




 本文详细介绍了如何通过requests模块配合MD5算法,解密有道词典网站的动态加密过程,包括salt、sign、lts的获取和sign的计算。通过实例代码展示了如何使用Python实现JS解密,重点在于时间戳处理和随机数生成。
本文详细介绍了如何通过requests模块配合MD5算法,解密有道词典网站的动态加密过程,包括salt、sign、lts的获取和sign的计算。通过实例代码展示了如何使用Python实现JS解密,重点在于时间戳处理和随机数生成。
爬虫学习第五天—requests模块实现JS解密
一、抓包分析
1、网页抓包分析
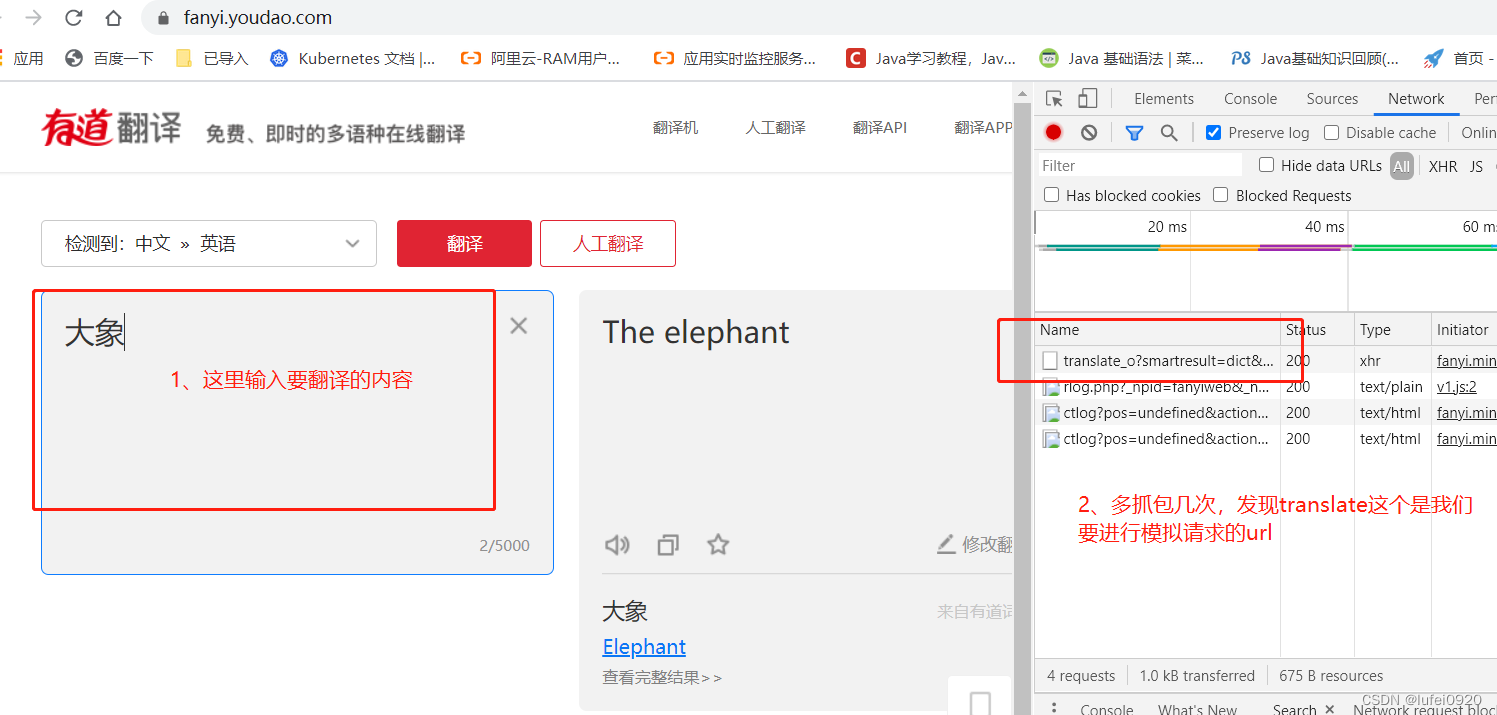
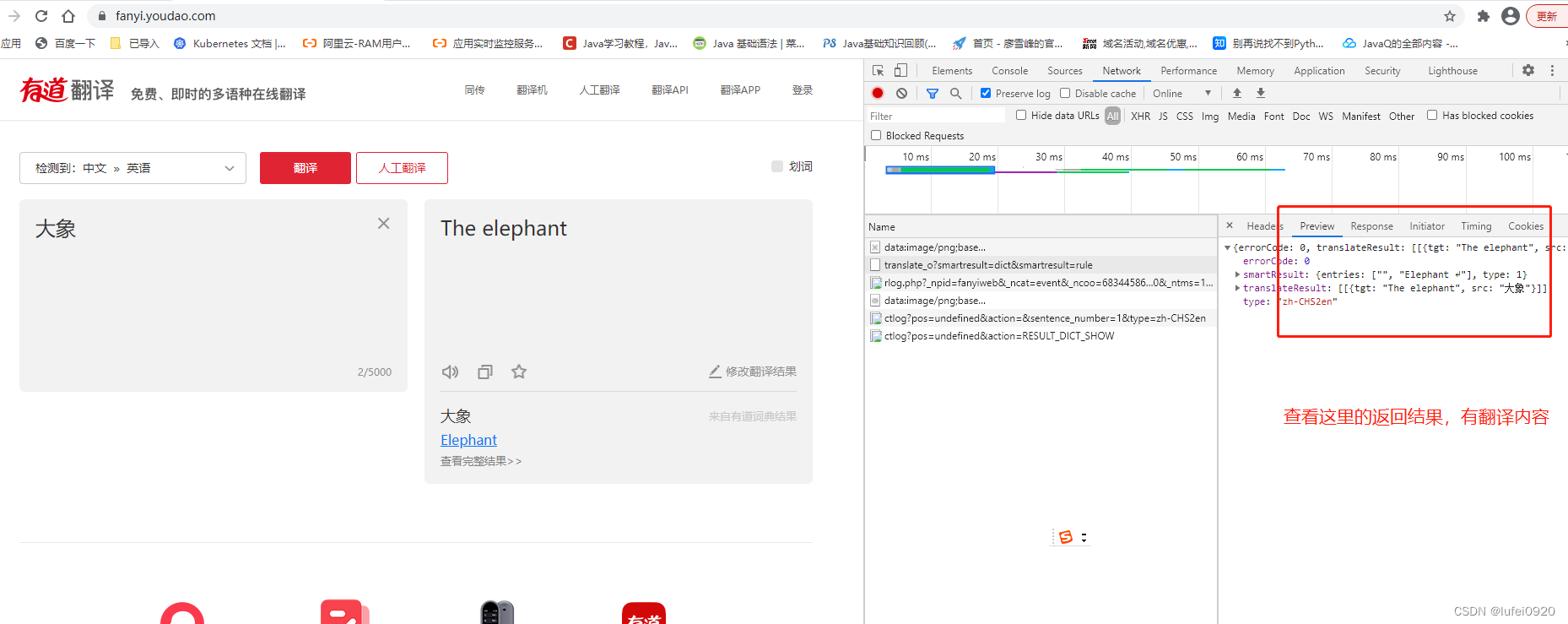
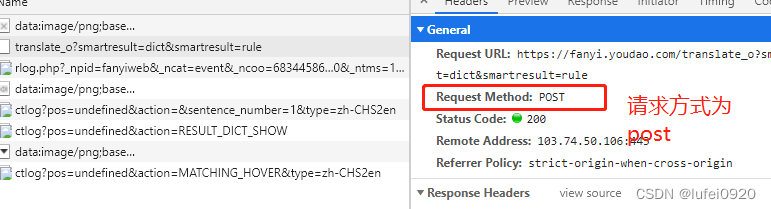
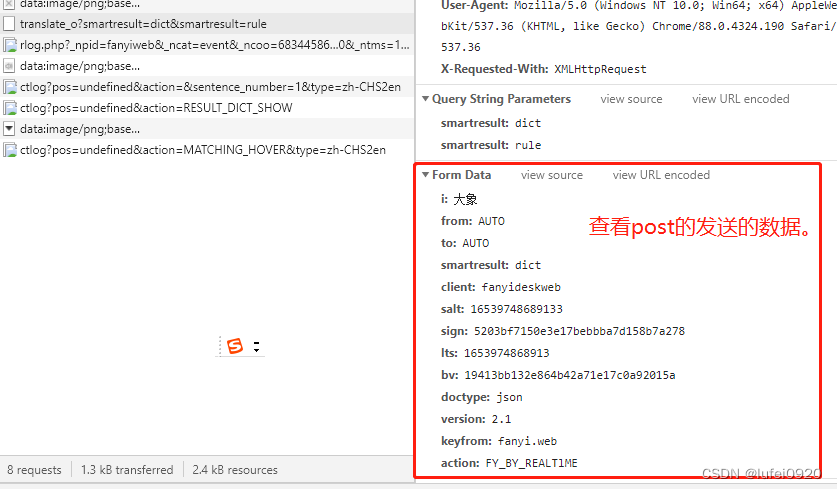
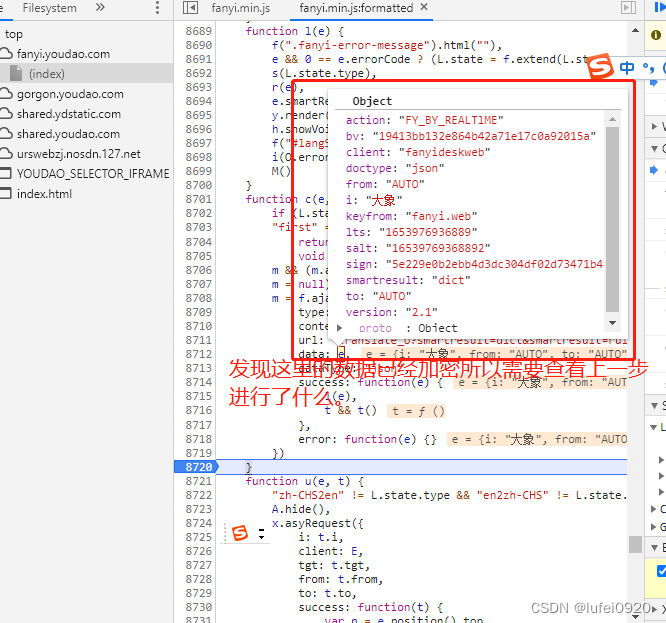
2、分析此处发送的数据是预设值还是固定值还是程序获取方式。
这里需要我们多抓包几次分析,如下图中。
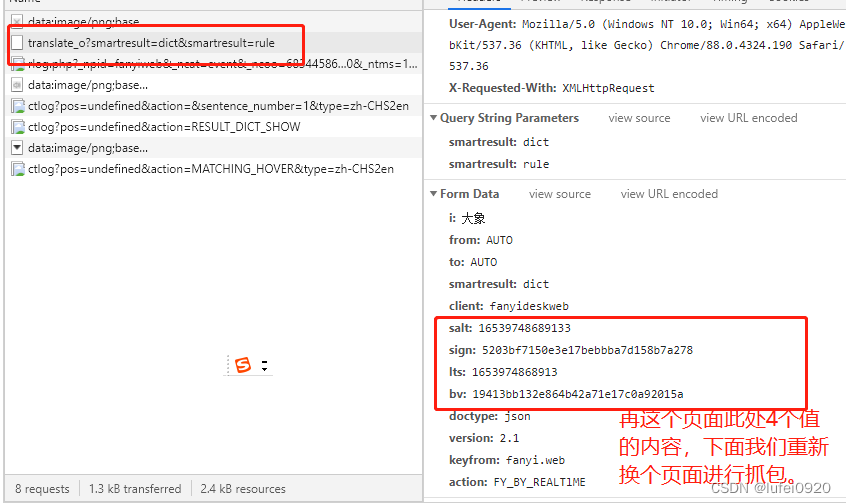
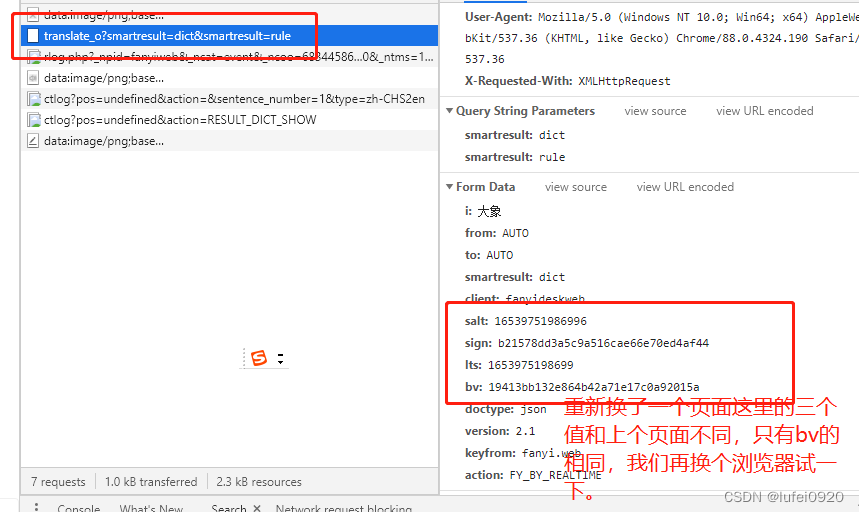

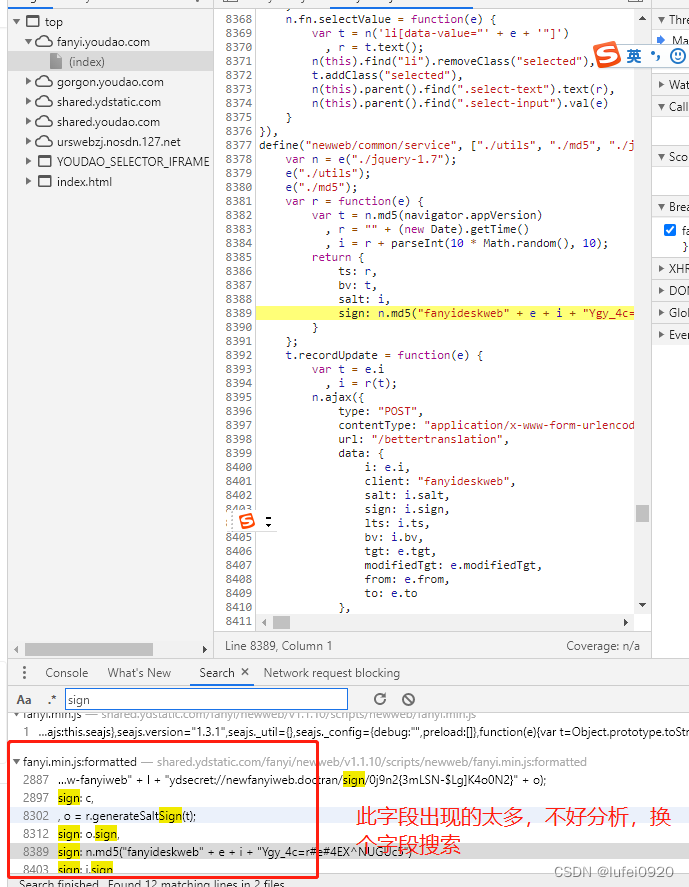
通过多次抓包分析得出
