







 提出了一种基于注意力机制的神经网络模型,用于自动生成图像描述。模型包含软注意力和硬注意力两种模式,通过卷积网络提取图像特征并利用LSTM进行解码,生成描述。硬注意力机制通过采样确定关注的图像区域,而软注意力则计算各区域的权重。
提出了一种基于注意力机制的神经网络模型,用于自动生成图像描述。模型包含软注意力和硬注意力两种模式,通过卷积网络提取图像特征并利用LSTM进行解码,生成描述。硬注意力机制通过采样确定关注的图像区域,而软注意力则计算各区域的权重。
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
时间:2016年
概括
提出了两个attention based model that automatically learns to describe the content of images,一个 soft attention 和一个 hard attention,
Model
encoder
网络输出
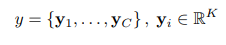
y
i
y_i
yi是输出的词,
K
K
K是caption的长度
作者使用卷积网络抓取L个D维特征向量
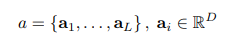
为了得到特征向量与图片具体位置的对应,作者从浅层的卷积核中提取了特征而非全连接层,通过输入
a
a
a的子集,这使得decoder能够选择性地专注于图片的某个部分
decoder
作者使用LSTM作为decoder,每一步生成一个词,
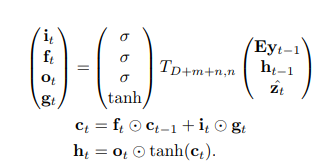
其中
z
z
z是context vector,计算方式如下,
a
t
i
a_{ti}
ati可以视作
α
i
\alpha_i
αi在
t
t
t时刻对于生成正确单词的重要程度
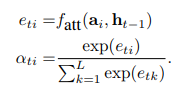
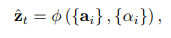
ϕ
\phi
ϕ返回一个向量,具体将在之后讨论
LSTM的初始细胞状态和隐藏状态由两个MLPs预测
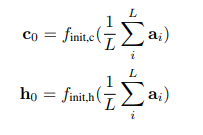
(不同位置的特征向量加在一起能表示什么呢…)
使用deep output layer来计算词的概率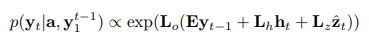
其中
L
∗
,
E
L_*,E
L∗,E都是待学习的参数
Stochastic “Hard” 和 Deterministic “Soft” Attention
这里给出了context vector z z z的计算方式
Stochastic “Hard” Attention
s
t
s_t
st代表模型在生成第
t
t
t个词时focus的位置变量,
s
t
,
i
=
1
s_{t,i}=1
st,i=1,当第
i
i
i个location(总共L个)用来作为视觉特征,否则为0,这是hard的含义,通过将attention location当作中间的隐变量,我们可以得到被
a
i
{a_i}
ai参数化的多项分布
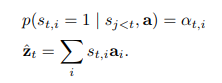
定义一个新的损失函数
L
s
L_s
Ls,它是marginal log-likelihood
log
(
y
∣
a
)
\log(y|a)
log(y∣a)的下界,可以通过优化下界来优化原损失函数
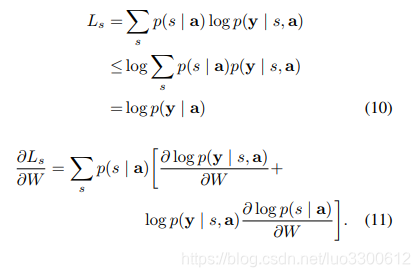
通过蒙特卡罗采样来得到梯度的估计值,这可以通过采样
s
t
s_t
st得到
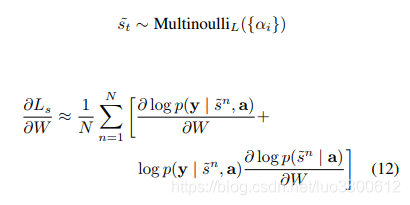
为了处理estimator variance的问题,需要采取一系列措施,最终的损失函数是
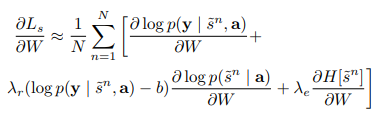
Deterministic “Soft” Attention
soft attention对于每个位置的权值不是非0即1的,之前的方法我们每次都要对
s
t
s_t
st采样,现在我们则可以直接计算
z
t
z_t
zt的期望
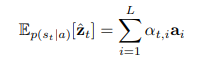
计算
z
z
z时,也可以直接求加权和
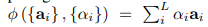
此时函数是可微的,因此只要通过梯度下降就可以优化
引入doubly stochastic regularization,是为了让模型平等的注意每个part,最后通过最小化以下函数优化
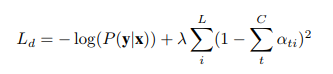
问题
top-down模型在生成一些停词的时候,attention所注意的位置没有任何意义


hard attention看起来很奇怪,为什么可以work

结论
本文提出了一个attention based 模型,图片按照spatial position编码成多个向量,并在这些向量上做attention,其attention机制分为hard和soft两种模式,效果显示attention的直觉与人的直觉相似

















 724
724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









