



一.背景
在大模型应用落地加速的当下,企业对 “智能交互 + 数据实时响应 + 成本可控” 的诉求日益强烈。传统大模型应用面临两大核心痛点:一方面,大模型存在上下文窗口限制,无法高效关联外部动态数据(如企业内部知识库、实时业务数据),导致交互响应缺乏精准性与时效性;另一方面,频繁调用大模型 API 会产生高额成本,且重复计算相同或相似请求会造成资源浪费,难以满足企业规模化应用的需求。
同时,企业在智能客服、内部协同助手、业务咨询系统等场景中,既需要大模型具备 “理解复杂需求、生成自然语言” 的核心能力,又要求系统能快速接入私有数据、保障数据安全性,且能灵活适配不同业务场景的定制化需求(如数据更新实时生效、交互延迟低)。传统方案或依赖大模型原生能力导致数据割裂,或通过复杂的中间件集成增加架构复杂度,难以兼顾 “易用性、实时性、低成本” 三大诉求。
Mem0 作为一款轻量级、高兼容的大模型记忆与数据增强工具,凭借其核心优势成为破解上述痛点的理想选择:它支持高效的外部数据接入与记忆管理,可突破大模型上下文窗口限制,让模型能实时关联私有数据进行精准响应;同时具备智能缓存与增量更新能力,能减少重复请求的大模型调用次数,显著降低使用成本;此外,其简洁的集成方式、良好的生态兼容性(支持主流大模型与开发框架),以及对私有数据的安全隔离支持,可快速适配企业现有技术架构,无需复杂改造。
在此背景下,开展 Mem0 使用尝试,核心目标是验证其在实际业务场景中的适用性与价值:通过接入企业私有数据(如内部知识库、业务系统数据),测试 Mem0 能否提升大模型交互的精准度与时效性;通过对比使用前后的 API 调用成本与响应延迟,评估其降本增效潜力;通过实际集成与定制开发,验证其在现有技术架构中的兼容性与易用性。此次尝试不仅是对新型大模型增强工具的技术探索,更是为企业构建 “低成本、高精准、可扩展” 的智能交互系统寻找最优解,助力企业在大模型应用落地中突破数据割裂与成本控制的核心瓶颈,提升智能应用的业务价值与落地效率。
二.具体实现
1.创建python工程,安装mem0
pip install mem0ai
2.创建main.py,引入依赖包
import os
from openai import OpenAI
from mem0 import Memory
from config import OPENAI_API_KEY, OPENAI_API_BASE
3.定义大模型配置
openai_client = OpenAI(
api_key=OPENAI_API_KEY,
base_url=OPENAI_API_BASE
)
# 设置环境变量
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
os.environ["OPENAI_BASE_URL"] = OPENAI_API_BASE
4.定义memory实例(本地已经搭建好向量数据库,图数据库)
memory = Memory.from_config({
"vector_store": {
"provider": "qdrant",
"config": {
"url": "http://xxx:16333",
"embedding_model_dims": 1536
}
},
"llm": {
"provider": "openai",
"config": {
"model": "gpt-3.5-turbo",
"api_key": OPENAI_API_KEY,
