







论文题目:Sequence to Sequence Learning with Neural Networks
论文作者:Ilya Sutskever(Google)
发表时间: NIPS 2014
论文背景
- DNN在很多任务上取得了非常好的结果,但是它并不能解决Seq2Seq模型。
- 我们使用多层LSTM作为Encoder和Decoder,并且在WMT14英语到法语上取得了34.8的BLEU的结果。
- 此外,LSTM在长度上表现也很好,我们使用深度NMT模型来对统计机器翻译的结果进行重排序,能够使结果BLEU从33.3提高到36.5。
- LSTM能够很好地学习到局部和全局的特征,最后我们发现对源句子倒序输入能够大大提高翻译的效果,因为这样可以缩短一些词从源语言到目标语言的依赖长度。
网络模型
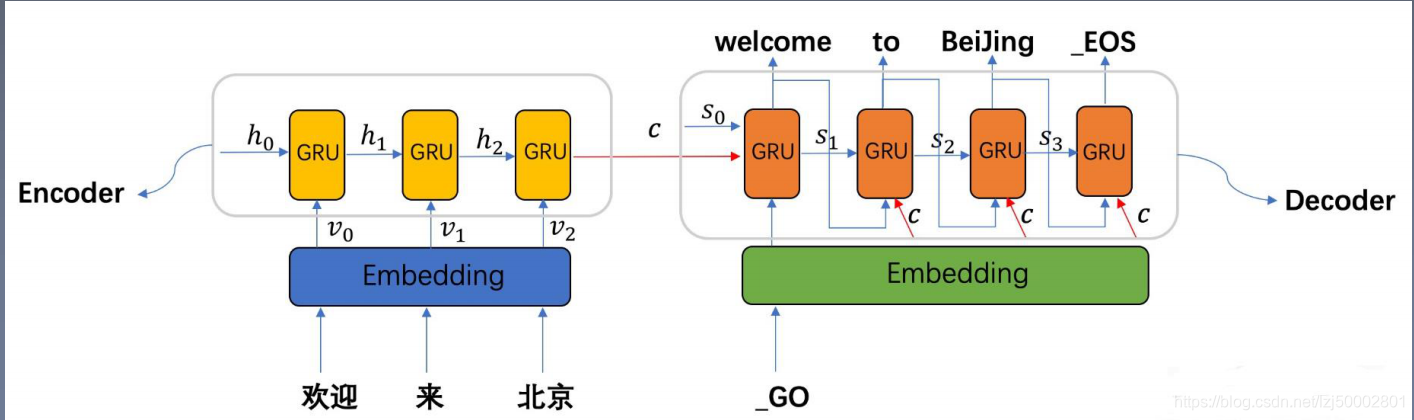
代码结构
import torch
import torch.nn as nn
import numpy as np
class Deep_NMT(nn.Module):
def __init__(self, source_vocab_size, target_vocab_size, embedding_size,
source_length, target_length, lstm_size):
super(Deep_NMT, self).__init__()
# 分别对源语言和目标语言生成词向量
self.source_embedding = nn.Embedding(source_vocab_size, embedding_size)
self.target_embedding = nn.Embedding(target_vocab_size, embedding_size)
# 定义encoder和decoder模型
self.encoder = nn.LSTM(input_size=embedding_size, hidden_size=lstm_size, num_layers=4,
batch_first=True)
self.decoder = nn.LSTM(input_size=embedding_size, hidden_size=lstm_size, num_layers=4,
batch_first=True)
# 全连接层
self.fc = nn.Linear(lstm_size, target_vocab_size)
def forward(self, source_data, target_data, mode="train"):
# 将源语言数据转换为词向量
source_data_embedding = self.source_embedding(source_data)
# 将源语言的词向量encoder,得到隐藏层
# enc_output shape: batchsize*length*lstm_length
# enc_hidden:返回每层最后一个时间步的h和c [h1,h2,...,hn,c1,c2,...,cn]
enc_output, enc_hidden = self.encoder(source_data_embedding)
if mode == "train":
# 将目标语言数据转换为词向量shape: batchsize*length*embedding_length
target_data_embedding = self.target_embedding(target_data)
