



一.背景
StarRocks 作为新一代 MPP 实时分析型数据库,凭借列式存储、向量化执行等核心技术,在海量数据实时写入与复杂查询场景中表现突出,广泛应用于实时报表、用户画像、监控告警等企业级核心业务。其数据导入过程中,为平衡写入性能与查询效率,采用了 Compaction(数据合并)机制—— 将分散的小数据版本(Segment)异步合并为更大的有序数据块,从而减少查询时的文件扫描次数、优化索引利用效率、降低存储冗余,是保障 StarRocks 长期稳定运行的关键后台任务。
在实际生产环境中,Compaction 机制的运行状态直接影响数据库的核心能力,具体体现在:
- 查询性能稳定性:若小文件堆积未及时合并,查询时需扫描大量零散 Segment,导致 IO 开销激增、查询延迟大幅上升,甚至引发集群性能瓶颈;
- 数据写入可用性:StarRocks 对单个 Tablet 的数据版本数量存在上限,若 Compaction 进度滞后于数据写入速度,会导致版本数超限,直接阻塞新数据导入,影响业务连续性;
- 存储与资源占用:未合并的小文件会占用更多元数据存储空间,且 Compaction 本身需消耗 CPU、IO 等集群资源,若进度异常(如长时间停滞、重复失败),会造成资源浪费,甚至影响其他业务任务;
- 故障排查效率:当出现查询缓慢、写入阻塞等问题时,若无法准确获取 Compaction 进度(如合并任务队列、执行状态、失败原因),会导致问题定位困难,延长故障恢复时间。
然而,StarRocks 的 Compaction 过程默认在后台异步执行,缺乏直观的可视化监控手段。传统运维中,开发者或运维人员需依赖零散的系统表查询、日志分析等方式获取有限信息,存在诸多痛点:
- 无法全局掌握集群级、数据库级或表级的 Compaction 整体进度,难以预判潜在风险;
- 难以定位 Compaction 延迟或失败的具体原因(如数据倾斜、资源不足、配置不合理);
- 缺乏对 Compaction 任务队列、执行优先级、资源占用情况的实时感知,运维决策缺乏数据支撑。
因此,实现 StarRocks Compaction 进度的精准查询,成为保障集群稳定运行与优化运维效率的核心诉求。通过标准化的查询方案,能够让运维人员实时掌握 Compaction 执行状态、快速定位异常问题、合理调整配置参数(如 Compaction 线程数、合并阈值),从而避免因 Compaction 异常导致的查询性能下降、数据写入阻塞等问题。这一实践对提升 StarRocks 集群的可用性、稳定性与运维效率具有重要意义,是企业级 StarRocks 部署与运维过程中不可或缺的关键环节。
二.具体方法
1.查看compaction压力最大的表
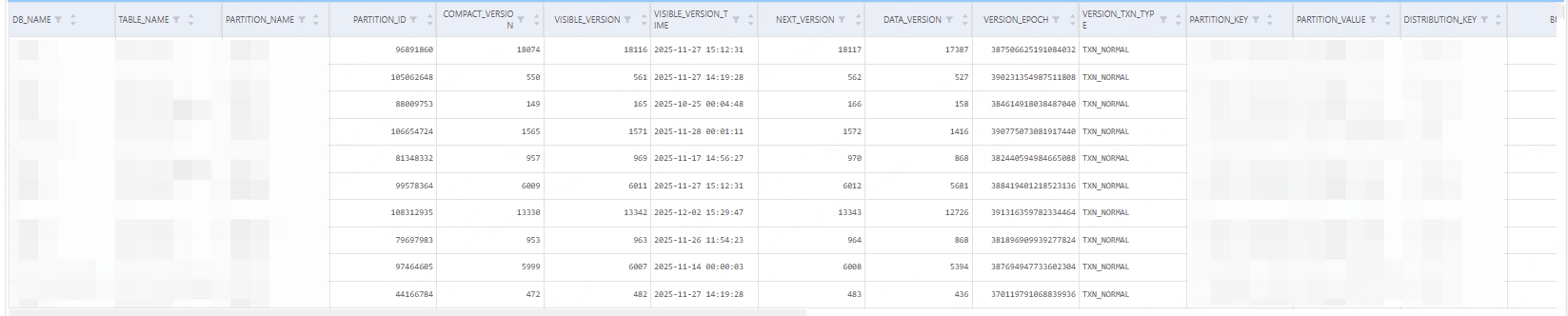
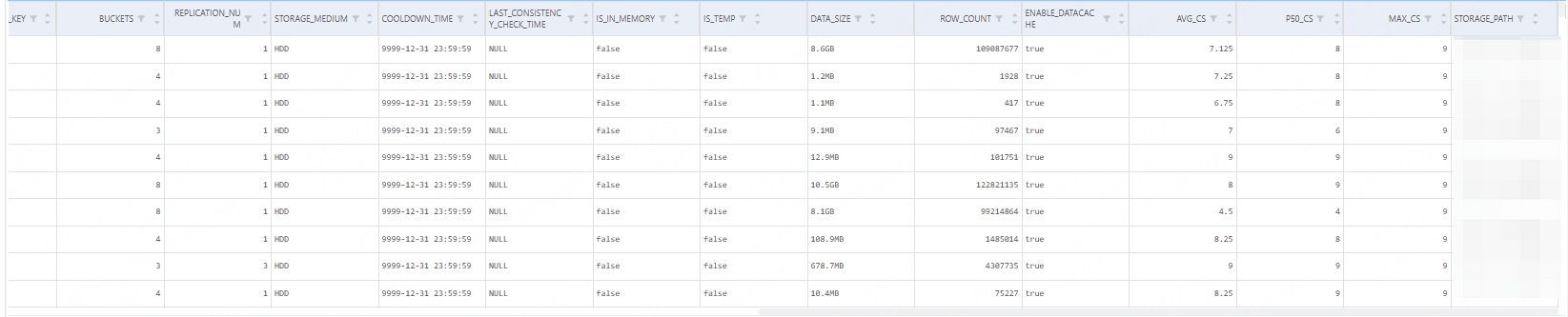
SELECT Max_CS FROM information_schema.partitions_meta ORDER BY Max_CS desc
可以看到查询结果是以表分区级展示compaction的压力情况
2.查看正在运行的compaction作业
SHOW PROC '/compactions'
可以看到compaction作业的具体运行情况(包括运行的事务id)

3.根据事务id我们能够更进一步查看子任务的执行情况
SELECT * FROM information_schema.be_cloud_native_compactions where TXN_ID=事务id order by START_TIME desc
可以看到每个tablet的compaction情况

4.对于异常的compaction任务我们可以直接取消,让它自动重跑
CANCEL COMPACTION WHERE TXN_ID =事务id


















 1631
1631

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











