







初识Kafka,分布式消息引擎的基石
大家好,今天咱们来聊聊Kafka这个在分布式系统中举足轻重的消息中间件,作为一位奋战多年的架构师,我依然记得第一次接触Kafka时那种既兴奋又头疼的感觉,它就像一把双刃剑,用好了它能让系统如虎添翼,用不好就是灾难的开始,
Kafka最初由LinkedIn开发,后来成为Apache顶级项目,它是一个分布式的,可水平扩展的,高吞吐量的消息引擎系统,简单地说就是一个超级强大的消息队列,但它的能力远不止于此,
Kafka的核心概念
先来熟悉几个基础概念,这些是理解Kafka的钥匙,
- Topic:主题,Kafka中消息的逻辑分类,就像是专门的信箱,
- Partition:分区,每个Topic可以有多个分区,实现并行处理,
- Producer:生产者,负责发送消息到Kafka集群,
- Consumer:消费者,从Kafka集群拉取消息并处理,
- Broker:Kafka服务器,存储消息的地方,
- Consumer Group:消费者组,共同消费Topic中的消息,
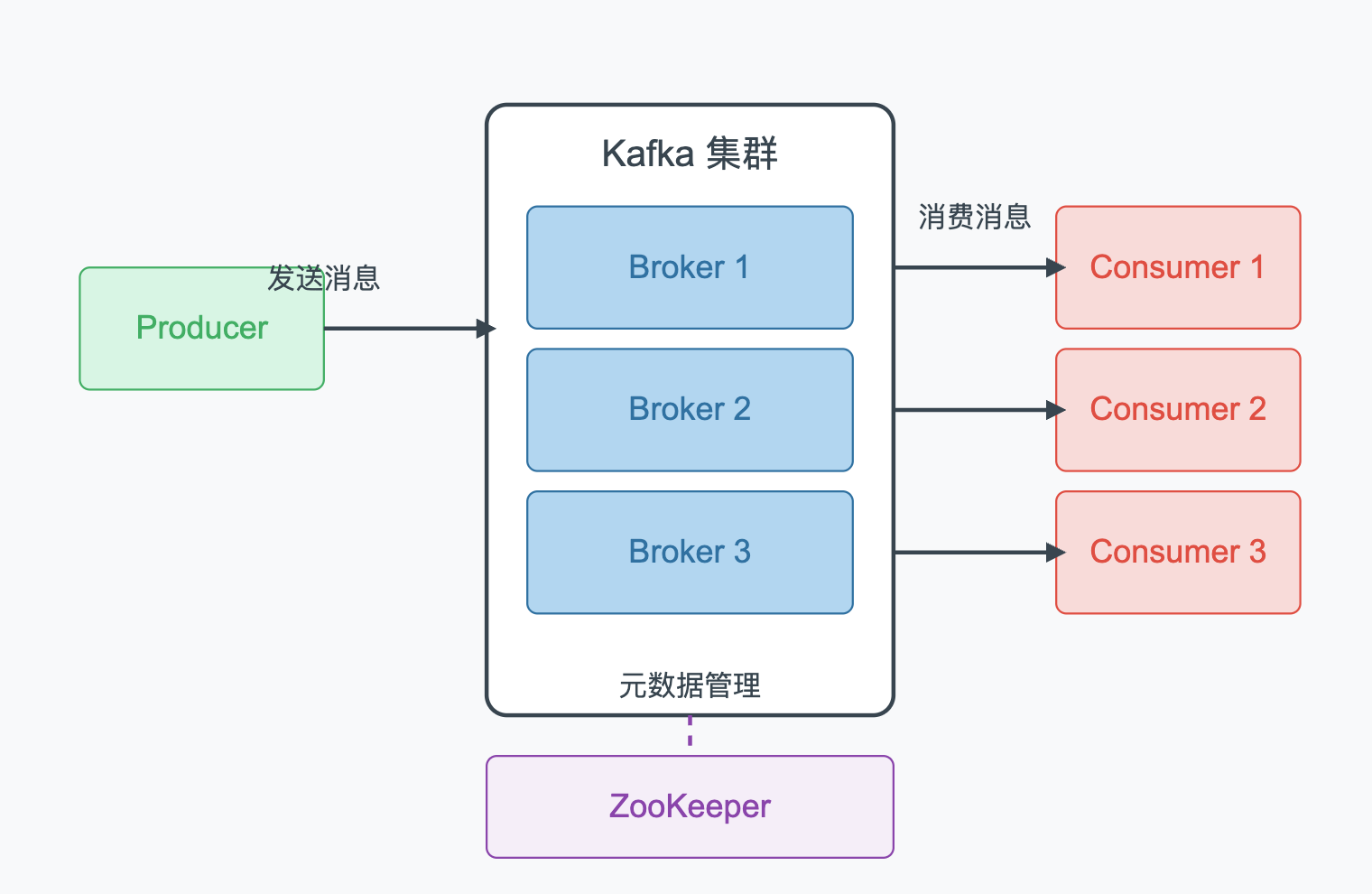
上图展示了Kafka的基本架构,生产者发送消息到Kafka集群的Broker中,消费者从Broker拉取消息进行处理,ZooKeeper(在新版本中逐渐被KRaft替代)负责管理集群元数据,
Kafka的实际应用场景
说了这么多概念,Kafka到底能用来干什么呢,作为一位曾经被Kafka救过无数次的架构师,我给大家分享几个常见场景,
- 日志收集:集中收集应用系统的日志,方便分析和处理,
- 消息系统:解耦生产者和消费者,实现异步通信,
- 用户活动跟踪:记录用户行为数据,用于分析和个性化推荐,
- 流式处理:结合Spark或Flink等框架进行实时数据分析,
- 事件溯源:记录所有状态变更事件,用于系统恢复和审计,
曾经我负责的一个电商项目,用户下单峰值达到每秒数千单,如果没有Kafka作为缓冲,数据库早就被打垮了,Kafka就像是系统的"减震器",让高峰期的流量平稳地分散到低峰期处理,
Kafka核心原理解析
消息存储机制
Kafka的高性能得益于其独特的存储设计,它采用了分区日志的方式存储消息,每个分区都是一个有序的不可变的消息序列,

新消息总是追加到分区的末尾,这种追加写入的方式使得Kafka能够实现高吞吐量,因为顺序写入磁盘比随机写入快很多,每个Partition还会分成多个Segment(段),便于数据管理和清理,
消息存储的代码实现关键部分如下,
// Log.scala (简化版)
def append(records: MemoryRecords, assignOffsets: Boolean): LogAppendInfo = {
// 验证消息记录
val appendInfo = analyzeAndValidateRecords(records)
