









作为一名经历过无数次深夜排查ES集群问题的架构师,不得不说,ElasticSearch就像一把双刃剑,用得好它能让你的搜索体验飞起,用不好就是一场灾难。
今天和大家从零开始,揭开ES的神秘面纱,一步步掌握这个强大的分布式搜索引擎。
一、ElasticSearch是什么
ElasticSearch(简称ES)是一个基于Lucene的开源分布式搜索引擎,它可以近乎实时地存储,检索数据。扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
最初接触ES时,我只把它当作一个搜索工具,直到我用它构建了一个日志分析平台,才真正体会到它的强大,ES不仅仅是搜索引擎,更是一个分析引擎。
ES的特点可以概括为以下几点:
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 分布式的实时分析搜索引擎
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据
- 全文检索,同时还支持复杂的数据分析
二、基本概念
在深入了解ES架构之前,我们需要了解一些基本概念,这些概念构成了ES的基础。
2.1 与关系型数据库的对比
为了让新人更好理解,我们先来看看ES与传统关系型数据库的对比:
| 关系型数据库 | ElasticSearch |
|---|---|
| 数据库(Database) | 索引(Index) |
| 表(Table) | 类型(Type) (ES 7.0后废弃) |
| 行(Row) | 文档(Document) |
| 列(Column) | 字段(Field) |
| 模式(Schema) | 映射(Mapping) |
| SQL | DSL查询 |
2.2 核心概念解析
集群(Cluster):一个集群由一个或多个节点组成,它们共同持有你的整个数据,并提供跨所有节点的联合索引和搜索功能,一个集群由一个唯一的名字标识。
节点(Node):一个节点是一个单独的服务器,作为集群的一部分,存储数据,参与集群的索引和搜索功能,节点也由一个名字来标识。
索引(Index):索引是一些具有相似特征的文档的集合,类似于传统关系数据库中的数据库,一个索引由一个名字标识。
类型(Type):在7.0之前,一个索引可以有多个类型,类似于数据库中的表,7.0之后已废弃该概念。
文档(Document):文档是可被索引的基础信息单元,以JSON格式表示,每个文档都有一个ID。
分片(Shard):因为索引可以存储大量数据,这些数据可能超出单个节点的硬件限制,ES提供了将索引细分为分片的能力,每个分片都是一个功能齐全的独立的"索引"。
副本(Replica):为了防止硬件故障导致的数据丢失,ES允许你创建一个或多个分片的副本,副本可以提供搜索性能和容错功能。
三、架构设计
3.1 集群架构
ES的集群架构是它能够提供高可用性和高扩展性的基础,一个ES集群中包含多个节点,每个节点可以扮演不同的角色。
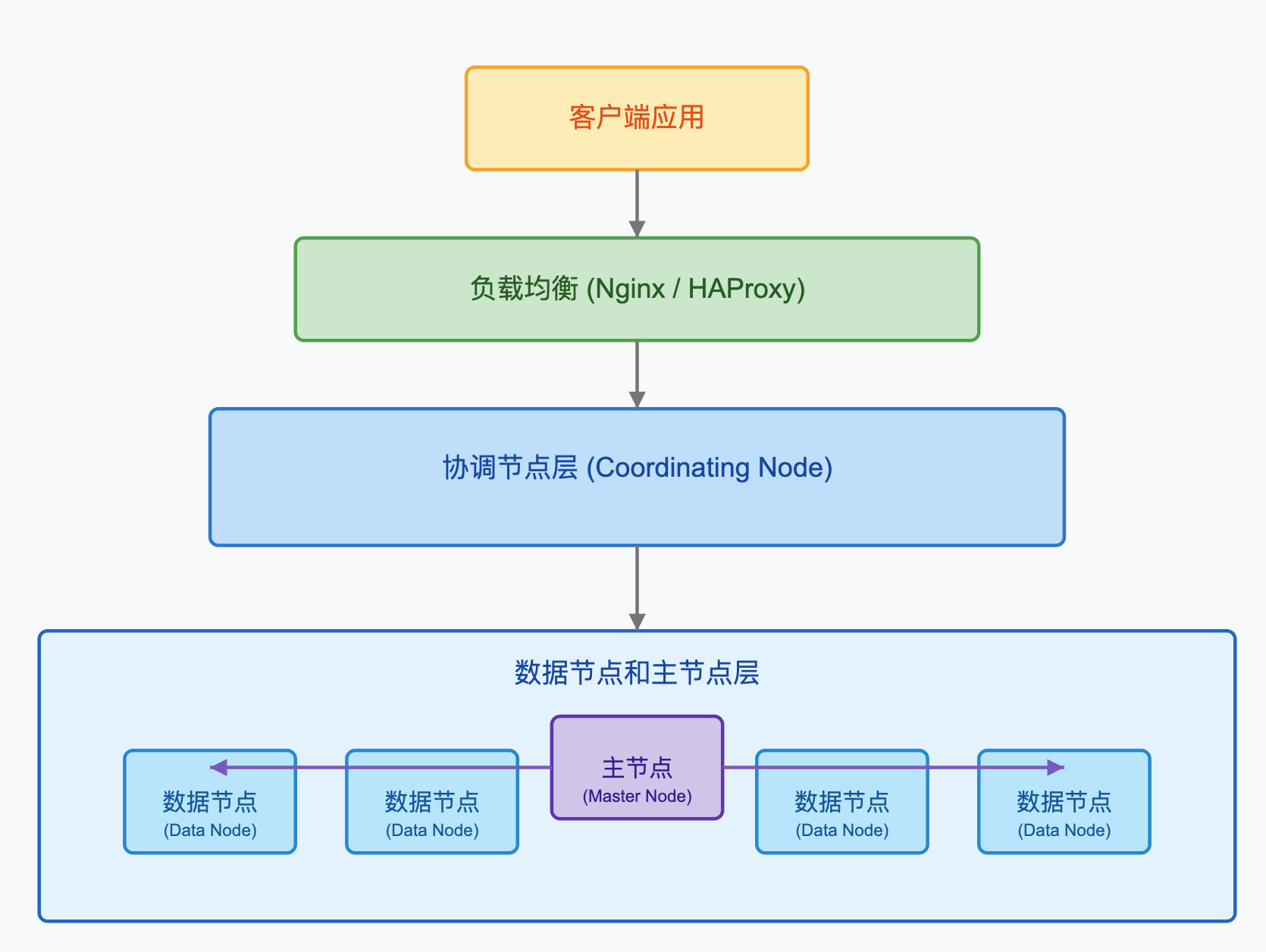
3.1.1 节点类型
在ES集群中,节点根据其配置和用途可以分为以下几种类型:
- 主节点(Master Node):负责轻量级集群管理操作,如创建或删除索引,跟踪集群中的节点,以及决定将分片分配给哪个节点。
- 数据节点(Data Node):存储数据并执行数据相关操作,如CRUD,搜索和聚合。
- 协调节点(Coordinating Node):将请求路由到正确的节点,例如,将批量索引请求路由到数据节点。
- 摄取节点(Ingest Node):对文档进行预处理操作,构成一个摄取管道。
- 机器学习节点(ML Node):专门用于机器学习任务。
3.1.2 集群角色选举
主节点的选举是通过一种名为Zen Discovery的机制完成的,在ES 7.0之后,使用了新的基于Raft算法的集群协调层。
主节点选举过程:
- 每个节点启动时,会尝试加入集群
- 如果是第一个节点,它将自动成为主节点
- 如果集群已经存在,它将尝试联系现有的主节点
- 如果现有主节点不可用,符合主节点资格的节点将通过投票选举新的主节点