"openai_base_url": OPENAI_API_BASE
}
},
"embedder": {
"provider": "openai",
"config": {
"model": "text-embedding-3-small",
"api_key": OPENAI_API_KEY,
"openai_base_url": OPENAI_API_BASE,
"embedding_dims": 1536
}
},
"graph_store": {
"provider": "neo4j",
"config": {
"url": "neo4j://localhost:7687",
"username": "neo4j",
"password": "xxxx"
}
},
"history_db_path": "./mem0_history.db"
})
5.测试memory
messages = [
{"role": "user", "content": "我今晚想看电影,有什么推荐?"},
]
memory.add(messages, user_id="alice", metadata={"category": "电影推荐"})
memory.add([
{"role": "user", "content": "我喜欢吃苹果,香蕉"},
], user_id="alice")
memory.add([
{"role": "user", "content": "我喜欢喝牛奶"},
], user_id="alice")
relevant_memories = memory.search(query="我喜欢什么食物", user_id="alice", limit=2)
print(relevant_memories)
6.结果
{
'results': [{
'id': 'aa9ff45c-33c6-4166-9b94-c20242a56264',
'memory': '喜欢吃苹果,香蕉',
'hash': '6e049298ec1641799fd1a039dee5691b',
'metadata': None,
'score': 0.8558062314987183,
'created_at': '2025-08-21T01:06:40.666898-07:00',
'updated_at': '2025-08-24T20:13:37.008707-07:00',
'user_id': 'alice'
}, {
'id': 'a6c9b986-6437-4416-990c-a385ccee2f86',
'memory': '喜欢吃香蕉',
'hash': '553cb759b0671e815b97f3aa5df02887',
'metadata': None,
'score': 0.8957499265670776,
'created_at': '2025-08-24T20:13:38.938117-07:00',
'updated_at': None,
'user_id': 'alice'
}],
'relations': []
}
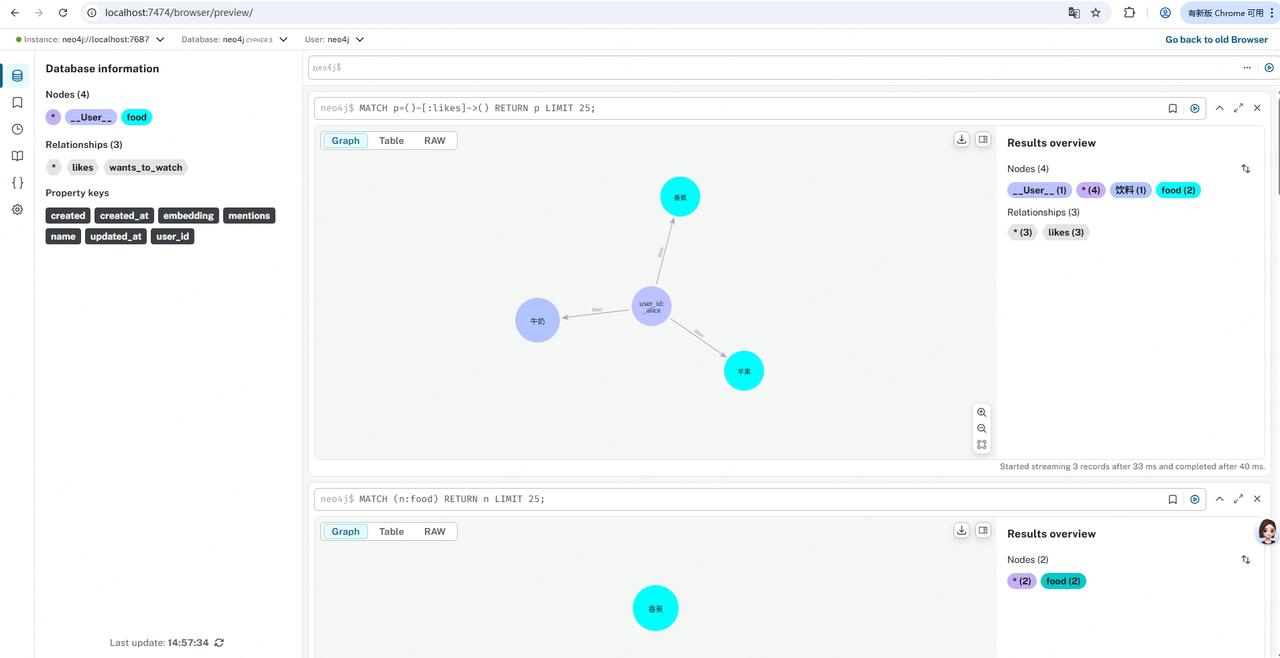
7.查看neo4j可以看到记忆构建成了实体-关系


















 2038
2038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











