




 本文详细讲解了如何利用lxml模块结合XPath语法在HTML和XML文档中定位元素,提取属性和文本,以及安装和使用XPathHelper插件。通过实例演示,学习者能快速上手数据抓取和解析技巧。
本文详细讲解了如何利用lxml模块结合XPath语法在HTML和XML文档中定位元素,提取属性和文本,以及安装和使用XPathHelper插件。通过实例演示,学习者能快速上手数据抓取和解析技巧。
爬虫学习之第七天—数据提取-lxml模块和Xpath使用
知识点:
了解 lxml模块和xpath语法的关系
了解 lxml模块的使用场景
了解 lxml模块的安装
了解 谷歌浏览器xpath helper插件的安装和使用
掌握 xpath语法-基础节点选择语法
掌握 xpath语法-节点修饰语法
掌握 xpath语法-其他常用语法
掌握 lxml模块中使用xpath语法定位元素提取属性值或文本内容
掌握 lxml模块中etree.tostring函数的使用
一、 了解 lxml模块和xpath语法
lxml模块可以利用XPath规则语法,来快速的定位HTML\XML 文档中特定元素以及获取节点信息(文本内容、属性值)
XPath (XML Path Language) 是一门在 HTML\XML 文档中查找信息的语言,可用来在 HTML\XML 文档中对元素和属性进行遍历。
W3School官方文档:http://www.w3school.com.cn/xpath/index.asp
提取xml、html中的数据需要lxml模块和xpath语法配合使用
二、 谷歌浏览器xpath helper插件的安装和使用
要想利用lxml模块提取数据,需要我们掌握xpath语法规则。接下来我们就来了解一下xpath helper插件,它可以帮助我们练习xpath语法。
1、xpath helper插件的安装
1.1、下载Chrome插件 XPath Helper
可以在chrome应用商城进行下载,如果无法下载,也可以从下面的链接进行下载
下载地址:链接:https://pan.baidu.com/s/10Nb2pqfgkhTuHJ4FnQ3Hrg 提取码:44ew
1.2、将下载好的xpath文件(请选着好mac或win版本的.crx文件)拖入谷歌浏览器。
点击插件后即可显示上面的界面。
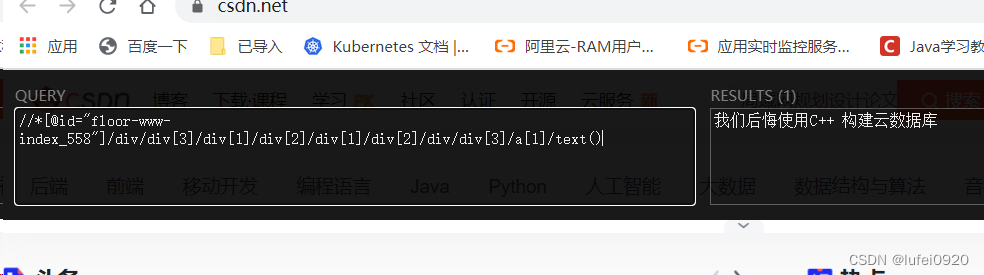
1.3、如果是linux或macOS操作系统,直接将crx文件拖入已经开启开发者模式的chrome浏览器扩展程序界面
三、Xpath使用
1、XPath简介
XPath 是一门在 XML 文档中查找信息的语言。XPath 用于在 XML 文档中通过元素和属性进行导航。
什么是XPath:
XPath 使用路径表达式在 XML 文档中进行导航
XPath 包含一个标准函数库
XPath 是 XSLT 中的主要元素
XPath 是一个 W3C 标准
2、XPath节点
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档节点(或称为根节点)。
节点(Node)
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。XML 文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。
示例说明:
请看下面这个 XML 文档:
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
上面的XML文档中的节点例子:
<bookstore> (文档节点)
<author>J K. Rowling</author> (元素节点)
lang="en" (属性节点)
