









前言
还记得我第一次线上Redis宕机的场景,那种感觉就像你正在享受一场电影,突然电影院的灯亮了,屏幕黑了,所有人面面相觑,而你作为放映员只能无奈地面对观众的抱怨,这种体验真的非常难忘。
高可用架构就是为了避免这种尴尬场面而存在的,而Redis作为现代应用的核心组件,它的高可用性直接关系到整个系统的稳定性。
今天一起探索Redis分布式高可用架构,从基础概念到高级实践,一步步深入。
一,Redis高可用的基础概念
1.1 什么是Redis高可用
Redis高可用是指Redis服务在面对各种故障时依然能够保持服务的可用性,简单来说就是让Redis永远不下班,时刻准备着为应用提供服务,
想象一下,如果Redis是一家便利店,那么高可用就是确保这家店24小时营业,即使店长生病了,也有副店长能立刻顶上,确保顾客随时都能买到想要的商品,
1.2 为什么需要Redis高可用
我们为什么需要Redis高可用呢,原因很简单:
- 降低故障影响:单点Redis挂了,整个系统可能就瘫痪了,
- 提高系统可靠性:关键业务数据需要有保障,不能说丢就丢,
- 满足业务持续性:现代应用追求的是7*24小时不间断服务,
- 应对流量波峰:大促活动时,单个Redis实例可能扛不住,
一位资深架构师曾经告诉我:"系统可以慢,但绝不能挂,"这句话道出了高可用的核心要义,
二,Redis高可用的基本架构模式
Redis提供了多种高可用方案,就像武侠小说中的各门各派,各有各的绝技,下面我们来看看几种主流的高可用架构,
2.1 主从复制(Master-Slave)
主从复制是Redis最基本的高可用方案,它的工作原理如下:
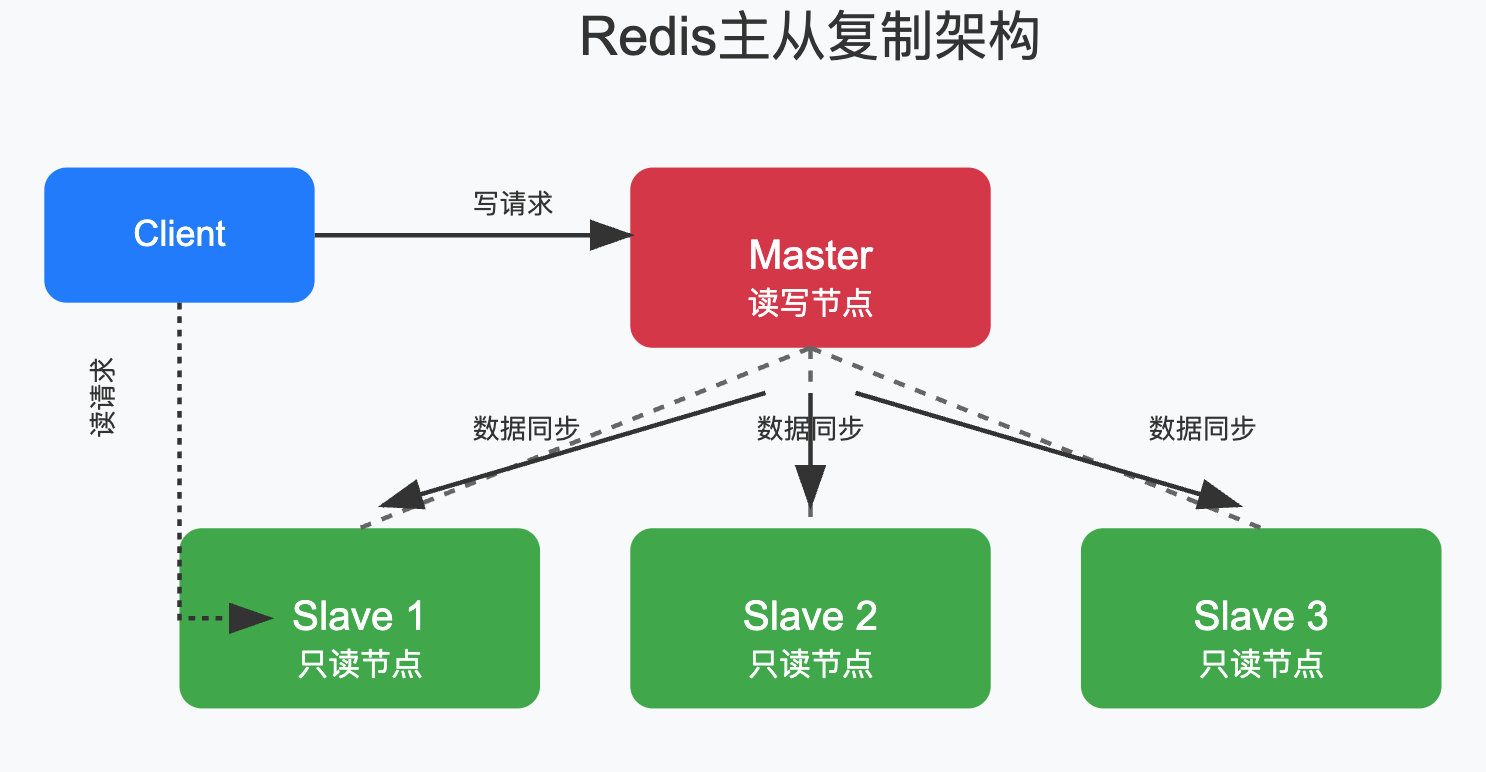
主从复制的核心特点:
- Master负责写操作,Slave负责读操作,
- Master将数据变更同步给Slave,
- 客户端可以连接任意节点,但写操作必须发送到Master,
主从复制的搭建非常简单,只需要在从节点上执行以下命令:
# 在从节点上执行
redis-cli> SLAVEOF 192.168.1.100 6379
# 或者在配置文件中设置
replicaof 192.168.1.100 6379
主从复制虽然简单,但它有一个致命缺点:当Master挂了,系统就失去了写入能力,需要手动将一个Slave提升为Master,这就好比店长病倒后,需要老板亲自来指定谁来当代理店长,效率很低,
2.2 哨兵模式(Sentinel)
为了解决主从复制中Master故障转移的问题,Redis提供了哨兵模式,它就像是给系统配备了一组"监工",时刻监控着Master的健康状况,一旦发现Master不行了,立即选举一个优秀的Slave顶上,
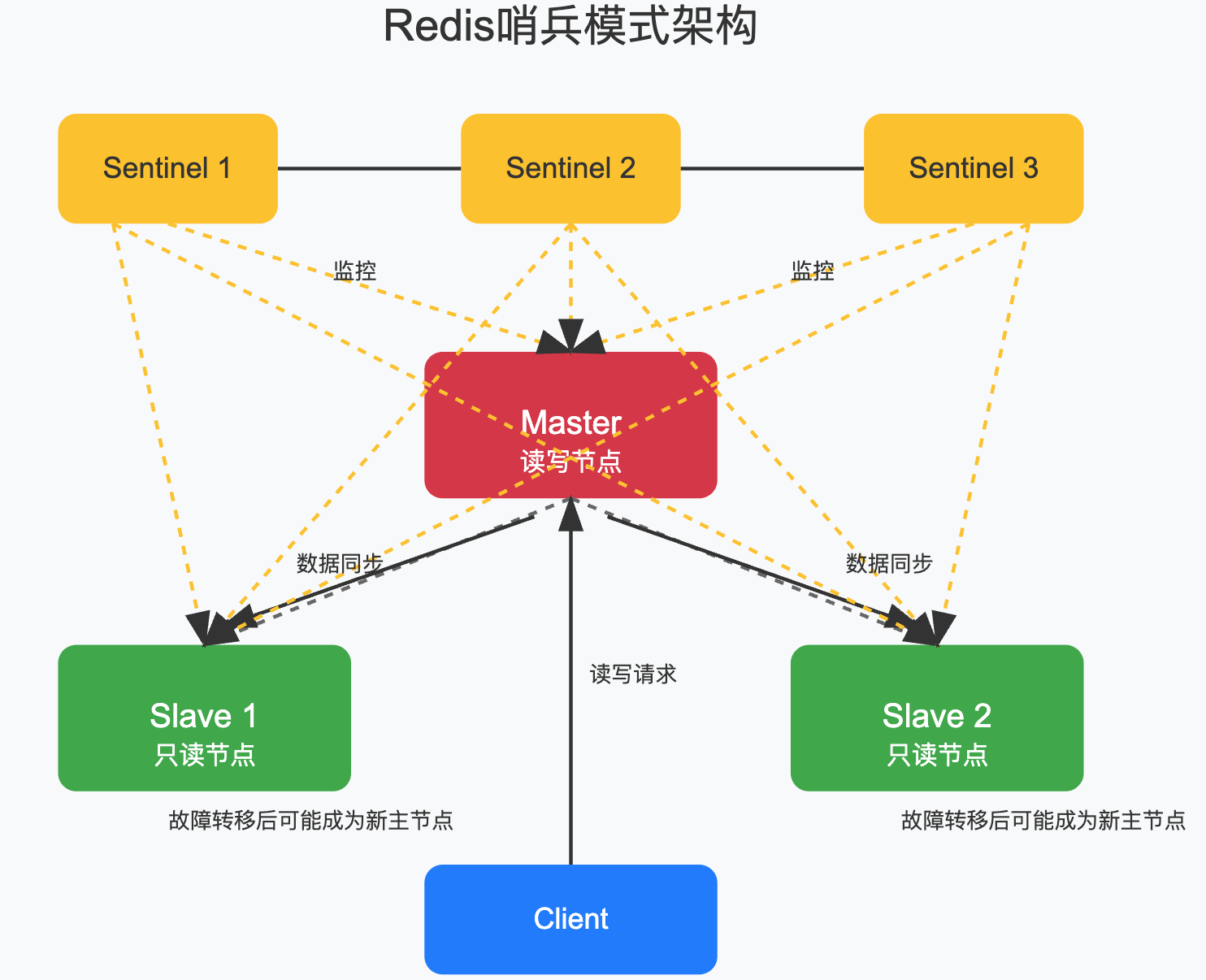
哨兵模式工作原理:
- 监控:多个哨兵持续监控Master和Slave的健康状态,
- 通知:当发现Master异常时,向系统管理员发送通知,
- 自动故障转移:
- 主观下线:单个哨兵认为Master不可用,
- 客观下线:超过配置数量的哨兵都认为Master不可用,
- 选举新Master:根据优先级,复制偏移量,运行ID等因素选出新Master,
- 通知客户端:通知客户端连接新的Master,
配置哨兵模式也很简单,创建一个sentinel.conf文件:
# sentinel.conf
# 监控的Master节点,名称为mymaster,2表示判定客观下线的哨兵数量
sentinel monitor mymaster 192.168.1.100 6379 2
# 判定主观下线的超时时间,默认30秒
sentinel down-after-milliseconds mymaster 30000
# 故障转移的超时时间,180秒
sentinel failover-timeout mymaster 180000
# 同时进行故障转移的Slave数量
sentinel parallel-syncs mymaster 1
然后使用以下命令启动哨兵:
redis-sentinel sentinel.conf
哨兵模式大大提高了Redis的高可用性,但它仍然存在一些问题:
- 水平扩展能力有限,
- 写操作仍然集中在单个Master节点,
- 数据量过大时,单个Master节点压力仍然很大,
2.3 Redis Cluster集群模式
当数据量继续增长,单Master架构不足以支撑业务需求时,就需要引入Redis Cluster集群模式,这种模式将数据分片存储在多个节点上,每个分片可以有自己的主从结构,
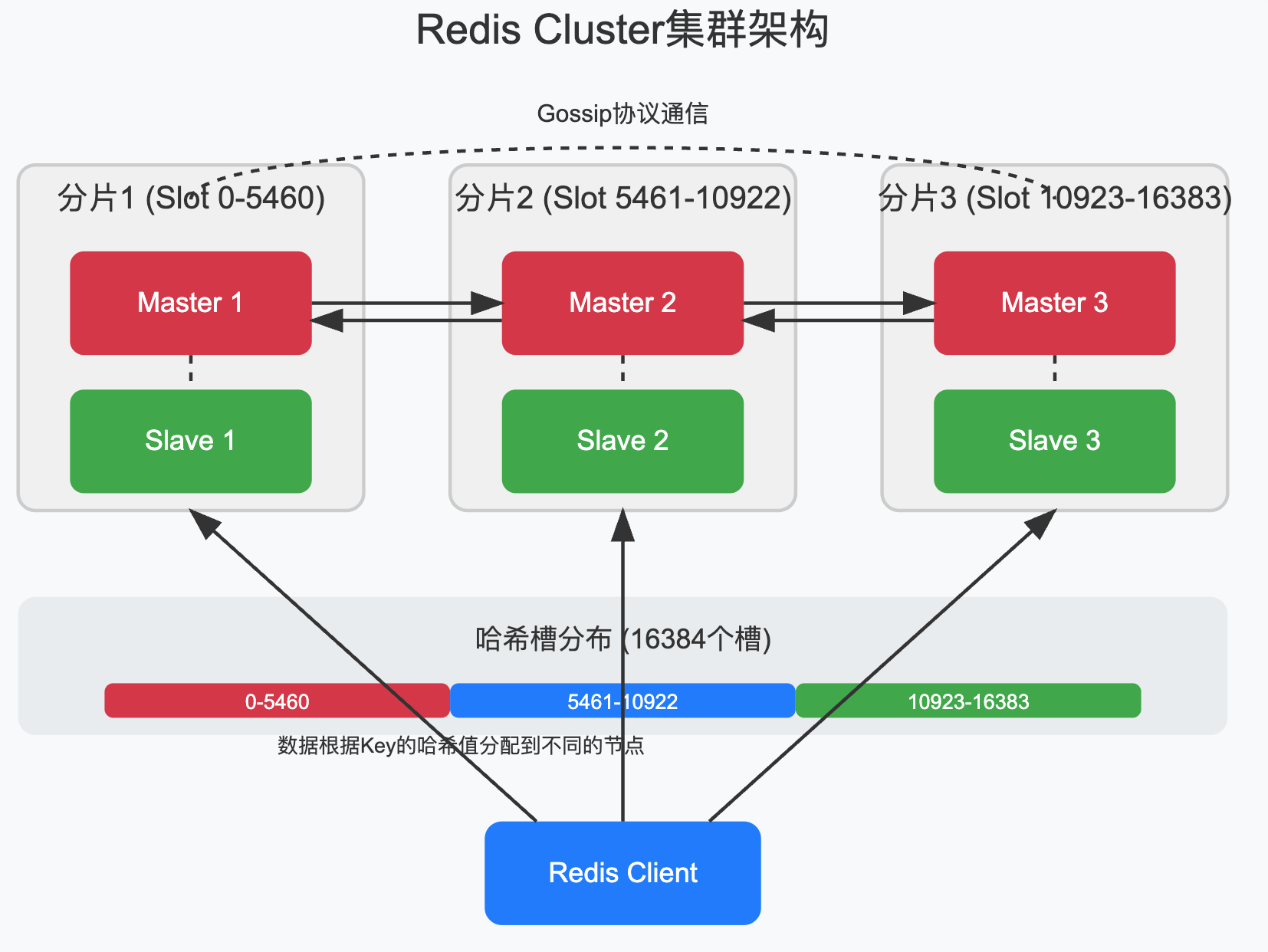
Redis Cluster的核心特点:
- 无中心架构,所有节点都是平等的,
- 数据按哈希槽(Hash Slot)分布,共16384个槽,
- 每个节点负责一部分槽,每个槽映射一个数据子集,
- 支持在线水平扩展和缩容,
- 节点间通过Gossip协议通信,
- 客户端可以连接任意节点,请求会被自动重定向,
Redis Cluster的配置示例:
# redis.conf
# 开启cluster模式
cluster-enabled yes
# 节点配置文件路径
cluster-config-file nodes-6379.conf
# 节点超时时间
cluster-node-timeout 15000
# 启用异步复制的情况下能够接受的数据丢失量
cluster-replica-validity-factor 10
# 标识此节点为集群节点
port 6379
创建Redis Cluster集群:
# 使用redis-cli命令创建集群
redis-cli --cluster create 192.168.1.100:6379 192.168.1.101:6379 192.168.1.102:6379 \
192.168.1.103:6379 192.168.1.104:6379 192.168.1.105:6379 \
--cluster-replicas 1
# 检查集群状态
redis-cli -c -h 192.168.1.100 -p 6379 cluster info
redis-cli -c -h 192.168.1.100 -p 6379 cluster nodes