这里有个常见的问题是脑裂(Split-Brain),即由于网络问题,集群分裂成两部分,各自认为对方已经下线,进而各自选出自己的主节点。ES通过设置最小主节点数(minimum_master_nodes)解决这个问题(在7.0之后通过discovery.zen.minimum_master_nodes参数设置)。
3.2 索引与分片
索引是ES存储数据的逻辑单元,而分片是物理存储单元。一个索引可以包含多个分片,这些分片分布在集群中的不同节点上。
3.2.1 分片的工作原理
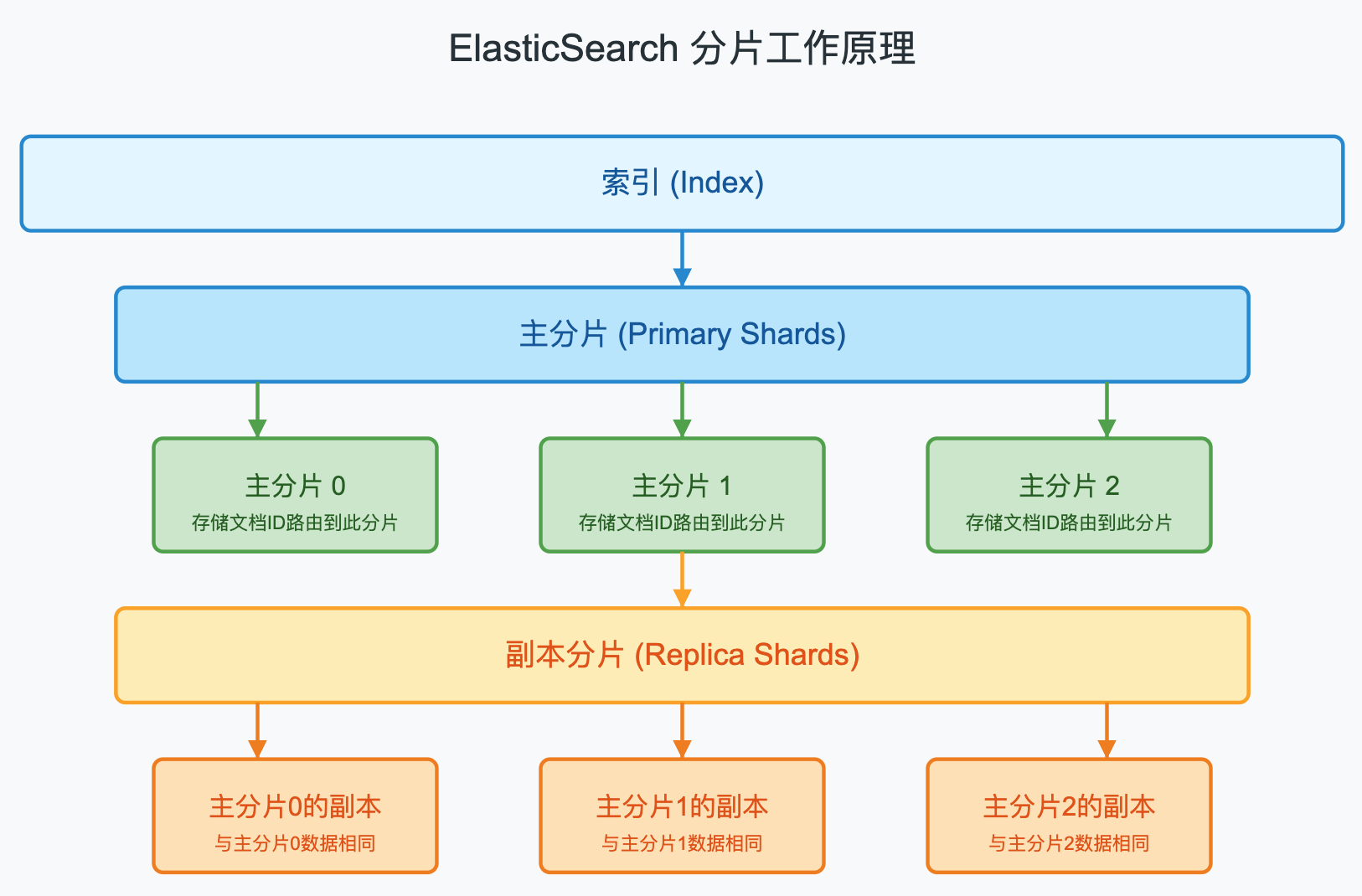
在ES中,当创建索引时,需要指定分片数量,默认情况下一个索引有5个主分片。分片数量是在索引创建时确定的,一旦创建,无法更改,只能通过重建索引的方式进行修改。
每个分片都是一个完整的Lucene索引实例,包含了一部分数据。ES通过分片实现数据的分布式存储,提高系统的吞吐量和可用性。
分片路由的过程如下:
shard_num = hash(routing_key) % num_primary_shards
其中,routing_key默认是文档的ID,也可以自定义;num_primary_shards是主分片的数量。通过这个公式,ES可以确定一个文档应该存储在哪个分片上。
3.2.2 副本分片的作用
副本分片是主分片的完整拷贝,它们有两个主要作用:
- 提高系统的容错性:如果某个节点失效,导致上面的主分片丢失,副本分片可以提升为主分片,保证数据不丢失。
- 提高系统的查询性能:查询请求可以由主分片或副本分片处理,从而提高系统的查询性能。
需要注意的是,副本分片不会和主分片存在于同一个节点上,这是为了防止单点故障。
3.3 文档索引过程
当我们向ES索引一个文档时,整个过程如下:
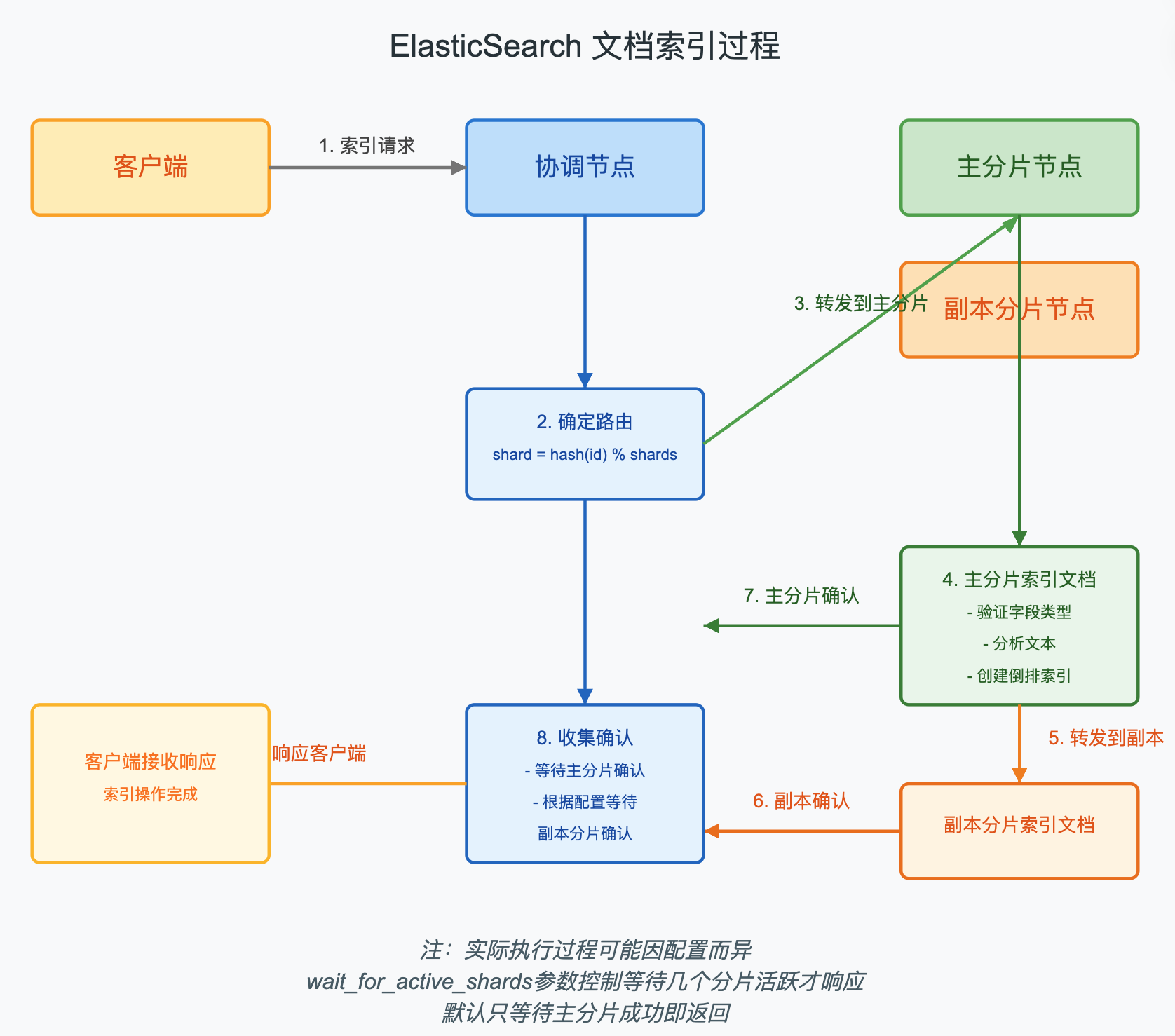
- 客户端发送索引请求到集群中的一个节点(协调节点)
- 协调节点根据文档ID确定文档应该存储到哪个分片上
- 协调节点将请求转发到主分片所在的节点
- 主分片节点执行索引操作,成功后将索引操作转发到副本分片
- 所有副本分片成功后,主分片向协调节点报告成功,协调节点向客户端报告成功
下面是客户端索引文档的一段示例代码:
// 使用JavaScript的elasticsearch客户端库
const { Client } = require('@elastic/elasticsearch');
// 创建客户端实例,连接ES集群
const client = new Client({
node: 'http://localhost:9200',
// 如果有多个节点,可以指定多个
// nodes: ['http://localhost:9200', 'http://localhost:9201']
});
async function indexDocument() {
try {
// 索引一个文档
const response = await client.index({
index: 'products', // 索引名称
id: '1', // 文档ID,可以不指定,ES会自动生成
document: { // 文档内容
name: 'iPhone 13',
category: 'Electronics',
price: 799,
description: 'The latest iPhone with advanced features',
tags: ['smartphone', 'apple', 'ios'],
in_stock: true,
created_at: new Date()
},
refresh: true // 可选,使文档立即可搜索
});
console.log('索引操作成功:', response);
// 可以设置索引参数来控制写入一致性
const responseWithParams = await client.index({
index: 'products',
id: '2',
document: {
name: 'Samsung Galaxy S21',
category: 'Electronics',
price: 699,
description: 'High-end Android smartphone',
tags: ['smartphone', 'samsung', 'android'],
in_stock: true,
created_at: new Date()
},
// 索引参数
