




爬虫学习第四天—requests模块-session
requests模块中的Session类能够自动处理发送请求获取响应过程中产生的cookie,进而达到状态保持的目的。
1、requests.session的作用以及应用场景
requests.session的作用:
自动处理cookie,即 下一次请求会带上前一次的cookie。
requests.session的应用场景:
自动处理连续的多次请求过程中产生的cookie。
2、 requests.session使用方法
session实例在请求了一个网站后,对方服务器设置在本地的cookie会保存在session中,下一次再使用session请求对方服务器的时候,会带上前一次的cookie
session = requests.session() # 实例化session对象
response = session.get(url, headers, ...)
response = session.post(url, data, ...)
3、示例演示
使用requests.session来完成github登陆,并获取需要登陆后才能访问的页面
3.1、项目分析
1、对github登陆以及访问登陆后才能访问的页面的整个完成过程进行抓包
2、确定登陆请求的url地址、请求方法和所需的请求参数
3、部分请求参数在别的url对应的响应内容中,可以使用re模块获取
4、确定登陆后才能访问的页面的的url地址和请求方法
5、利用requests.session完成代码
3.2、分析过程
1、打开谷歌的无痕浏览器,输入github登录页面,进行抓包
https://github.com/
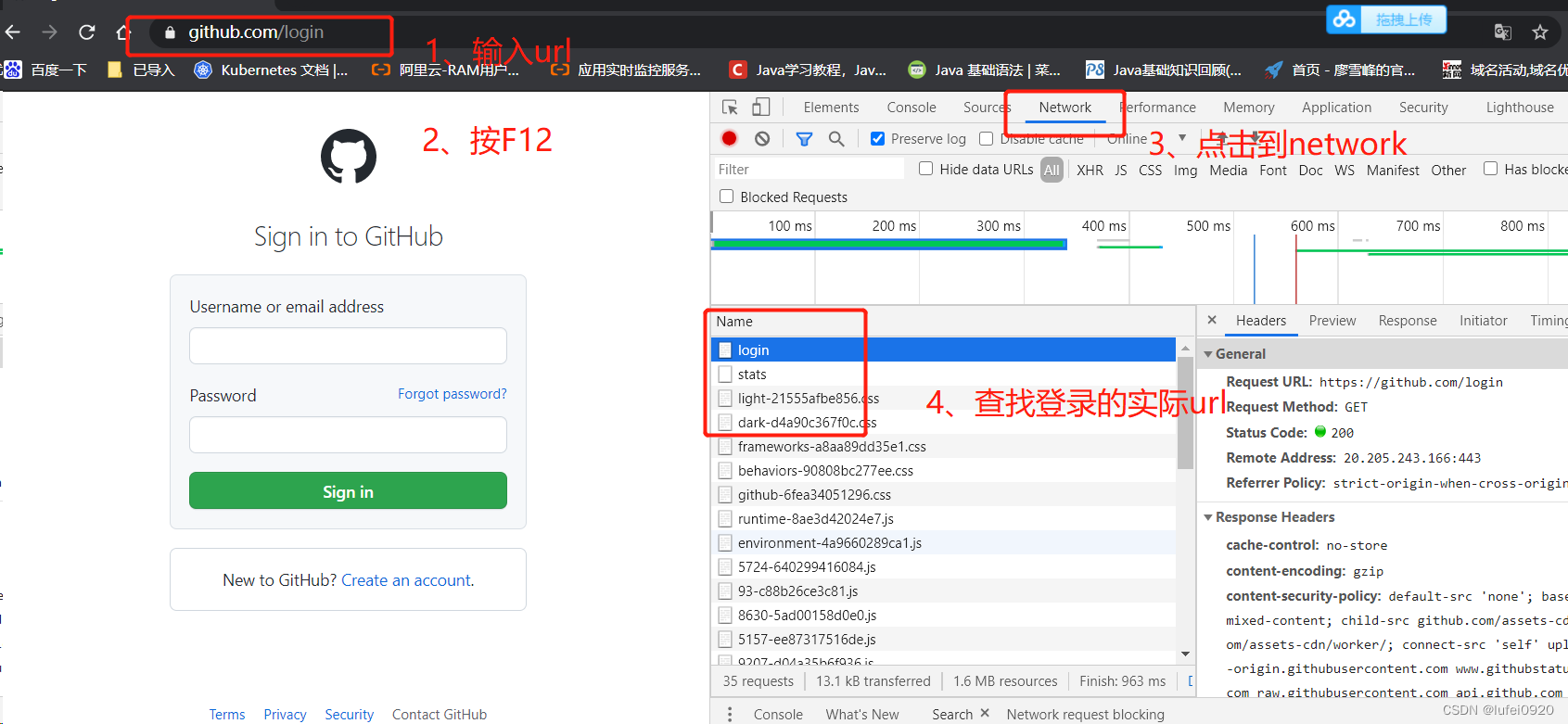
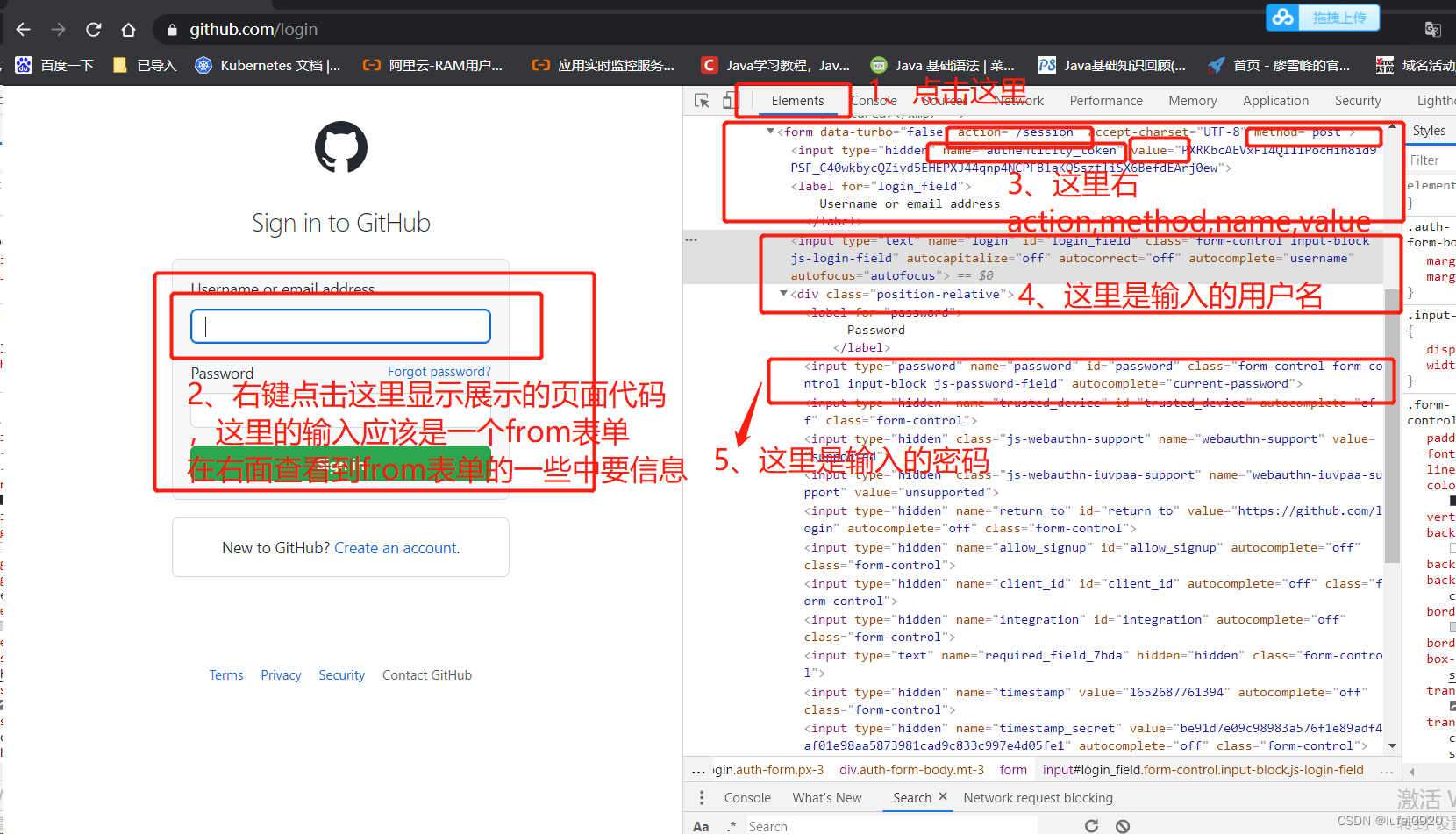
说明:这里的action是指我们需要将数据发送给那个uri,method是指发送方法。
2、接下来我们输入登录的账号和密码
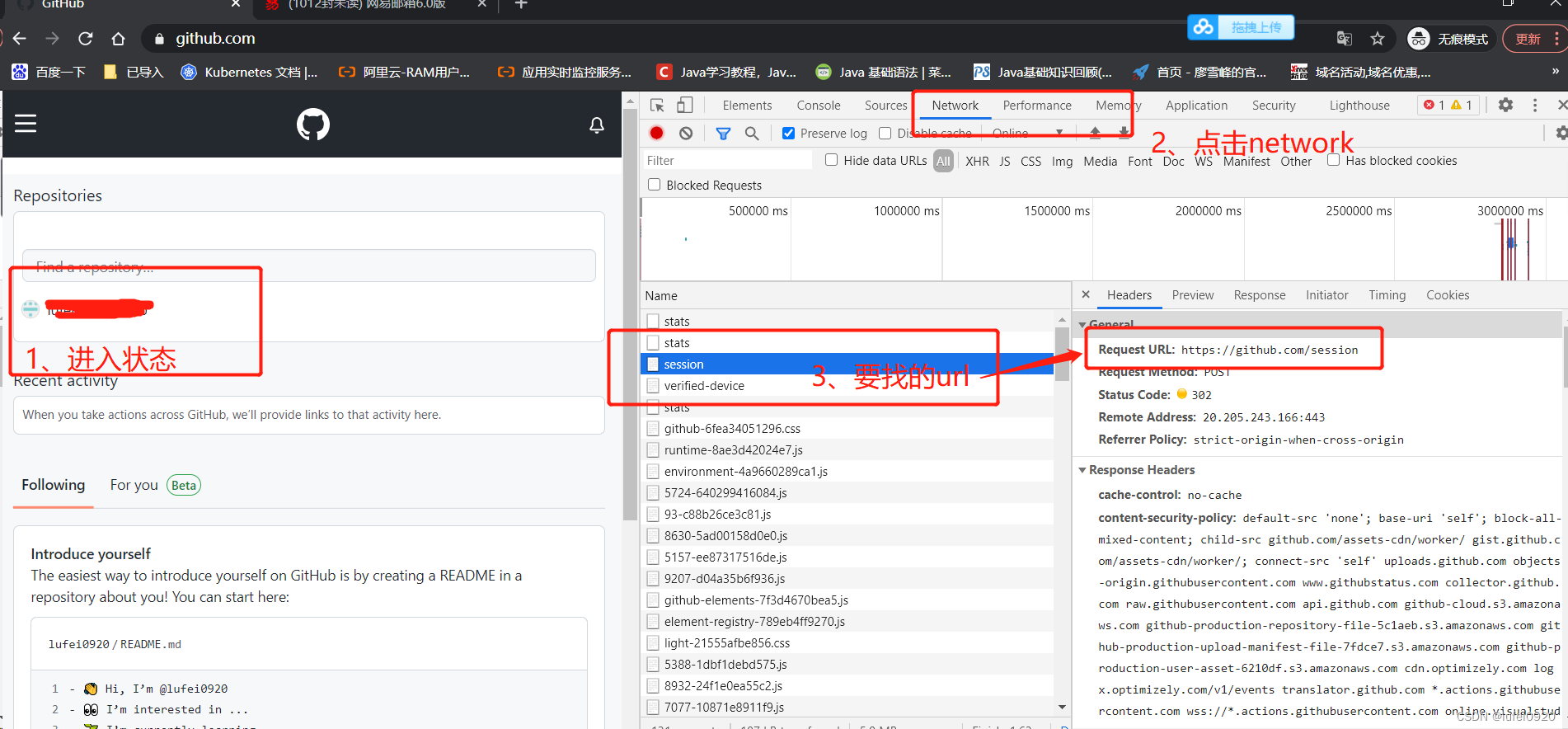
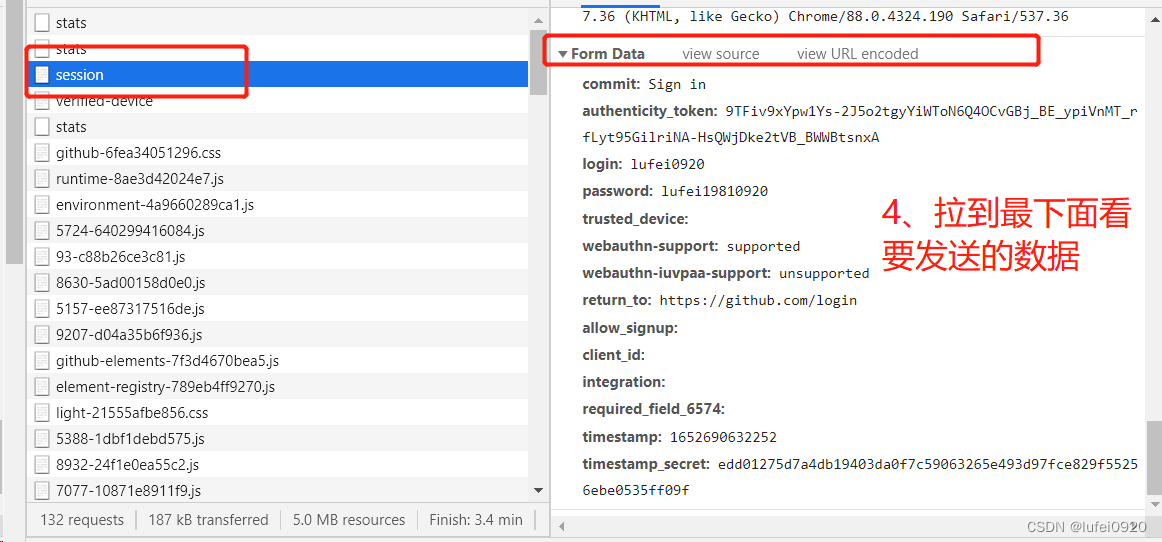
说明:这里的session的url拉到最下面显示了from data数据,我们需要将此数据发送至session的url页面中,所以需要确认from data数据的性质。这里需要对此处的数据多进行抓包查看。下图为三次抓包的对比结果

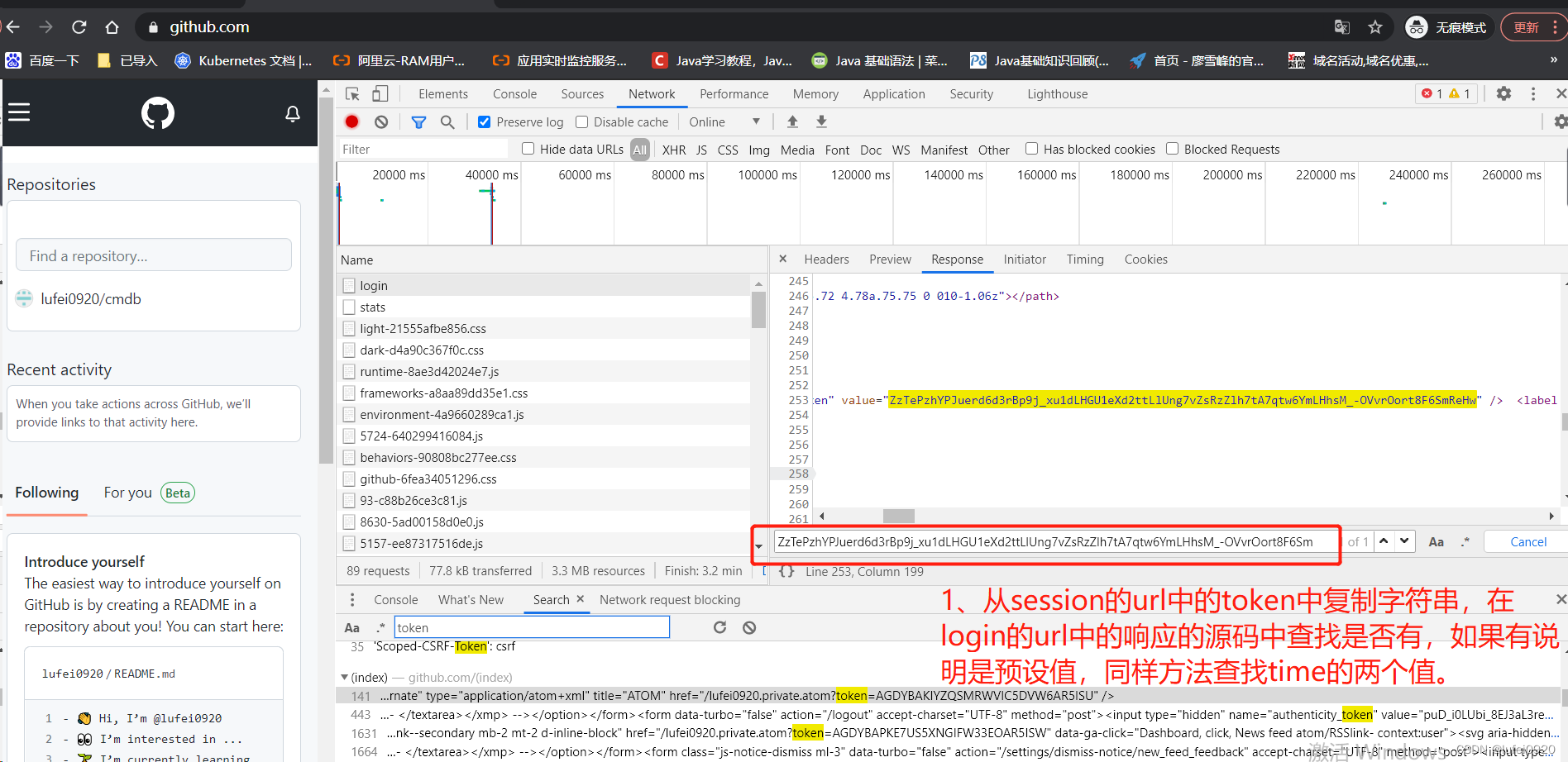
