







前言
本文记录了STARK代码学习阶段的步骤,核心内容从原作者的github中搬运,对于部分内容(如不同数据集的测试语句)仅以一个为例进行展示,详细请查看原github页面。
code链接:https://github.com/researchmm/Stark
paper链接:https://arxiv.org/abs/2103.17154
STARK的Highlights:
- End-to-End: 直接预测一个精准的边界框作为跟踪结果。
- Post-processing Free: 不需要任何超参数敏感性的处理,性能稳定。
- Real-Time Speed: STARK-ST50, STARK-ST101在Tesla V100上的运行时间分别为40和30FPS;STARK-Lightning在RTX TITAN上的运行时间为200-300FPS
开始前的准备工作,从https://github.com/researchmm/Stark中下载代码部分
一、环境安装
该项目基于pytorch17的框架,如果已经有pytorch17的环境可以直接在自己电脑中的环境中运行,不用再重建虚拟环境。
进入自己的pytorch17的虚拟环境中,安装STRAK中的所需的其他库(记得进入install_pytorch17.sh把前4行中安装pytorch的语句删除)。
conda activate pytorch17 # 我的虚拟环境的名称就叫做pytorch17
bash install_pytorch17.sh # 安装其他库
二、设置项目路径
cd到STARK文件夹,执行以下语句,会在 lib/train/admin/local.py 和 lib/test/evaluation/local.py 中分别生成训练数据和测试数据的路径,之后如果要修改数据路径也是在对应local.py文件中修改。
python tracking/create_default_local_file.py --workspace_dir . --data_dir ./data --save_dir .
三、训练STARK
用单个GPU训练
python tracking/train.py --script stark_s --config baseline --save_dir . --mode single
四、测试STARK
1. 下载预训练模型
直接进行测试的话,需要下载一个预训练好的模型
- 官方链接:https://github.com/researchmm/Stark/blob/main/MODEL_ZOO.md
- 我自己只下了STARK-ST50的baseline,存放在阿里云盘里了,下载挺快的:https://www.aliyundrive.com/s/erHasVGm46h
下载完成后在项目根目录下创建checkpoints/train/strak_st2/baseline文件夹,并将文件放在里面。
2. 准备测试数据集
以LaSOT数据集为例,在项目的根目录下创建data文件夹,然后放入自己下好的LaSOT数据集。
- LaSOT链接:http://vision.cs.stonybrook.edu/~lasot/download.html
- 全部的LaSOT序列太大了,我这里只下载了truck的序列视频(约5G),阿里云盘链接:
以LaSOT数据集为例,终端环境下测试语句如下:
# 在终端下测试
python tracking/test.py stark_st baseline --dataset lasot --threads 32
python tracking/analysis_results.py # need to modify tracker configs and names
直接运行会出BUG,还需要修改以下几个地方。
-
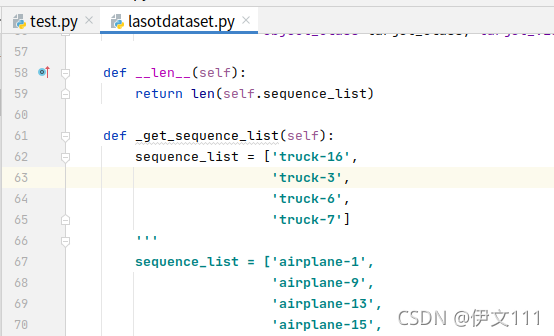
将lasotdataset.py中的def _get_sequence_list()方法里的sequence_list改为[‘truck-1’,…,] (这是因为我们只下载了truck序列的数据集)
-
在终端重新运行
python tracking/test.py stark_st baseline --dataset lasot --threads 32
会提示Downloading: restnet50之类的语句,这是在下载backbone,虽然只有97.8M还是很慢,我自己下载好后放到了该语句中提示的下载处。
restnet50的阿里云盘链接:https://www.aliyundrive.com/s/yb9SVcm4wY2
这时再重新运行,进行测试
python tracking/test.py stark_st baseline --dataset lasot --threads 32
五、STARK代码细节
持续补充ing…
测试结果会保存在STARK/test/tracking_results文件夹中
若要观察代码运行过程中每一帧的预测结果,STARK/lib/test/evaluation/tracker.py中约line 87
output = self._track_sequence(tracker, seq, init_info)
print(‘output[‘target_bbox’]’) # 视频中所有帧的预测结构
六、测试过程可视化
为了实时看到测试的结果,可以对原始代码略加修改,增加可视化部分。
这里需要注意一下:LaSOT的annotations和该项目中的output的预测框格式都是**[x,y,w,h]**,其中x:左上角的横坐标,y:左上角的纵坐标,w:目标的宽,h:目标的高。
所以可视化预测框的代码如下,将其添加在STARK/lib/test/evaluation/tracker.py的约line145行后(也就是_store_outputs(…)后),
img = cv.imread(frame_path)
pred_bbox = out['target_bbox']
cv.rectangle(img,(int(pred_bbox[0]),int(pred_bbox[1])),(int(pred_bbox[0]+pred_bbox[2]),int(pred_bbox[1]+pred_bbox[3])),(0,0,255),3)
cv.imshow(seq.name, img)
cv.waitKey(1)
再重新测试就可以看到实时检测的画面了,红色框就是算法的预测框。

















 5487
5487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