1、相同浏览器不同页面其salt,sign,lts的值不同。
2、不同浏览器,其四个值都不同
所以我们需要继续分析获取此处的数据。
二、JS 解密salt、sign、lts、bv详解)
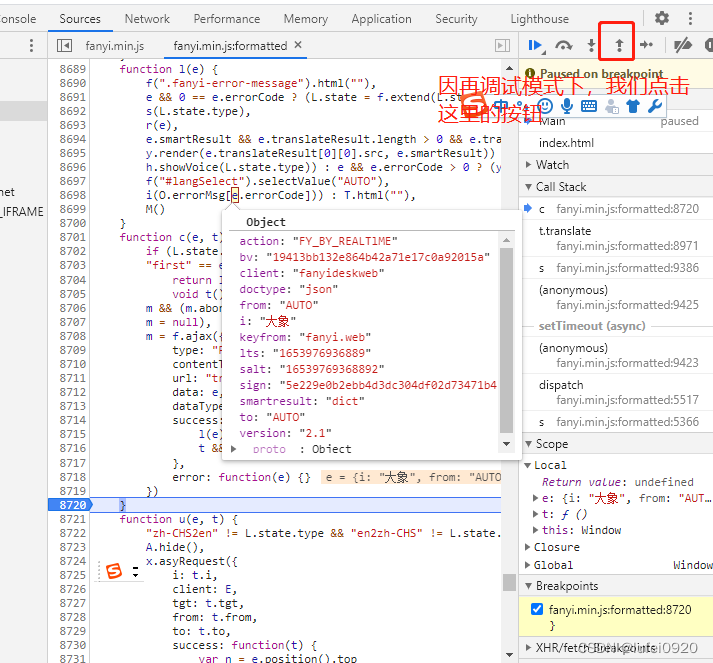
1、解密分析
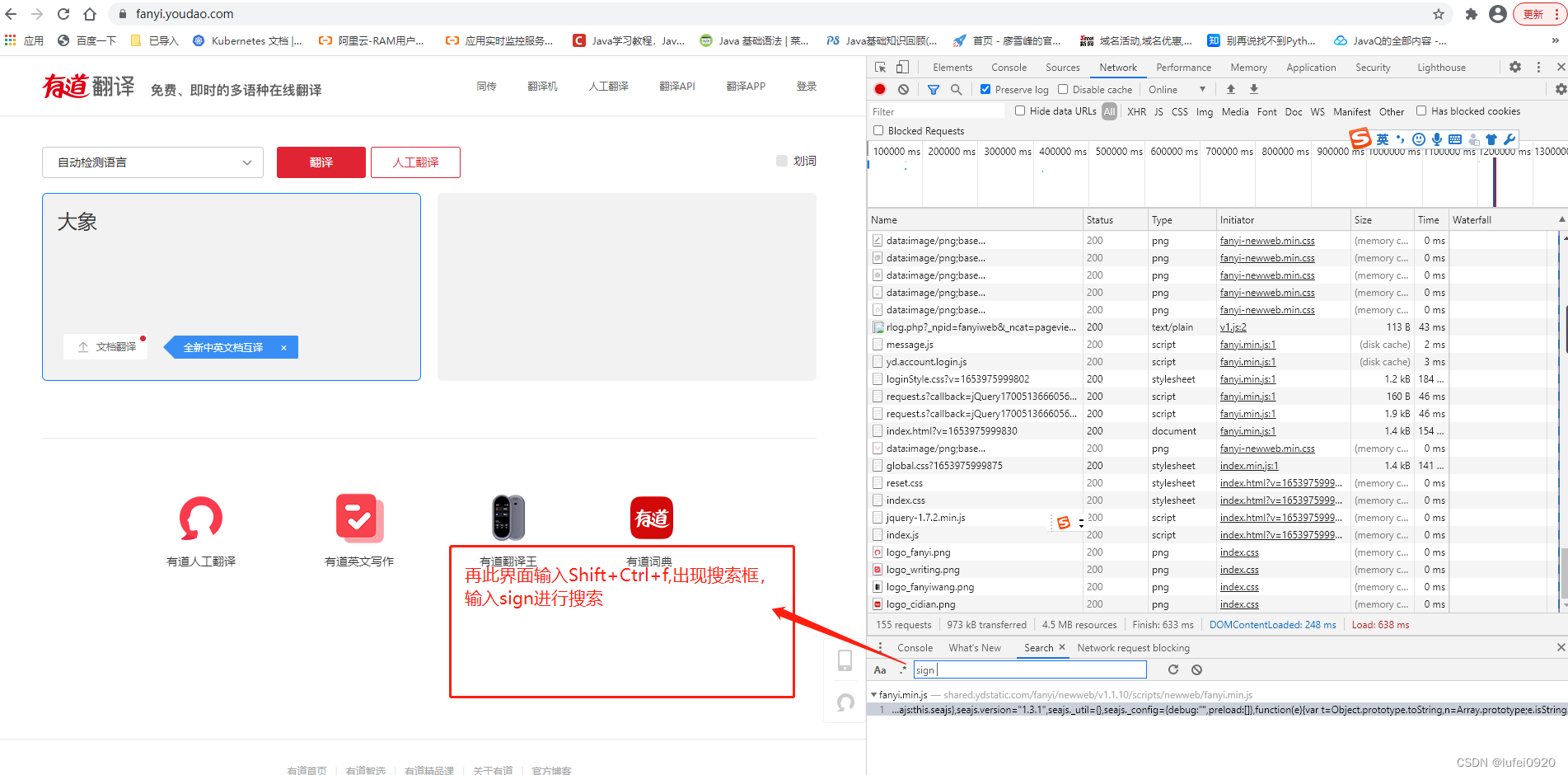
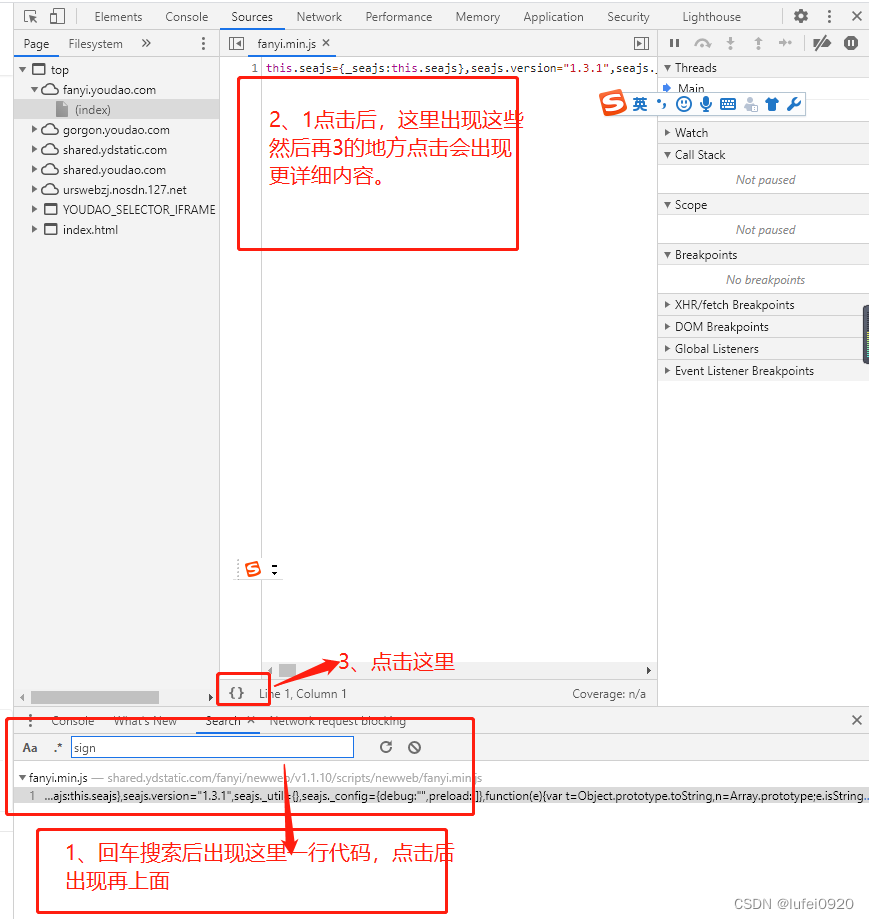
调试
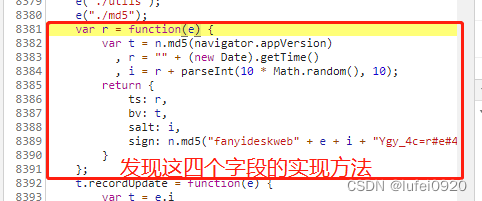
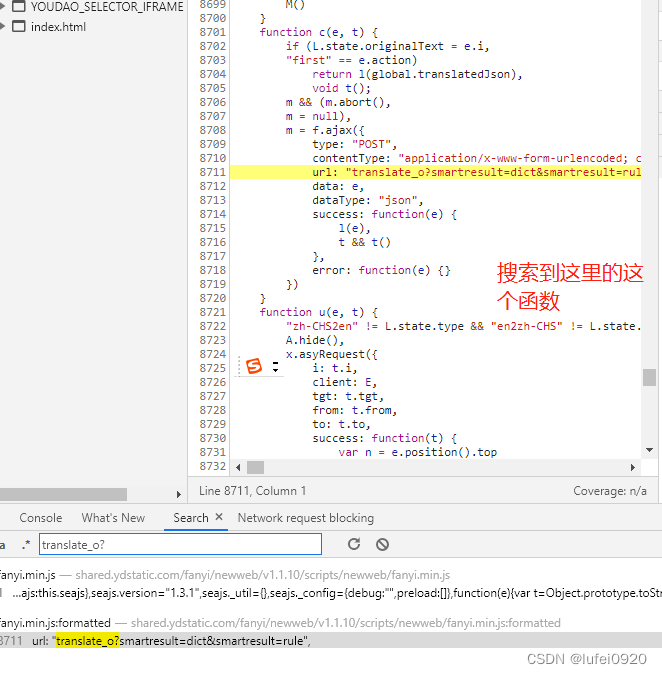
var r = function(e) {
var t = n.md5(navigator.appVersion)
, r = "" + (new Date).getTime()
, i = r + parseInt(10 * Math.random(), 10);
return {
ts: r,
bv: t,
salt: i,
sign: n.md5("fanyideskweb" + e + i + "Ygy_4c=r#e#4EX^NUGUc5")
}
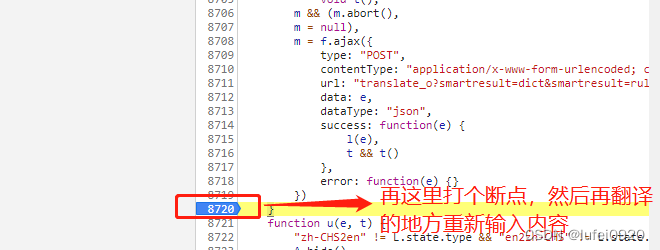
这时我们需要通过python代码来实现上面的加密方法即可。
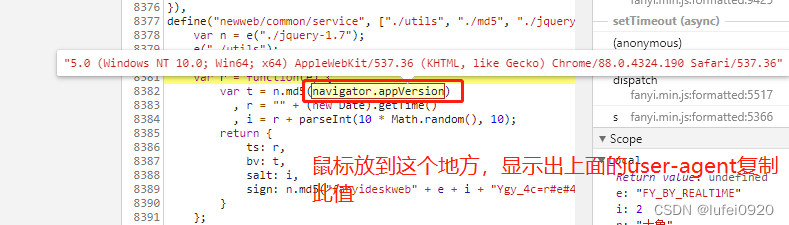
2、python实现
01、先解bv,bv为t