// 如果需要分配偏移量
if (assignOffsets) {
// 分配消息偏移量
val offset = nextOffsetMetadata.messageOffset
appendInfo.firstOffset = Some(offset)
appendInfo.lastOffset = offset + records.records.asScala.size - 1
// 更新消息中的偏移量
records.batches().forEach(batch => {
batch.setLastOffset(appendInfo.lastOffset)
batch.setPartitionLeaderEpoch(leaderEpoch)
})
}
// 写入消息到活跃段
segment.append(appendInfo.firstOffset, appendInfo.maxTimestamp,
appendInfo.offsetOfMaxTimestamp, records)
// 更新日志末尾信息
updateLogEndOffset(appendInfo.lastOffset + 1)
// 如果需要,创建新的日志段
maybeRoll(segment)
// 返回追加信息
appendInfo
}
// LogSegment.scala (简化版)
def append(offset: Long, timestamp: Long, timestampOffset: Long, records: MemoryRecords): Unit = {
if (records.sizeInBytes > 0) {
// 追加到日志文件
val appendedBytes = log.append(records)
// 更新索引
if (bytesSinceLastIndexEntry > indexIntervalBytes) {
offsetIndex.append(offset, log.sizeInBytes)
timeIndex.append(timestamp, timestampOffset)
bytesSinceLastIndexEntry = 0
}
// 增加计数器
bytesSinceLastIndexEntry += records.sizeInBytes
}
}
从代码中可以看到,Kafka在处理消息追加时主要进行了以下操作:验证消息,分配偏移量,写入日志段,更新索引,这种简单高效的设计是Kafka高性能的关键所在,
分区副本机制
Kafka通过副本机制来保证数据的可靠性,每个分区可以有多个副本,分布在不同的Broker上,
- Leader副本:处理所有读写请求,
- Follower副本:只从Leader复制数据,不处理客户端请求,
- ISR(In-Sync Replicas):与Leader保持同步的副本集合,
