









Ref
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
MLA实现及其推理上的十倍提速——逐行解读DeepSeek V2中多头潜在注意力MLA的源码(图、公式、代码逐一对应)_mla加速 csdn-优快云博客
deepseek技术解读(1)-彻底理解MLA(Multi-Head Latent Attention)
DeepSeek-V3/inference/model.py at main · deepseek-ai/DeepSeek-V3 · GitHub
理解 FlashMLA 在 DeepSeek MLA 计算过程中的位置和作用
DeepSeek-V2 高性能推理 (1):通过矩阵吸收十倍提速 MLA 算子
计算公式
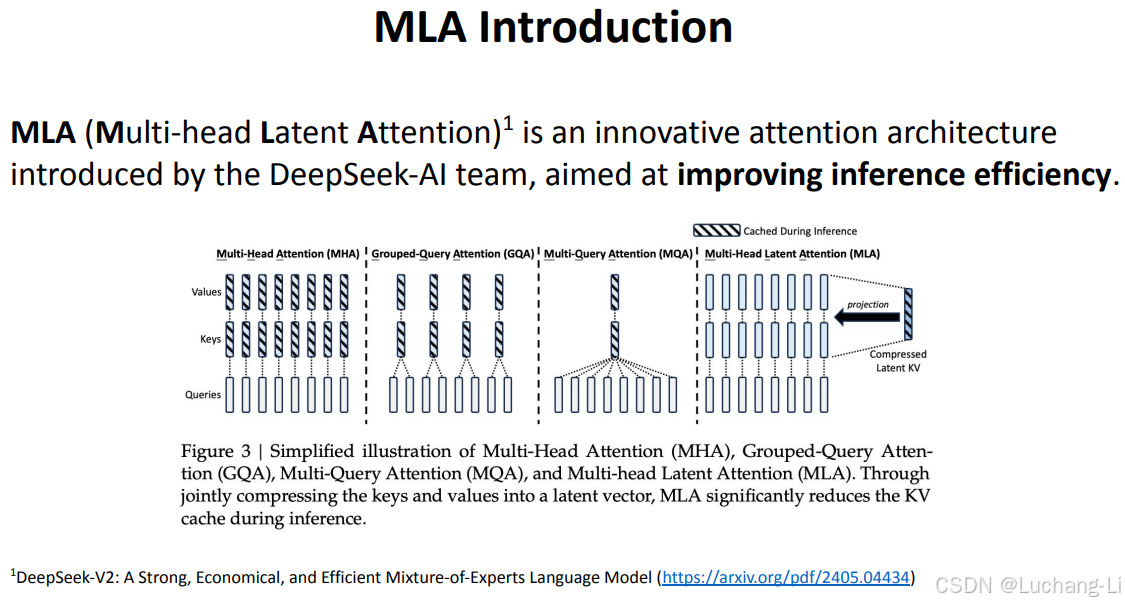
The core of MLA is the low-rank joint compression for attention keys and values to reduce Key-Value (KV) cache during inference:

For the attention queries, we also perform a low-rank compression, which can reduce the activation memory during training:

KV cache比较

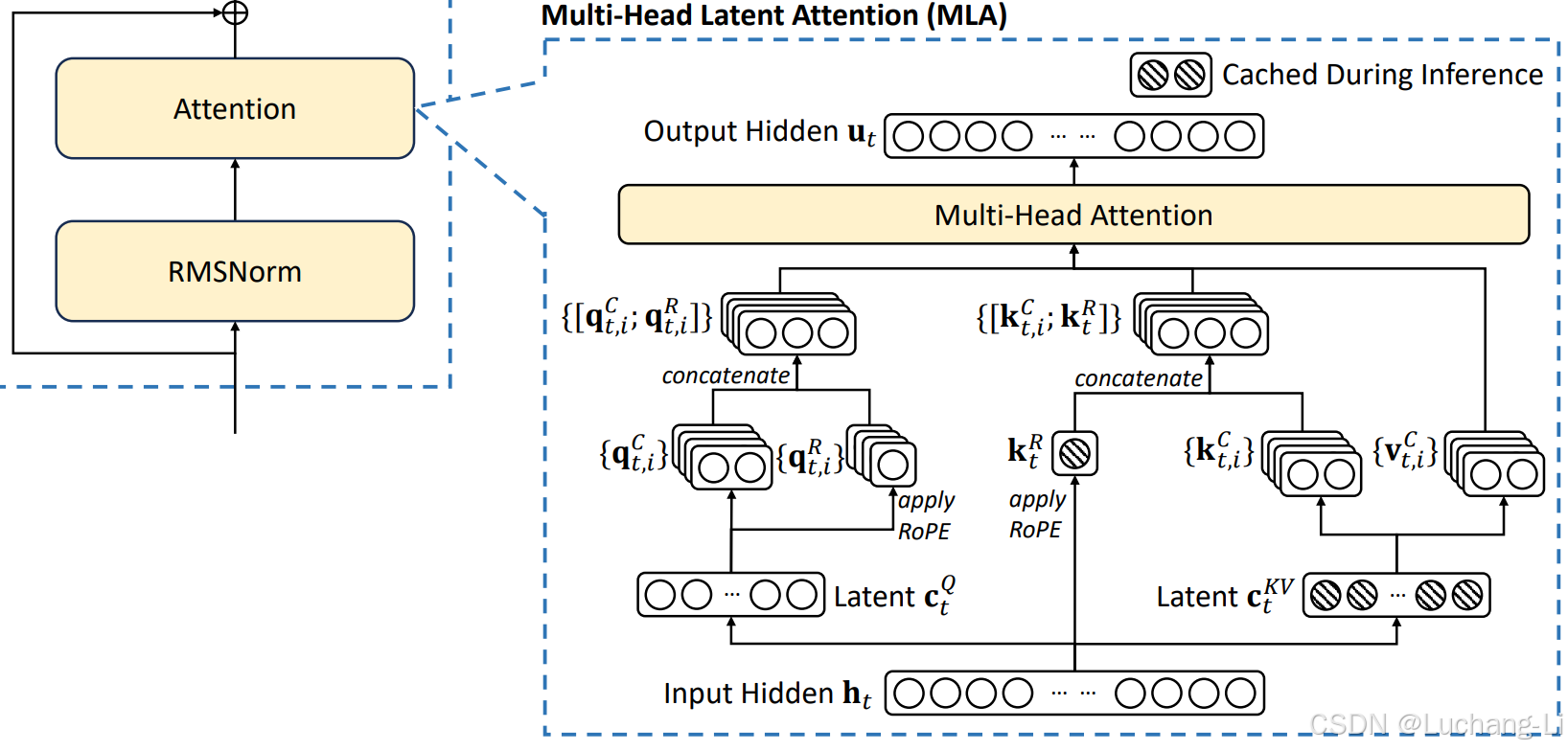