上面的命令中,--cluster-replicas 1 表示为每个主节点配置一个从节点,这样创建的集群会有3个主节点和3个从节点,Redis Cluster是目前Redis官方推荐的分布式解决方案,适合大规模的Redis环境,
三,Redis高可用架构的核心原理分析
了解了各种高可用架构后,我们来深入探讨一下这些架构背后的核心原理,
3.1 主从复制的实现原理
Redis主从复制的完整过程分为以下几个阶段:
-
连接建立阶段:
- Slave向Master发送SYNC或PSYNC命令,
- Master启动后台线程生成RDB文件,
-
数据同步阶段:
- Master将RDB文件发送给Slave,
- Slave清空自己的数据,加载RDB文件,
-
命令传播阶段:
- Master将新写入的命令实时发送给Slave,
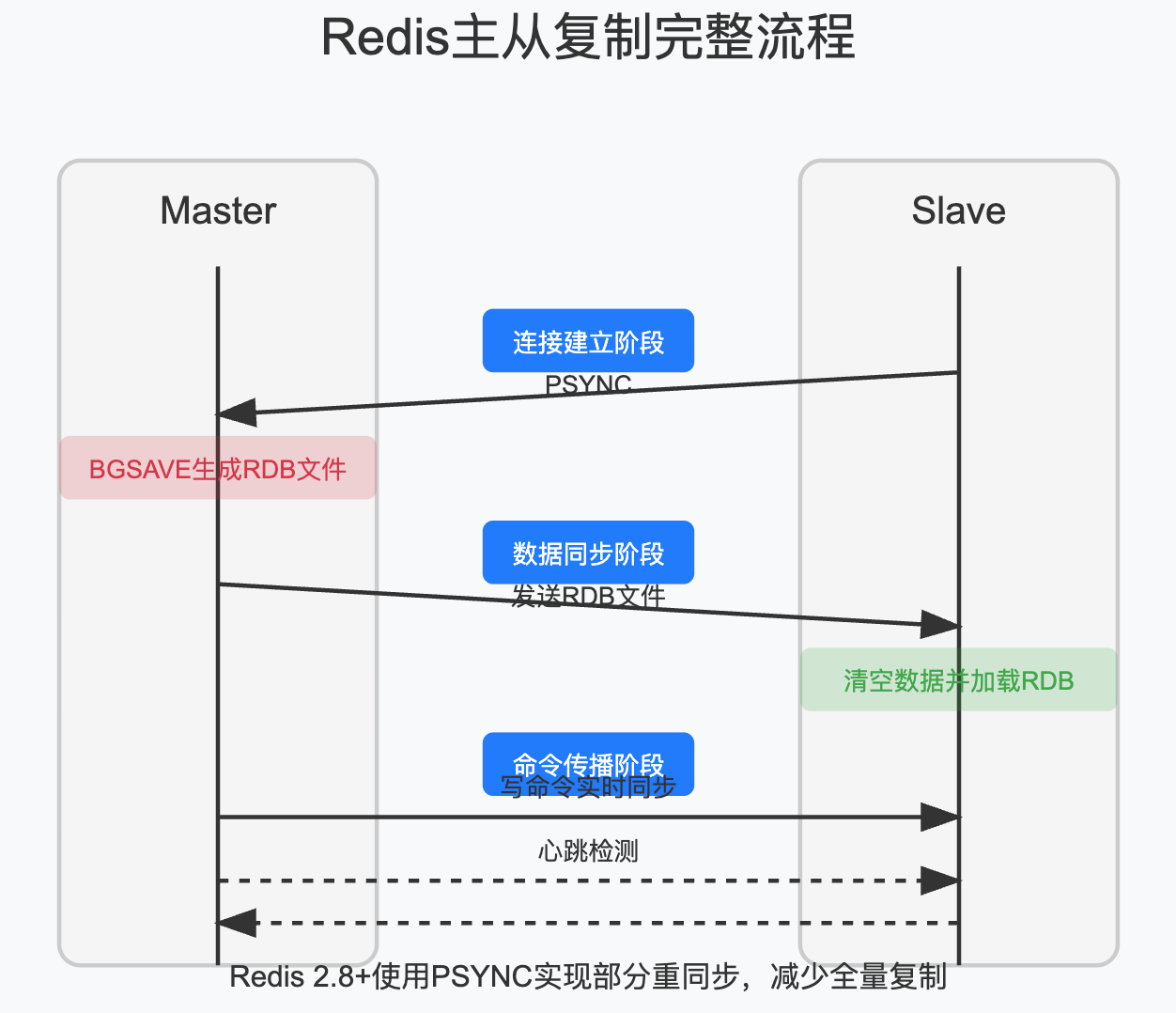
- Master将新写入的命令实时发送给Slave,
Redis 2.8版本后引入了PSYNC命令,支持部分重同步,大大提高了主从复制的效率,它的核心机制是:
- 复制偏移量:Master和Slave分别维护一个复制偏移量,记录传输的字节数,
- 复制积压缓冲区:Master维护一个固定长度的先进先出队列,默认1MB,
- 服务器运行ID:每个Redis实例启动时都会生成一个ID,用于唯一标识,
当Slave断线重连时:
- 如果运行ID相同,且复制偏移量在积压缓冲区范围内,执行部分重同步,
- 否则执行完整重同步,
来看部分重同步的代码实现关键部分:
/* 以下是Redis源码中关于PSYNC实现的简化版本 */
/* 处理PSYNC命令 */
void syncCommand(client *c) {
/* PSYNC runid offset */
if (!strcasecmp(c->argv[0]->ptr,"psync")) {
if (masterTryPartialResynchronization(c) == C_OK) {
/* 部分重同步成功 */
return;
}
/* 执行完整重同步 */
}
/* 以下是完整重同步的步骤 */
/* 1. 执行BGSAVE生成RDB文件 */
if (rdbSaveBackground(server.rdb_filename) != C_OK) {
addReplyError(c,"Background save failed");
return;
}
/* 2. 记录复制积压缓冲区起始偏移量 */
server.repl_backlog_histlen = 0;
server.repl_backlog_idx = 0;
server.repl_backlog_off = server.master_repl_offset;
/* 3. 设置客户端为从节点 */
c->flags |= CLIENT_SLAVE;
c->replstate = SLAVE_STATE_WAIT_BGSAVE_START;
listAddNodeTail(server.slaves,c);
}
/* 尝试部分重同步 */
int masterTryPartialResynchronization(client *c) {
long long psync_offset = -1;
char *master_runid = NULL;
/* 获取PSYNC参数 */
master_runid = c->argv[1]->ptr;
psync_offset = strtoll(c->argv[2]->ptr,NULL,10);
/* 检查runid是否匹配 */
if (strcasecmp(master_runid, server.runid) != 0) {
/* runid不匹配,需要完整重同步 */
addReplyMasterRejectedSync(c, "FULLRESYNC", server.runid, server.master_repl_offset);
return C_ERR;
}
/* 检查偏移量是否在积压缓冲区内 */
if (!server.repl_backlog || psync_offset < server.repl_backlog_off ||
psync_offset > server.repl_backlog_off + server.repl_backlog_histlen)
{
/* 偏移量超出范围,需要完整重同步 */
addReplyMasterRejectedSync(c, "FULLRESYNC", server.runid, server.master_repl_offset);
return C_ERR;
}
/* 部分重同步成功 */
c->replstate = SLAVE_STATE_ONLINE;
c->repl_ack_off = psync_offset;
c->flags |= CLIENT_SLAVE;
listAddNodeTail(server.slaves,c);
/* 计算偏移量差值,并发送积压缓冲区中的数据 */
long long offset = psync_offset - server.repl_backlog_off;
long long j;
for (j = offset; j < server.repl_backlog_histlen; j++) {
/* 发送命令到从节点 */
addReplyFromBacklog(c, j);
}
return C_OK;
}
虽然主从复制看起来很简单,但它也有一些需要注意的问题:
- 全量复制开销大:主节点需要生成RDB文件并传输,会消耗大量CPU、内存和网络带宽,
- 复制中断风险:如果复制过程中网络不稳定,可能导致复制中断,
- 读写分离不均衡:所有写操作集中在Master,可能成为性能瓶颈,
- 主节点故障无法自动转移:需要手动干预,
3.2 哨兵模式的实现原理
哨兵模式是建立在主从复制基础上的高可用方案,其核心原理包括:
- 监控:周期性地给所有Redis节点发送PING命令,判断节点是否可达,
- 通知:当监控的Redis节点出现问题时,发送通知给管理员,
- 自动故障转移:当Master不可用时,自动选择一个Slave提升为新的Master,
