




 本文详细介绍使用Scrapy的XMLFeedSpider爬虫模板抓取中新网滚动新闻的过程,包括项目搭建、字段提取、数据清洗及存储至本地的方法。
本文详细介绍使用Scrapy的XMLFeedSpider爬虫模板抓取中新网滚动新闻的过程,包括项目搭建、字段提取、数据清洗及存储至本地的方法。
手动反爬虫:原博地址
知识梳理不易,请尊重劳动成果,文章仅发布在优快云网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
如若转载,请标明出处,谢谢!
1. 目标网址
中新网即时新闻,界面信息如下,内容是会按时间动态刷新
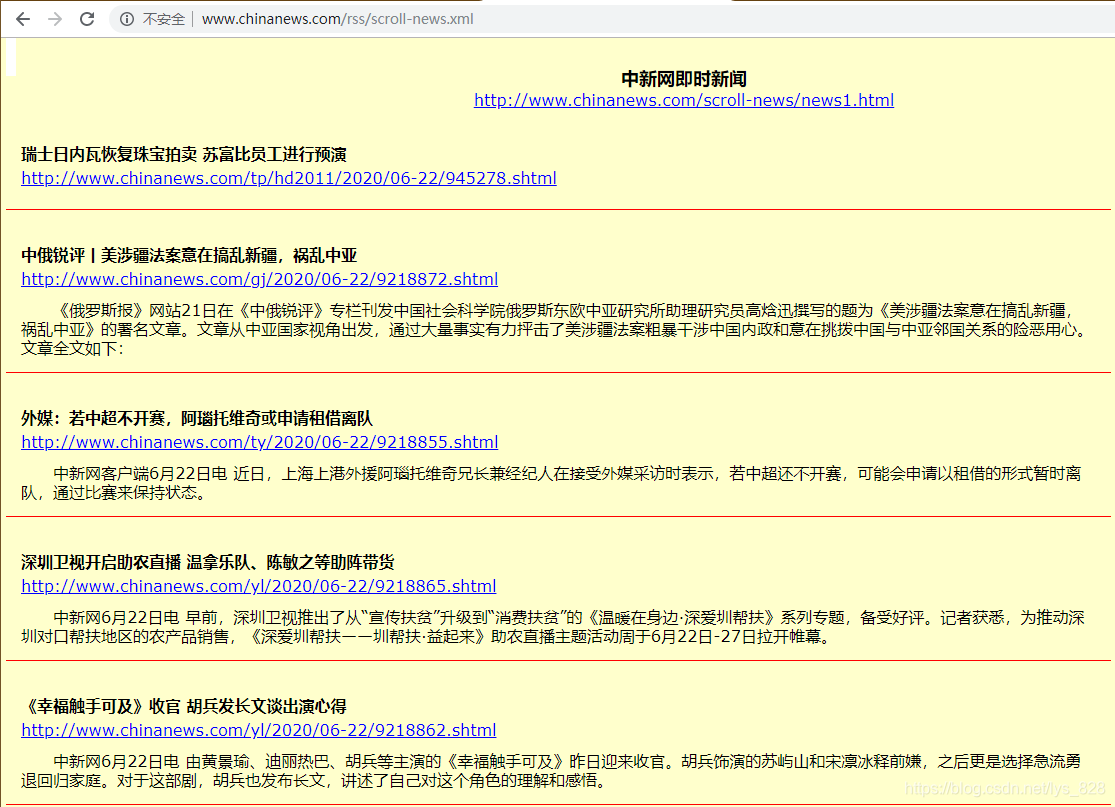
2. 项目爬取
2.1 新建项目
创建一个xmlfeed_demo项目的爬虫文件夹
scrapy srartproject xmlfeed_demo
cd ./xmlfeed_demo #接着接入创建好的文件夹下
2.2 创建csvfeed爬虫模板
紧接着上一个指令进行操作
scrapy genspider -t xmlfeed news chinanews.com
2.3 修改items.py文件
根据新闻网站上面的信息,可以发现可以获取的字段有四个,分别是新闻标题,新闻链接,新闻简述和更新时间,需要注意的是不是所有的新闻简述都存在的(比如第一条就没有)
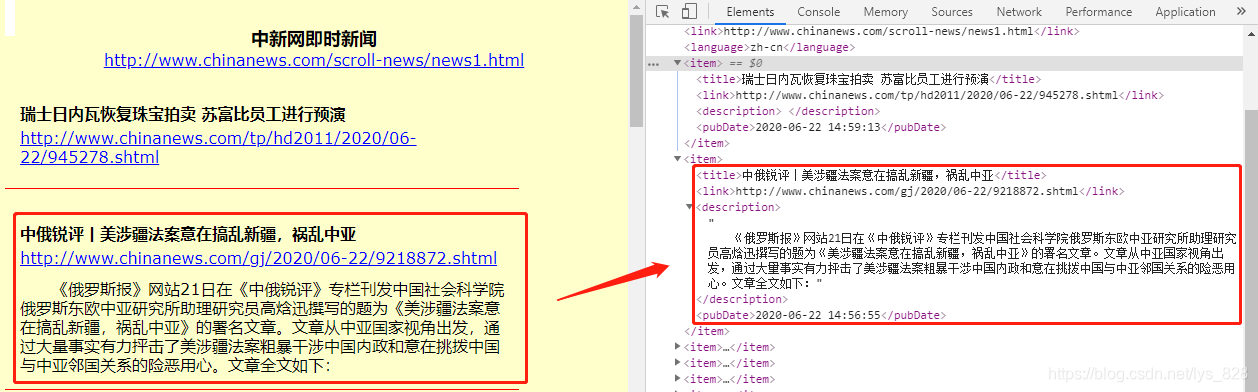
items.py文件中的代码修改如下,定义了四个爬取的字段
import scrapy
class XmlfeedDemoItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
link = scrapy.Field()
description = scrapy.Field()
pubDate = scrapy.Field()
2.4 修改news.py文件
进行爬虫内容代码的编写,模板中有详细的书写示范,这里根据自己的数据格式进行改进即可
from scrapy.spiders import XMLFeedSpider
from ..items import XmlfeedDemoItem