js方法:
t = n.md5(navigator.appVersion)
navigator.appVersion为:‘5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36’
python方法:
from hashlib import md5
user_agent = "5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36"
t = md5(user_agent.encode()).hexdigest()
经验证值相同

02、解ts,即函数中的r
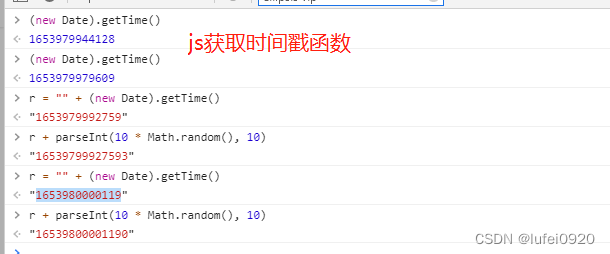
js实现:
r = "" + (new Date).getTime()
python实现:
r = str(int(time.time() * 1000)) # 用time获取时间戳,但发现小数点前少三位,则需要乘以1000再取整数
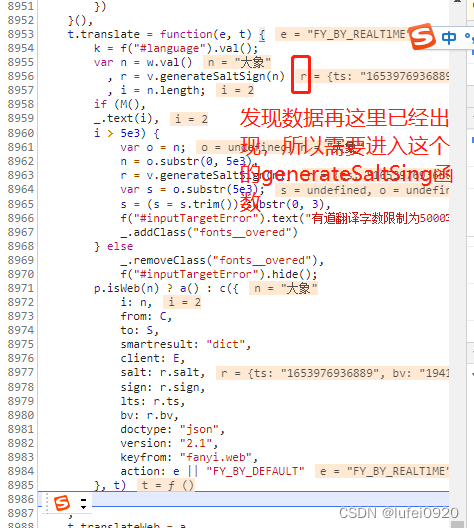
03、salt获取,即函数中的i
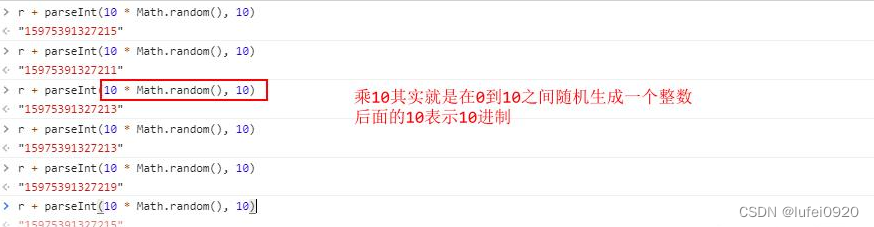
js实现:
i = r + parseInt(10 * Math.random(), 10);
python实现
i = r + str(random.randint(0, 9)) # i就等于r加上0-9的任意一个随机数(字符串)
