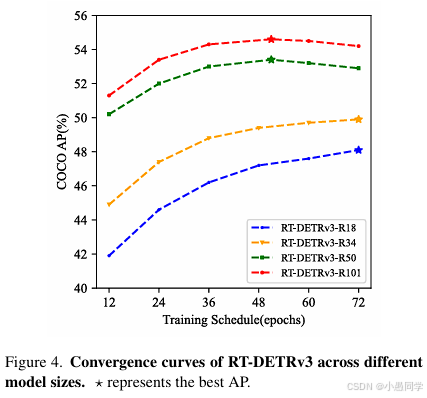
图4. RT-DETRv3在不同模型规模下的收敛曲线。⋆表示最佳AP值。
与基于CNN的实时目标检测器的比较
推理速度与算法性能
我们将RT-DETRv3与当前先进的基于CNN的实时目标检测方法进行了端到端速度和准确性的比较。根据推理速度,我们将模型分为小型、中型和大型模型。在相似的推理性能条件下,我们将RT-DETRv3与诸如YOLOv6-3.0、Gold-YOLO、YOLO-MS、YOLOv8、YOLOv9和YOLOv10等最新的算法进行了对比。
如表2所示,对于小型模型,RT-DETRv3-R18相比YOLOv6-3.0-S、Gold-YOLO-S、YOLO-MS-S、YOLOv8-S、YOLOv9-S和YOLOv10-S,分别提升了4.4%、3.3%、2.5%、2.5%、2.0%和2.4%。
对于中型模型,RT-DETRv3同样展现了比YOLOv6-3.0-M、Gold-YOLO-M、YOLO-MS-M、YOLOv8-M、YOLOv9-M和YOLOv10-M更优越的性能。
对于大型模型,我们的方法在各方面都持续超越了基于CNN的实时目标检测器。例如,我们的RT-DETRv3-R101可以达到54.6 AP,比YOLOv10-X表现更佳。然而,由于我们尚未对RT-DETRv3检测器的整体框架进行轻量化部署优化,因此RT-DETRv3的推理效率仍有进一步提升的空间。
收敛速度
如表2所示,我们发现RT-DETRv3在达到更高性能的同时,可以将训练周期减少至基于CNN的实时检测器的60%甚至更低。这进一步证明了我们方法的高效性。
消融研究
实验设置
我们以RT-DETR作为基线,并通过依次集成辅助的基于CNN的一对多标签分配分支、辅助的基于变换器的一对多标签分配分支,以及多组自注意力扰动模块,验证我们提出的方法的影响。这些实验均以ResNet18作为主干网络,批量大小为64,使用四张NVIDIA A100 GPU进行训练,同时其他配置与RT-DETR保持一致。
组件消融实验
我们对本文提出的模块进行了消融实验,以评估它们对模型性能的贡献。如表4所示,每个模块都显著提升了模型的性能。例如,在RT-DETR中加入O2M-T模块时,相较于基础模型,性能提升了1.0%。当将所有提出的模块集成到RT-DETR中进行算法优化时,模型性能总体提升了1.6%。
自注意力扰动分支数量
为了验证自注意力扰动分支数量对RT-DETRv3性能的影响,我们在RT-DETRv3-R18上进行了消融实验,设置了分支数量为2、3和4,其他配置保持不变。如表5所示,当分支数量设置为3时,模型达到了最佳性能,AP为48.1。减少分支数量会降低监督信号的丰富性,从而导致性能下降。相反,过多增加分支数量会提高模型的学习难度,但未带来显著的性能提升。
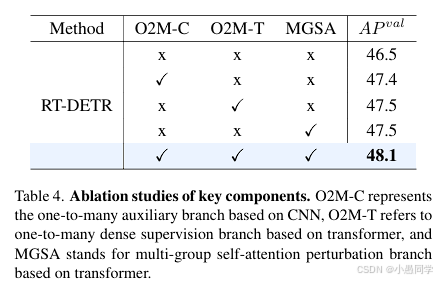
表4. 关键组件的消融研究。O2M-C表示基于CNN的一对多辅助分支,O2M-T表示基于变换器的一对多密集监督分支,MGSA表示基于变换器的多组自注意力扰动分支。
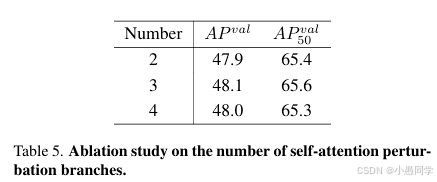
表5. 关于自注意力扰动分支数量的消融研究。
结论
本文提出了一种基于变换器的实时目标检测算法,命名为RT-DETRv3。该算法在RT-DETR的基础上,结合了多种密集正样本辅助监督模块。这些模块对RT-DETR的编码器和解码器中特定的特征施加了一对多目标监督,从而加速了算法的收敛并提升了其性能。需要注意的是,这些模块仅在训练阶段使用。
我们在COCO目标检测基准上验证了该算法的有效性,实验结果表明,与其他实时目标检测器相比,我们的算法取得了更好的性能。我们希望本工作能够为从事基于变换器的实时目标检测研究和开发的研究人员与开发者提供灵感。

















 1104
1104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