示意图
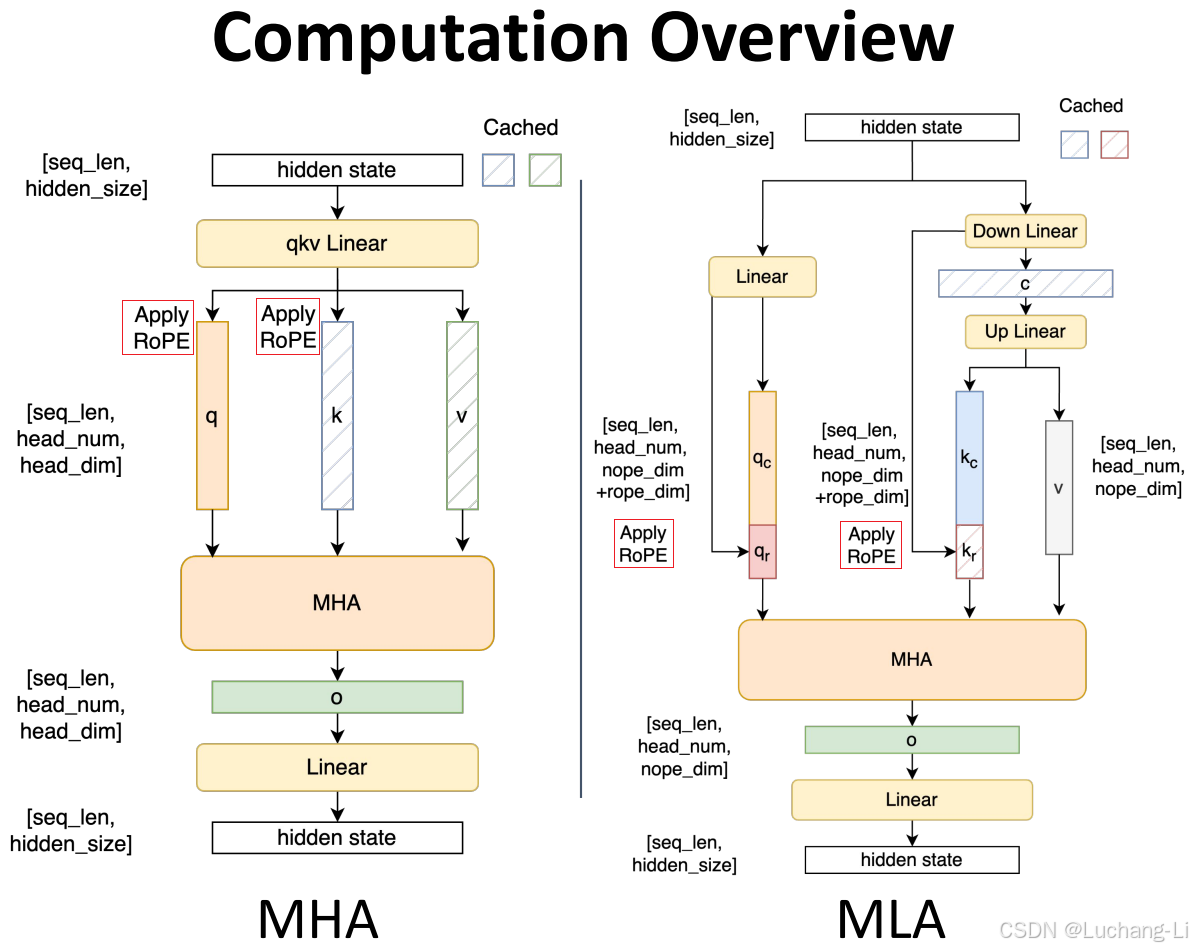
这个图看着很复杂,主要是Apply RoPE这部分导致的。MHA得到q,k, v向量后,对q, k两个部分全部做Apply RoPE,但是MLA是部分做RoPE,部分不做。为啥当前要这么做ApplyRoPE而不是对恢复后的q, k部分整个做RoPE?如果那样的话这个图会变得非常简单清晰。但也许这样效果更好吧,我不是做算法的也不懂。
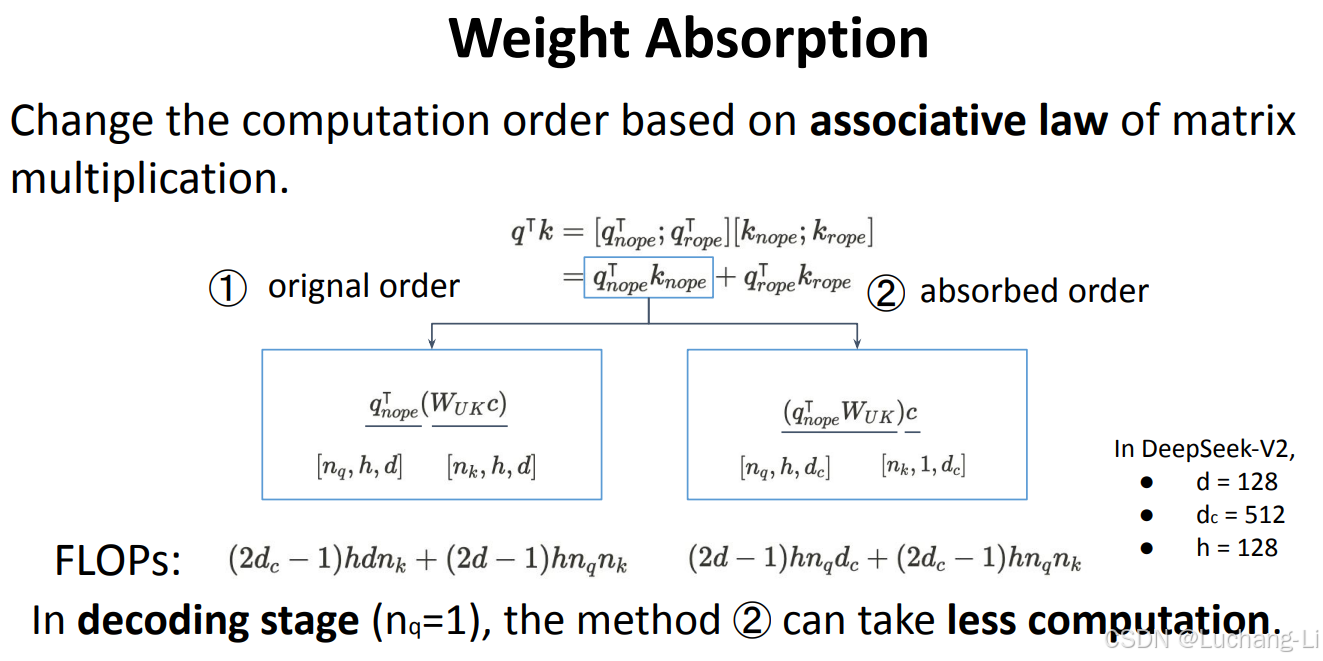
Weight absorption
Use normal computation for prefill and use weight absorption for extend/decode.