这种机制保证了即使某个Broker宕机,数据依然可用,我曾经见过凌晨3点集群一台机器突然宕机,但系统没有任何影响,领导都不知道出过问题,这就是高可用架构的魅力,
消费者模型
Kafka的消费模型与传统消息队列有显著不同,
- 拉模式(Pull):消费者主动从Broker拉取消息,而不是Broker推送,
- 消费者组:同一组内的消费者共同消费一个Topic的消息,每个分区只能被组内一个消费者消费,
- 位移管理:消费者自己管理消费位移(offset),可以从任意位置开始消费,
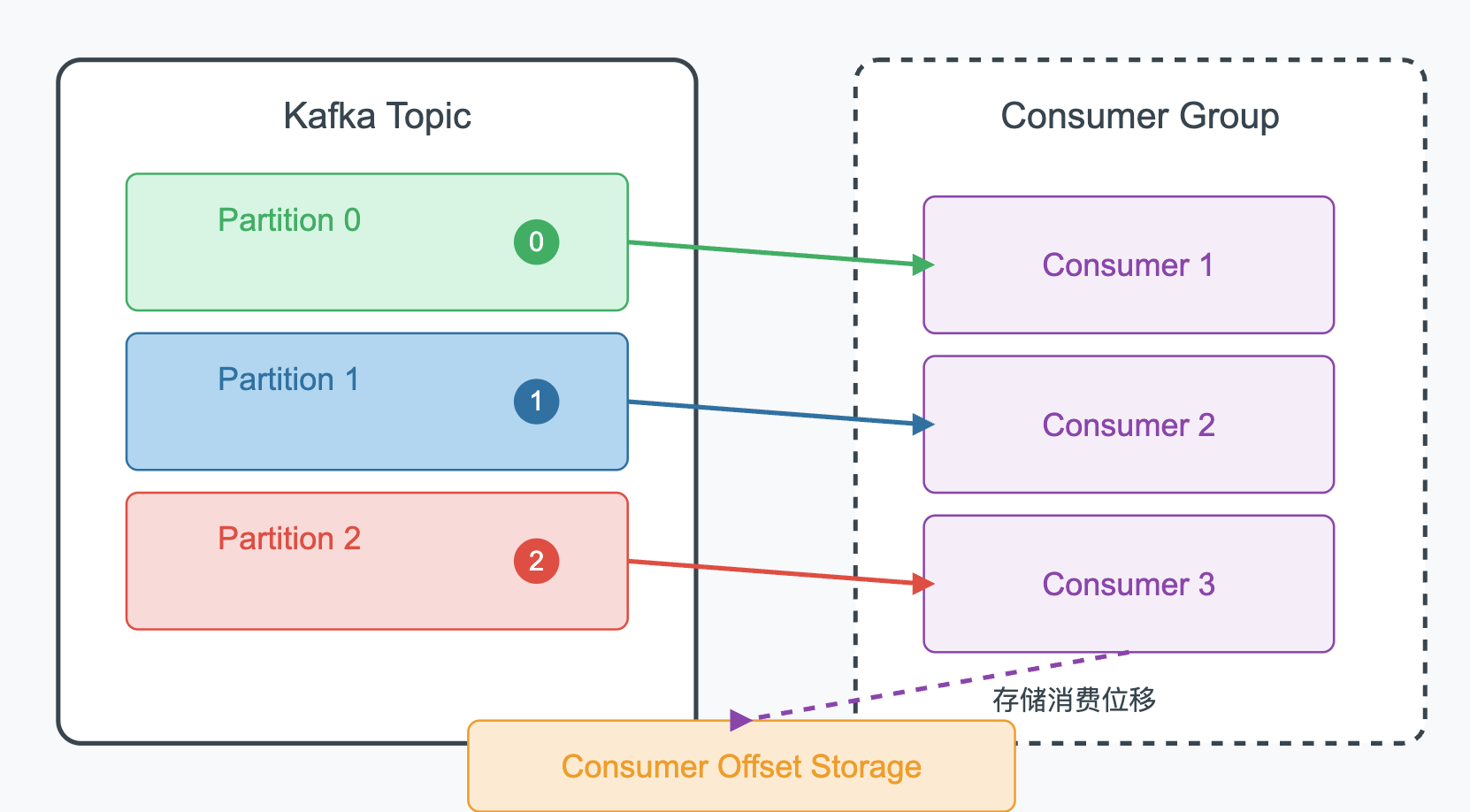
消费者组的设计让Kafka能够实现高并发消费,同时保证消息的顺序性,位移管理的灵活性也让系统具备了重播数据的能力,这对于数据修正和系统恢复非常重要,
Kafka最新架构发展
KRaft模式:告别ZooKeeper
在早期版本中,Kafka依赖ZooKeeper管理集群元数据,但从2.8版本开始,Kafka引入了KRaft(Kafka Raft)模式,使用自己的共识协议,不再依赖ZooKeeper,
这一变化带来了几个重要好处:
- 简化架构:减少了部署和维护的复杂度,
- 提高性能:减少了元数据操作的延迟,
- 增强扩展性:支持更多的分区和更大的集群,
使用KRaft模式的配置示例:
# KRaft模式服务器配置
process.roles=broker,controller
node.id=1
controller.quorum.voters=1@localhost:9093,2@localhost:9094,3@localhost:9095
listeners=PLAINTEXT://localhost:9092,CONTROLLER://localhost:9093
inter.broker.listener.name=PLAINTEXT
controller.listener.names=CONTROLLER
listener.security.protocol.map=PLAINTEXT:PLAINTEXT,CONTROLLER:PLAINTEXT
advertised.listeners=PLAINTEXT://localhost:9092
# 日志目录
log.dirs=/tmp/kraft-combined-logs
# 其他常规配置
num.partitions=3
default.replication.factor=3
min.insync.replicas=2
auto.create.topics.enable=false
在一个项目中,我们从ZooKeeper模式迁移到KRaft模式后,元数据操作的延迟降低了约30%,系统稳定性也有了明显提升,
Tiered Storage:分层存储
Kafka 3.0引入了分层存储功能,可以将不同时期的数据存储在不同的存储介质上,热数据保存在性能较高的存储上,冷数据则可以转移到成本较低的存储中,