# dec_output shape: batchsize*length*lstm_length
# dec_hidden:返回每层最后一个时间步的h和c [h1,h2,...,hn,c1,c2,...,cn]
dec_output, dec_hidden = self.decoder(target_data_embedding, enc_hidden)
# 全连接层输出,batchsize*length*target_vocab_size
outs = self.fc(dec_output)
else:
# 将目标语言数据转换为词向量
target_data_embedding = self.target_embedding(target_data)
# 将encoder的隐藏层作为decoder的输入层
dec_prev_hidden = enc_hidden
outs = []
for i in range(100):
# 将目标语言词向量和decoder的隐藏层作为输入,进行decoder
dec_output, dec_hidden = self.decoder(target_data_embedding, dec_prev_hidden)
# 全连接层,输出预测结果,然后取最好的pred
pred = self.fc(dec_output)
# 得到这个时间步的输出,也就是下一个时间步的输入 batchsize*1
pred = torch.argmax(pred, dim=-1)
outs.append(pred.squeeze().cpu().numpy())
# 然后将这个时间步的隐藏层作为下个时间步的隐藏层输入
dec_prev_hidden = dec_hidden
target_data_embedding = self.target_embedding(pred)
return outs
Tricks:
- 对于Encoder和Deocder,使用不同的LSTM(GRU是LSTM的一个变体,性能更好)。
- 深层的LSTM比浅层的LSTM效果好。
- 对源语言倒序输入会大幅度提高翻译效果。
应用:
4. 是谷歌翻译的基础。
5. 多层的LSTM配合Attention是Transformer出来前最好的模型。
评价方法:BLEU
背景:机器翻译需要人工翻译打分,成本太高,速度慢;所以提出了一种机器自动评价的方法;
出处: a Method for Automatic Evaluation of Machine Translation, 2002
1-GRAM: p 1 = C o u n t c l i p ( t h e ) C o u n t ( t h e ) p_1 = \frac {Count^{clip}(the)}{Count(the)} p1=Count(the)Countclip(the)
举个例子:
Candidate: the the the the the the the.
Reference 1: the cat is on the mat.
Reference 2: there is a cat on the mat.
结果:
C o u n t ( t h e ) = 7 Count(the) = 7 Count(the)=7
C o u n t 1 c l i p ( t h e ) = m i n ( 7 , 2 ) = 2 Count_1^{clip} (the) = min(7,2) = 2 Count1clip(the)=min(7,2)=2