refresh: 'wait_for', // 等待刷新后才返回
timeout: '1m', // 操作超时时间
wait_for_active_shards: 'all', // 等待所有活跃分片确认
op_type: 'create' // 操作类型:创建,如果文档已存在则失败
});
console.log('索引操作成功(带参数):', responseWithParams);
} catch (error) {
console.error('索引操作失败:', error);
}
}
// 批量索引文档示例
async function bulkIndex() {
const operations = [];
// 为1000个文档准备批量操作
for (let i = 1; i <= 1000; i++) {
// 每个文档需要两个对象:操作描述和文档本身
operations.push(
// 操作描述
{ index: { _index: 'products', _id: `bulk-${i}` } },
// 文档内容
{
name: `Product ${i}`,
price: Math.floor(Math.random() * 100) + 1,
in_stock: Math.random() > 0.2, // 80%几率为true
created_at: new Date()
}
);
}
try {
// 执行批量操作
const response = await client.bulk({
operations,
refresh: true
});
console.log(`批量索引完成。成功: ${response.items.filter(item => !item.index.error).length}, 失败: ${response.items.filter(item => !!item.index.error).length}`);
// 检查是否有错误
if (response.errors) {
const failedItems = response.items.filter(item => !!item.index.error);
console.error('部分文档索引失败:', failedItems);
}
} catch (error) {
console.error('批量索引操作失败:', error);
}
}
// 执行索引操作
indexDocument().then(() => {
console.log('单文档索引示例完成');
return bulkIndex();
}).then(() => {
console.log('批量索引示例完成');
}).catch(err => {
console.error('操作出错:', err);
});
3.4 文档搜索过程
搜索是ES最核心的功能,当我们发起一个搜索请求时,整个过程如下:
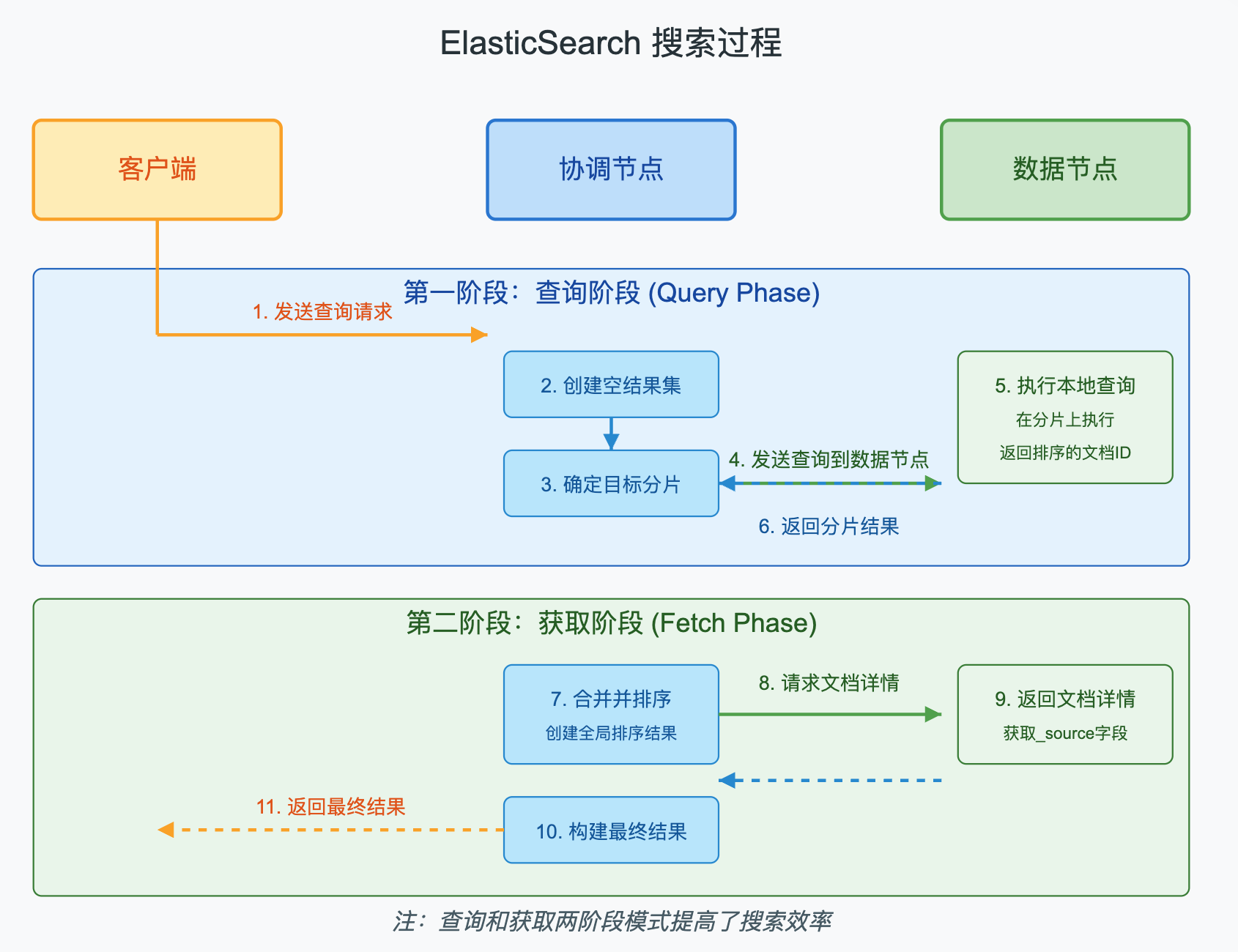
ElasticSearch的搜索过程分为两个阶段:查询阶段和获取阶段。
-
查询阶段:
- 客户端发送搜索请求到协调节点
- 协调节点创建一个空的优先队列,用于存储排序后的文档
- 协调节点确定要查询的分片,并向相关数据节点发送查询请求
- 每个数据节点在本地执行查询,并返回一个包含文档ID和排序值的轻量级结果集
-
获取阶段:
- 协调节点合并所有分片的结果,并根据指定的排序条件对文档进行排序
- 协调节点向相关数据节点请求详细的文档内容
- 数据节点返回文档详情
- 协调节点构建最终的搜索结果,并返回给客户端
下面是一个搜索的示例代码:
// 使用JavaScript的elasticsearch客户端库
const { Client } = require('@elastic/elasticsearch');
// 创建客户端实例
const client = new Client({
node: 'http://localhost:9200'
});
async function searchProducts() {
try {
// 基本搜索
const basicResponse = await client.search({
index: 'products',
query: {