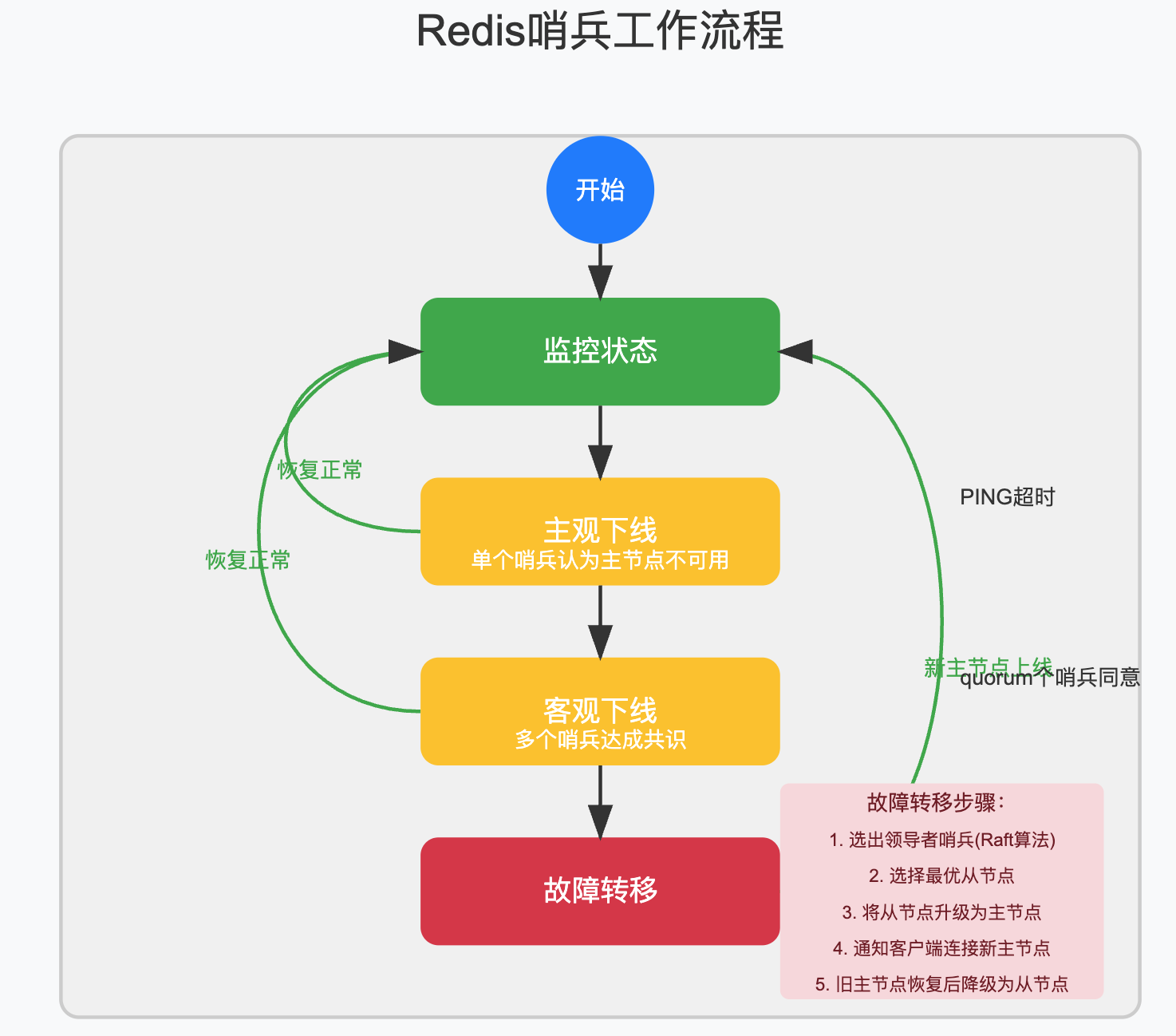
哨兵模式中最关键的是故障转移,它分为以下步骤:
- 领导者选举:使用Raft算法选出一个领导者哨兵,负责故障转移,
- 从节点选择:根据优先级、复制偏移量、运行ID等选出新的主节点,
- 配置更新:通知其他从节点连接新的主节点,
从节点选择的优先级如下:
- 优先级最高的从节点(通过slave-priority或replica-priority配置),
- 复制偏移量最大的从节点(数据最完整),
- 运行ID最小的从节点,
让我们来看看哨兵模式中的选举算法,这是其中的核心部分:
/* 以下是Redis哨兵选举算法的简化版本 */
/* 哨兵领导者选举,基于Raft算法 */
void sentinelStartFailoverIfNeeded(sentinelRedisInstance *master) {
/* 检查是否已经有足够的哨兵认为主节点下线 */
if (master->flags & SRI_S_DOWN &&
master->flags & SRI_O_DOWN &&
!(master->flags & SRI_FAILOVER_IN_PROGRESS))
{
/* 开始故障转移 */
sentinelStartFailover(master);
}
}
/* 开始故障转移流程 */
void sentinelStartFailover(sentinelRedisInstance *master) {
master->flags |= SRI_FAILOVER_IN_PROGRESS;
master->failover_start_time = mstime();
master->failover_state = SENTINEL_FAILOVER_STATE_WAIT_START;
master->failover_auth_count = 0;
master->failover_auth_sent = 0;
/* 生成新的选举纪元(epoch) */
master->failover_epoch = ++sentinel.current_epoch;
sentinelEvent(LL_WARNING,"+new-epoch",master,"%llu",master->failover_epoch);
/* 尝试投票给自己 */
sentinelEvent(LL_WARNING,"+try-failover",master,"%@");
master->failover_state = SENTINEL_FAILOVER_STATE_WAIT_START;
}
/* 投票请求处理 */
void sentinelReceiveIsMasterDownReply(redisAsyncContext *c, void *reply, void *privdata) {
sentinelRedisInstance *master = privdata;
/* 统计同意主节点下线的哨兵数量 */
if (reply && ((redisReply*)reply)->type == REDIS_REPLY_INTEGER &&
((redisReply*)reply)->integer == 1)
{
master->failover_auth_count++;
/* 如果获得足够的票数,进入选择新主节点阶段 */
if (master->failover_auth_count >= master->quorum) {
if (master->failover_state == SENTINEL_FAILOVER_STATE_WAIT_START) {
master->failover_state = SENTINEL_FAILOVER_STATE_SELECT_SLAVE;
sentinelEvent(LL_WARNING,"+elected-leader",master,"%@");
sentinelEvent(LL_WARNING,"+failover-state-select-slave",master,"%@");
}
}
}
}
/* 选择最佳从节点作为新主节点 */
sentinelRedisInstance *sentinelSelectSlave(sentinelRedisInstance *master) {
sentinelRedisInstance **slaves = NULL;
int numslaves = 0, i, j, selected;
/* 获取所有从节点 */
sentinelRedisInstance *slave = NULL;
/* 过滤不符合条件的从节点 */
dictIterator *di;
dictEntry *de;
di = dictGetIterator(master->slaves);
while((de = dictNext(di)) != NULL) {
slave = dictGetVal(de);
/* 只选择正常在线的从节点 */
if (slave->flags & (SRI_S_DOWN|SRI_O_DOWN)) continue;
if (slave->link->disconnected) continue;
/* 将符合条件的从节点加入候选数组 */
slaves = zrealloc(slaves, sizeof(sentinelRedisInstance*)*(numslaves+1));
slaves[numslaves++] = slave;
}
dictReleaseIterator(di);
/* 选择优先级最高的从节点 */
/* 如果优先级相同,选择复制偏移量最大的 */
/* 如果偏移量也相同,选择运行ID最小的 */
selected = -1;
for (i = 0; i < numslaves; i++) {
if (selected == -1 ||
slaves[i]->slave_priority < slaves[selected]->slave_priority ||
(slaves[i]->slave_priority == slaves[selected]->slave_priority &&
slaves[i]->slave_repl_offset > slaves[selected]->slave_repl_offset) ||
