






 PADA网络作为PartialAdversarialDomainAdaptation的一种实现,通过优化网络架构和损失函数,有效解决了源域和目标域数据类别不完全匹配的问题。相较于SAN网络,PADA网络通过集成域鉴别器和引入γ权重调整,简化了计算复杂度,增强了源域和目标域之间的特征一致性,提高了迁移学习的性能。
PADA网络作为PartialAdversarialDomainAdaptation的一种实现,通过优化网络架构和损失函数,有效解决了源域和目标域数据类别不完全匹配的问题。相较于SAN网络,PADA网络通过集成域鉴别器和引入γ权重调整,简化了计算复杂度,增强了源域和目标域之间的特征一致性,提高了迁移学习的性能。
第二篇:Partial Adversarial Domain Adaptation
这篇文章的设置情境与之前的partial transfer learning的情境一样,都是在目标域数据种类是源域数据种类的子集情况下所进行的一个讨论。解决问题的总思路也是一致的,即通过减小在源域类别而不在目标域数据类别的数据权重而增大既在目标域种类又在源域种类中数据的权重把问题转化为传统迁移学习问题。
首先先看一看这篇文章的网络架构
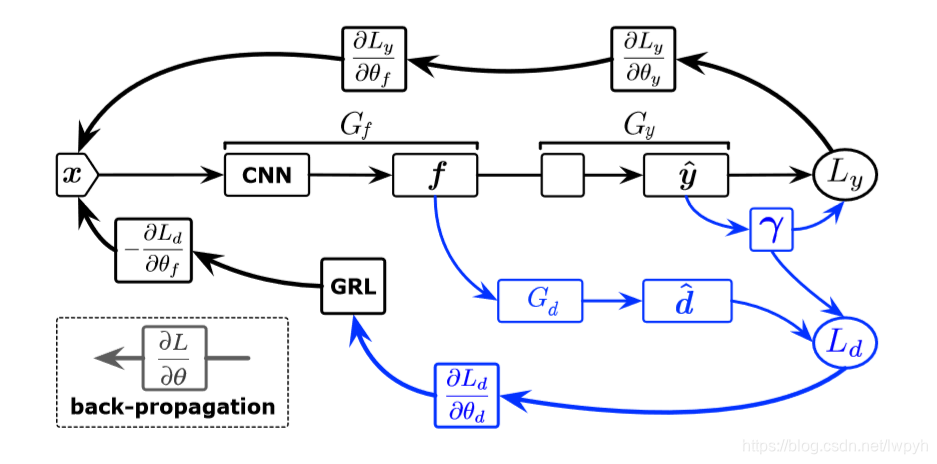 仔细对比一下第一篇文章,不难发现,其实这两篇文章的架构几乎是一样的,均是在DaNN网络的基础上所做的改进工作。先介绍一下架构中各个字母所代表的含义,Gf是特征提取器,Gy是源域分类器,黑色部分就是一个纯粹的源域上的有监督分类问题网络。Gd是一个域鉴别器,主要目的是用来鉴别输入的样本是不是还是在目标域类别里,如果既属于源域类别,又属于目标域类别,其分类权重就变大,反之就变小。D则是获得的域标签的预测结果,γ则代表了类权重平均的标签预测目标数据。Ly是有监督学习的损失函数,Ld则是域分类损失。
仔细对比一下第一篇文章,不难发现,其实这两篇文章的架构几乎是一样的,均是在DaNN网络的基础上所做的改进工作。先介绍一下架构中各个字母所代表的含义,Gf是特征提取器,Gy是源域分类器,黑色部分就是一个纯粹的源域上的有监督分类问题网络。Gd是一个域鉴别器,主要目的是用来鉴别输入的样本是不是还是在目标域类别里,如果既属于源域类别,又属于目标域类别,其分类权重就变大,反之就变小。D则是获得的域标签的预测结果,γ则代表了类权重平均的标签预测目标数据。Ly是有监督学习的损失函数,Ld则是域分类损失。
与上一篇文章的SAN网络做一下比较
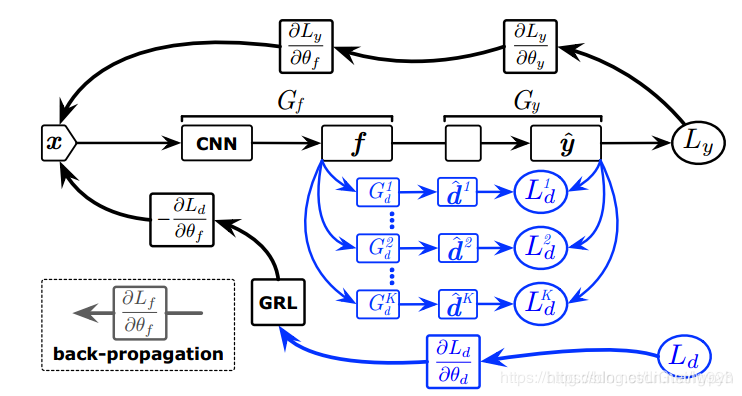 不难发现这篇文章思路与架构几乎和SAN一致,但还是有不同的地方。首先,在SAN网络里使用了多个域鉴别器,源域中有多少个类就有多少个鉴别器,这样就对计算成本产生了很高的要求,比如Imagenet网络到Office31网络做partial transfer learning问题就需要1000个域鉴别器,而这在实际网络设计中并不现实,而且也会造成极大的浪费。而在本文中则是将这k个(k是源域种类个数)全部集成为一个域鉴别器,之前这个域鉴别器输出的是一个数,表示属于这一类的概率值,现在输出的则是一个向量,向量是k维的,每一个维度依次表示这个输入样本属于该类别的可能性,这是PADA网络相较SAN网络一个显著的不同,第二个不同是引入了γ,这个γ是用来干什么的呢?这个在后面解释损失函数时再具体解释。