match: {
description: 'smartphone'
}
}
});
console.log('基本搜索结果:', {
total: basicResponse.hits.total,
hits: basicResponse.hits.hits.map(hit => ({
id: hit._id,
score: hit._score,
name: hit._source.name
}))
});
// 复杂搜索示例
const complexResponse = await client.search({
index: 'products',
// 分页
from: 0,
size: 20,
// 超时设置
timeout: '5s',
// 查询部分
query: {
bool: {
must: [
{ match: { category: 'Electronics' } }
],
should: [
{ match: { description: 'premium' } },
{ match: { name: 'pro' } }
],
must_not: [
{ range: { price: { gt: 1000 } } }
],
filter: [
{ term: { in_stock: true } },
{ range: { price: { gte: 500, lte: 900 } } }
]
}
},
// 排序
sort: [
{ price: { order: 'desc' } },
'_score'
],
// 返回特定字段
_source: ['name', 'price', 'category', 'description'],
// 高亮
highlight: {
fields: {
description: {}
}
},
// 聚合
aggs: {
price_ranges: {
range: {
field: 'price',
ranges: [
{ to: 600 },
{ from: 600, to: 800 },
{ from: 800 }
]
}
},
avg_price: {
avg: {
field: 'price'
}
},
categories: {
terms: {
field: 'category.keyword',
size: 10
}
}
}
});
console.log('复杂搜索结果:');
console.log('文档总数:', complexResponse.hits.total);
console.log('最高得分:', complexResponse.hits.max_score);
// 处理命中结果
const hits = complexResponse.hits.hits.map(hit => ({
id: hit._id,
score: hit._score,
name: hit._source.name,
price: hit._source.price,
category: hit._source.category,
description: hit._source.description,
highlight: hit.highlight
}));
console.log('命中结果:', hits);
// 处理聚合结果
console.log('价格区间分布:', complexResponse.aggregations.price_ranges.buckets);
console.log('平均价格:', complexResponse.aggregations.avg_price.value);
console.log('类别分布:', complexResponse.aggregations.categories.buckets);
// 使用Search After进行深度分页
if (hits.length > 0) {
const lastHit = hits[hits.length - 1];
const searchAfterResponse = await client.search({
index: 'products',
size: 20,
query: {
bool: {
must: [
{ match: { category: 'Electronics' } }