C o u n t 2 c l i p ( t h e ) = m i n ( 7 , 1 ) = 1 Count_2^{clip} (the) = min(7,1) = 1 Count2clip(the)=min(7,1)=1
C o u n t c l i p ( t h e ) = m a x ( 2 , 1 ) = 2 Count^{clip}(the) = max(2,1) = 2 Countclip(the)=max(2,1)=2
- 问题1:1gram是按词翻译,而且不考虑句子流利性的问题,所以BLEU使用了1-4gram。
N-GRAM: p n = ∑ n _ g r a m ∈ C C o u n t c l i p ( n − g r a m ) ∑ n _ g r a m ∈ C C o u n t ( n − g r a m ) p_n=\frac{\sum_{n\_gram\in C}Count^{clip}(n-gram)}{\sum_{n\_gram\in C}Count(n-gram)} pn=∑n_gram∈CCount(n−gram)∑n_gram∈CCountclip(n−gram)
- 问题2:长度问题,如上例子中,如果预测句子为: the. p1概率为1,pn概率=0.25
解决方案:对长度增加惩罚
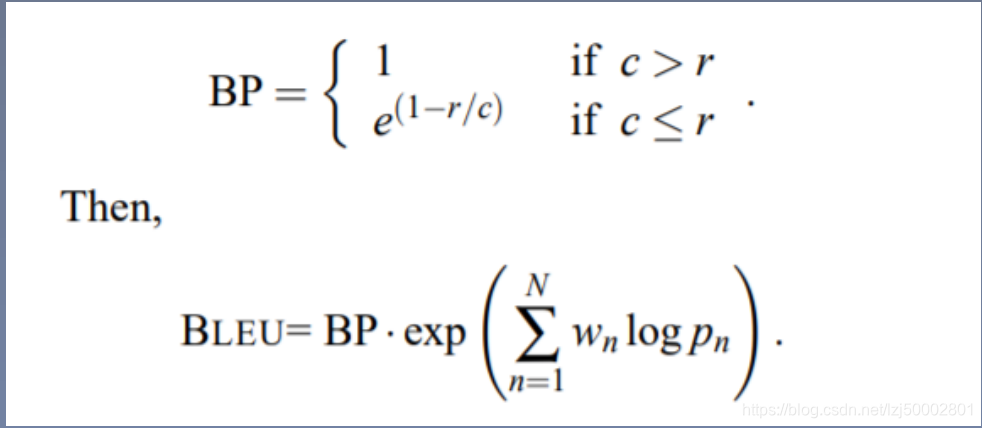
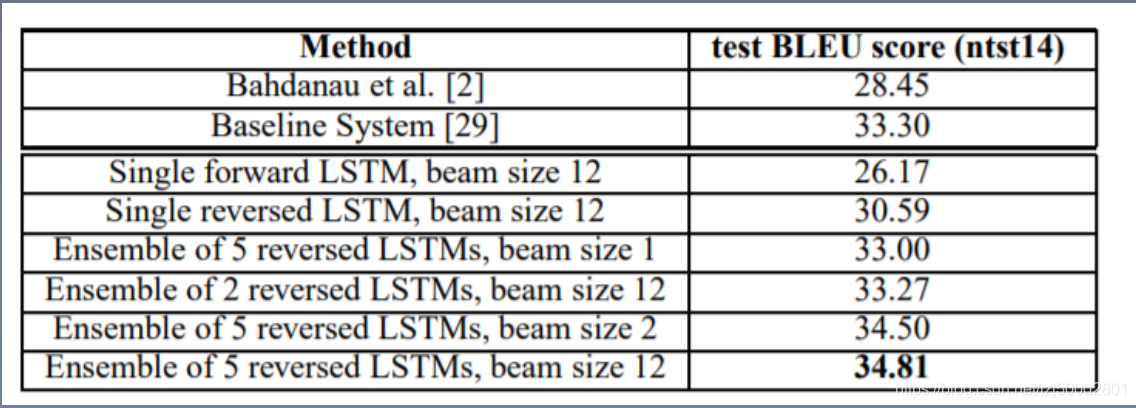
实验结果比较
和baseline进行比较
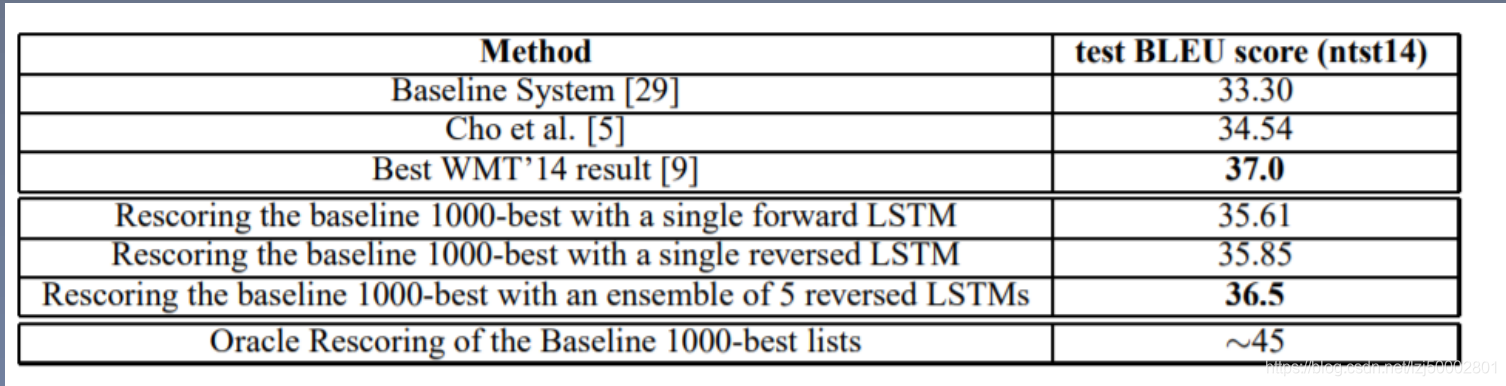
和最好的模型比较
翻译结果与词频的关系

论文总结
关键点
- 验证了Seq2Seq模型对于序列到序列任务的有效性。
- 从实验的角度发现了很多提高翻译效果的tricks
- Deep NMT模型
创新点
- 提出了一种新的神经机器翻译模型—Deep NMT模型
- 提出了一些提高神经机器翻译效果的tricks——多层LSTM和倒序输入等。
- 在WMT14英语到法语翻译上得到了非常好的结果。
启发点
- Seq2Seq模型就是使用一个LSTM提取输入序列的特征,每个时间步输入一个词,从而生成固定维度的句子向量表示,然后Deocder使用另外一个LSTM来从这个向量中生成输入序列。
The idea is to use one LSTM to read the input sequence, one timestep at a time, to obtain
large fixed dimensional vector representation, and then to use another LSTM to extract the
output sequence from that vector(Introduction P3)- 我们的实验也支持这个结论,我们的模型生成的句子表示能够明确词序信息,并且能够识别出来同一种含义的主动和被动语态。
A qualitative evaluation supports this claim, showing that our model is aware of word order
and is fairly invariant to the active and passive voice.(Introduction P8)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