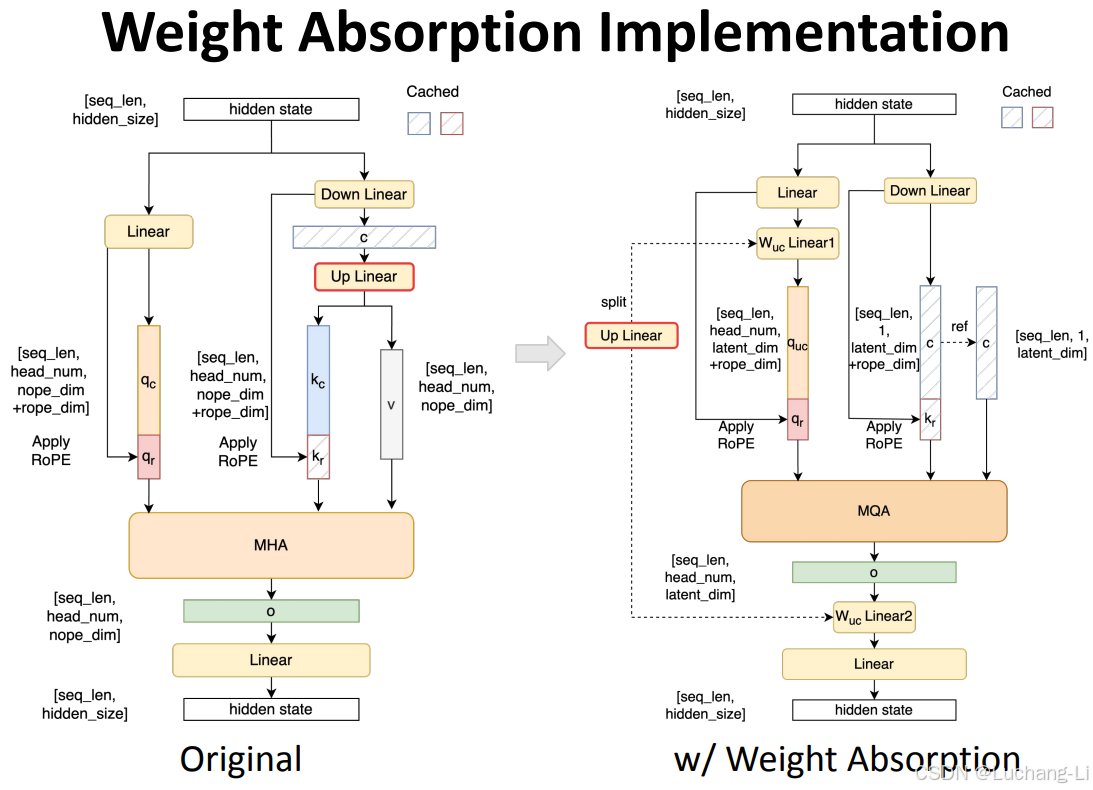
示意图v2
我感觉上面这些示意图(from DeepSeek V2/V3 Technical Report, sglang_deepseek_model_optimizations.pdf)并不是特别容易看懂,我自己重新绘制的一个示意图:
weight absorption:
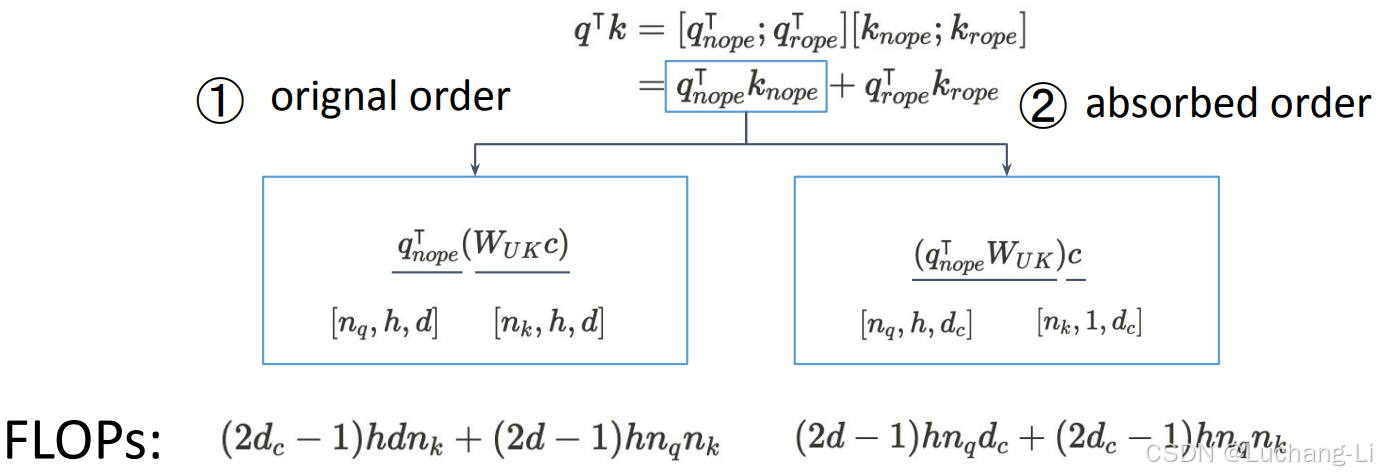
对于weight absorption场景,理论上是利用矩阵乘的结合律改变了矩阵乘的计算先后顺序。
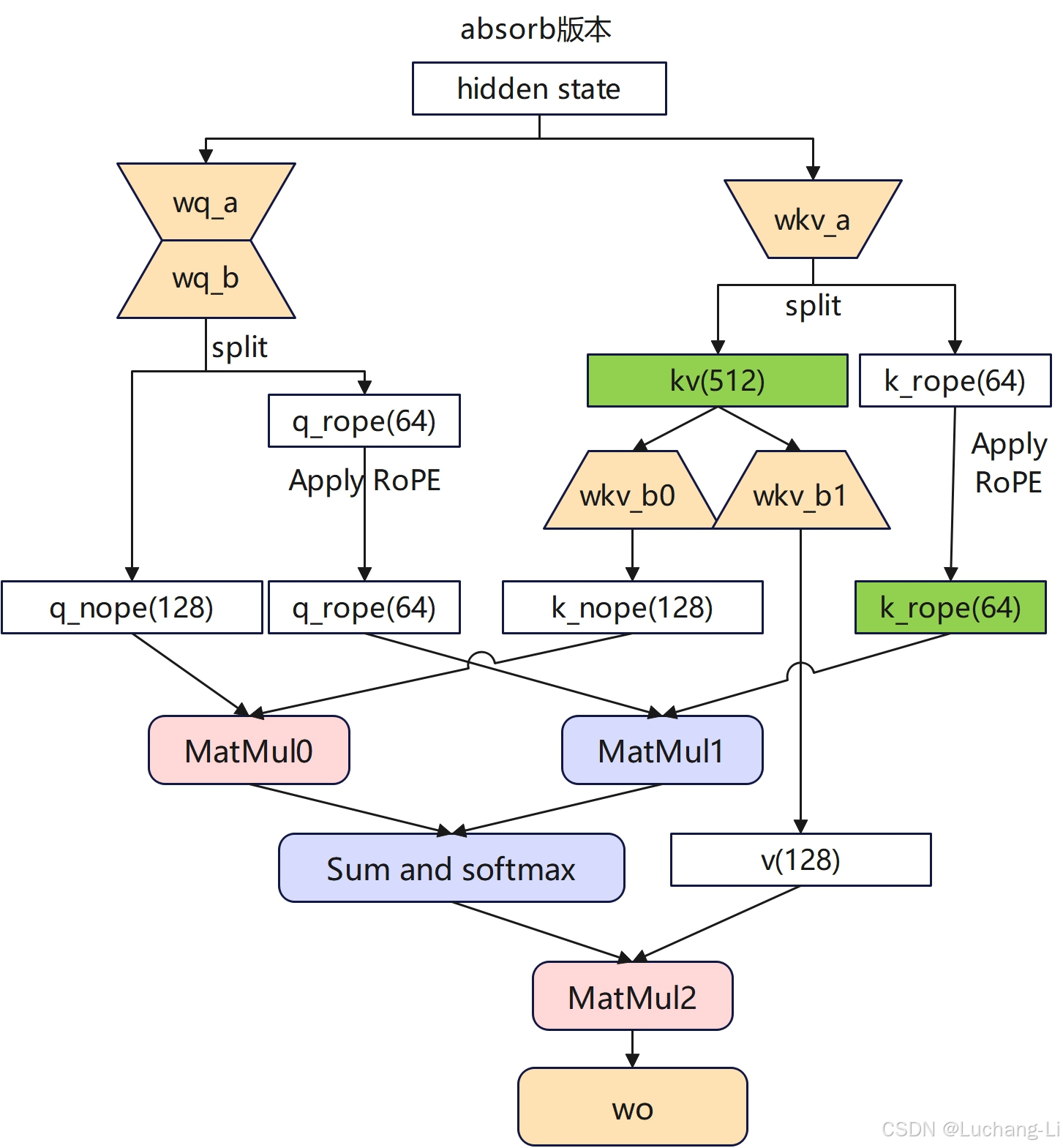
对MatMul0和wkv_b0的计算,以及MatMul2和wkv_b1的矩阵乘计算过程中,采用了结合律,而不是先计算hidden的kv cache与wkv_b0和wkv_b1的矩阵乘。
实际代码实现还是真实分离计算了,只是调整了计算顺序,没有真正实现对wkv_b对应的两个矩阵乘的权重吸收到wq_b0和wo里面。
代码实现(pytorch,非FlashMLA)
DeepSeek-V3/inference/model.py at main · deepseek-ai/DeepSeek-V3 · GitHub
MLA相关的权重:
class MLA(nn.Module):
"""
Multi-Headed Attention Layer (MLA).