]
}
},
sort: [
{ price: { order: 'desc' } },
{ _id: 'asc' } // 第二个排序字段必须是唯一的
],
search_after: [lastHit._source.price, lastHit._id] // 使用上一批次最后一个文档的排序值
});
console.log('下一页结果:', searchAfterResponse.hits.hits.map(hit => ({
id: hit._id,
price: hit._source.price,
name: hit._source.name
})));
}
} catch (error) {
console.error('搜索操作失败:', error);
}
}
// 执行搜索
searchProducts().then(() => {
console.log('搜索示例完成');
}).catch(err => {
console.error('操作出错:', err);
});
3.5 ES写入原理与倒排索引
ElasticSearch的核心是基于Lucene构建的倒排索引,它是ES高效搜索的基础。
3.5.1 倒排索引结构
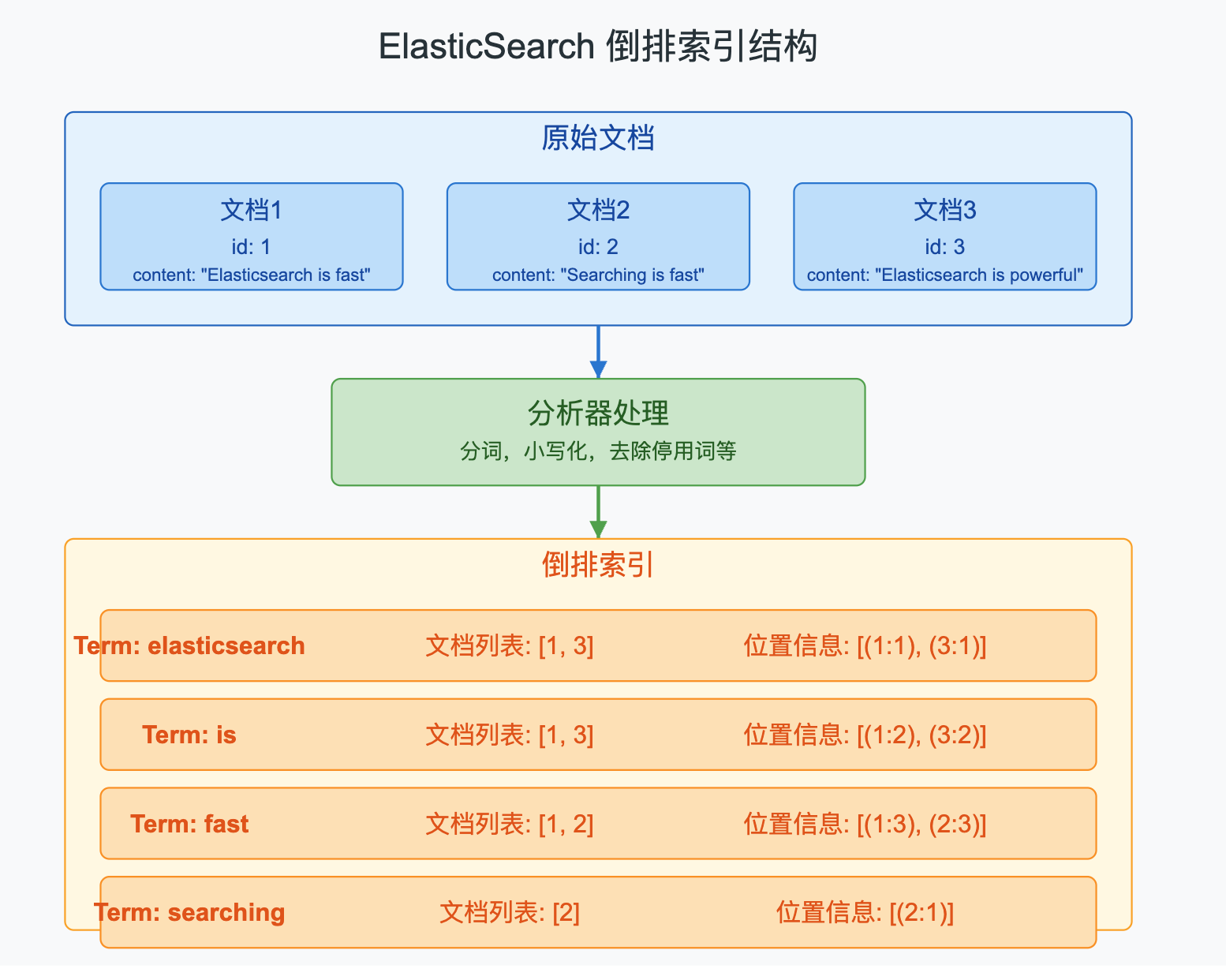
传统的正向索引是以文档为中心,找到文档后再找到关键字。而倒排索引是以关键字为中心,找到关键字后再找到对应的文档。
倒排索引主要包含以下几个部分:
- Term Dictionary:存储所有文档分词后的词项,以及它们的统计信息
- Posting List:存储单词出现的文档ID列表
- Position Information:记录单词在每个文档中的位置
- Term Frequency:记录单词在文档中出现的次数
倒排索引的优点是可以快速地进行全文检索,通过词项直接找到文档,但缺点是占用空间较大,且不适合频繁更新。
3.5.2 文档写入流程
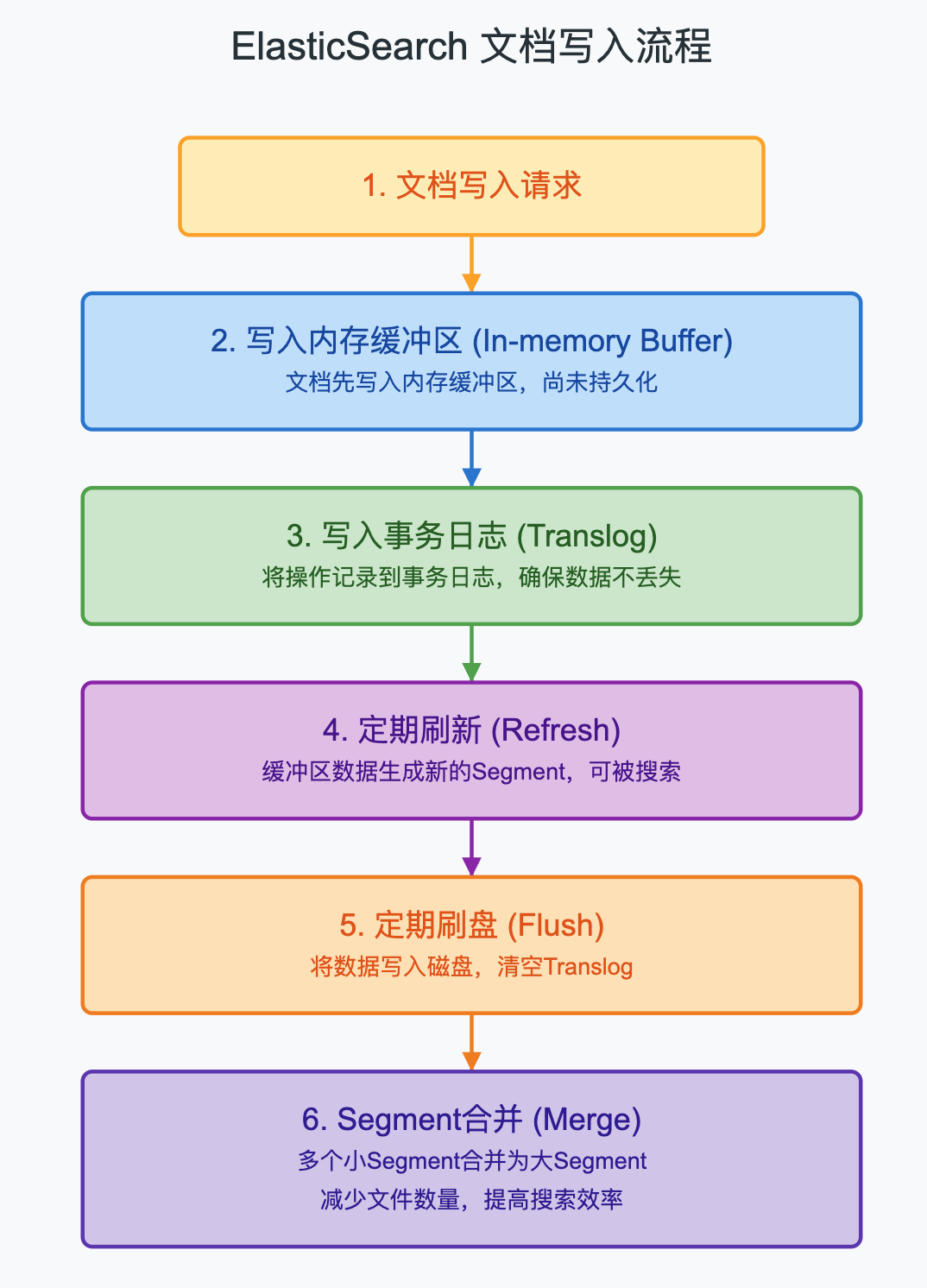
ElasticSearch的文档写入流程是保证数据持久性和搜索性能的关键,它主要包含以下几个步骤:
- 内存缓冲区:当文档被索引时,首先被写入内存缓冲区。
- Translog:同时写入事务日志,以防内存数据丢失。
- Refresh:定期(默认每1秒)将内存缓冲区的数据写入一个新的Segment,使其对搜索可见,但此时还未真正持久化到磁盘。
- Flush:定期(默认每30分钟或当Translog过大时)将缓存的数据写入磁盘,并清空Translog。
- Merge:随着时间推移,Segment会越来越多,ES会在后台自动合并多个小的Segment为一个大的Segment,提高搜索效率。
ES采用这种写入方式是为了平衡写入性能和搜索性能,让新写入的文档能够尽快被搜索到,同时通过批量处理和后台合并提高整体性能。
四、高级特性
4.1 集群扩展与水平分片
当单个节点无法处理所有数据时,ElasticSearch可以通过水平扩展来增加集群的处理能力。
水平扩展的两种方式:
- 增加分片数量:在创建索引时指定更多的分片,使数据分布在更多的物理存储单元上。
- 增加节点数量:向集群添加更多的节点,ES会自动将分片分配到新节点上。
需要注意的是,分片数量是在索引创建时确定的,后期无法修改。因此在设计索引时,需要考虑未来的数据增长。
4.2 分片分配与平衡
ES集群会自动管理分片的分配,以确保数据均匀分布在各个节点上,这个过程称为分片平衡。
分片分配策略包括:
- 均衡分配:尽量使每个节点上的分片数量相同
- 感知分配:考虑节点的物理位置,如机架、可用区等
- 基于磁盘的分配:考虑节点的磁盘使用情况
- 强制分配:通过设置包含或排除规则,强制将分片分配到特定节点
4.3 集群状态与健康
ES集群的健康状态可以分为三种:
- 绿色(Green):所有主分片和副本分片都已分配,集群功能完全正常
- 黄色(Yellow):所有主分片已分配,但部分副本分片未分配,集群功能正常但容错能力降低
- 红色(Red):部分主分片未分配,集群部分功能不可用
集群健康状态是运维中需要重点关注的指标,可以通过以下命令查看:
GET _cluster/health
4.4 Query DSL与聚合分析