(slaves[i]->slave_priority == slaves[selected]->slave_priority &&
slaves[i]->slave_repl_offset == slaves[selected]->slave_repl_offset &&
strcmp(slaves[i]->name, slaves[selected]->name) < 0))
{
selected = i;
}
}
if (selected != -1) {
slave = slaves[selected];
}
zfree(slaves);
return slave;
}
哨兵模式解决了主从复制中的自动故障转移问题,但也有一些局限性:
- 脑裂问题:网络分区可能导致多个Master同时存在,
- 写入性能瓶颈:仍然是单Master架构,无法解决写入瓶颈,
- 资源利用率:大部分情况下只有一个节点处理写请求,资源利用率不高,
3.3 Redis Cluster的实现原理
Redis Cluster是一种无中心化的Redis集群方案,实现了数据的水平分片,其核心原理包括:
- 数据分片:使用哈希槽(Hash Slot)将数据分布到不同节点,
- 节点通信:使用Gossip协议实现节点间状态同步,
- 故障检测:节点间相互监视,实现故障检测和转移,
/* 计算键所属的哈希槽 */
unsigned int keyHashSlot(char *key, int keylen) {
int s, e; /* start-end indexes */
/* 查找花括号,支持hash tags */
for (s = 0; s < keylen; s++)
if (key[s] == '{') break;
/* 没有找到'{' */
if (s == keylen) return crc16(key,keylen) & 16383;
/* 找到了'{', 查找'}' */
for (e = s+1; e < keylen; e++)
if (key[e] == '}') break;
/* 没有找到'}'或者'{'和'}'之间没有内容 */
if (e == keylen || e == s+1) return crc16(key,keylen) & 16383;
/* 使用花括号中的内容计算哈希槽 */
return crc16(key+s+1,e-s-1) & 16383;
}
最有趣的是,Redis Cluster还支持哈希标签(Hash Tags)功能,通过花括号指定计算哈希槽的部分,这样可以让相关的键分配到同一个节点,便于实现事务和Lua脚本操作,例如:user:{123}:profile和user:{123}:orders会被映射到同一个槽中,
Redis Cluster使用Gossip协议进行节点间通信,这是一种去中心化的信息传播协议,就像人们之间的传言一样,信息会逐渐传播到整个集群,让我们看看这个协议的关键实现:
/* 发送Gossip消息 */
void clusterSendGossipMsg(void) {
int j, freshnodes = 0;
/* 统计当前已知的其他节点数量 */
dictIterator *di = dictGetSafeIterator(server.cluster->nodes);
dictEntry *de;
while((de = dictNext(di)) != NULL) {
clusterNode *node = dictGetVal(de);
if (node->flags & (CLUSTER_NODE_MYSELF|CLUSTER_NODE_NOADDR)) continue;
freshnodes++;
}
dictReleaseIterator(di);
/* 如果没有其他节点,直接返回 */
if (freshnodes == 0) return;
/* 更新我们的Ping发送计数 */
server.cluster->stats_bus_messages_sent[CLUSTERMSG_TYPE_PING]++;
/* 遍历所有节点,每次随机选择一部分节点发送gossip消息 */
di = dictGetSafeIterator(server.cluster->nodes);
while((de = dictNext(di)) != NULL) {
clusterNode *node = dictGetVal(de);
/* 不向自己或者没有地址的节点发送消息 */
if (node->flags & (CLUSTER_NODE_MYSELF|CLUSTER_NODE_NOADDR)) continue;
/* 计算要在Gossip中发送的其他节点信息 */
int wanted = floor(freshnodes/10);
if (wanted < 3) wanted = 3;
if (wanted > freshnodes) wanted = freshnodes;
/* 随机选择一些节点的信息加入到gossip消息中 */
clusterMsg *msg = clusterCreateMsg(CLUSTERMSG_TYPE_PING, NULL);
int gossipcount = 0;
for (j = 0; j < wanted; j++) {
/* 随机选择一个节点 */
clusterNode *gossipNode = getRandomNode();
/* 我们不把节点自身的信息告诉它 */
if (gossipNode == node) continue;
/* 添加节点信息到gossip消息 */
clusterSetGossipEntry(msg, gossipcount, gossipNode);
gossipcount++;
}
/* 发送消息 */
clusterSendMessage(node, msg, ntohl(msg->totlen));
}
dictReleaseIterator(di);
}
/* 处理接收到的Gossip消息 */
void clusterProcessGossipMsg(clusterMsg *hdr, clusterLink *link) {
