







 本文聚焦利用视觉关系辅助图像描述,提出GCN - LSTM模型。结合目标语义和空间关系,用目标检测模块编码图像,生成语义图和空间关系图,经GCN处理后输入LSTM生成描述。在Visual Genome数据集训练,获先进图像描述模型,但存在输出关系弱、门控与注意力区别不明等问题。
本文聚焦利用视觉关系辅助图像描述,提出GCN - LSTM模型。结合目标语义和空间关系,用目标检测模块编码图像,生成语义图和空间关系图,经GCN处理后输入LSTM生成描述。在Visual Genome数据集训练,获先进图像描述模型,但存在输出关系弱、门控与注意力区别不明等问题。
Exploring Visual Relationship for Image Captioning
时间:2018年
Intro
尽管当前存在很多CNN+RNN模型,还有一个未被充分研究的问题,即如何利用视觉关系来帮助image captioning。
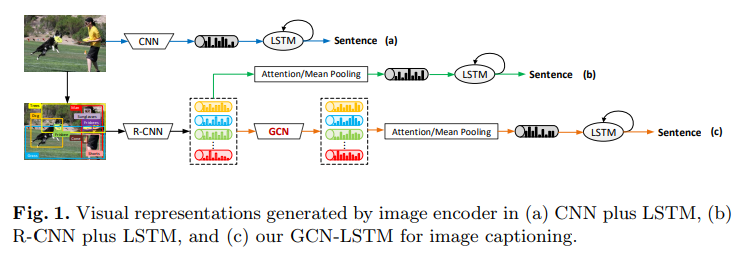
本文提出了一个GCN-LSTM模型,如图所示
Contribution
本文的主要贡献是提出了对视觉关系的使用
Model
本文通过结合目标在语义上的和空间上的关系(semantic and spatial object relationships)来进行image caption,首先使用目标检测模块(如Faster R-CNN)来检测目标,从而将整张图编码成一个显著区域的集合,以这个集合为基础分别生成semantic graph 和 spatial relation graph,然后开始训练GCN,利用GCN将之前的feature结合成更好的feature,得到relation-aware的region representation,然后喂给LSTM,使用region-level的attention机制来生成caption,模型的整体如图所示
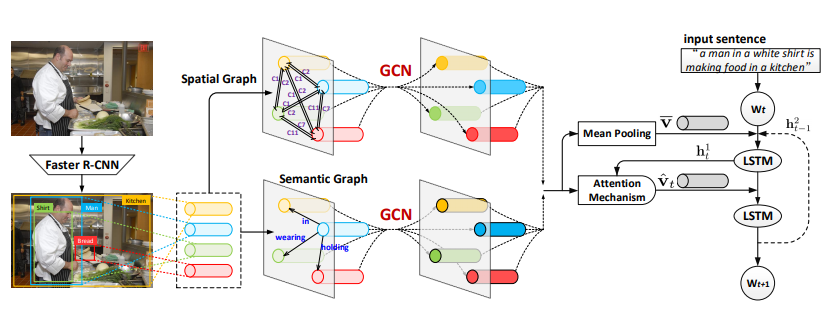
Visual Relationship between Objects in Images
Semantic Object Relationship
semantic relation是
<
s
u
b
j
e
c
t
−
p
r
e
d
i
c
a
t
e
−
o
b
j
e
c
t
>
<subject-predicate-object>
<subject−predicate−object>这样的三元组,本文使用了一个分类网络来得到两个object之间的关系,这个网络是在visual relationship benchmarks上学习的(比如 Visual Genome),为了得到目标
v
i
v_i
vi和目标
v
j
v_j
vj的关系,需要将它们并集的bounding box作为网络输入的一部分,如图所示
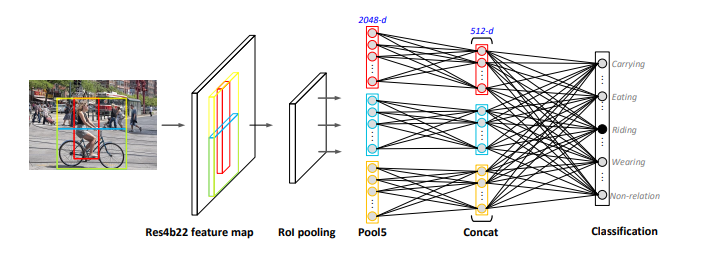
region-level feature v i v_i vi 和 v j v_j vj首先分别通过一个embedding层,然后和 v i j \mathbf{v_{ij}} vij(包含两者的bounding box的特征)concat到一起,输入到网络中,输出是一个在 N s e m N_{sem} Nsem个semantic relationship类和一个无relationship类上的softmax概率,region level feature取 D v D_v Dv维( D v D_v Dv=2048)的来自R-CNN(with ResNet-101)的Res4b22 feature map的Pool5层输出。
记RCNN的proposal数为 K K K,首先将这 K K K个目标组成 K ∗ ( K − 1 ) K*(K-1) K∗(K−1)对,然后计算每一对在relation classifier上的输出,如果无relation这类的输出小于0.5,则将在两个目标之间建立一条有向边,边上的关系即是剩余输出最大的类别所指向的关系
Spatial Object Relationship
semantic relationship没能考虑到空间上的relationship,因此引入spatial relationship作为补充,spatial relationship是一个二元组
<
o
b
j
e
c
t
i
−
o
b
j
e
c
t
j
>
<object_i-object_j>
<objecti−objectj>,记录两个物体的相对几何位置,边和相应的标签是由IoU、相对距离和角度决定的,共有11类位置关系和一类无关系,如图所示
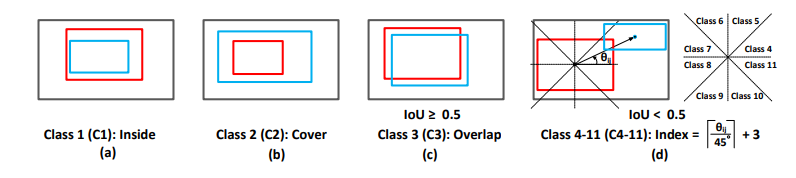
有关系则用边连接起来,并在边上表上关系
captioning model