class NewsSpider(XMLFeedSpider):
name = 'news'
allowed_domains = ['chinanews.com']
start_urls = ['http://www.chinanews.com/rss/scroll-news.xml']
iterator = 'iternodes'
#iterator属性:设置使用的迭代器,默认为“iternodes”(一个基于正则表达式的高性能迭代器),除此之外还有“html”和“xml”迭代器;
# itertag = 'rss' # 设置开始迭代的节点
def parse_node(self, response, selector):
item =XmlfeedDemoItem()
#直接extract()之后是列表,这里.extract_first() 和 extract()[0]等价的
item['title'] = selector.xpath('title/text()').extract()[0]
item['link'] = selector.xpath('link/text()').extract()[0]
item['description'] =selector.xpath('description/text()').extract_first()
item['pubDate'] = selector.xpath('pubDate/text()').extract_first()
print(item)
return item
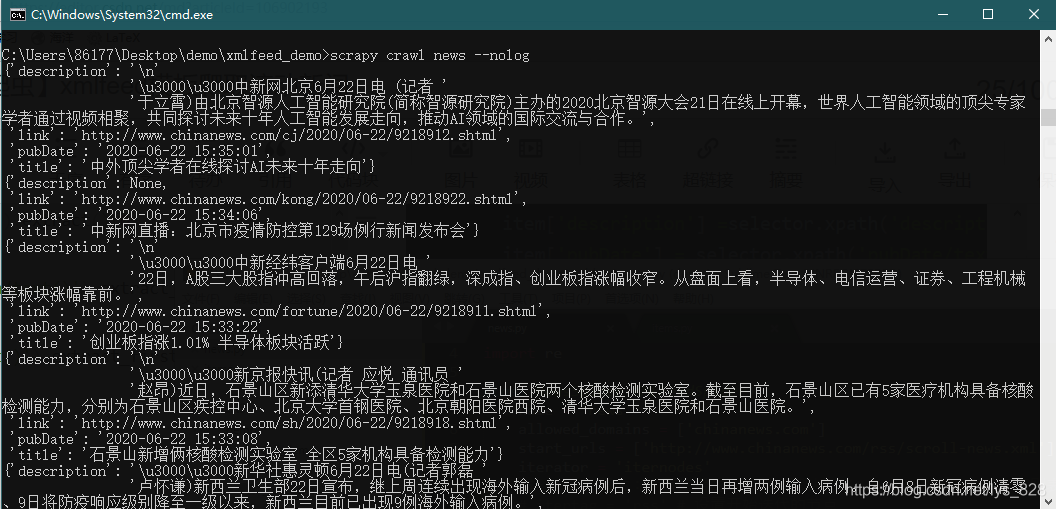
2.5 执行爬虫
命令行输入爬虫指令
scrapy crawl news --nolog
→ 输出的结果为:(可以看出在description字段,存在着大量的不需要字符,要进一步清洗)
这时候引入re库,将description字段的数据进行清洗,修改后的代码如下
from scrapy.spiders import XMLFeedSpider
from ..items import XmlfeedDemoItem
import re
class NewsSpider(XMLFeedSpider):