uint16_t count = ntohs(hdr->count);
clusterMsgDataGossip *g = (clusterMsgDataGossip*) hdr->data.ping.gossip;
clusterNode *sender = link->node ? link->node : clusterLookupNode(hdr->sender);
/* 更新发送者的最后一次通信时间 */
if (sender) sender->pong_received = mstime();
/* 处理gossip中包含的每个节点信息 */
for (int j = 0; j < count; j++) {
uint16_t flags = ntohs(g[j].flags);
clusterNode *node;
/* 查找节点或者创建新节点 */
node = clusterLookupNode(g[j].nodename);
if (node == NULL) {
node = createClusterNode(g[j].nodename, flags);
clusterAddNode(node);
}
/* 更新节点信息 */
if (node != myself && !(flags & CLUSTER_NODE_NOADDR)) {
/* 仅当信息比我们已知的更新时更新 */
if (node->pong_received < ntohl(g[j].pong_received)) {
node->flags = flags;
node->pong_received = ntohl(g[j].pong_received);
}
}
}
}
Redis Cluster的故障检测基于PING/PONG机制,当一个节点发现另一个节点疑似下线时,会将该信息通过Gossip协议传播给其他节点,当超过半数的主节点都认为某个主节点下线时,才会触发故障转移,
Redis Cluster的客户端访问流程也很有意思:
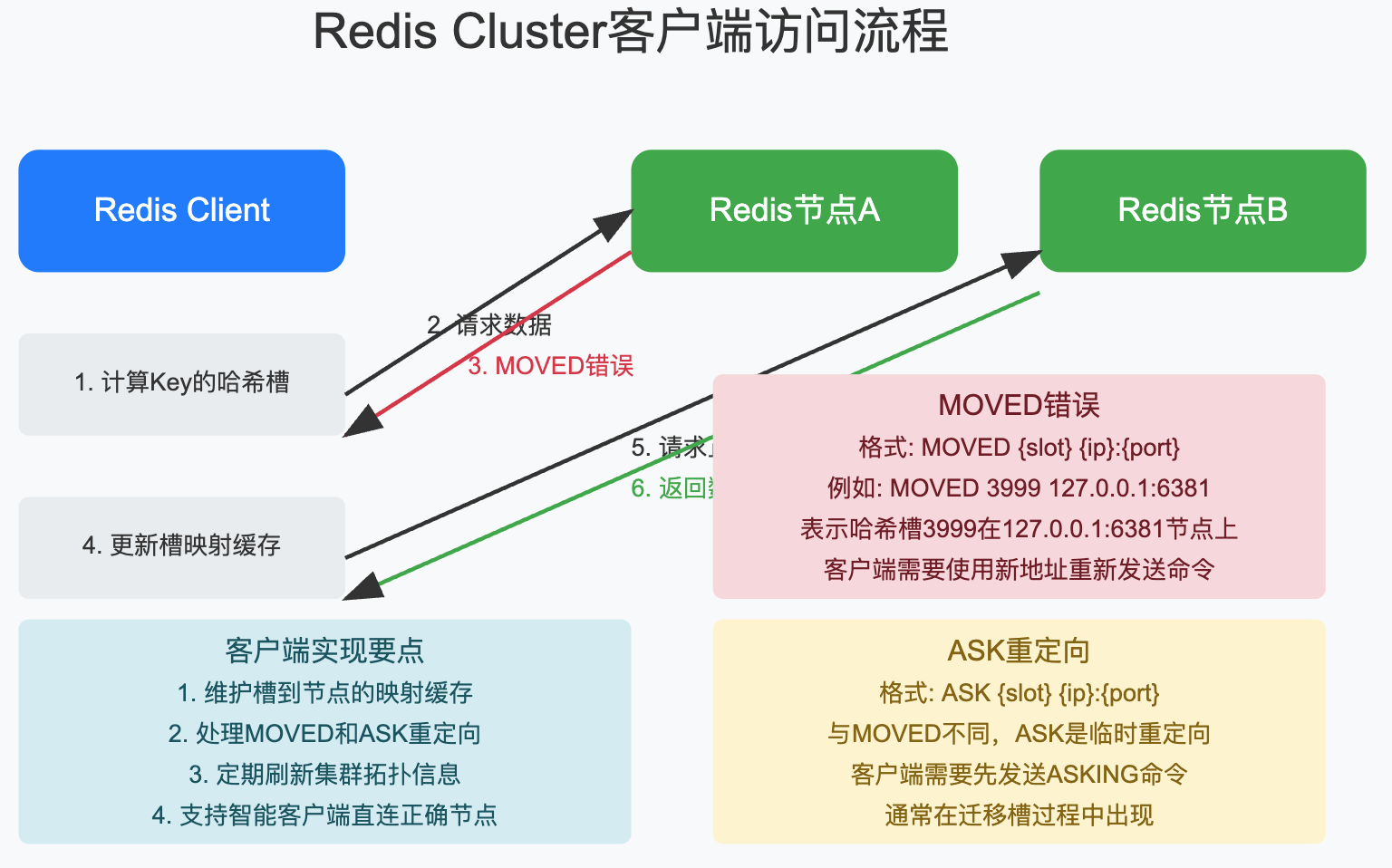
Redis Cluster引入了两种重定向机制:
- MOVED重定向:永久性重定向,表示某个槽已经被分配给了另一个节点,
- ASK重定向:临时性重定向,通常出现在槽迁移过程中,
虽然Redis Cluster解决了数据分片和高可用问题,但它也有一些不足:
- 事务支持有限:只支持对同一个槽中的键进行事务操作,
- 分布式锁实现困难:不同的键可能分布在不同的节点上,
- 集群管理复杂:节点的增减需要迁移大量数据,
- 客户端复杂度增加:客户端需要处理重定向等逻辑,
四,Redis分布式高可用架构的扩展方案
4.1 Redis Sentinel+读写分离
标准的Redis哨兵模式中,从节点通常只用于备份,但实际上可以让从节点承担读请求,这样可以减轻主节点的压力,
import redis
from redis.sentinel import Sentinel
# 创建哨兵连接
sentinel = Sentinel([
('sentinel1.example.com', 26379),
('sentinel2.example.com', 26379),
('sentinel3.example.com', 26379)
], socket_timeout=0.5)
# 获取主节点连接
master = sentinel.master_for('mymaster', socket_timeout=0.5, db=0)
# 获取从节点连接 (只读)
slave = sentinel.slave_for('mymaster', socket_timeout=0.5, db=0)
# 写操作使用主节点
def write_data(key, value):
try:
return master.set(key, value)
except Exception as e:
print(f"写入失败: {e}")
# 可以添加重试逻辑
return None
# 读操作使用从节点
def read_data(key):
try:
return slave.get(key)
except Exception as e:
print(f"读取从节点失败: {e}")
# 从节点失败时退化为从主节点读取
try:
return master.get(key)
except Exception as e:
print(f"读取主节点也失败: {e}")
return None
# 读取负载均衡 - 随机选择一个从节点
def read_with_load_balance(key):
# 随机获取一个从节点
slave = sentinel.slave_for('mymaster', socket_timeout=0.5, db=0)
try:
return slave.get(key)
except Exception as e:
print(f"读取从节点失败: {e}")
# 从节点失败时退化为从主节点读取
try:
return master.get(key)
except Exception as e:
print(f"读取主节点也失败: {e}")
return None
# 例:写数据
write_data('user:1001', '{"name": "Zhang San", "age": 30}')
# 例:读数据
user_data = read_data('user:1001')
实现读写分离的关键点:
- 主从同步延迟:从节点数据可能存在延迟,需要考虑应用是否能接受,
- 从节点选择策略:可以采用随机、轮询或最小连接数等策略选择从节点,
- 失败处理:从节点不可用时需要降级到主节点,
- 强一致性需求:对于要求强一致性的请求,仍需要从主节点读取,
4.2 多数据中心部署
对于大型应用,通常需要跨数据中心部署Redis,以应对区域性故障和提供就近服务,
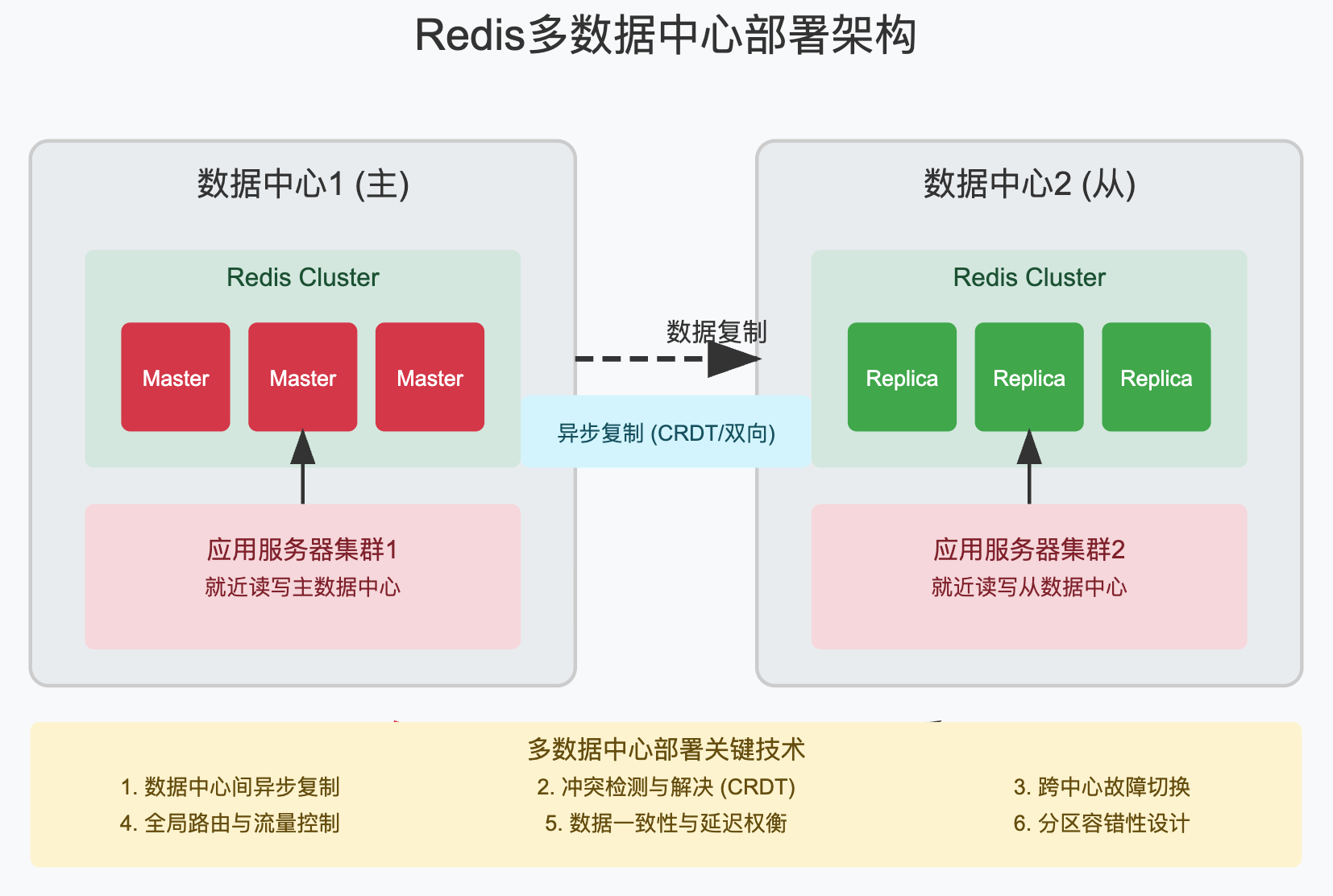
多数据中心Redis架构的关键技术:
- 数据中心间复制:使用Redis的复制功能或自定义同步机制,
- 冲突解决:采用CRDT(无冲突复制数据类型)或时间戳最新胜出策略,
- 故障切换:实现数据中心级别的故障切换机制,
- 流量路由:使用全局负载均衡将用户请求路由到最近的数据中心,