04、sign实现
js实现:
sign: n.md5("fanyideskweb" + e + i + "Ygy_4c=r#e#4EX^NUGUc5")
python实现:
sign = md5(("fanyideskweb" + e + i + "Ygy_4c=r#e#4EX^NUGUc5").encode()).hexdigest()
三、python实现有道词典的JS解密后的完整代码
import requests
from hashlib import md5
import time
import random
import re
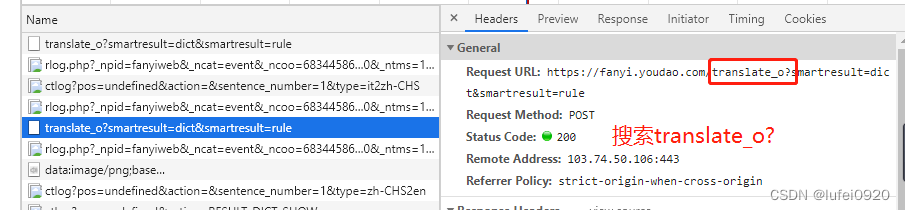
# 请求地址
url = "https://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule"
url_js = 'https://shared.ydstatic.com/fanyi/newweb/v1.1.10/scripts/newweb/fanyi.min.js'
user_agent = "5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36"
ip_list = [
"http://58.220.95.34:10174",
"http://112.6.117.178:8085",