3.3、代码详解
import requests
import re
def login():
# 创建session
session = requests.session()
# headers信息
session.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"
}
proxies = {
# "http": "http://1.198.72.207:9999",
# "http": "http://106.14.5.129:80",
"http": "http://60.207.131.49:80",
# "https": "https://123.55.101.55:9999",
}
# 登录url1获取token信息
url1 = 'https://github.com/login'
# 发送请求获取响应
# ret_1 = session.get(url1,headers=session.headers,proxies=proxies).content.decode()
ret_1 = session.get(url1, headers=session.headers).content.decode()
# print(ret_1)
# 正则提取
token = re.findall('name="authenticity_token" value="(.*?)" />',ret_1)[0] # 只获取token的字符串
timestamp_str = re.findall('<input type="hidden" name="timestamp" value="(.*?)" autocomplete="off" class="form-control" />',ret_1)[0]
timestamp_secret_str = re.findall('name="timestamp_secret" value="(.*?)" autocom',ret_1)[0]
# print(token,timestamp_str,timestamp_secret_str)
# print(token)
# 登录URL2
url2 = 'https://github.com/session'
# 构建表单数据
data = {
"commit": "Sign in",
"authenticity_token": token,
"login": "用户名",
"password": "密码",
"webauthn-support": "supported",
"webauthn-iuvpaa-support": "unsupported",
"timestamp": timestamp_str,
"timestamp_secret": timestamp_secret_str
}
response2 = session.post(url2,data=data,headers=session.headers)
# URL3验证
username = 'lufei0920'
url3 = 'https://github.com/'
response3 = session.get(url3+username,headers=session.headers)
print(re.findall('<title>(.+)</title>',response3.content.decode()))
if __name__ == "__main__":
login()
结果:



















 198
198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