多数据中心部署的实现挑战:
- 网络延迟导致的数据一致性问题,
- 复制带宽消耗大,
- 冲突解决复杂,
- 运维成本高,
对于多数据中心场景,通常需要自定义开发数据同步组件:
import redis
import time
import threading
import json
import hashlib
from datetime import datetime
class RedisCrossDCSync:
def __init__(self, source_redis_config, target_redis_config, sync_interval=1):
"""
初始化跨数据中心Redis同步组件
:param source_redis_config: 源Redis配置
:param target_redis_config: 目标Redis配置
:param sync_interval: 同步间隔(秒)
"""
self.source_redis = redis.Redis(**source_redis_config)
self.target_redis = redis.Redis(**target_redis_config)
self.sync_interval = sync_interval
self.running = False
self.sync_thread = None
# 同步位置记录
self.sync_position_key = "_cross_dc_sync_position"
def start(self):
"""启动同步线程"""
if self.running:
return
self.running = True
self.sync_thread = threading.Thread(target=self._sync_loop)
self.sync_thread.daemon = True
self.sync_thread.start()
print("跨数据中心同步已启动")
def stop(self):
"""停止同步线程"""
self.running = False
if self.sync_thread:
self.sync_thread.join(timeout=10)
print("跨数据中心同步已停止")
def _sync_loop(self):
"""同步主循环"""
while self.running:
try:
self._perform_sync()
except Exception as e:
print(f"同步过程中发生错误: {e}")
time.sleep(self.sync_interval)
def _perform_sync(self):
"""执行一次同步操作"""
# 获取上次同步位置
last_position = self.target_redis.get(self.sync_position_key)
if last_position:
last_position = int(last_position)
else:
last_position = 0
# 从源Redis获取最新的更新操作
updates = self._get_updates_since(last_position)
if not updates:
return
# 应用更新到目标Redis
new_position = self._apply_updates(updates)
# 更新同步位置
if new_position > last_position:
self.target_redis.set(self.sync_position_key, new_position)
print(f"同步完成,同步位置更新到: {new_position}")
def _get_updates_since(self, position):
"""获取指定位置之后的所有更新操作"""
# 这里假设我们使用一个特殊的数据结构来记录更新操作
# 实际实现可能使用Redis Stream或自定义的复制日志
updates = []
# 从复制日志中获取更新
# 示例使用sorted set实现,实际可使用其他机制
log_key = "_update_log"
updates_data = self.source_redis.zrangebyscore(log_key, position + 1, "+inf")
for update_data in updates_data:
update = json.loads(update_data)
updates.append(update)
return updates
def _apply_updates(self, updates):
"""将更新应用到目标Redis,并返回新的同步位置"""
if not updates:
return 0
pipeline = self.target_redis.pipeline()
max_position = 0
for update in updates:
op_type = update.get("type")
key = update.get("key")
position = update.get("position")
# 记录最大位置
max_position = max(max_position, position)
# 根据操作类型执行不同的命令
if op_type == "set":
value = update.get("value")
ttl = update.get("ttl")
pipeline.set(key, value)
if ttl:
pipeline.expire(key, ttl)
elif op_type == "del":
pipeline.delete(key)
elif op_type == "expire":
ttl = update.get("ttl")
pipeline.expire(key, ttl)
elif op_type == "hash":
field = update.get("field")
value = update.get("value")
pipeline.hset(key, field, value)