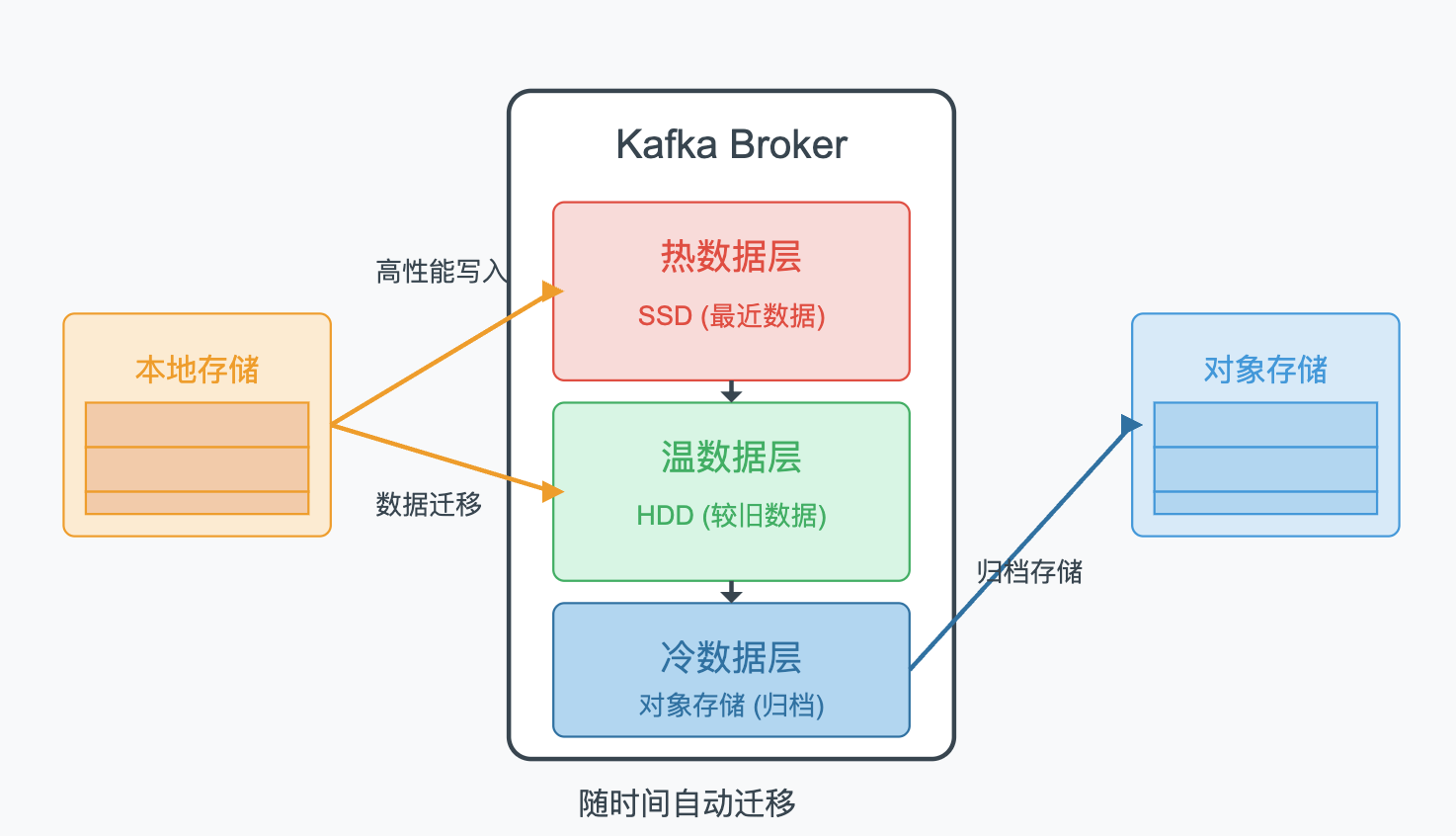
分层存储是Kafka架构发展的重要突破,它解决了长期以来数据存储成本与性能的矛盾,对于需要长期保留数据的企业尤其有价值,我参与的一个金融项目将冷数据迁移到对象存储后,存储成本降低了近70%,而且不影响数据的可访问性,
消费者重平衡优化
在最新版本中,Kafka对消费者组的重平衡机制做了重大改进,引入了增量式重平衡(Incremental Rebalance)策略,
// 消费者配置示例
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "my-group");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 关键配置:设置分区分配策略为协作式粘性策略
props.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,
CooperativeStickyAssignor.class.getName());
// 设置会话超时时间
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "30000");
// 设置心跳间隔
props.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, "10000");
// 设置最大轮询间隔
props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, "300000");
// 创建消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 订阅主题
consumer.subscribe(Collections.singletonList("my-topic"));
// 消费消息
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n",
record.offset(), record.key(), record.value());
}
// 手动提交偏移量
consumer.commitAsync();
}
传统的重平衡会导致所有消费者暂停消费,而增量式重平衡只影响需要迁移的分区,大大减少了重平衡对系统的影响,我曾经调试过一个消费者组重平衡问题,原来每次重平衡都会导致整个系统暂停处理几秒钟,切换到增量式重平衡后,这个问题基本消失了,
事务支持强化
Kafka在最新版本中强化了事务支持,实现了端到端的消息处理语义保证,包括:
- 精确一次(Exactly Once)语义:确保消息不会重复处理,
- 跨分区原子写入:多个分区的写入要么全部成功,要么全部失败,