name = 'news'
allowed_domains = ['chinanews.com']
start_urls = ['http://www.chinanews.com/rss/scroll-news.xml']
iterator = 'iternodes'
#iterator属性:设置使用的迭代器,默认为“iternodes”(一个基于正则表达式的高性能迭代器),除此之外还有“html”和“xml”迭代器;
# itertag = 'rss' # 设置开始迭代的节点
def parse_node(self, response, selector):
item =XmlfeedDemoItem()
#直接extract()之后是列表,这里.extract_first() 和 extract()[0]等价的
item['title'] = selector.xpath('title/text()').extract()[0]
item['link'] = selector.xpath('link/text()').extract()[0]
#这一步是提取表格中的数据,转化成字符串后,替换掉里面的格式字符
description = selector.xpath('description/text()').extract()
item['description'] = re.sub(r'\s','',''.join(description))
item['pubDate'] = selector.xpath('pubDate/text()').extract_first()
print(item)
return item
→ 输出的结果为:(数据清洗完毕,可以在爬取过程中就清洗的数据尽量就清洗好入库,省的用时候再次进行数据的筛选及清洗)
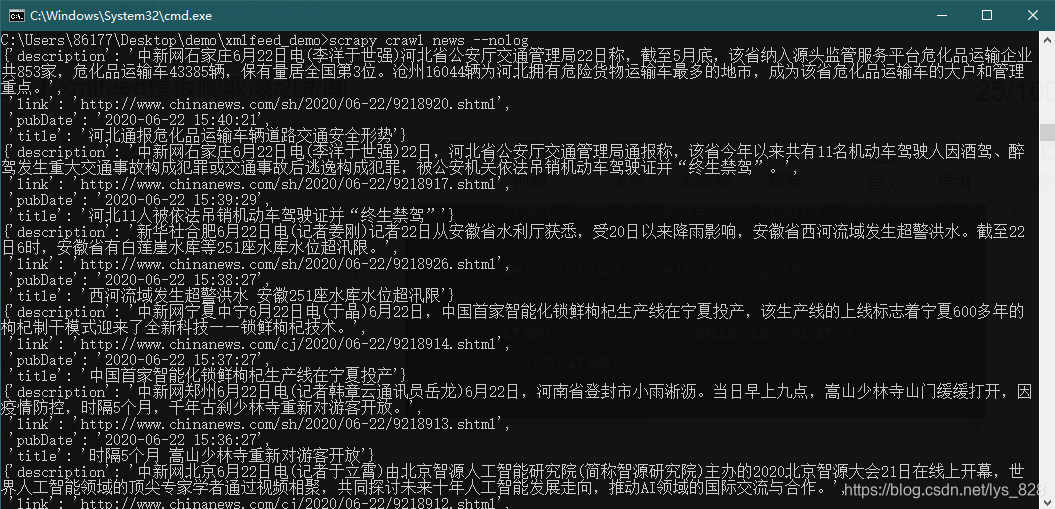
3. 保存文件
将爬取的内容保存至本地,这里采用txt和csv两种方式存放数据
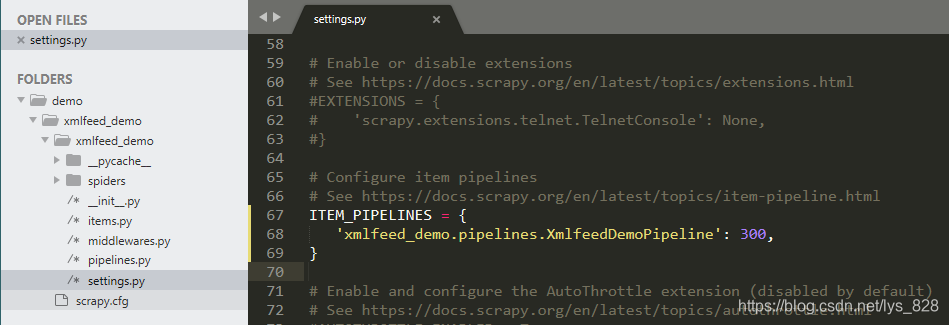
3.1 修改settings.py文件
一定不要忘记打开pipeline管道,不然只有就算写了保存数据的代码,最后也不会生成文件
3.1 修改pipeline.py文件(1)
