






导言
著名的人工智能公司 DeepSeek 最近开源了 FlashMLA,这是一款针对 Hopper GPU 上的多头潜意识(MLA)进行了优化的高性能解码内核。这一进展对于大型语言模型(LLM)来说意义重大,因为大型语言模型在推理过程中面临内存和计算方面的挑战,尤其是长序列。本报告深入探讨了 FlashMLA 的技术细节、性能指标、应用和未来影响,为研究人员、开发人员和人工智能爱好者提供了全面的了解。
背景介绍多头潜在注意力(MLA)
要了解 FlashMLA,我们首先要探索 DeepSeek 的 DeepSeek-V2 模型(DeepSeek-V2:一个强大、经济、高效的专家混合语言模型)中引入的 MLA。MLA 是多头注意力(MHA)的一种变体,是 LLM 中使用的转换器架构的基石。
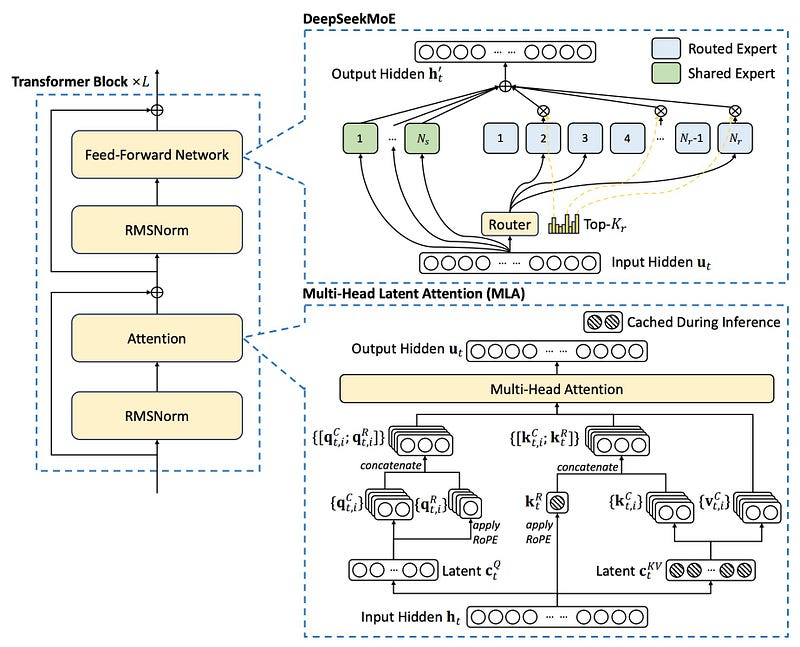
DeepSeek-V3 基本架构示意图。继 DeepSeek-V2 之后,采用 MLA 和 DeepSeekMoE 实现高效推理和经济训练。
标准多头关注及其挑战
在 MHA 中,每个注意力头都独立处理查询、键和值,从而使模型能够捕捉不同的依赖关系。然而,在推理过程中,KV 缓存–存储前一个标记的键和值–随序列长度线性增长,成为长序列的内存瓶颈。对于具有 n_h 个头部和头部维度 d_h 的模型,KV 缓存的大小为 seq_len * 2 * n_h * d_h,对于较大的 seq_len,这可能会超过 GPU 的内存限制。
MLA协助如何解决这一问题
MLA 将 KV 对压缩为每个标记 t 的潜在向量 c_t,从而减少了内存占用:
- 隐藏状态 h_t 通过矩阵 W^{KV} 投射到潜在向量 c_t,其中 c_t 的维度为 d_c,远小于 n_h * d_h。
- 然后,密钥 k_t 和值 v_t 分别为 k_t = W^{UK} c_t 和 v_t = W^{UV} c_t,其中 W^{UK} 和 W^{UV} 映射 d_c 到 n_h * d_h。
在推理过程中,MLA 不再缓存 k_t 和 v_t,而是缓存 c_t,从而将 KV 缓存大小减少到 seq_len * d_c。从 DeepSeek-V2 中可以看出,这种压缩方式可以减少高达 93.3% 的内存使用量,使上下文长度更长,处理效率更高。
MLA的好处
- 内存效率:允许处理较长的序列而不受内存限制。
- 性能维护:根据 DeepSeek 的结果,保持或提高模型性能。
- 降低成本:降低训练和推理成本,使大型模型更易于使用。
FlashMLA:针对 Hopper GPU 的优化实现
FlashMLA是DeepSeek为MLA量身定制的GPU内核,专门针对Hopper GPU(如H800 SXM5)进行了优化。它侧重于 LLM 的解码阶段(新令牌按顺序生成),其灵感来自 Flash Attention 2 & 3(Flash Attention 2&3 GitHub)和 Nvidia 的 cutlass 库(cutlass GitHub)。
技术细节
- 硬件要求:需要 Hopper GPU(如 H800 SXM5)、CUDA 12.3+ 和 PyTorch 2.0+。
- 精度和功能:目前支持 BF16,采用分页式 KV 缓存和 64 块大小的块,以实现高效的内存管理。
- 性能指标:根据其 GitHub 存储库(FlashMLA GitHub),FlashMLA 实现了。
- 内存带宽高达 3000 GB/秒,接近 H800 SXM5 的峰值内存带宽 3350 GB/秒。
- 计算极限:高达 580 TFLOPS,考虑到 H800 的理论峰值为 260 TFLOPS(用于 BF16 矩阵乘法),这一点值得注意。
了解数字性能
580 TFLOPS 的计算性能尤其引人关注,因为它超过了 H800 预期的 260 TFLOPS 的 BF16 性能。这表明,虽然存储库指定了 BF16,但可能利用了 FP8 等低精度格式进行了高级优化。这种差异可能表明有效使用了张量核或定制内核设计,最大限度地提高了 MLA 特定操作的吞吐量。
