



1.字典 用于储存键值对
- 键(Key):必须是不可变类型(如字符串、整数、元组等),且唯一。
- 值(Value):可以是任意数据类型(如字符串、数字、列表,甚至是另一个字典)。
遍历字典的键
my_dict = {"name": "Alice", "age": 30, "city": "New York"}
print("\n--- 遍历字典的键 ---")
for key in my_dict:
print(key)
遍历字典的值
print("\n--- 遍历字典的值 ---")
for value in my_dict.values():
print(value)值就是Alice 30 和New York 相对应
2.标签编码
之前提到离散数据 如果是不存在顺序,则采用独热编码,函数为pd.get_dummies()。
那么存在大小和顺序的离散特征则采用标签编码
import pandas as pd
data = pd.read_csv('data.csv')
data.head()
data["Home Ownership"].value_counts()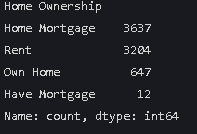
按照贷款严重程度来进行标签编码 这里也可以用独热编码
即自有房小于租房小于有其他贷款小于有房贷
mapping = {
"Own Home": 0,
"Rent": 1,
"Have Mortgage ": 2,
"Home Mortgage": 3
}
data["Home Ownership"].head()二分类问题的标签编码
mapping = {
"Short Term": 1,
"Long Term": 0
}
data["Term"] = data["Term"].map(mapping)
data["Term"].head()同时对两个特征进行标签编码 做一个嵌套
import pandas as pd
data = pd.read_csv("data.csv")
mapping = {
"Term": {
"Short Term": 1,
"Long Term": 0
},
"Home Ownership": {
"Rent": 0,
"Own Home": 1,
"Have Mortgage ": 2,
"Home Mortgage": 3
}
}
3.对annual income做归一化处理
def manual_normalize(data):
min_val = data.min()
max_val = data.max()
normalized_data = (data - min_val) / (max_val - min_val)
return normalized_data
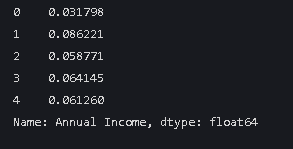
data['Annual Income'] = manual_normalize(data['Annual Income'])
data['Annual Income'].head()前面几行是函数的内容 最后打印数值归一化后的效果
标准化处理
data = pd.read_csv("data\data.csv")
scaler = StandardScaler() # 函数
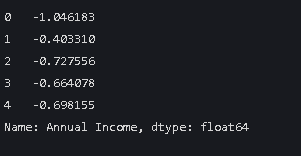
data['Annual Income'] = scaler.fit_transform(data[['Annual Income']])
data['Annual Income'].head()
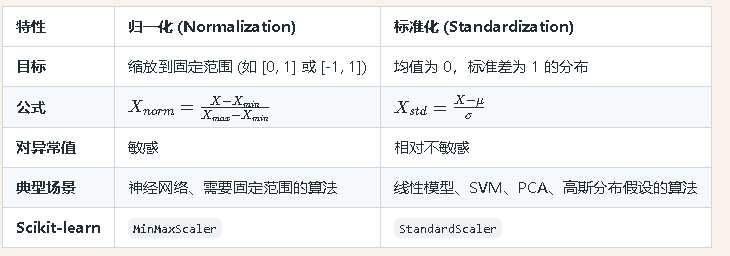
两者的差别
继续完成对心脏病数据集的预处理
import pandas as pd
data = pd.read_csv('heart.csv')
from sklearn.preprocessing import MinMaxScaler, StandardScaler
# 归一化
min_max_scaler = MinMaxScaler()
data["age"] = min_max_scaler.fit_transform(data[["age"]])
data["trestbps"] = min_max_scaler.fit_transform(data[["trestbps"]])
data["chol"] = min_max_scaler.fit_transform(data[["chol"]])
# 标准化
standard_scaler = StandardScaler()
data["thalach"] = standard_scaler.fit_transform(data[["thalach"]])
data["oldpeak"] = standard_scaler.fit_transform(data[["oldpeak"]])
print(data.head())
















 1068
1068

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