先将数据保存为txt文本数据,具体的代码如下
class XmlfeedDemoPipeline(object):
def open_spider(self,spider):
self.file = open('news.txt', 'w',encoding='gbk')
def close_spider(self,spider):
self.file.close()
def process_item(self, item, spider):
try:
title=item['title']
link = item['link']
description =item['description']
pubDate = item['pubDate']
self.file.write('新闻标题:{},\n新闻链接:{},\n新闻简述:{},\n发布时间:{}\n\n'.format(
title,link,description,pubDate)
)
except:
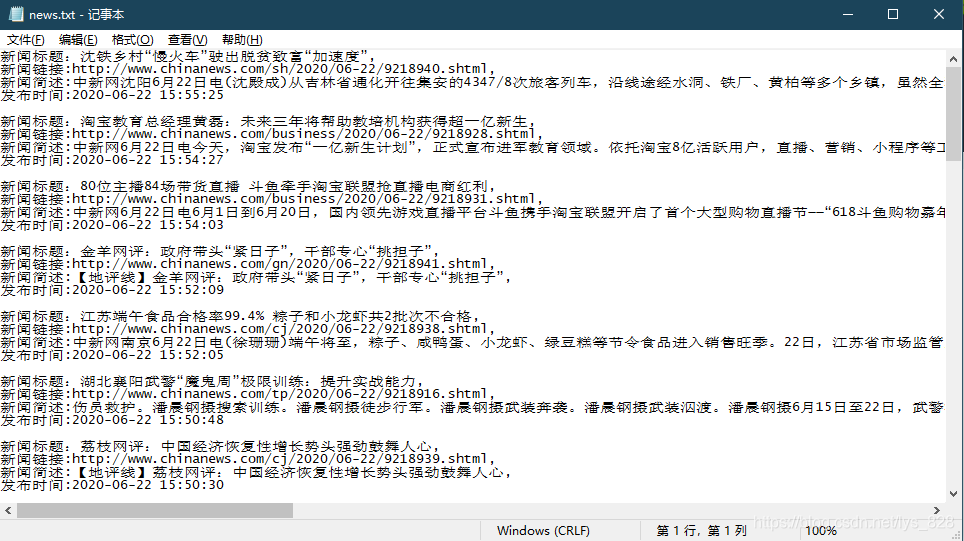
pass
→ 输出的结果为:(为了方便阅览,进行可视化输出)
3.2 修改pipeline.py文件(2)
接着就是生成csv文件,代码如下
from scrapy.exporters import CsvItemExporter
class XmlfeedDemoPipeline(object):
def __init__(self):
self.file = open('news.csv', 'wb')
self.exporter = CsvItemExporter(self.file, encoding = 'gbk')
self.exporter.start_exporting()
def close_spider(self,spider):
self.exporter.finish_exporting()
self.file.close()
def process_item(self, item, spider):
self.exporter.export_item(item)
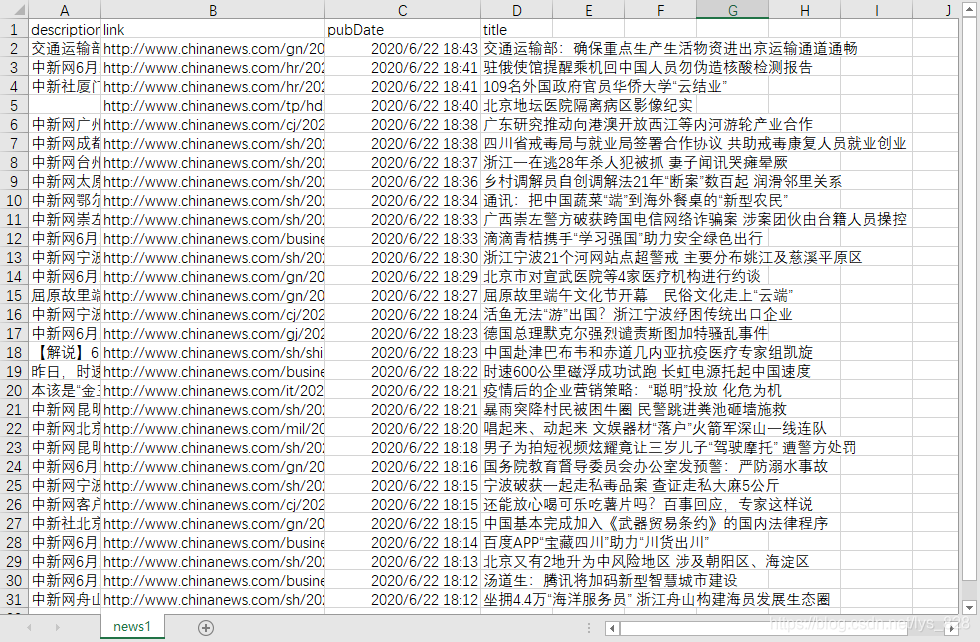