ElasticSearch提供了强大的Query DSL(Domain Specific Language)来进行复杂的搜索操作,以及丰富的聚合功能来进行数据分析。
4.4.1 Query DSL
Query DSL是一种基于JSON的查询语言,可以构建复杂的查询,主要分为两种类型:
- 叶子查询子句(Leaf Query Clauses):如match、term、range等,用于查找特定字段中的特定值
- 复合查询子句(Compound Query Clauses):如bool、dis_max等,用于组合多个叶子查询子句
// 基本匹配查询
GET products/_search
{
"query": {
"match": {
"description": "smartphone"
}
}
}
// 精确匹配查询(不分词)
GET products/_search
{
"query": {
"term": {
"category.keyword": "Electronics"
}
}
}
// 范围查询
GET products/_search
{
"query": {
"range": {
"price": {
"gte": 500,
"lte": 1000
}
}
}
}
// 布尔组合查询
GET products/_search
{
"query": {
"bool": {
"must": [
{ "match": { "category": "Electronics" } }
],
"should": [
{ "match": { "description": "premium" } },
{ "match": { "name": "pro" } }
],
"must_not": [
{ "range": { "price": { "gt": 1000 } } }
],
"filter": [
{ "term": { "in_stock": true } }
]
}
}
}
// 多字段查询
GET products/_search
{
"query": {
"multi_match": {
"query": "apple",
"fields": ["name", "description", "tags"]
}
}
}
// 复杂组合查询示例
GET products/_search
{
"size": 20,
"query": {
"bool": {
"must": [
{
"match": {
"description": {
"query": "smartphone high quality",
"operator": "and"
}
}
}
],
"should": [
{
"match_phrase": {
"name": "iPhone Pro"
}
},
{
"term": {
"tags.keyword": {
"value": "flagship",
"boost": 2.0
}
}
}
],
"filter": [
{
"range": {
"release_date": {
"gte": "now-1y"
}
}
},
{
"range": {
"price": {
"gte": 700,
"lte": 1200
}
}
},
{
"term": {
"in_stock": true
}
}
]
}
},
"sort": [
{
"_score": {
"order": "desc"
}
},
{
"price": {
"order": "asc"
}
}
],
"highlight": {
"fields": {
"description": {},
"name": {}
},
"pre_tags": ["<em>"],
"post_tags": ["</em>"]
}
}
4.4.2 聚合分析
ES的聚合功能允许我们基于搜索结果进行统计分析,主要分为四种类型:
- 桶聚合(Bucket Aggregations):如terms、date_histogram等,将文档分组
- 指标聚合(Metric Aggregations):如avg、max、min等,计算统计值
- 管道聚合(Pipeline Aggregations):如derivative、moving_avg等,基于其他聚合结果计算
- 矩阵聚合(Matrix Aggregations):如matrix_stats等,计算多字段之间的统计信息
// 简单统计聚合
