



 介绍了SelectiveAdversarialNetworks(SAN)如何通过调整源域类别权重解决partialtransferlearning问题,将问题转化为传统迁移学习问题。
介绍了SelectiveAdversarialNetworks(SAN)如何通过调整源域类别权重解决partialtransferlearning问题,将问题转化为传统迁移学习问题。
上一篇文章就说明是迁移学习,以及partial transfer learning问题是什么做了介绍,目前,在partial transfer learning问题上,现在主要有三篇文章,这里分别做介绍,今天先介绍第一篇:
第一篇:Partial Transfer Learning with Selective Adversarial Networks
本文提出了一种叫做SAN(Selective Adversarial Networks)的网络来解决partial transfer learning的问题,这个网络是DaNN网络的基础上做的改良,前文提及DaNN网络在面对partial transfer learning问题时会面临负迁移的问题,该网络做的就是将每一类源域样本均进行分析,通过使既在源域又在目标域中的类别权重变大,只在源域不在目标域中的类别权重变小,来将partial transfer learning问题转化为一个新的传统迁移学习问题。
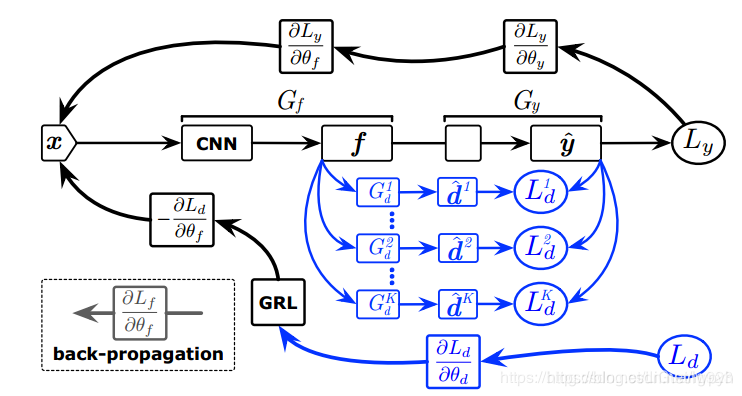
黑色部分是传统的DaNN网络的组成部分,蓝色部分则是SAN所独有的改变源域类别权重的新网络结构。下面对该网络结构进行分析。
Gf是传统的特征提取器,即几个卷积层叠加,获取源域图像的特征向量;G_d^k 表示第k类的类别鉴别器,它的作用是输出一个概率值,表示输入的样本属于该类别的可能性,d^k 表示预测的域标签,这个标签值表示的是该类样本既属于目标域又属于源域的可能性,L_d^k 则表示第k类样本的域判别损失,这个损失函数依然是交叉熵损失函数的形式,但是这里由y与d^k 组成。同时考虑了源域与目标域的特征提取,达到提取共同特征的目的,将会在后面损失函数处进行详细解释,这里y是预测的标签值,当然这个值也是假的,因为softmax函数输出的实际是一种可能性概率值,现在将概率值当做标签值用于损失函数。所以总体思路就是先按照传统DaNN网络来提取源域与目标域的共同特征,同时构建新网络结构对每一类别进行分析,使属于源域但不属于目标域的类别权重变小,既属于目标域又属于源域的类别权重不变,这样将partial transfer learning问题转化为传统迁移学习问题。
损失函数分析:
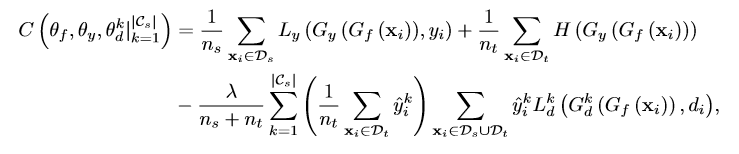
损失函数第一项就是传统的交叉熵损失函数,如果只看这一项的话就相当于是在源域上做有监督学习。第二项是半监督学习里面的一个低密度分离这一概念的损失函数表达式,这一项的作用是将最后分类得到的各个类别之间能够拉的更开,即不同类别数据之间可以分的更开。那么怎么实现分的更开呢?这就通过无监督学习里一个概念熵最小化原理来实现,信息熵可以体现出一段信息的信息量,而熵最小的时候就是最稳定的时候,即各类分的最开,最不易混淆的时候,第三项就是这篇文章的精髓所在,这个就是上文提及的域分类器,这里的损失函数L_d^k仍是交叉熵的形式,前面不同的标签预测值y是个概率值,表示这一类属于源域且属于目标域的可能,,从而各类样本属于异常类的权值低,而属于相关类的权值高。第三项损失的意义是说每个子判别器通过可能性权重来进行有监督优化,同时每个子判别器又通过权值相乘进行结合而成,其中样本属于异常类的权值低,而属于相关类的权值高。而前两项是通过最小化来实现准确,最后一项前面的负号则是因为上面提到的要最小化Gy并最大化Gd。
这就是SAN网络的基本思想。
partial transfer learning文章总结(二)
最新推荐文章于 2025-08-11 18:35:31 发布

















 1129
1129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