3000 GB/s 的内存带宽也令人印象深刻,接近硬件极限,这表明数据访问模式非常高效,很可能是受闪存注意事项的启发,采用了平铺和缓存等技术。
与其他注意力实施方法的比较
FlashMLA 从 Flash Attention 3 中汲取灵感,后者在 H100 GPU 上实现了 740 TFLOPS 的标准注意力。虽然 FlashMLA 在 H800 上的 580 TFLOPS 较低,但它是为 MLA 量身定制的,而 MLA 的计算模式与之不同。这一比较凸显了 FlashMLA 在特定使用情况下的效率,特别是考虑到 H800 与 H100 相似,但由于出口法规的潜在限制。
MLA 和 FlashMLA 的计算分析
为了理解 FlashMLA 的优化,让我们来分析一下 MLA 在推理过程中的计算方面:
- 标准 MHA 计算:对于一个新标记,计算所有头部的 q_t(n_h * d_model * d_h),然后计算注意力分数(n_h * d_h * seq_len)和加权总和(n_h * seq_len * d_h),每个标记的总运算量约为 n_h * d_model * d_h + 2 * n_h * d_h * seq_len。
- 工作重点计算:包括从 h_t 计算 c_t(d_model * d_c),从缓存 C 重构 K 和 V(2 * n_h * d_h * d_c * seq_len),以及相同的注意力计算(2 * n_h * d_h * seq_len)。总计算量为 d_model * d_c + 2 * n_h * d_h * d_c * seq_len + n_h * d_model * d_h + 2 * n_h * d_h * seq_len。
其中的权衡显而易见:MLA 增加了 K 和 V 重构的计算量,但却大大减少了内存使用量,因此适用于长序列。FlashMLA 优化了这些操作,利用 Hopper GPU 的张量核和高效内存访问实现了高 TFLOPS。
在 DeepSeek 模型中的应用
FlashMLA 是 DeepSeek 模型不可或缺的一部分,它提高了模型的效率:
- DeepSeek-V2:拥有 236B 参数(每个令牌激活 21B),支持 128K 上下文长度。MLA 可减少 93.3% 的 KV 缓存,节省 42.5% 的训练成本,并将生成吞吐量提高 5.76 倍(DeepSeek-V2 论文)
- DeepSeek-V3:可扩展至 671B 个参数,证明了 MLA 的可扩展性。该模型在两个月的时间内以 558 万美元的成本高效地完成了训练,凸显了经济效益(DeepSeek 的多头潜在注意力)
这些应用凸显了 FlashMLA 在实现大型、高效 LLM 方面的作用,符合人工智能开发的成本效益趋势。
未来方向与挑战
FlashMLA 虽然前景广阔,但也面临着挑战和机遇:
- 采用:主要提供商仍依赖于群体查询关注(GQA),而 MLA 的采用有限。TransMLA 等研究表明,MLA 可以代表 GQA,同时保持效率(TransMLA: Multi-Head Latent Attention Is All You Need),这表明 MLA 有可能得到更广泛的应用。
- 通用性:确保 MLA 在不同任务和硬件中的性能至关重要。关于 MLA 的实验(mla-experiments GitHub)表明,它能改进模型,而不是牺牲性能,但还需要更多验证。
- 优化:针对其他 GPU 架构进一步优化 FlashMLA 或探索混合精度(如 FP8)可提高性能,特别是考虑到 BF16 实现了 580 TFLOPS。
结论
FlashMLA 是 LLM 推理领域的一项重要进步,它为具有接近峰值内存和计算性能的 Hopper GPU 优化了 MLA。它在 DeepSeek-V2 和 V3 中的集成展示了实际优势,降低了成本,提高了吞吐量。随着人工智能规模的扩大,FlashMLA 和类似的创新技术将塑造高效、便捷的模型部署,而正在进行的研究可能会扩大其影响。


















 191
191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