- 生产者幂等性:避免网络重试导致的重复消息,
// 创建具有事务功能的生产者
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 开启事务必须设置事务ID
props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "my-transactional-id");
// 启用幂等性
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true");
// 创建生产者
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// 初始化事务
producer.initTransactions();
try {
// 开始事务
producer.beginTransaction();
// 发送多条消息
producer.send(new ProducerRecord<>("topic1", "key1", "value1"));
producer.send(new ProducerRecord<>("topic2", "key2", "value2"));
// 处理消费者偏移量(消费-处理-生产模式)
Map<TopicPartition, OffsetAndMetadata> offsets = new HashMap<>();
offsets.put(new TopicPartition("source-topic", 0), new OffsetAndMetadata(100));
producer.sendOffsetsToTransaction(offsets, "consumer-group-id");
// 提交事务
producer.commitTransaction();
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {
// 不可恢复的错误,关闭生产者
producer.close();
} catch (KafkaException e) {
// 可恢复的错误,中止事务
producer.abortTransaction();
}
这些特性对于金融、支付等要求数据一致性的领域尤为重要,在实际项目中,我们利用Kafka事务特性实现了跨系统的数据一致性,极大提升了系统的可靠性,
Kafka性能调优秘籍
多年实战经验告诉我,Kafka的性能调优主要从以下几个方面入手:
1. Broker配置优化
# 增加网络线程数
num.network.threads=8
# 增加IO线程数
num.io.threads=16
# 发送缓冲区大小
socket.send.buffer.bytes=1048576
# 接收缓冲区大小
socket.receive.buffer.bytes=1048576
