







本篇文章深入分析了大型模型微调的基本理念和多样化技术,细致介绍了LoRA、适配器调整(Adapter Tuning)、前缀调整(Prefix Tuning)等多个微调方法。详细讨论了每一种策略的基本原则、主要优点以及适宜应用场景,使得读者可以依据特定的应用要求和计算资源限制,挑选最适合的微调方案。
一、大型模型微调的基础理论
大型语言模型(LLM)的训练过程通常分为两大阶段:
阶段一:预训练阶段
在这个阶段,大型模型会在大规模的无标签数据集上接受训练,目标是使模型掌握语言的统计特征和基础知识。此期间,模型将掌握词汇的含义、句子的构造规则以及文本的基本信息和上下文。
需特别指出,预训练实质上是一种无监督学习过程。完成预训练的模型,亦即基座模型(Base Model),拥有了普遍适用的预测能力。例如,GLM-130B模型、OpenAI的四个主要模型均属于基座模型。
阶段二:微调阶段
预训练完成的模型接下来会在针对性的任务数据集上接受更进一步的训练。这一阶段主要涉及对模型权重的细微调整,使其更好地适配具体任务。最终形成的模型将具备不同的能力,如gpt code系列、gpt text系列、ChatGLM-6B等。
那么,何为大型模型微调?
直观上,大型模型微调即是向模型“输入”更多信息,对模型的特定功能进行“优化”,通过输入特定领域的数据集,使模型学习该领域知识,从而优化大模型在特定领域的NLP任务中的表现,如情感分析、实体识别、文本分类、对话生成等。
为何微调至关重要?
其核心理由是,微调能够“装备”大模型以更精细化的功能,例如整合本地知识库进行搜索、针对特定领域问题构建问答系统等。
以VisualGLM为例,作为一个通用多模态模型,当应用于医学影像判别时,就需要输入医学影像领域的数据集以进行微调,以此提升模型在医学影像图像识别方面的表现。
这与机器学习模型的超参数优化类似,只有在调整超参数后,模型才能更好地适应当前数据集;同时,大型模型可以经历多轮微调,每次微调都是对模型能力的优化,即我们可以在现有的、已经具备一定能力的大模型基础上进一步进行微调。
二、大型模型的经典网络结构
以GPT系列中的Transformer为例,这种深度学习模型结构通过自注意力机制等技巧解决了相关问题。正是得益于Transformer架构,基于GPT的大型语言模型取得了显著的进展。
Transformer模型架构包含了众多模块,而我们讨论的各种微调技术通常是对这些模块中的特定部分进行优化,以实现微调目的。
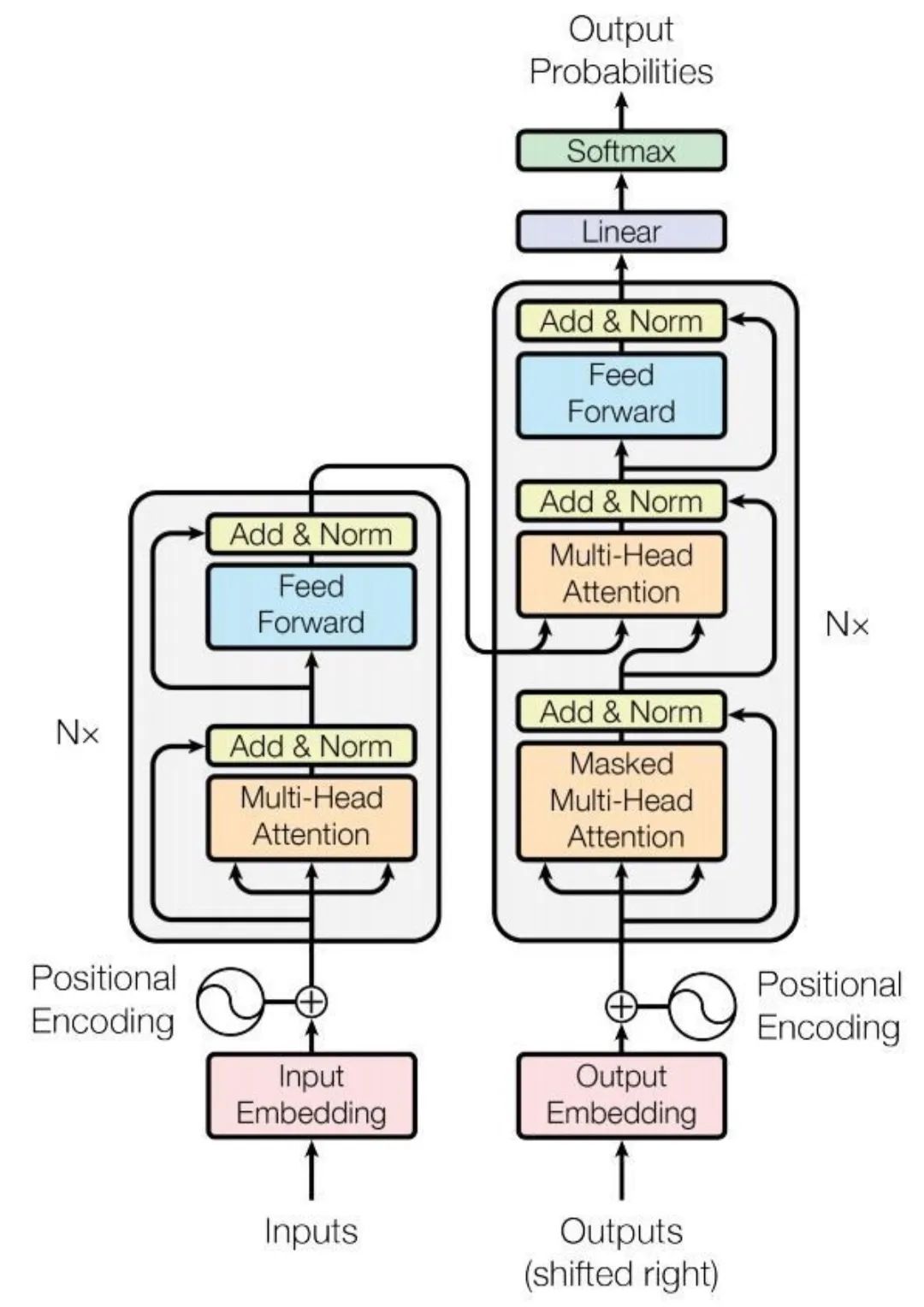
要深入理解各类微调手段,首先需要对网络架构有一个基本的认识。以下以Transformer为例,阐述各个模块的作用:
- 输入嵌入层(Input Embedding)
-
输入(Inputs):模型的输入环节,通常为单词或符号序列。
-
输入嵌入(Input Embedding):此步骤将输入序列(例如句中的每个单词)转化为嵌入表示,即能够表征单词语义信息的高维向量。
-
位置编码(Positional Encoding):鉴于Transformer不依赖序列,位置编码旨在提供序列中单词位置的信息,这些编码添加到输入嵌入中,确保模型即便同时处理输入也能够利用单词的顺序信息。
- 编码器层(Encoder,左边)
-
Nx:指示有N个相同的编码器层叠加而成。每个编码器层包括两个主要子层:多头自注意力机制和前馈神经网络。
-
多头自注意力(Multi-Head Attention):注意力机制允许模型在处理每个单词时考虑到输入序列中的所有单词。多头部分表示模型并行学习输入数据的不同表示。
-
残差连接和归一化(Add & Norm):注意力层后面跟着残差连接和层归一化,有助于防止深层网络中的梯度消失问题,并稳定训练过程。
-
前馈神经网络(Feed Forward):全连接神经网络处理自注意力层的输出,包含两个线性变换和一个非线性激活函数。
- 解码器层(Decoder,右侧)
-
解码器亦包含多个相同的层,每层包括三个主要子层:掩蔽的多头自注意力机制、多头自注意力机制和前馈神经网络。
-
掩蔽多头自注意力(Masked Multi-Head Attention):与编码器的多头自注意力机制类似,但为确保解码顺序性,掩蔽操作确保预测仅依赖于之前的输出。
-
前馈神经网络(Feed Forward):与编码器相同,每个子层之后也有加法和归一化步骤。
- 输出嵌入层和输出过程
-
解码器端的嵌入层将目标序列转换为向量形式。
-
线性层(Linear)和Softmax层:解码器的输出通过线性层映射到一个更大的词汇空间,Softmax函数将输出转换为概率分布。
三、大型模型微调的技术手段
大型模型的全面微调(Fine-tuning)涉及调整所有层和参数,以适配特定任务。此过程通常采用较小的学习率和特定任务的数据,可以充分利用预训练模型的通用特征,但可能需要更多计算资源。
参数高效微调(Parameter-Efficient Fine-Tuning,PEFT)旨在通过最小化微调参数数量和计算复杂度,提升预训练模型在新任务上的表现,从而减轻大型预训练模型的训练负担。
即使在计算资源受限的情况
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1579
1579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