Attributes:
dim (int): Dimensionality of the input features.
n_heads (int): Number of attention heads.
n_local_heads (int): Number of local attention heads for distributed systems.
q_lora_rank (int): Rank for low-rank query projection.
kv_lora_rank (int): Rank for low-rank key/value projection.
qk_nope_head_dim (int): Dimensionality of non-positional query/key projections.
qk_rope_head_dim (int): Dimensionality of rotary-positional query/key projections.
qk_head_dim (int): Total dimensionality of query/key projections.
v_head_dim (int): Dimensionality of value projections.
softmax_scale (float): Scaling factor for softmax in attention computation.
"""
def __init__(self, args: ModelArgs):
super().__init__()
self.dim = args.dim # dim = 7168
self.n_heads = args.n_heads # n_heads = 128
self.n_local_heads = args.n_heads // world_size # for tensor parallelism
self.q_lora_rank = args.q_lora_rank # q_lora_rank = 1536
self.kv_lora_rank = args.kv_lora_rank # kv_lora_rank = 512
self.qk_nope_head_dim = args.qk_nope_head_dim # qk_nope_head_dim = 128
self.qk_rope_head_dim = args.qk_rope_head_dim # qk_rope_head_dim = 64
self.qk_head_dim = args.qk_nope_head_dim + args.qk_rope_head_dim # 128 + 64 = 192
self.v_head_dim = args.v_head_dim # v_head_dim = 128
if self.q_lora_rank == 0: # q_lora_rank = 1536
self.wq = ColumnParallelLinear(self.dim, self.n_heads * self.qk_head_dim)
else:
self.wq_a = Linear(self.dim, self.q_lora_rank)
self.q_norm = RMSNorm(self.q_lora_rank)
self.wq_b = ColumnParallelLinear(self.q_lora_rank, self.n_heads * self.qk_head_dim)
