






shujjyolo每年一更,听起来耳熟能详,不够高大上,但在目标检测领域是绝对的王者地位啊,对于做计算机视觉的研究生来说,使用yolo对自己的课题进行研究也是非常普遍,对于本科生来说,在参加比赛项目,课程课设上,使用yolo做一些目标检测的小任务,那可是远超身边的同学们了。现在我就逐步进行yolo训练的教程。
一、配置环境
yolo的适应性极强,可以在很多版本的环境中运行。如果从头开始的话,首先下载pycharm(如果不经常使用,社区版和专业版都行,专业版需要激活一下。不需要下太新版本)和anaconda,并安装,anaconda需要配置环境变量,不过也非常简单,找一个教程跟着来就行了。
在开始菜单中找到anaconda prompt,点击进去,你可以看到conda的base环境,现在好像都是python3.11了,此时创建conda虚拟环境(虚拟环境就是一个可以独立管理的工作室,里面可以随便装修,以后跑模型的时候可以去不同的活可以去不同的工作室),此处我简单介绍,详细可以去搜索别的帖子。
conda create --name myenvname python=3.8 # 在myenvname定义自己环境的名字python版本最好不好低于3.8,但也最好不要超过3.10,否则可能出现一些包不兼容的问题。
conda activate myenvname # 激活你的环境激活你的环境,此时你的命令行前面应该是你定义的名字了。如何打开PyTorch官网,在下面找到安装命令
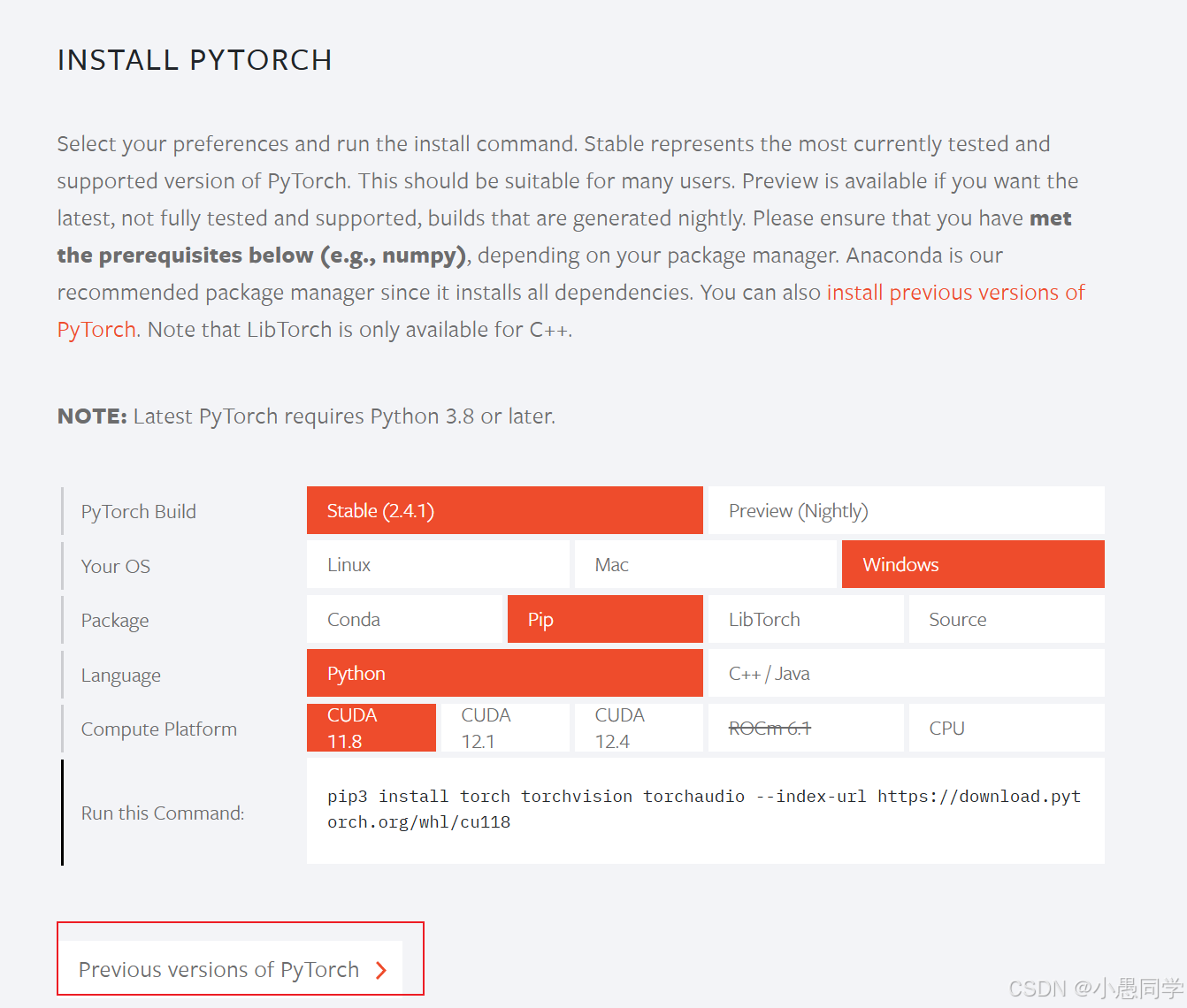
然后点进去,找到对应的版本,装2.0之后的也行,基本上安装包都是向下兼容的 ,
再次之前,需要查看你电脑显卡的cuda版本,原则上安装的pytorch版本不能超过电脑自己的cuda版本,具体自己查一下吧。这里说一个简单的,win+r,输入cmd然后回车,输入nvcc --version,就可以,如果这个方法不行,有可能你的电脑还没安装过cuda,那就去英伟达官网下载安装。如果你没有独立显卡,只有核显或cpu,那就不用查了。
回到pytorch的安装页面,对应好cuda版本,找到一个合适的版本,复制命令。好像在conda的prompt中,使用pip或者conda安装都可以,复制安装命令到conda prompt中,回车等待就行了。
如果下载过慢,请自主搜索如何更新/更换镜像源。
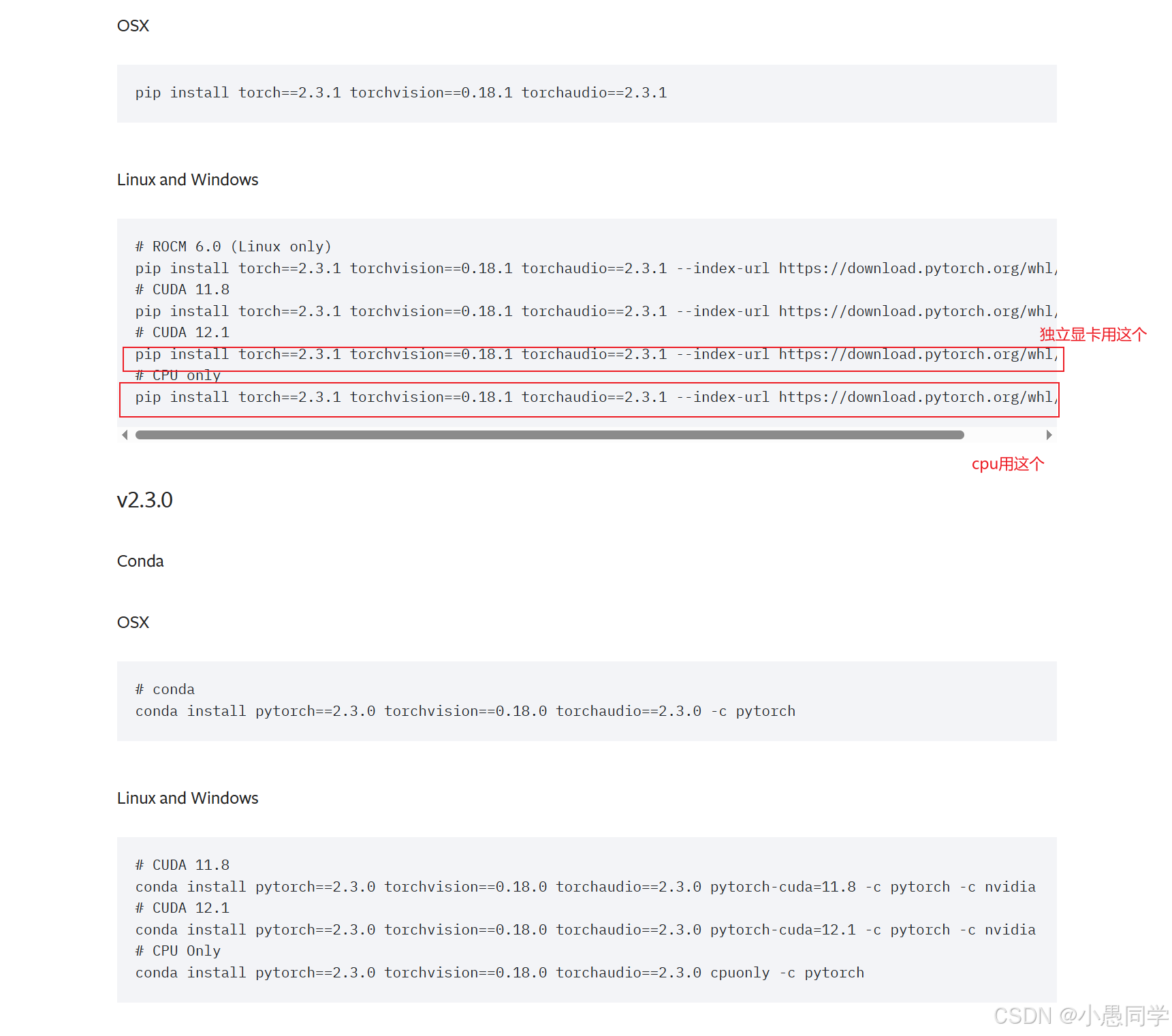
环境配置完毕。
二、在pycharm中配置conda解释器
打开pycharm,现在应该是没有编译器的,点击files-setting-project-python interpreter,点右上角的add interpreter add local interpreter ,选择conda environment 在第二行的conda executable中选择环境安装的位置,如果不知道,打开C盘的user 打开可以查看隐藏的文件,有一个.conda 使用记事本打开,可以看到位置,一般在C盘或者anaconda的安装目录下,的env下,我的是D:\Environment\Anaconda\envs\pytorch12\python.exe,你们自己找找看。一定要选择到自己之前创建的环境,找到这个环境下的python.exe,就可以了。然后保存就行了。然后在编译器的右下角就能选择这个环境了。
如果这一步我这个介绍太简陋,你们自主搜索详细教程。
三、下载代码和安装包
yolo的高度集成化,几乎将所有版本的代码都放在一块了,导致了我们使用的时候,很多很乱,很多其实用不着,但没办法,他们是方便了,苦了我们初学者。代码下载网址为Ultralytics · GitHub
里面可以下载yolov5,v8,v10,11,也就这些比较典型。