# "http://58.220.95.8:10174",
# "http://58.246.58.150:9002",
# "http://36.134.91.82:8888",
# "http://219.246.65.55:80",
# "http://218.59.139.238:80",
# "http://120.220.220.95:8085",
# "http://120.42.46.226:6666",
# "http://58.220.95.42:10174",
# "http://221.7.197.248:8000",
]
random_ip = random.choice(ip_list)
proxies = {
"http": random_ip,
# "https": "https://12.34.56.79:9527",
}
# headers = {
# 'User-Agent': appVersion
# }
headers = { # headers中必须保留的字段:Cookie、Referer、User-Agent
'Cookie': 'OUTFOX_SEARCH_USER_ID=-583950801@10.110.96.160; OUTFOX_SEARCH_USER_ID_NCOO=683445865.2455099; fanyi-ad-id=305838; fanyi-ad-closed=1; ___rl__test__cookies=1653964405876',
'Referer': 'https://fanyi.youdao.com/',
'User-Agent': user_agent,
}
def get_encry_data(word): # 获取post数据中的加密部分内容。
# '''
# var r = function(e) {
# var t = n.md5(navigator.appVersion)
# , r = "" + (new Date).getTime()
# , i = r + parseInt(10 * Math.random(), 10);
# return {
# ts: r,
# bv: t,
# salt: i,
# sign: n.md5("fanyideskweb" + e + i + "Ygy_4c=r#e#4EX^NUGUc5")
# }
# 这里是js代码中的加密方式。
# '''
# bv
t = md5(user_agent.encode()).hexdigest()
# lts
r = str(int(time.time() * 1000)) # 用time获取时间戳,但发现小数点前少三位,则需要乘以1000再取整数
# i
i = r + str(random.randint(0, 9)) # i就等于r加上0-9的任意一个随机数(字符串)
js_str = js_data()
return {
"ts": r,
"bv": t,
"salt": i,
"sign": md5((js_str['client'] + word + i + js_str['str_slat']).encode()).hexdigest()