self.wkv_a = Linear(self.dim, self.kv_lora_rank + self.qk_rope_head_dim)
self.kv_norm = RMSNorm(self.kv_lora_rank)
self.wkv_b = ColumnParallelLinear(self.kv_lora_rank, self.n_heads * (self.qk_nope_head_dim + self.v_head_dim))
self.wo = RowParallelLinear(self.n_heads * self.v_head_dim, self.dim)
self.softmax_scale = self.qk_head_dim ** -0.5
if args.max_seq_len > args.original_seq_len:
mscale = 0.1 * args.mscale * math.log(args.rope_factor) + 1.0
self.softmax_scale = self.softmax_scale * mscale * mscale
if attn_impl == "naive":
self.register_buffer("k_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.qk_head_dim), persistent=False)
self.register_buffer("v_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.v_head_dim), persistent=False)
else: # "absorb"
self.register_buffer("kv_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.kv_lora_rank), persistent=False)
self.register_buffer("pe_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.qk_rope_head_dim), persistent=False)
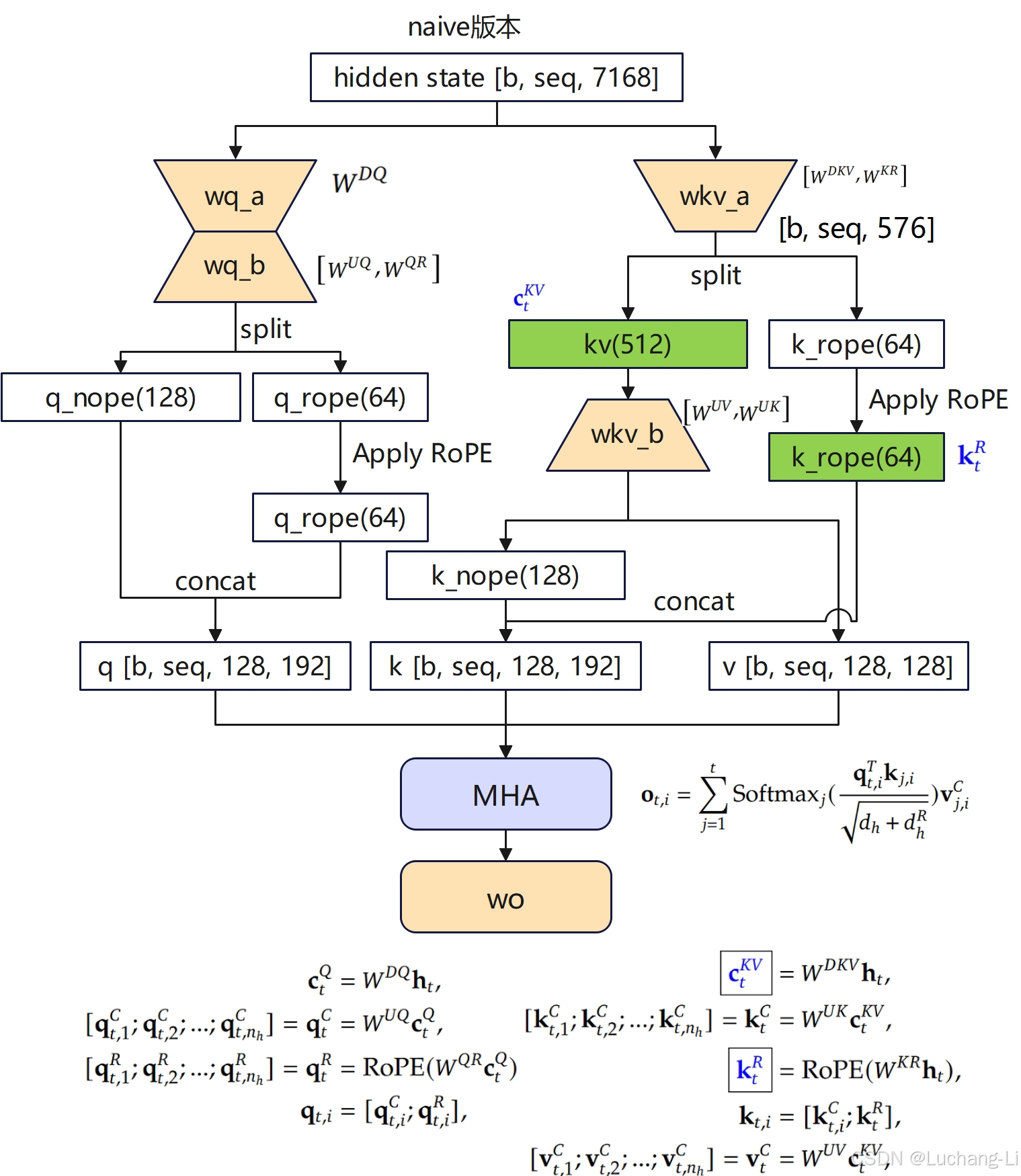
MLA计算
class MLA(nn.Module):
def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]):
"""
Forward pass for the Multi-Headed Attention Layer (MLA).
Args:
x (torch.Tensor): Input tensor of shape (batch_size, seq_len, dim).
start_pos (int): Starting position in the sequence for caching.
freqs_cis (torch.Tensor): Precomputed complex exponential values for rotary embeddings.
mask (Optional[torch.Tensor]): Mask tensor to exclude certain positions from attention.
Returns:
torch.Tensor: Output tensor with the same shape as the input.