# 可以添加其他类型的操作...
# 执行所有命令
pipeline.execute()
return max_position
def record_update(self, update_type, key, **kwargs):
"""记录一个更新操作到源Redis"""
log_key = "_update_log"
# 生成唯一的位置标识
position = int(time.time() * 1000) # 毫秒时间戳
# 构造更新记录
update = {
"type": update_type,
"key": key,
"position": position,
"timestamp": datetime.now().isoformat(),
**kwargs
}
# 将更新记录添加到复制日志
self.source_redis.zadd(log_key, {json.dumps(update): position})
# 清理旧日志条目(保留最近1小时的)
min_position = position - 3600 * 1000
self.source_redis.zremrangebyscore(log_key, 0, min_position)
return position
# 使用示例
if __name__ == "__main__":
# 源数据中心Redis配置
source_config = {
"host": "dc1-redis.example.com",
"port": 6379,
"db": 0,
"password": "password1"
}
# 目标数据中心Redis配置
target_config = {
"host": "dc2-redis.example.com",
"port": 6379,
"db": 0,
"password": "password2"
}
# 创建同步组件
sync = RedisCrossDCSync(source_config, target_config)
# 启动同步
sync.start()
# 在源Redis上记录更新操作
# 当应用程序写入Redis时也调用这些方法
# 可以通过代理层或钩子实现透明拦截
sync.record_update("set", "user:1001", value=json.dumps({"name": "Zhang San"}), ttl=3600)
sync.record_update("hash", "product:2002", field="price", value="299.99")
# 运行一段时间后停止
time.sleep(60)
sync.stop()
4.3 Redis与其他存储系统的混合架构
在实际生产环境中,通常会将Redis与其他存储系统结合使用,形成混合架构,以发挥各自的优势,
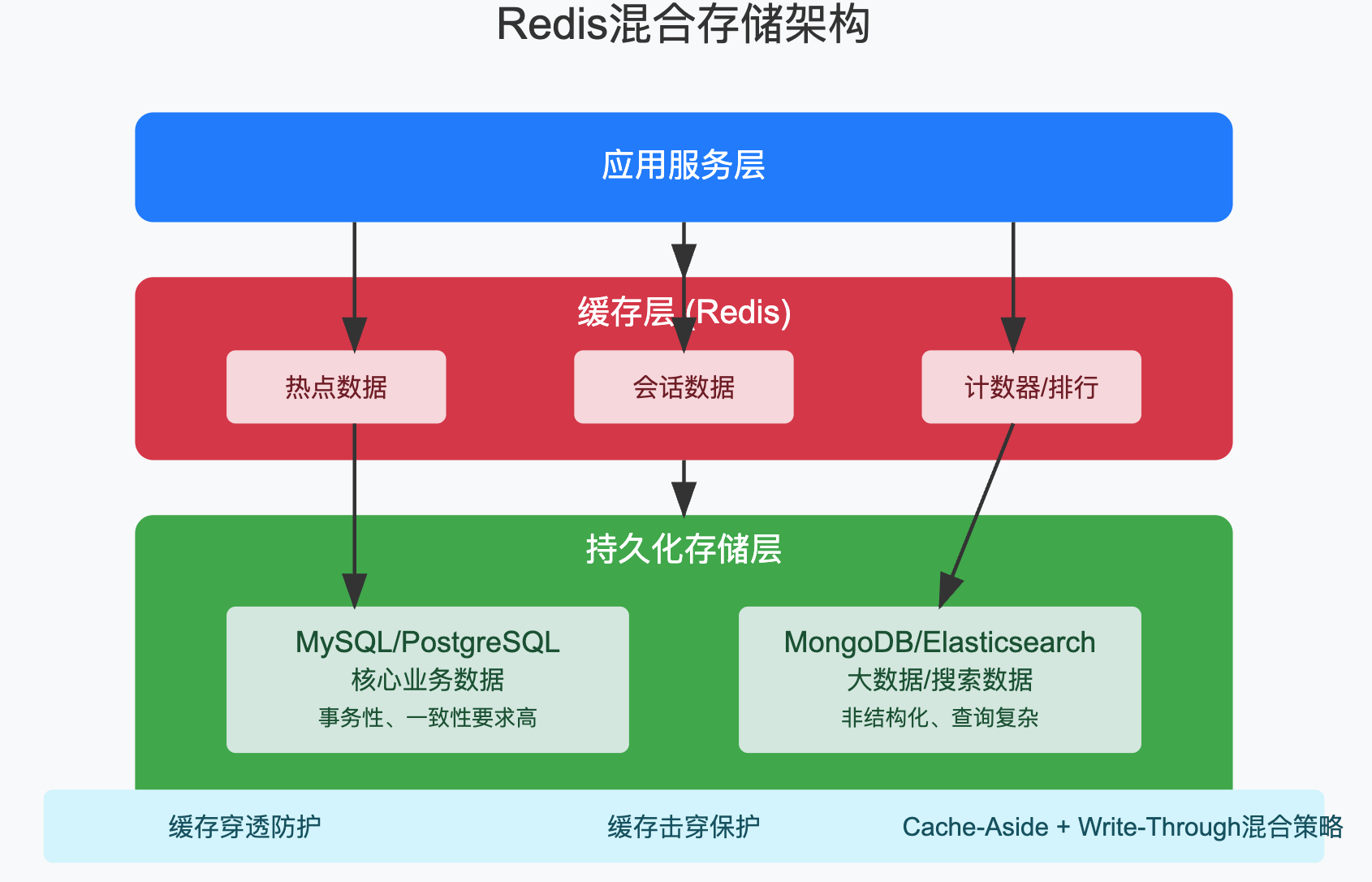
混合架构中,Redis通常承担以下角色:
- 热点数据缓存:缓存数据库中频繁访问的数据,
- 会话存储:存储用户会话信息,
- 计数器和排行榜:利用Redis的原子操作和排序能力,
- 消息队列:利用Redis的发布订阅或列表实现简单队列,
混合架构的缓存策略通常包括:
- Cache-Aside(旁路缓存):应用程序同时维护缓存和数据库,
/**
* Cache-Aside模式实现
*/
public class CacheAsideService {
private final RedisTemplate<String, Object> redisTemplate;
private final UserRepository userRepository;
// 缓存过期时间
private static final long CACHE_EXPIRATION = 3600; // 1小时
public CacheAsideService(RedisTemplate<String, Object> redisTemplate,
UserRepository userRepository) {
this.redisTemplate = redisTemplate;
this.userRepository = userRepository;
}
/**
* 读取数据的Cache-Aside模式
*/
public User getUserById(Long userId) {
String cacheKey = "user:" + userId;
// 1. 从缓存中查询
User user = (User) redisTemplate.opsForValue().get(cacheKey);
// 2. 缓存命中,直接返回
if (user != null) {
return user;
}
// 3. 缓存未命中,从数据库查询
user = userRepository.findById(userId).orElse(null);
// 4. 数据库中存在该数据,写入缓存
if (user != null) {
redisTemplate.opsForValue().set(cacheKey, user, CACHE_EXPIRATION, TimeUnit.SECONDS);
} else {
// 5. 防止缓存穿透,可以缓存空值或默认值,但过期时间较短
redisTemplate.opsForValue().set(cacheKey, new NullUser(), 60, TimeUnit.SECONDS);
}
return user;
}
/**
* 更新数据的Cache-Aside模式
*/
public void updateUser(User user) {
// 1. 更新数据库
userRepository.save(user);
// 2. 删除缓存
String cacheKey = "user:" + user.getId();
redisTemplate.delete(cacheKey);
// 注意: 这里选择删除缓存而不是更新缓存,避免数据不一致问题
}
/**
* 删除数据的Cache-Aside模式
*/
public void deleteUser(Long userId) {
// 1. 删除数据库中的数据
userRepository.deleteById(userId);
// 2. 删除缓存
String cacheKey = "user:" + userId;
redisTemplate.delete(cacheKey);
}
/**
* 防止缓存击穿的获取用户信息方法(加锁)
*/
public User getUserWithLock(Long userId) {
String cacheKey = "user:" + userId;
String lockKey = "lock:user:" + userId;
// 1. 从缓存中查询
User user = (User) redisTemplate.opsForValue().get(cacheKey);
// 2. 缓存命中,直接返回
if (user != null) {
return user;
}
// 3. 缓存未命中,尝试获取分布式锁
try {
boolean locked = redisTemplate.opsForValue().setIfAbsent(lockKey, "LOCKED", 10, TimeUnit.SECONDS);
if (locked) {
try {
// 4. 双重检查,避免其他线程已经更新了缓存
user = (User) redisTemplate.opsForValue().get(cacheKey);
if (user != null) {
return user;
}
// 5. 从数据库中查询
user = userRepository.findById(userId).orElse(null);
// 6. 更新缓存
if (user != null) {
redisTemplate.opsForValue().set(cacheKey, user, CACHE_EXPIRATION, TimeUnit.SECONDS);
} else {
redisTemplate.opsForValue().set(cacheKey, new NullUser(), 60, TimeUnit.SECONDS);
}
return user;
} finally {
// 7. 释放锁
redisTemplate.delete(lockKey);
}
} else {
// 8. 未获取到锁,短暂休眠后重试
Thread.sleep(50);
return getUserWithLock(userId);
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException("获取用户信息被中断", e);
}
}
// 空对象,用于缓存null结果,防止缓存穿透
private static class NullUser extends User {
private static final long serialVersionUID = 1L;
}
}
- Read-Through / Write-Through(读写穿透):缓存作为数据库的代理,
- Write-Behind(异步写入):先更新缓存,再异步更新数据库,
- Refresh-Ahead(预刷新):缓存在过期前主动刷新数据,
混合架构中常见的挑战及解决方案:
-
缓存穿透:大量查询不存在的数据导致请求直接打到数据库,
- 解决:缓存空值、布隆过滤器,
-
缓存击穿:热点key过期导致大量请求打到数据库,
- 解决:互斥锁、热点数据永不过期,
-
缓存雪崩:大量缓存同时过期,
- 解决:过期时间随机化、多级缓存,
-
数据一致性:缓存与数据库数据不一致,
- 解决:延迟双删、消息队列异步通知,
五,Redis分布式高可用架构的面试热点解析
作为一个资深架构师,掌握Redis高可用架构的面试热点是必不可少的,以下是几个常见问题及分析:
5.1 Redis主从复制的原理及可能遇到的问题?
关键回答点:
- 全量同步和增量同步机制,
- 复制积压缓冲区和复制偏移量的作用,
- 网络中断导致的全量同步开销问题,
- 复制延迟问题及解决方案,
深度分析:
PSYNC命令实现的部分重同步是Redis 2.8后的重要优化,它减少了主从断连后的全量同步开销,但复制积压缓冲区大小设置不当仍可能导致全量同步,建议根据实际情况调整复制积压缓冲区大小,典型值为repl-backlog-size 1gb,
5.2 Redis Sentinel的工作原理和故障转移流程?
关键回答点:
- 主观下线和客观下线判断标准,
- Raft算法在选举哨兵领导者中的应用,
- 新主节点选择策略,
- 客户端如何感知主节点变化,
深度分析:
哨兵模式的配置中,quorum参数至关重要,它决定了判定主节点客观下线需要的哨兵数量,通常建议设置为哨兵总数的一半加一,如三个哨兵设置为2,这样可以在部分哨兵故障时仍能正常工作,另外,parallel-syncs参数控制故障转移时同时进行复制的从节点数量,较大的值可加快故障恢复但会增加主节点负载,
5.3 Redis Cluster的数据分片机制和故障恢复流程?
关键回答点:
- 16384个哈希槽的分配方式,
- MOVED和ASK重定向的区别,
- 集群中的主节点投票机制,
- 集群分裂时的少数派节点自动下线,
深度分析:
Redis Cluster使用哈希槽而非一致性哈希的主要原因是便于管理和迁移,在扩缩容时只需迁移特定范围的槽,而不是重新计算整个哈希环,另外,Redis Cluster默认要求至少有3个主节点才能正常工作,并且当集群中超过半数主节点不可用时,整个集群将不可用,这是为了避免"脑裂"问题,
5.4 如何设计一个支持百万QPS的Redis架构?
关键回答点:
- 合理的数据分片策略,
- 多级缓存架构(本地缓存+Redis),
- 读写分离和热点数据优化,
- 集群监控和自动扩容机制,
深度分析:
百万QPS的Redis架构需要考虑多个维度的优化,首先是硬件层面,要选择高性能的CPU和足够的内存,网络方面使用万兆网卡,其次在架构层面,采用Redis Cluster进行水平扩展,每个节点控制在10GB以内避免内存碎片,同时引入本地缓存如Caffeine减轻Redis压力,最后在应用层面,使用合理的数据结构和批量操作(pipeline)提高吞吐量,
5.5 Redis与数据库双写一致性如何保证?
关键回答点:
- 先更新数据库再删除缓存,
- 延迟双删策略,
- 消息队列保证最终一致性,
- 分布式锁控制并发更新,
深度分析:
双写一致性没有银弹,每种方案都有其适用场景,对于强一致性要求高的业务,可以使用分布式锁保证更新的原子性,但会牺牲性能,对于可以接受短时间不一致的业务,延迟双删是比较好的折中方案,具体做法是先删除缓存,再更新数据库,再延迟一段时间(通常是业务读写锁的最大持有时间)后再次删除缓存,
/**
* Redis与数据库双写一致性解决方案 - 延迟双删
*/
@Service
public class DelayDoubleDeleteService {
private final RedisTemplate<String, Object> redisTemplate;
private final UserRepository userRepository;
private final ThreadPoolExecutor delayDeleteExecutor;
public DelayDoubleDeleteService(RedisTemplate<String, Object> redisTemplate,
UserRepository userRepository) {
this.redisTemplate = redisTemplate;
this.userRepository = userRepository;
// 创建延迟删除的线程池
this.delayDeleteExecutor = new ThreadPoolExecutor(
5, 10, 60, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1000),
new ThreadFactoryBuilder().setNameFormat("delay-delete-pool-%d").build(),
new ThreadPoolExecutor.CallerRunsPolicy()
);
}
/**
* 更新用户信息(延迟双删策略)
*/
@Transactional
public void updateUser(User user) {
String cacheKey = "user:" + user.getId();
// 1. 先删除缓存
redisTemplate.delete(cacheKey);
// 2. 再更新数据库
userRepository.save(user);
// 3. 延迟再次删除缓存
delayDeleteExecutor.execute(() -> {
try {
// 延迟500ms再次删除
Thread.sleep(500);
redisTemplate.delete(cacheKey);
logger.info("延迟删除缓存成功, key={}", cacheKey);
} catch (Exception e) {
logger.error("延迟删除缓存失败", e);
}
});
}
/**
* 使用消息队列保证最终一致性
*/
@Transactional
public void updateUserWithMQ(User user) {
// 1. 更新数据库
userRepository.save(user);
// 2. 发送消息到MQ
CacheInvalidateMessage message = new CacheInvalidateMessage();
message.setType("user");
message.setId(user.getId());
message.setTimestamp(System.currentTimeMillis());
// 使用可靠消息投递,确保消息一定会被处理
reliableMessageSender.sendMessage("cache_invalidate", message);
}
/**
* 使用分布式锁保证强一致性
*/
public void updateUserWithLock(User user) {
String lockKey = "lock:user:" + user.getId();
String cacheKey = "user:" + user.getId();
// 获取分布式锁,30秒超时
boolean locked = redisTemplate.opsForValue().setIfAbsent(lockKey, "LOCKED", 30, TimeUnit.SECONDS);
if (!locked) {
throw new RuntimeException("获取锁失败,请稍后重试");
}
try {
// 1. 更新数据库
userRepository.save(user);
// 2. 删除缓存
redisTemplate.delete(cacheKey);
} finally {
// 3. 释放锁
redisTemplate.delete(lockKey);
}
}
/**
* 基于版本号的缓存更新策略
*/
public void updateUserWithVersion(User user) {
String cacheKey = "user:" + user.getId();
String versionKey = "user:version:" + user.getId();
// 1. 更新数据库并获取新版本号
userRepository.save(user);
long newVersion = userRepository.getLatestVersion(user.getId());
// 2. 原子更新缓存版本号,并获取旧版本号
Long oldVersion = redisTemplate.opsForValue().getAndSet(versionKey, newVersion);
// 3. 如果缓存中的版本号小于当前版本号,更新缓存
if (oldVersion == null || oldVersion < newVersion) {
redisTemplate.opsForValue().set(cacheKey, user);
logger.info("缓存已更新,key={}, version={}", cacheKey, newVersion);
} else {
logger.info("无需更新缓存,当前版本较旧,key={}, oldVersion={}, newVersion={}",
cacheKey, oldVersion, newVersion);
}
}
}
六,总结与最佳实践
Redis分布式高可用架构是一个复杂而精彩的话题,我们从不同角度进行了详细的剖析,最后总结几点实践经验:
-
架构选择:
- 小型应用:主从复制足够,
- 中型应用:哨兵模式保证高可用,
- 大型应用:Redis Cluster实现分片扩展,
- 超大型应用:多数据中心部署,
-
性能优化:
- 合理使用数据结构和命令,
- 避免使用O(N)复杂度的命令,
- 使用pipeline批量操作减少网络开销,
- 控制单个实例内存在10GB以内,
-
监控告警:
- 内存使用率、连接数等基础指标,
- 慢查询、大key监控,
- 主从复制延迟监控,
- 积极响应并处理告警,
-
运维管理:
- 自动化部署和配置管理,
- 定期数据备份和恢复演练,
- 灰度发布和回滚机制,
- 定期安全审计和更新,
Redis的高可用架构就像一座冰山,表面上看起来简单,但内部蕴含着丰富的技术细节和设计思想,作为架构师,我们需要深入理解这些原理,才能在实际工作中设计出稳定可靠的系统,希望本文能够帮助你更深入地理解Redis分布式高可用架构,从入门到精通,逐步掌握这一技术栈,
最后,让我们记住一句话,高可用不是一个目标,而是一个持续优化的过程,只有不断学习和实践,才能设计出真正稳定可靠的系统架构。


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