} # 返回一个字典
def js_data():
while True:
try: # 有时请求url时会报无法访问,则做一下循环即可。
r_sign = requests.get(url=url_js, headers=headers, proxies=proxies)
print(r_sign.status_code)
if r_sign.status_code == int(200):
r_sign = r_sign.text
mm = re.findall('sign:n.md5.*?;t.recordUpdate', str(r_sign)) # 这里搜索出来是:'sign:n.md5("fanyideskweb"+e+i+"Ygy_4c=r#e#4EX^NUGUc5")}};t.recordUpdate'
mm = mm[0].split(";")[0].split('"') # 对上面字符串进行分割处理,目的是为了取出fanyideskweb,Ygy_4c=r#e#4EX^NUGUc5这两个地方,可能这里的字符串会不定期变化,所以要通过访问js返回的详细内容获取。
return {
'client': mm[1],
'str_slat': mm[3],
}
break
except:
print("js_data获取数据出错")
def fanyi(word):
data = get_encry_data(word)
post_data = { # post发送的数据,经验证可以去掉from、to、smartresult、doctype、action
"i": word,
"client": "fanyideskweb",
"salt": data["salt"],
"sign": data["sign"],
"lts": data["ts"],
"bv": data["bv"],
"version": "2.1",
"keyfrom": "fanyi.web",
}
# print(data["salt"])
while True:
try:
response = requests.post(url=url, headers=headers, data=post_data,proxies=proxies)
if response.status_code == int(200):
return response.json()
break
except:
print("获取翻译数据失败")
if __name__ == "__main__":
# word = input("请输入要翻译的语句:")
word = "加密"
result = fanyi(word)
# 对返回的json数据进行提取,提取出我们需要的数据
r_data = result["translateResult"][0]
print(r_data[0]["src"])
print(r_data[0]["tgt"])


















 3508
3508



 到【灌水乐园】发言
到【灌水乐园】发言










