






_mem.index.data:和sift_base.fbin一模一样。0-3字节是总向量数,4-7是每个向量的特征数。后面就是依次放置的每个向量。
_disk.index:是存储的图,但是不光包含图也包含原始向量。前4KB不知道存的是啥。从第0x1000开始存放的是原始向量,存放顺序和 _mem.index.data一致。每个原始向量后紧跟着的是4B的整数,代表邻居数。然后就是依序存放的邻居,每个邻居是4B的整形。然后就是下一个向量。存放原始向量的目的是为了遍历图的时候能够获取原始向量进行二次排序,与论文说的一致。然后DiskANN会对所有向量进行4K对齐,一个向量不会横跨两个4K块。所以每个4K块的末尾都会有一些为0的数据。
开头的字段定义在pq_flash_index.cpp中第1045行,对我们没有太大意义。包含了向量数量08-0F,向量维数10-17,pq中心数量18-1F,每个向量占的字节数20-27,每个4K块占包含的向量数量28-2F。文件的总大小48-4F
_pq_compressed.bin:存储的是DiskANN要放在内存中的压缩向量。0-3是向量总数,4-7是每个向量的字节数。后面就依次存放每个向量。至于这些PQ向量的中心在哪,被分成了几段什么的不知道。
_pq_pivots.bin:加载这个文件的代码在pq.cpp的load_pq_centroid_bin函数中。第一个4KB主要表示后面有几个偏移量。