# 请求最大字节数
socket.request.max.bytes=104857600
2. Topic配置优化
# 根据业务需求设置合适的分区数
num.partitions=12
# 根据数据规模设置日志段大小
log.segment.bytes=1073741824
# 数据保留时间
log.retention.hours=168
# 消息压缩类型
compression.type=lz4
3. 生产者优化
# 批量大小
batch.size=16384
# 批处理延迟
linger.ms=5
# 缓冲区大小
buffer.memory=33554432
# 压缩类型
compression.type=lz4
# 确认机制
acks=1
4. 消费者优化
# 单次拉取消息的最大数量
max.poll.records=500
# 自动提交间隔
auto.commit.interval.ms=5000
# 拉取消息的最大字节数
fetch.max.bytes=52428800
曾经我通过调整这些参数,将一个处理能力只有每秒5000条消息的系统提升到每秒50000条,提升了整整10倍,关键是理解你的业务场景和数据特点,不能盲目照搬参数,
Kafka面试热点解析
作为一名面试官,我经常问到以下Kafka相关问题,希望能帮助大家在面试中脱颖而出,
1. Kafka如何保证消息不丢失
从三个环节保证:
- 生产者:使用acks=all和重试机制,确保消息成功写入,
- Broker:设置适当的复制因子和最小同步副本数量,
- 消费者:关闭自动提交,手动控制偏移量提交时机,
2. Kafka为什么这么快
- 顺序写入:利用磁盘顺序IO的高性能特性,
- 零拷贝:直接从文件系统缓存到网络通道,减少数据复制,
- 批处理:合并小消息为大批次,提高传输效率,
- 压缩:减少网络传输和存储开销,
- 分区并行:多分区并行处理,提高吞吐量,
3. Rebalance机制是什么
消费者组成员变化或分区数量变化时,Kafka会自动调整分区的所有权,将分区重新分配给组内消费者,确保负载均衡,最新的协作式重平衡让这个过程更加平滑,
4. 消费者位移存储在哪里
在早期版本中,位移存储在ZooKeeper中,现在统一存储在内部的名为__consumer_offsets的主题中,以key-value形式保存,
结语
Kafka的发展历程告诉我们,优秀的架构设计必定是简单且高效的,从最初的消息队列到如今的事件流平台,Kafka始终保持着其设计哲学,简单,高性能,可扩展,
在实际工作中,不仅要掌握Kafka的使用方法,更要理解其设计思想,只有这样才能在合适的场景选择合适的技术解决方案,
希望这篇文章能帮助你更好地理解和应用Kafka,
技术没有终点,让我们一起在学习的路上前行。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