不难发现这篇文章思路与架构几乎和SAN一致,但还是有不同的地方。首先,在SAN网络里使用了多个域鉴别器,源域中有多少个类就有多少个鉴别器,这样就对计算成本产生了很高的要求,比如Imagenet网络到Office31网络做partial transfer learning问题就需要1000个域鉴别器,而这在实际网络设计中并不现实,而且也会造成极大的浪费。而在本文中则是将这k个(k是源域种类个数)全部集成为一个域鉴别器,之前这个域鉴别器输出的是一个数,表示属于这一类的概率值,现在输出的则是一个向量,向量是k维的,每一个维度依次表示这个输入样本属于该类别的可能性,这是PADA网络相较SAN网络一个显著的不同,第二个不同是引入了γ,这个γ是用来干什么的呢?这个在后面解释损失函数时再具体解释。
下面就PADA网络的损失函数进行具体分析。损失函数表达式是
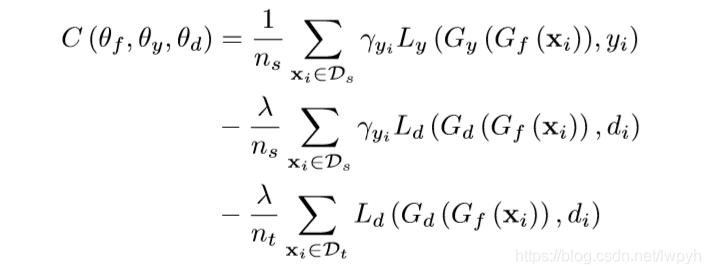 这里第一项是典型的有监督学习的损失函数,但是又加了一个γ,这是为什么呢?首先要明白γ是怎么来的,γ体现的是源域数据的总体分布权重情况。源域分类器对源域分类后,源域数据总体的分布实际上体现了源域中各个类别的分布情况,而不难发现属于源域而不属于目标域类别的分布与既属于源域又属于目标域类别的分布情况应该是有很大不同的,所以实际上把属于后者的误分到前者的可能性是很小的,但是虽然很小并不代表不存在,但是这些极小的误分情况如果置于总体当中再取平均,这种误差就可以忽略不计,这就是γ的作用,γ的表达式如下:
这里第一项是典型的有监督学习的损失函数,但是又加了一个γ,这是为什么呢?首先要明白γ是怎么来的,γ体现的是源域数据的总体分布权重情况。源域分类器对源域分类后,源域数据总体的分布实际上体现了源域中各个类别的分布情况,而不难发现属于源域而不属于目标域类别的分布与既属于源域又属于目标域类别的分布情况应该是有很大不同的,所以实际上把属于后者的误分到前者的可能性是很小的,但是虽然很小并不代表不存在,但是这些极小的误分情况如果置于总体当中再取平均,这种误差就可以忽略不计,这就是γ的作用,γ的表达式如下: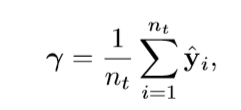 γ是|Cs|维权向量量化每个源类的贡献,换言之,γ表明每个源类对目标域的贡献的权重,即将第一项这个总体损失函数向目标域拉近。
γ是|Cs|维权向量量化每个源类的贡献,换言之,γ表明每个源类对目标域的贡献的权重,即将第一项这个总体损失函数向目标域拉近。
第二项则是DaNN网络的提取域不变特征项的表达式,这里加上了γ也是为了提取域不变特征时可以尽可能的将源域向目标域拉近,拉近的方法就是将属于源域但不属于目标域类的类别权重减小,属于源域和目标域类别的类权重增大。
最后一项就是单纯的提取共同特征,这里由于全是目标域上的数据来做的,所以只需要提取共同特征就好。
这就是PADA网络的总体介绍,相对SAN网络其本质没变,但是相对更加简洁,也相对将两个域之间距离拉的更近了,所以最后结果效果也更好。

















10-11
 1129
1129
1129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