J K. Rowling (基本值(或称原子值,Atomic value),基本值是无父或无子的节点。)
"en" (基本值(或称原子值,Atomic value),基本值是无父或无子的节点。)
节点关系

author是title的第一个兄弟节点
3、XPath语法
XPath语法基本分为四类:层级、属性、函数、运算符
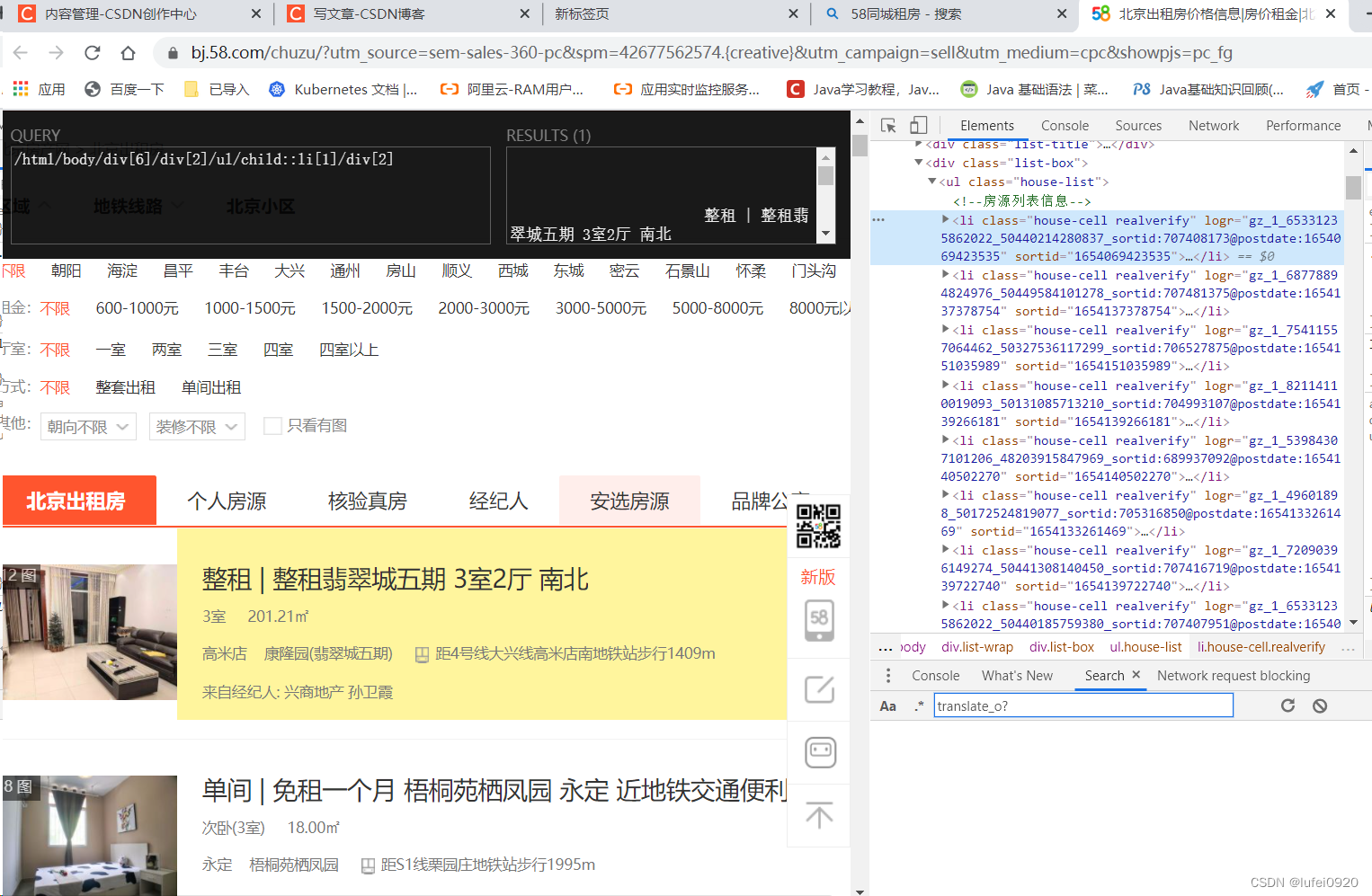
以下语法均通过58同城租房网做演示实例
| 语法类别 | 表达式 | 描述 | 示例 |
|---|---|---|---|
| 层级 | / | 从根节点选取、或者是元素和元素间的过渡。 | /html/body/div[6]/div[2] : 获取此div中所有列表中的信息 |
| 层级 | // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 | //div[@class=“list-box”]: 获取div中class=“list-box”的所有内容 |
| 层级 | . | 选取当前节点。 | |
| 层级 | … | 选取当前节点的父节点。 | |
| 层级 | parent | 选取当前节点的父节点 | //ul[@class=“house-list”]/li[1]/parent::div : 选取ul的所有信息(li的父节点) |
| 层级 | child | 选取当前节点的所有子节点 | //ul[@class=“house-list”]/li[1]/child::div[2]: 获取li列表中子节点div2的信息 |
| 层级 | preceding | 选取当前节点的开始标签之前的所有节点 | |
| 层级 | following | 选取当前节点的结束标签之后的所有节点 | //ul[@class=“house-list”]/li[1]/following::text() |
| 层级 | ancestor | 选取当前节点的所有先辈节点 (父、祖父等) | //ul[@class=“house-list”]/li[1]/ancestor::div |
| 层级 | descendant-or-self | 选取当前节点的所有后代节点及当前节点本身 | //ul[@class=“house-list”]/li[1]/descendant-or-self::div[2] |
| 层级 | descendant | 选取当前节点的所有后代节点 (子、孙等) | //ul[@class=“house-list”]/li[1]/descendant::h2 : 选取li的孙节点h2 |
| 属性 | @ | 选取属性 | |
| 属性 | @* | 选取所有属性 | //ul[@class=“house-list”]//div[@class=“des”]//a/@* |
| 属性 | [@attrib] | 选取具有给定属性的所有元素 | //ul[@class=“house-list”]//div[@class=“des”]//a/@href |
| 属性 | [@attrib=‘value’] | 选取给定属性具有给定值的所有元素 | //ul[@class=“house-list”] |
| 函数 | last() | 返回被处理节点的最后一个元素 | //div[@id=“s-top-left”]/a[last()] |
| 函数 | position() | 匹配返回节点的索引位置 | //div[@id=“s-top-left”]/a[position()=1] |
| 函数 | contains() | 匹配一个属性值中包含的字符串,用于模糊定位 | //div[contains(@id,“s-t”)]/a[last()] |
| 函数 | text() | 文本定位,常和contains()函数一起使用 | //div/a[contains(text(),“学”)] |