GET products/_search
{
"size": 0,
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
},
"max_price": {
"max": {
"field": "price"
}
},
"min_price": {
"min": {
"field": "price"
}
}
}
}
// 分组聚合
GET products/_search
{
"size": 0,
"aggs": {
"categories": {
"terms": {
"field": "category.keyword",
"size": 10
}
}
}
}
// 嵌套聚合
GET products/_search
{
"size": 0,
"aggs": {
"categories": {
"terms": {
"field": "category.keyword",
"size": 10
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
},
"price_ranges": {
"range": {
"field": "price",
"ranges": [
{ "to": 500 },
{ "from": 500, "to": 1000 },
{ "from": 1000 }
]
}
}
}
}
}
}
// 日期直方图
GET products/_search
{
"size": 0,
"aggs": {
"sales_over_time": {
"date_histogram": {
"field": "created_at",
"calendar_interval": "month"
},
"aggs": {
"total_sales": {
"sum": {
"field": "price"
}
},
"sales_count": {
"value_count": {
"field": "price"
}
}
}
}
}
}
// 复杂聚合示例 - 销售分析
GET products/_search
{
"size": 0,
"query": {
"bool": {
"filter": [
{
"range": {
"created_at": {
"gte": "now-1y",
"lte": "now"
}
}
}
]
}
},
"aggs": {
"sales_by_category": {
"terms": {
"field": "category.keyword",
"size": 5,
"order": {
"total_revenue": "desc"
}
},
"aggs": {
"total_revenue": {
"sum": {
"field": "price"
}
},
"monthly_sales": {
"date_histogram": {
"field": "created_at",
"calendar_interval": "month"
},
"aggs": {
"revenue": {
"sum": {
"field": "price"
}
},
"cumulative_revenue": {
"cumulative_sum": {
"buckets_path": "revenue"
}
},
"moving_avg_monthly": {
"moving_avg": {
"buckets_path": "revenue",
"window": 3
}
}
}
},
"top_products": {
"top_hits": {
"size": 3,
"sort": [
{
"price": {
"order": "desc"
}
}
],
"_source": {
"includes": ["name", "price", "description"]
}
}
}
}
}
}
}
4.5 性能优化与调优
随着业务的发展,ES集群的性能优化变得尤为重要。以下是一些常见的优化方向:
4.5.1 索引优化
- 合理设置分片数量:分片数量过多会导致小文件过多,过少则无法充分利用集群资源
- 选择合适的分片路由:默认的分片路由是基于文档ID的,可以根据业务特点自定义路由字段
- 定义合适的映射:为字段设置正确的类型,使用适当的分析器
