







 本文探讨了深度迁移学习的前沿进展,包括Partial Transfer Learning、Importance Weighted Adversarial Nets和GLoMo等方法,旨在解决源域和目标域标签空间不完全匹配的挑战,通过特征提取、关系图学习等策略提升模型泛化能力。
本文探讨了深度迁移学习的前沿进展,包括Partial Transfer Learning、Importance Weighted Adversarial Nets和GLoMo等方法,旨在解决源域和目标域标签空间不完全匹配的挑战,通过特征提取、关系图学习等策略提升模型泛化能力。
神经网络迁移学习
-
对抗迁移
- Partial Transfer Learning with Selective Adversarial Networks
- 分类:基于样本的迁移学习方法;解决的是在源域的标签空间包含目标域的标签空间情况下,迁移学习的问题,其中目标域无标记数据,源域中有大量的标记数据。
- 方法:利用gan的判别器来选择与目标域样本相近的源域实现迁移
- 数据:
- 网络架构:G_f特征提取(feature extractor)和 G_y标签预测(label predictor).其中G_y包含判别器D
- 流程:源域和目标域的数据经过cnn网络提取特征,判别器该特征是否属于源域还是目标域,与此同时G_y预测数据的标签。
- loss:使得源域分类器错误最小;子判别器对每个类别要判别出该特征是属于源域还是目标域;为了减小子判别器对于样本的依赖所以减小目标域的熵
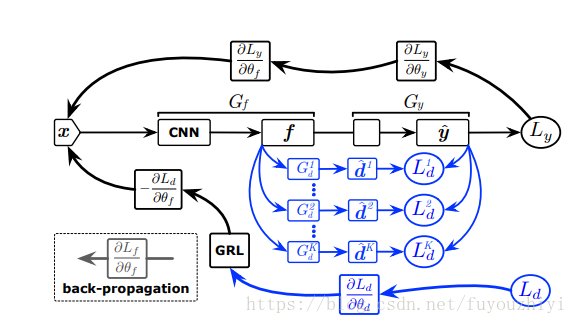
- 训练:通过最小化Loss求出特征提取和标签预测的参数;通过最大化Loss学习判别器的参数
- 论文地址
- 代码
- Importance Weighted Adversarial Nets for Partial Domain Adaptation
- 分类:基于样本的迁移学习方法;解决的是在源域的标签空间包含目标域的标签空间情况下,迁移学习的问题,其中目标域无标记数据,源域中有大量的标记数据。
- 方法:用两个判别器,一个计算权重,一个优化目标域分类器,解决迁移学习中的域漂移
- 数据:
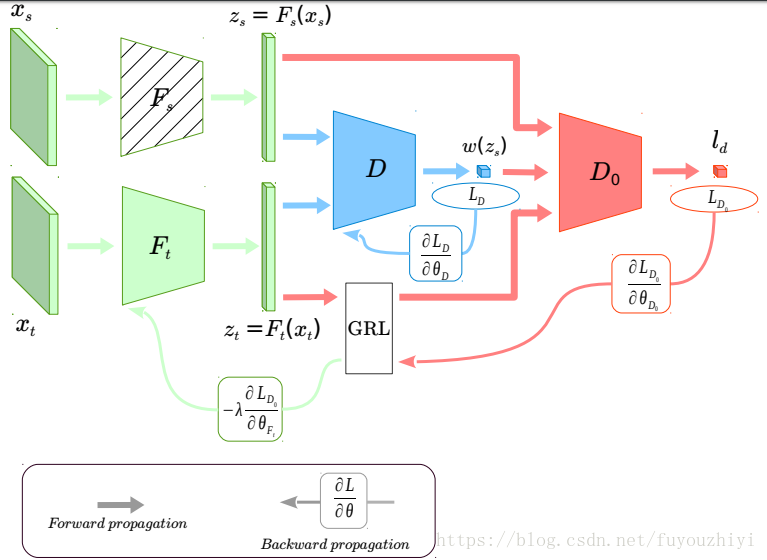
- 首先训练源域分类器:F_s,C.其后的训练源域特征提取器都固定住。
- 同时优化领域判别器D,D_0和目标域特征提取器F_t。其中用源域训练好的特征提取器F_s初始化F_t
- ) 通过固定住的F_s和当前的F_t得到重要权重w
- ) D_0,F_t通过极小极大化博弈学习参数,通过熵最小化学习目标域分类器
- 论文地址
- Partial Transfer Learning with Selective Adversarial Networks
-
深度迁移
- GLoMo: Unsupervisedly Learned Relational Graphs as Transferable Representations
- 分类:无监督迁移学习。(源域和目标域都没有标签);学习一种结构(特征之间的关联矩阵)将它应用到即将要迁移的任务中。
- 方法:用无监督的网络提取特征,并学习特征之间的关系,将这部分知识迁移到另一个任务中。
- 数据::
- 图预测器(graph predictor):输入x,输出图的集合G=f(x)
给定一个x,经过两个CNN网络(key CNN 和 query CNN)提取特征。 key CNN的每一层都输出一列特征(k_1,k_2,…,k_T),query CNN同理输出(q_1,q_2,…,q_T).计算该层特征之间的相关性,输出该层的关联矩阵。 - 特征预测(feature predictor)f:输入x和关联矩阵G,输出每一层的特征,最后一层的特征见下一节。每一层的特征都是通过上一层的特征和该层的图G计算的。其中第一层仅给出x。
- objective function:通过2,得到最终的特征F,将最后一层的特征f_L输入到RNN的decoder中,预测出x_t。
- loss:在objective function上,最大化条件概率分布。
在无监督学习阶段,特征预测器和图形预测器被一起训练以执行上下文预测。在迁移阶段,图形预测器被冻结并用于提取下游任务的图形。RNN 解码器应用于特征预测器中的所有位置,但是简单起见,我们仅指出了位置「A」处的一个。「Select one」表示图形可以迁移到下游任务模型中的任何层。「FF」指前馈网络。图形预测器输出的图用作「weighted sum」操作中的权重
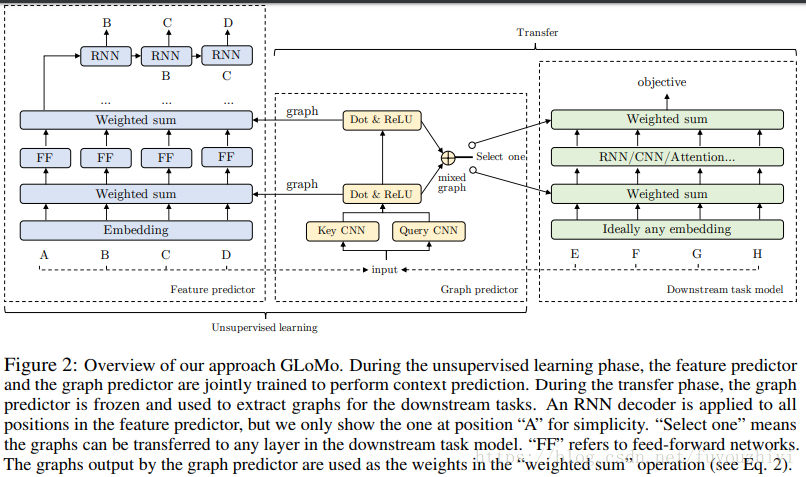
- 图预测器(graph predictor):输入x,输出图的集合G=f(x)
- 论文地址
- Deep Transfer Learning with Joint Adaptation Networks
- Distant Domain Transfer Learning (2017)
- GLoMo: Unsupervisedly Learned Relational Graphs as Transferable Representations

















 512
512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