v5还有配置train.py让我们run,之后的版本就主要使用CLI命令行了。
找到你想要的,下载下来,解压,使用pycharm打开,点开最下面或左下角的terminal,点击窗体的左上角的加号旁边的下拉符号,选择commad prompt,此时进去可能是base环境,你需要conda activate yourenv,激活你的环境,然后运行pip install -r requirements.txt,再次之前先检测txt中的内容,如果有torch,torchvision torchaudio,把他们屏蔽掉,因为我们之前安装时已经安装好了,此时再安装,需要大量时间。此时安装过程中,可能会有一些报错,需要对包的版本进行一些调整。
然后 安装
pip install ultralytics这是v8之后的版本启动的关键,v5可以选择性安装。这个包几乎涵盖了所有需要的包,安装之后就不需要手动去安装其他包了
到此为止,环境配置完毕,请不要放弃,即将胜利。
四、训练
yolo的官方文档的网址为火车 -Ultralytics YOLO 文档
此时你可以跑一些官方的数据集和测试,来验证模型是否可以运行,yolov5在train.py中配置好model的model.yaml和dataset的data.yaml,就可以运行了。v5之后的版本,查看文档,使用命令行在conda环境的命令行中输入后回车,就可以看看跑起来什么样子。你也可以提取根据你的任务提取下载好预训练的权重文件,最小为n(nano),s(small),m(middle),l(large),s足以应付大多数任务,而且大小合适、运行速度较快。
yolov5之后的版本,功能是否广泛,从目标检测,实例分割,图像分类,关键点识别,obb,覆盖了大多数检测任务,但是这是功能都是目标检测的附带功能,主要功能还是目标检测。
yolo detect train data=coco8.yaml model=yolo11n.yaml pretrained=yolo11n.pt epochs=100 imgsz=640数据集标注
如果你先用自己的数据集做一些训练,那你必不可少的需要标注自己的数据集。
一般使用labelme或者labelimg,yolo擅长识别和处理竖直的矩形框,也可进行语义分割或者OBB识别,语义分割可以使用labelimg进行,OBB只能用其他软件了。
在conda环境中安装labelme或者labelimg,pip install labelme/labelimg即可,后在命令行窗口输入labelme/labelimg 即可打开,在里面选择文件夹,选择保存位置,然后选择矩形框即可,一张一张的标注即可,标注文件时txt格式,每行格式为[类别 中心点x 中心点y 高 宽]
标注完整成后,需要划分数据集为训练集和测试集,下面的代码是划分数据集,默认划分为7:2:1.可以在代码中调整
# 数据集打乱与划分
import os
import shutil
import random
random.seed(0)
def split_data(file_path,xml_path, new_file_path, train_rate, val_rate, test_rate):
each_class_image = []
each_class_label = []
for image in os.listdir(file_path):
each_class_image.append(image)
for label in os.listdir(xml_path):
each_class_label.append(label)
data=list(zip(each_class_image,each_class_label))
total = len(each_class_image)
random.shuffle(data)
each_class_image,each_class_label=zip(*data)
train_images = each_class_image[0:int(train_rate * total)]
val_images = each_class_image[int(train_rate * total):int((train_rate + val_rate) * total)]
test_images = each_class_image[int((train_rate + val_rate) * total):]
train_labels = each_class_label[0:int(train_rate * total)]
val_labels = each_class_label[int(train_rate * total):int((train_rate + val_rate) * total)]
test_labels = each_class_label[int((train_rate + val_rate) * total):]
for image in train_images:
print(image)
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'train' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in train_labels:
print(label)
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'train' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
for image in val_images:
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'val' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in val_labels:
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'val' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
for image in test_images:
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'test' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in test_labels:
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'test' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
if __name__ == '__main__':
file_path = "E:/Desktop/S/N/IMAGES"
xml_path = 'E:/Desktop/S/N/labels'
new_file_path = "E:/Desktop/S/data"
split_data(file_path,xml_path, new_file_path, train_rate=0.7, val_rate=0.1, test_rate=0.2)dataset/
├── train/
│ ├── images/
│ └── labels/
└── val/
├── images/
└── labels/

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