4.5.2 查询优化
- 使用Filter Context:filter不会计算相关性得分,性能更好
- 避免使用通配符前缀查询:如
"query": "abc*"会导致全表扫描 - 使用Search After代替深度分页:深度分页会消耗大量内存
4.5.3 系统配置优化
- JVM堆大小设置:建议设置为物理内存的50%,不超过32GB
- 禁用Swapping:ES对内存要求高,Swapping会严重影响性能
- 文件描述符:ES需要大量的文件描述符,确保系统限制足够高
4.5.4 硬件选择
- 使用SSD:相比HDD,SSD能显著提升随机IO性能
- 增加内存:给文件系统缓存预留足够的内存
- 多核CPU:ES是多线程应用,能够充分利用多核资源
五、实际应用案例
5.1 日志分析平台
ElasticSearch + Logstash + Kibana (ELK Stack) 是最常见的日志分析解决方案。
- Logstash:收集、处理和转发日志
- ElasticSearch:存储和索引日志数据
- Kibana:可视化和分析日志
日志分析平台的优势在于它能处理大规模的日志数据,并提供近实时的搜索和分析能力。
5.2 全文搜索引擎
作为一个搜索引擎,ES可以为网站、电商平台等提供全文搜索功能。
- 相关性排序:根据TF-IDF或BM25算法计算文档得分
- 分词和同义词:通过分析器和同义词词典提供更智能的搜索
- 搜索建议:通过completion suggester提供自动完成功能
5.3 实时数据分析
ES不仅是搜索引擎,也是强大的分析工具。
- 业务指标监控:如电商平台的销售额、用户增长等
- 异常检测:基于机器学习功能,检测时序数据中的异常
- 地理位置分析:使用ES的地理位置功能,进行位置相关的分析
六、常见面试问题
6.1 ES与传统关系型数据库的区别
- 存储方式:ES是基于文档的,关系型数据库是基于表的
- 查询语法:ES使用DSL,关系型数据库使用SQL
- 事务支持:ES不支持ACID事务,关系型数据库支持
- 扩展性:ES易于水平扩展,关系型数据库通常倾向于垂直扩展
- 实时性:ES接近实时,默认1秒可见
6.2 ES的写入原理
ES的写入过程包括:
- 先写入内存buffer,此时数据不可搜索
- 同时将操作记录写入translog
- refresh操作将buffer中的数据写入segment,此时数据可搜索
- flush操作将数据持久化到磁盘,并清空translog
6.3 ES的脑裂问题及解决方案
脑裂是指集群中出现多个主节点的情况,通常由网络问题引起。解决方案包括:
- 设置最小主节点数:ES 7.0前通过
discovery.zen.minimum_master_nodes设置 - 使用Zen2和Raft:ES 7.0后引入了新的集群协调机制
- 合理配置网络:确保节点间网络稳定性
6.4 ES如何优化查询性能
- 使用Filter替代Query:Filter不计算相关性得分,有缓存
- 避免使用Script:Script会显著影响性能
- 字段预处理:如使用keyword类型存储不需要分词的字段
- 使用索引别名:通过别名实现零停机重建索引
6.5 ES的GC优化
ES是Java应用,GC优化非常重要:
- 合理设置堆内存:一般不超过32GB
- 使用G1GC:ES 7.0后默认使用G1垃圾收集器
- 监控GC情况:通过监控工具关注GC频率和时间
七、总结一下
ElasticSearch作为一个分布式搜索和分析引擎,具有高扩展性、高可用性和近实时性的特点。它的核心架构包括集群、节点、索引、分片等组件,通过分布式存储和计算实现了大规模数据的处理能力。
随着大数据和AI时代的到来,ElasticSearch也在不断发展,未来的发展方向包括:
- 更深入的机器学习集成:提供更智能的异常检测、预测分析等功能
- 向矢量检索发展:支持基于向量的相似性搜索,更好地支持AI应用
- 性能与扩展性提升:降低资源消耗,提高处理能力,支持更大规模的数据
作为架构师,需要深入理解ES的工作原理,根据业务特点合理设计索引结构和查询方式,才能充分发挥ElasticSearch的强大能力。希望这篇文章能对你了解ElasticSearch的架构有所帮助。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