"""
bsz, seqlen, _ = x.size()
end_pos = start_pos + seqlen
if self.q_lora_rank == 0: # q_lora_rank = 1536
q = self.wq(x)
else:
q = self.wq_b(self.q_norm(self.wq_a(x)))
q = q.view(bsz, seqlen, self.n_local_heads, self.qk_head_dim) # [batch, seqlen, 128, 192]
q_nope, q_rope = torch.split(q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1)
q_rope = apply_rotary_emb(q_rope, freqs_cis)
kv = self.wkv_a(x)
kv, k_rope = torch.split(kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1)
k_rope = apply_rotary_emb(k_rope.unsqueeze(2), freqs_cis)
if attn_impl == "naive":
q = torch.cat([q_nope, q_rope], dim=-1)
kv = self.wkv_b(self.kv_norm(kv))
kv = kv.view(bsz, seqlen, self.n_local_heads, self.qk_nope_head_dim + self.v_head_dim)
k_nope, v = torch.split(kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1)
k = torch.cat([k_nope, k_rope.expand(-1, -1, self.n_local_heads, -1)], dim=-1)
self.k_cache[:bsz, start_pos:end_pos] = k
self.v_cache[:bsz, start_pos:end_pos] = v
scores = torch.einsum("bshd,bthd->bsht", q, self.k_cache[:bsz, :end_pos]) * self.softmax_scale
else: # "absorb"
wkv_b = self.wkv_b.weight if self.wkv_b.scale is None else weight_dequant(self.wkv_b.weight, self.wkv_b.scale, block_size)
wkv_b = wkv_b.view(self.n_local_heads, -1, self.kv_lora_rank)
q_nope = torch.einsum("bshd,hdc->bshc", q_nope, wkv_b[:, :self.qk_nope_head_dim])
self.kv_cache[:bsz, start_pos:end_pos] = self.kv_norm(kv)
self.pe_cache[:bsz, start_pos:end_pos] = k_rope.squeeze(2)
scores = (torch.einsum("bshc,btc->bsht", q_nope, self.kv_cache[:bsz, :end_pos]) +
torch.einsum("bshr,btr->bsht", q_rope, self.pe_cache[:bsz, :end_pos])) * self.softmax_scale
if mask is not None:
scores += mask.unsqueeze(1)
scores = scores.softmax(dim=-1, dtype=torch.float32).type_as(x)
if attn_impl == "naive":
x = torch.einsum("bsht,bthd->bshd", scores, self.v_cache[:bsz, :end_pos])
else: # "absorb"
x = torch.einsum("bsht,btc->bshc", scores, self.kv_cache[:bsz, :end_pos])
x = torch.einsum("bshc,hdc->bshd", x, wkv_b[:, -self.v_head_dim:])
x = self.wo(x.flatten(2))
return x
FlashMLA
原理示意图大概如图所示,有问题麻烦指出。
具体公式推导参考上面的引用部分。
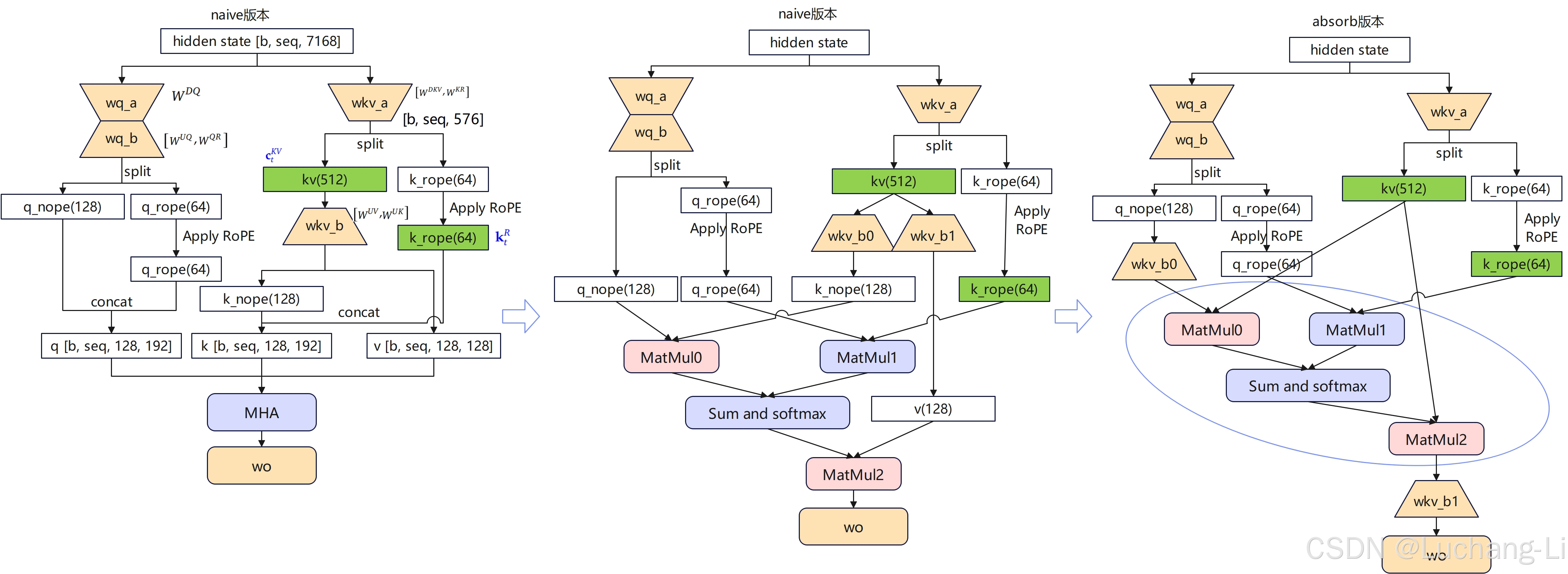
sglang的flashmla是最右边圈选的部分,采用了MLA的计算。
Data Parallelism Attention
to do


















 649
649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