return item
→ 输出的结果为:(可以看出最终的输出的字段顺序并不是我们指定的顺序,因此需要进行设置)
4. csv文件指定字段顺序输出
将字典变成有序字典之后在转回原来的字典形式之后,巧妙的解决了这个问题代码如下,修改的内容在pipeline.py文件中,为了证明是按照字典的最初循序存放到csv文件中的,在为转换数据之前进行打印输出,最后对比输出到csv中的内容
from scrapy.exporters import CsvItemExporter
import json
from collections import OrderedDict
class XmlfeedDemoPipeline(object):
def __init__(self):
self.file = open('news.csv', 'wb')
self.exporter = CsvItemExporter(self.file, encoding = 'gbk')
self.exporter.start_exporting()
def close_spider(self,spider):
self.exporter.finish_exporting()
self.file.close()
def process_item(self, item, spider):
print('默认的字典数据:{}\n'.format(item))
item = OrderedDict(item)
item = json.dumps(item, ensure_ascii = False)
print('调整后的字典数据:{}\n'.format(item))
self.exporter.export_item(eval(item))
return item
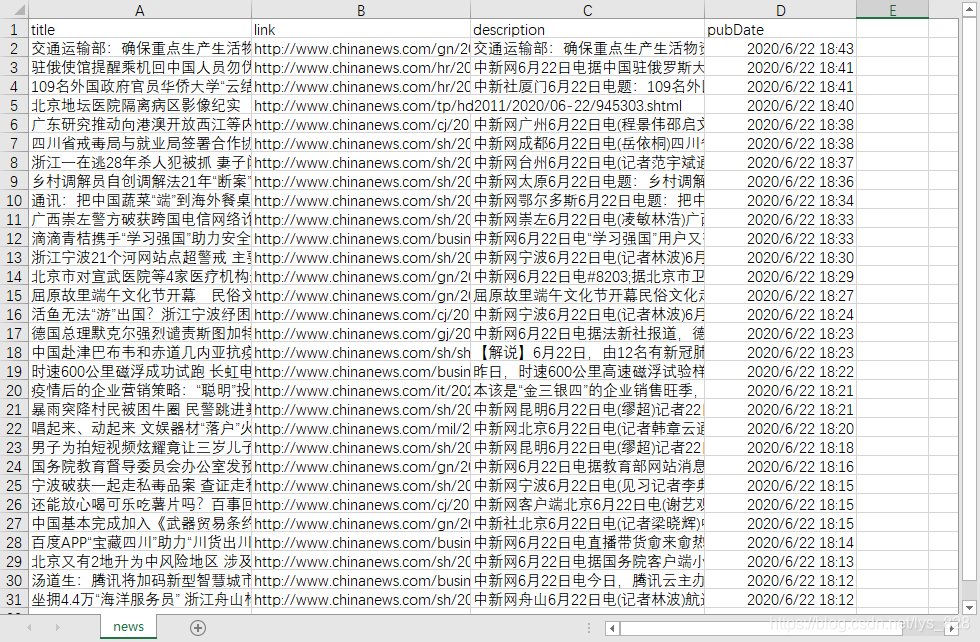
→ 输出的结果为:(这个就和最初的写的顺序一样了)
至此,xmlfeed模板爬取滚动新闻梳理结束,接下来就进行指定字段输出的详解


















 4743
4743

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