首先从第4096开始读,4096开始的前4个字节是pq_file_num_centroids,并且会判断该值是否是256,这个值应该是代表有接下来有多少个向量。后面4个字节是pq_file_dim,应该是向量的维数。解析该文件的时候会和_pq_compressed.bin结合起来看。至于为什么256个向量就够了,这和PQ的原理有关。PQ压缩把他分为nchunk个类别,那么每个聚类的维数就是(维数/nchunk)。然后每个聚类内部有256个类别,即需要256个聚类中心。结合前两个,存储每个聚类中聚类中心的大小是256*(维数/nchunk)*特征大小。然后所有聚类需要的总大小就是256*(维数/nchunk)*特征大小*nchunk = 256*维数*特征大小 = 256个原始特征的大小。
256正好是2^8,那么PQ压缩的时候应该是每个聚类都最多有256个向量,_pq_compressed.bin存储PQ向量的时候每个聚类就最多只需要1B,也就是为什么不管内存设置为多大,_pq_compressed.bin的大小最多就是(维数*向量数)个字节。
然后第二个偏移量开始表示读取centroid,在pq.cpp的105行。centroid of each dimension。
然后第三个偏移量开始表示读取chunk_offsets,在pq.cpp的124行。表示偏移量,the offset of each chunk, start from 0。
_sample_data.bin和_sample_ids.bin:应该是采样的邻居,但是具体用途未知,经过测试和检索过程无关。_data是存放的原始向量,_ids是这些向量对应的id。这两个文件都是0-3字节表示这个文件包含多少个向量,4-7表示这些向量的维数。
关于入口点:
为SIFT1M构建索引时,包含的文件就上面几个。但是为bigann构建索引时,包含的文件中多出来了_disk.index_medoids.bin和_disk.index_centroids.bin。加载入口点的函数在pq_flash_index.cpp的第1128行。
他首先判断是否存在_disk.index_medoids.bin文件,如果存在则把其中的点(可能有很多个)加载为入口点,同时去_disk.index_centroids.bin读这些入口点对应的向量(如果不存在centroids文件则把_disk.index_medoids.bin里面的id对应的向量作为入口向量,顺带一提根据id读向量的函数read_nodes在pq_flash_index.cpp的第144行)。
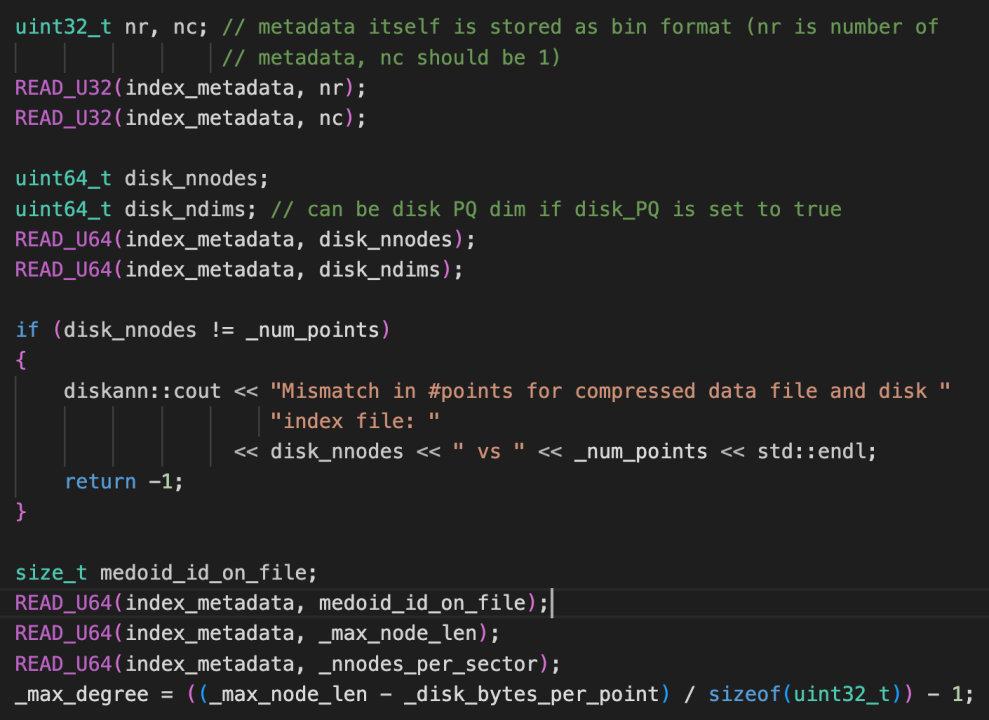
如果不存在_disk.index_medoids.bin文件,那么流程如下图所示。首先默认只有一个入口点medoid_id_on_file,这个id是从_disk.index中加载出来的,是第24-31个字节。
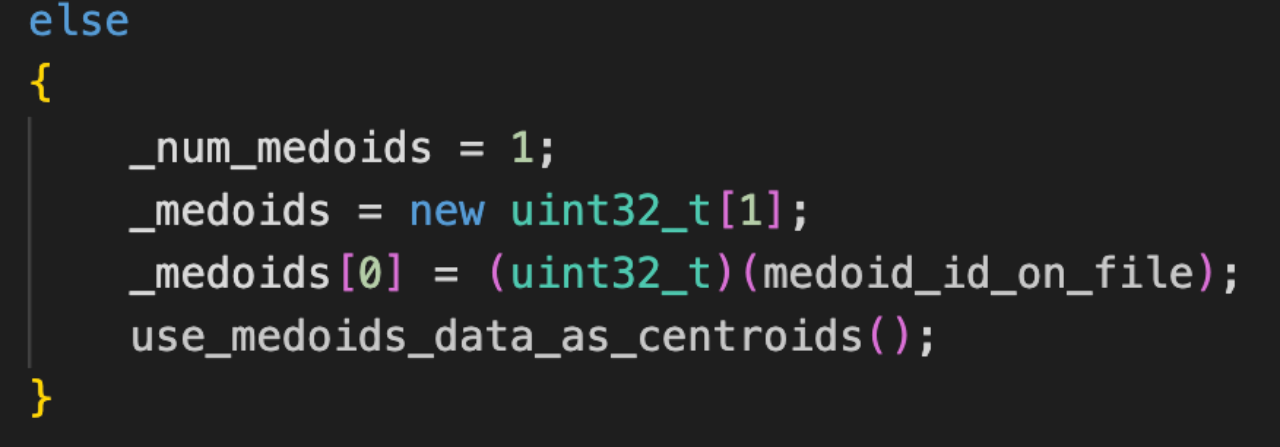
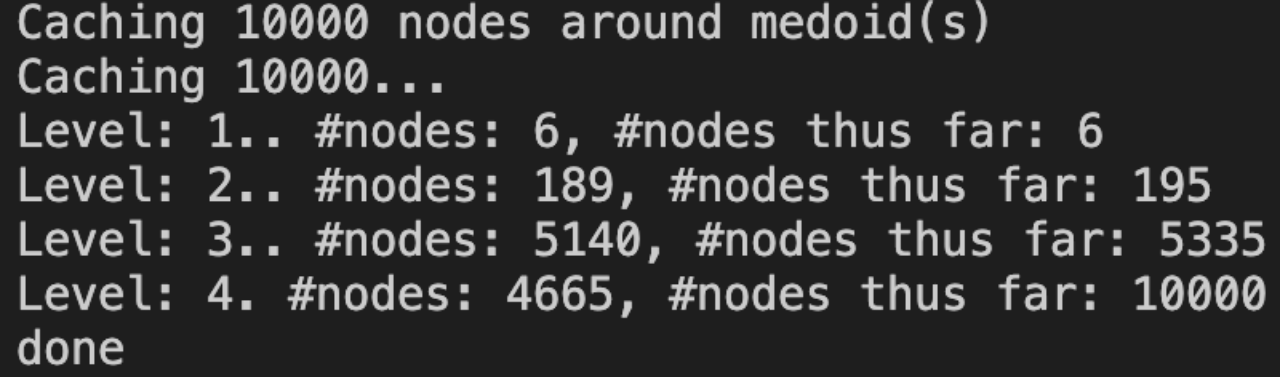
入口点会在缓存的时候作为第一层缓存进来,然后逐层向外扩展,如下图所示。
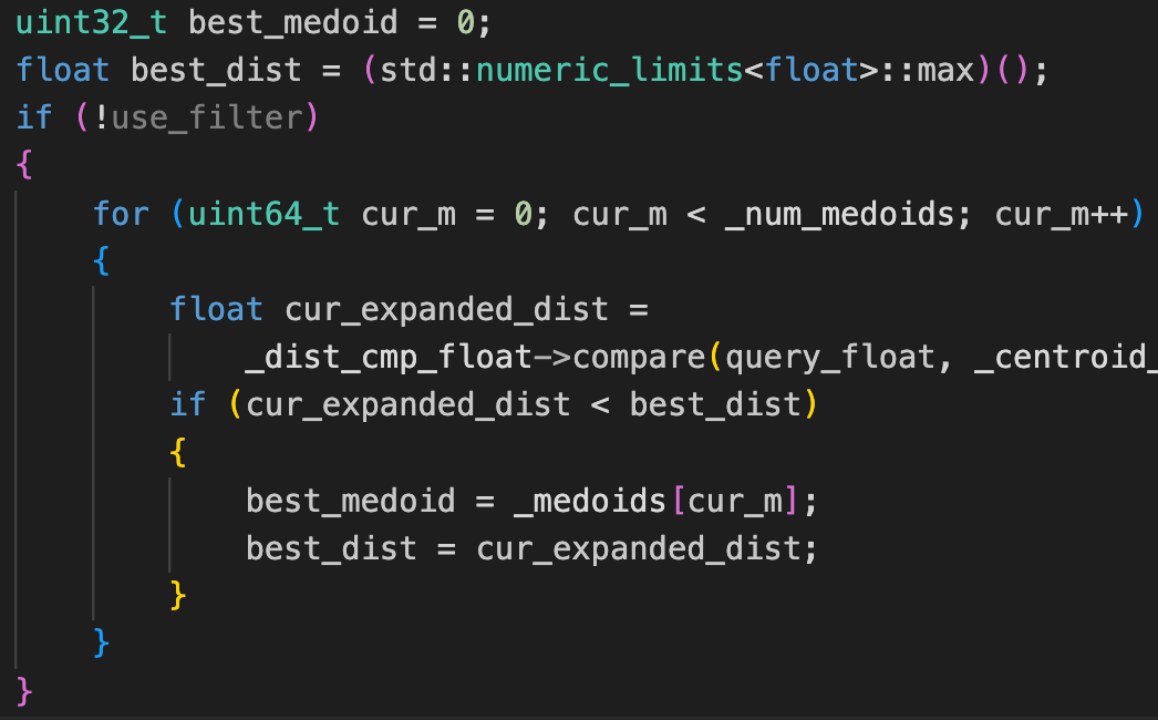
在检索的时候,会把入口点都遍历一遍,找到距离查询点最近的一个best_medoid,然后以这个点开始查询。

















 747
747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









