







LangChain Memory架构演进与技术解析
一、版本演进与开发状态
当前LangChain Memory模块(v0.0.X)仍处于测试阶段,主要受限于两大技术因素:
- 生产可用性:除ChatMessageHistory外,多数功能尚未通过企业级稳定性验证
- 语法适配:现有组件主要适配传统链式编程范式,对新兴的LCEL语法(LangChain Expression Language)支持有限
开发路线图显示,LangChain团队计划在0.3.0-0.4.0版本实现重大升级:
- 重构Memory接口以原生支持LCEL语法树
- 引入增量式记忆持久化机制
- 增加多模态记忆处理能力
二、核心架构设计
基类体系采用分层设计理念:
BaseMemory
├── SimpleMemory(轻量级无状态实现)
└── BaseChatMemory(对话场景专用)
├── ConversationBufferMemory
├── ConversationSummaryMemory
└── VectorStoreBackedMemory核心方法通过双重模式覆盖开发需求:
| 同步方法 | 异步方法 | 功能描述 |
|--------------------|----------------------|--------------------------|
| load_memory_variables | aload_memory_variables | 加载记忆上下文 |
| save_context | asave_context | 保存交互数据 |
| clear | aclear | 清空记忆存储 |三、组件特性对比
-
SimpleMemory
轻量级无状态容器,适用于无需记忆功能的场景。开发者可通过此类实现代码结构兼容性,例如:from langchain.memory import SimpleMemory dummy_memory = SimpleMemory(memories={"history": []}) -
BaseChatMemory
对话系统的专用基类,提供三大增强能力:- 多轮对话历史管理
- 上下文感知的prompt构建
- 自动化的记忆存储/检索流水线
典型实现包括:
- ConversationBufferMemory:全量存储对话记录(需注意token膨胀风险)
- ConversationSummaryMemory:通过摘要压缩历史信息(适合长对话场景)
- VectorStoreBackedMemory:基于向量数据库的语义检索记忆
四、开发实践建议
- 在LCEL语法成熟前,建议通过ChatMessageHistory手动集成记忆功能
- 生产环境优先选择经过稳定性验证的ConversationBufferWindowMemory(窗口记忆机制)
- 监控记忆组件的token消耗量,当单次对话超过2K tokens时需启用摘要或向量存储方案
LangChain 记忆组件的流程图如下: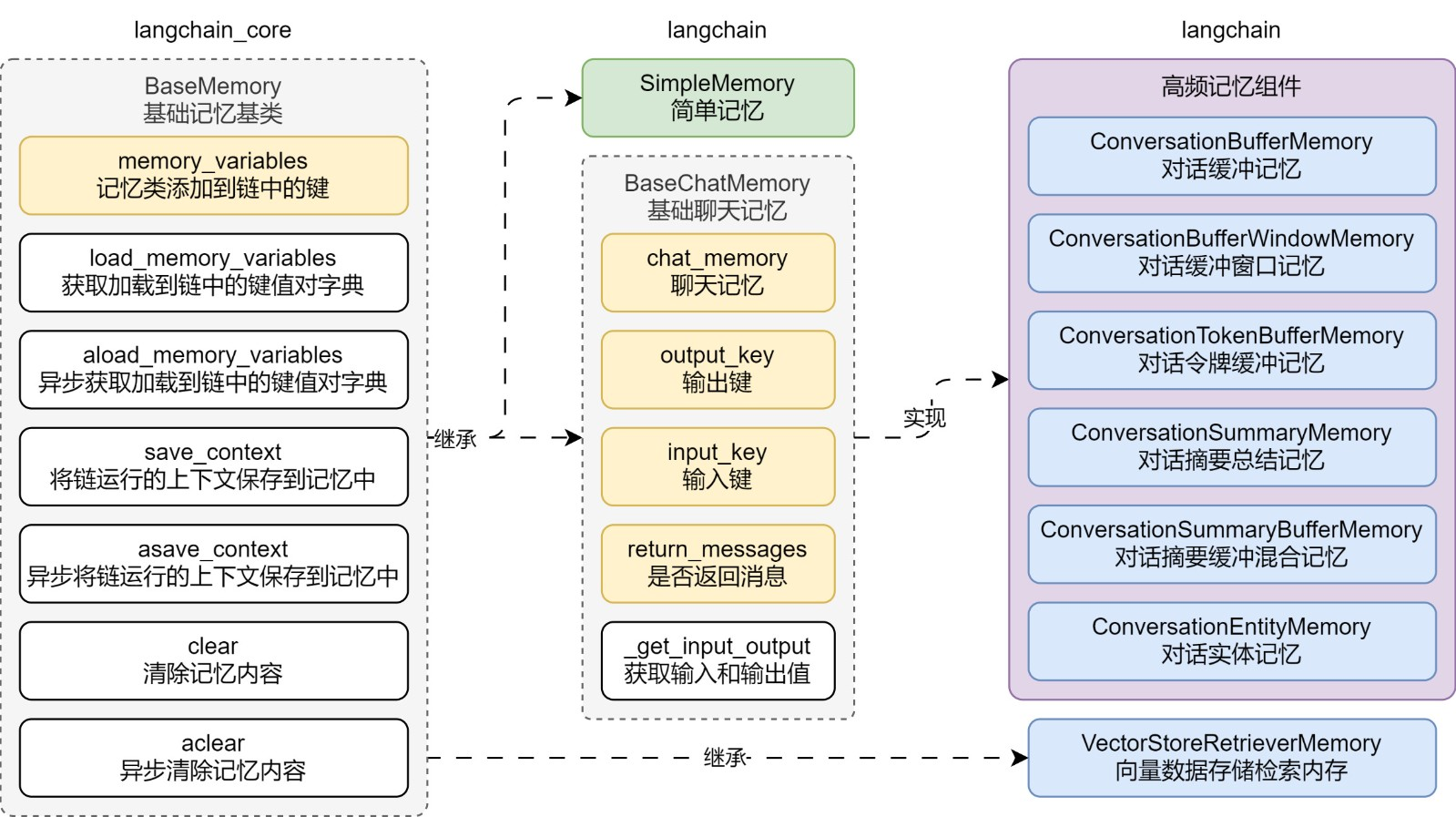


















 955
955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