| 函数 | starts-with() | 匹配一个属性值开始位置的关键字,用于模糊定位 | //div[starts-with(@id,“s-t”)]/a[last()] |
| 运算符 | = | 等于 | |
| 运算符 | != | 不等于 | |
| 运算符 | < | 小于 | |
| 运算符 | > | 大于 | |
| 运算符 | <= | 小于等于 | |
| 运算符 | >= | 大于等于 | |
| 运算符 | or | 或 | |
| 运算符 | and | 且 | |
| 运算符 | * | 通配符,匹配任意字符,如//div/*,选取div标签下的所有标签 | |
| 运算符 | 与或符,双方条件都满足时都显示,否则只显示满足条件的一方 | ||
| 运算符 | [] | 谓语和索引需要用[]括起来,谓语是用来查找某个特定节点或包含指定值的节点 |
四、Lxml模块
1、安装模块
pip/pip3 install lxml
或:python/python3 -m pip/pip3 install lxml
2、lxml使用
导入lxml 的 etree 库
from lxml import etree
利用etree.HTML,将html字符串(bytes类型或str类型)转化为Element对象,Element对象具有xpath的方法,返回结果的列表
html = etree.HTML(text)
ret_list = html.xpath("xpath语法规则字符串")
xpath方法返回列表的三种情况
返回空列表:根据xpath语法规则字符串,没有定位到任何元素
返回由字符串构成的列表:xpath字符串规则匹配的一定是文本内容或某属性的值
返回由Element对象构成的列表:xpath规则字符串匹配的是标签,列表中的Element对象可以继续进行xpath
3、lxml模块实例
from lxml import etree
text = '''
<div>
<ul>
<li class="item-1">
<a href="link1.html">first item</a>
</li>
<li class="item-1">
<a href="link2.html">second item</a>
</li>
<li class="item-inactive">
<a href="link3.html">third item</a>
</li>
<li class="item-1">
<a href="link4.html">fourth item</a>
</li>
<li class="item-0">
a href="link5.html">fifth item</a>
</ul>
</div>
'''
html = etree.HTML(text)
#获取href的列表和title的列表
href_list = html.xpath("//li[@class='item-1']/a/@href")
title_list = html.xpath("//li[@class='item-1']/a/text()")
#组装成字典
# for href in href_list: 方法1
# item = {}
# item["href"] = href
# item["title"] = title_list[href_list.index(href)]
# print(item)
for text,link in zip(title_list,href_list): # 方法2
print(text,link)


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