接下来就是使用GCN-LSTM来进行image caption了,GCN-based image encoder将image regions feature, semantic graph 和 spatial graph 分别 encode到一起,综合上下文信息生成relation aware representation,然后喂给LSTM
GCN-based Image Encoder
原始的GCN是在无向图上进行操作的
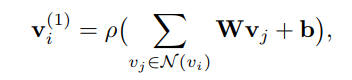
其中
N
(
v
i
)
\mathcal{N}(v_i)
N(vi)是所有与
v
i
v_i
vi有边连接的结点,其中也包括
v
i
v_i
vi自身,但这种GCN无法融入有向边和边上label的信息,故修改为
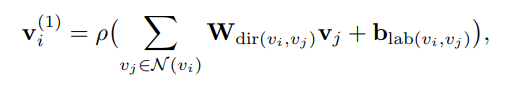
d
i
r
(
v
i
,
v
j
)
dir(v_i,v_j)
dir(vi,vj)根据边的方向给出不同的
W
W
W,
W
1
W_1
W1 for
v
i
−
t
o
−
v
j
v_i-to-v_j
vi−to−vj,
W
2
W_2
W2 for
v
j
−
t
o
−
v
i
v_j-to-v_i
vj−to−vi,
W
3
W_3
W3 for
v
i
−
t
o
−
v
i
v_i-to-v_i
vi−to−vi,并且,加上一个edge-wise gate(区别于attention)来使网络focus一些重要的边
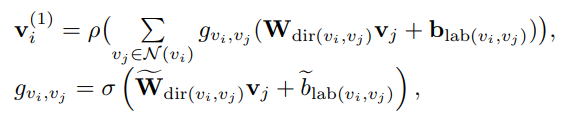
Attention LSTM Sentence Decoder
在上一步的输出
v
i
(
1
)
i
=
1
K
{v_i^{(1)}}^{K}_{i=1}
vi(1)i=1K的基础上,LSTM的更新如下
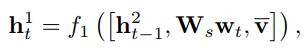
LSTM的输入融合了上一轮的隐层输出(初始化为
v
ˉ
\bar{v}
vˉ),输入词
w
t
\mathbf{w_t}
wt是embedding 向量,和
v
ˉ
=
1
K
∑
i
=
1
K
v
i
(
1
)
\bar{v}=\frac{1}{K}\sum^{K}_{i=1}v_{i}^{(1)}
vˉ=K1∑i=1Kvi(1),
W
s
W_s
Ws是transformation matrix,
h
1
h^1
h1是first layer LSTM unit,然后可以求attention
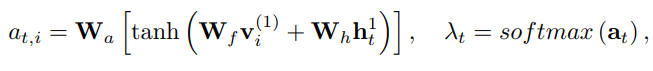
然后就可以在
v
i
(
1
)
v_i^{(1)}
vi(1)上加权求出
v
^
t
=
∑
i
=
1
K
λ
t
,
i
v
i
(
1
)
\hat{v}_t=\sum_{i=1}^K\lambda_{t,i}\mathbf{v_i}^{(1)}
v^t=i=1∑Kλt,ivi(1)
然后将结果concat起来喂给second-layer LSTM unit,
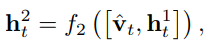
然后
h
t
2
h_t^2
ht2就用来预测下一个词
w
t
+
1
w_{t+1}
wt+1
训练
训练的时候semantic和spatial graph分别用来训练两个网络,实际预测时两个网络的输出加权得到结果
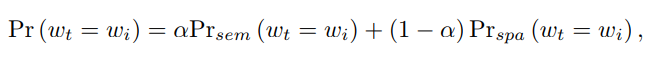
细节
预处理时将所有文本转化为小写且去掉所有少于五次的词
数据集
Visual Genome:大规模的数据集,用来对目标的相交以及关系进行建模
结论
本文通过将semantic graph和spatial graph融入到图像region feature中,得到了state-of-the-art的image caption模型
问题
-
1 v i ( 1 ) \mathbf{v_i^{(1)}} vi(1)本身与 v i \mathbf{v_{i}} vi的直接关系显得很弱
这个公式中,如果有两个 v i v_i vi,它们本身是不同的,但却与相同的其他object有相同的关系,那么它们的输出就几乎是相同的,因为在求和中仅仅是它们连接到自身的那条边不一样,这某种程度上也是因为第一个式子的右边 v i v_i vi没有直接参与到运算的原因(除了和自己相连的那次) -
2 gate和attention的区别
注意到文中对于不同的连接使用了gate,这样做和用attention用啥区别?attention-based简写就是
v i ( 1 ) = ρ ( ∑ λ v i , v j ( W v + b ) ) v_i^{(1)}=\rho(\sum \lambda_{v_i,v_j}(Wv+b)) vi(1)=ρ(∑λvi,vj(Wv+b))
λ v i , v j = s o f t m a x ( W v + b ) \lambda_{v_i,v_j}=softmax(Wv+b) λvi,vj=softmax(Wv+b)

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









