




大模型学习 (Datawhale_Happy-LLM)笔记
任务2:第一章 NLP 基础概念
1. 什么是 NLP
NLP (Natural Language Processing)自然语言处理的核心意义在于让计算机理解人类语言,解读语言背后蕴含的深层含义,让人机进行更丝滑的交互。例如让手机语音助手听懂你的指令,或让翻译软件把中文转成英文。
随着 Deep learning 等技术的发展 NLP 虽已取得了显著进步,但诸多挑战亟待解决(如处理复杂场景下的语言歧义、理解抽象概念、处理隐喻和讽刺、伦理争议以及多模态数据的处理与解读等。)
2. NLP的发展历程:从“规则基础”到“智能学习”
2.1 早期(1940-1960年代):1950 年,Alan Turing (图灵)发表《计算机器与智能》,提出 “图灵测试” 的概念,首次提出机器具备思维的可能性,成为人工智能领域的重要基石。Noam Chomsky (诺姆·乔姆斯基)提出了生成语法理论。(Generative Grammar)生成语法的形式化方法(如递归规则、形式语言理论)为计算机语言处理、编译原理和自然语言理解提供了理论基础。例如,编译器的语法分析算法借鉴了他的句法理论。
2.2 统计方法(1970-1990年代):符号主义(规则基础)和统计方法两派。随着算法算力的提升,统计方法逐步取代复杂手写规则。
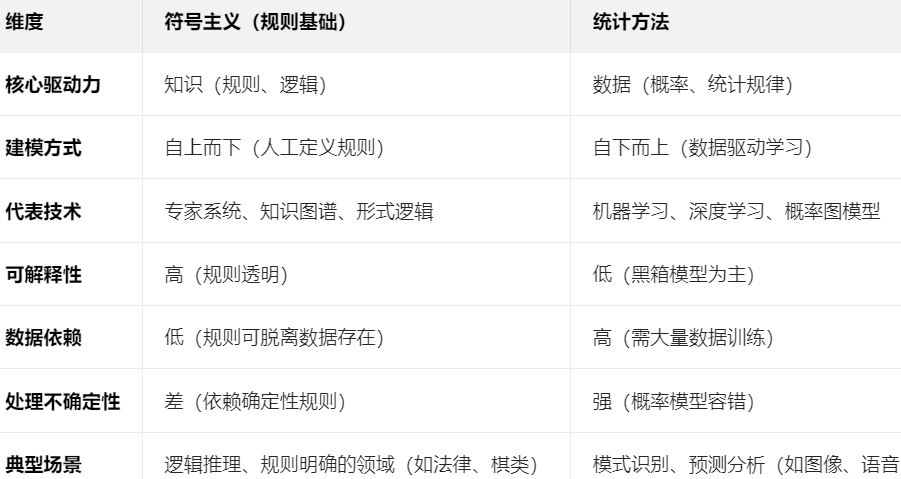
2.3 机器学习(2000年代至今):
- 深度学习技术(RNN, LSTM)与注意力机制等应用使 NLP 取得了显著进步
- Wo
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 513
513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









