



一、业务流程
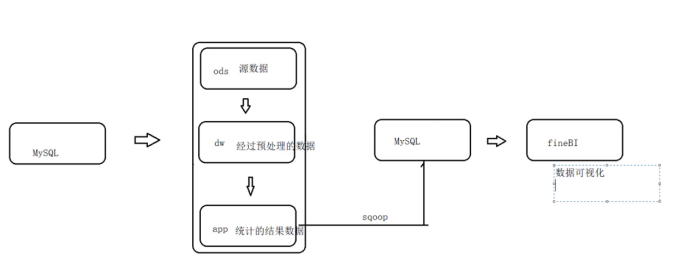
第一个Mysql称为业务库,我称它为数据仓库的作用---经过hive的加工得到app层数据。
---再通过sqoop把hive(Hadoop)导入到Mysql里(第二个mysql叫数据库,用于分析)
---最后就是可视化的步骤了
二、涉及到的技术
HDFS--hive--sqoop--mysql--finebi
三、数据的处理
这里我们在hive里把数据分为三层,分别是ods层源数据--dw层与处理数据--app层统计数据
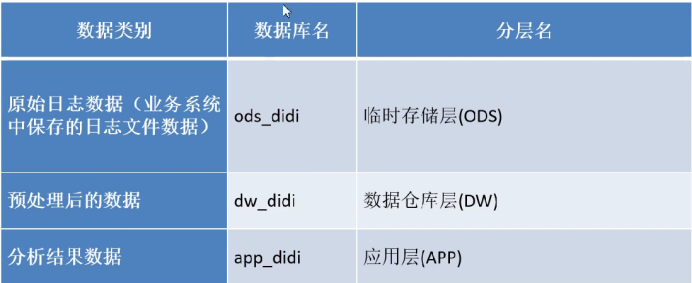
同时建立分区字段,按照不同时间进行管理
四、dw层数据的获取
(我们这里只针对一个表进行加工,后续其他表还使用ods层)

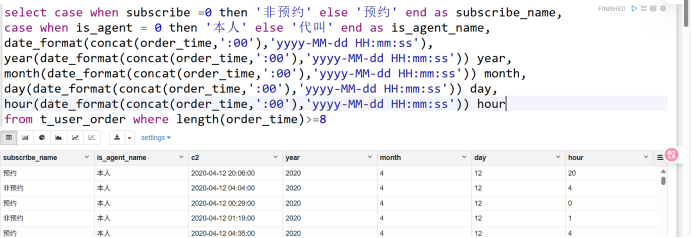
函数:length()--- case when --- concat ---date_format(这个函数不是谁都可以用,具体我也不清楚,反正mysql里没有) --- year --- month --- day
select case when subscribe =0 then '非预约' else '预约' end as subscribe_name,
case when is_agent = 0 then '本人' else '代叫' end as is_agent_name,
date_format(concat(order_time,':00'),'yyyy-MM-dd HH:mm:ss')
from t_user_order where length(order_time)>=8;
注意这里提取年月日不能用你现计算的字段,这是 常出现的错误
最后插入数据的时候:
Insert overwrite dw_didi.t_user_order_wide partition(dt=...)
...
五、指标分析
1.总订单个数:
select count(1) as total_num from dw_didi.t_user_order_wide
where dt=‘2020-04-12’;(查询)(分区字段是在where里选择的)
2.预约订单和非预约订单占比:

这是横向数据,也可以用union all获得纵向数据
3.按时间段统计订单个数:
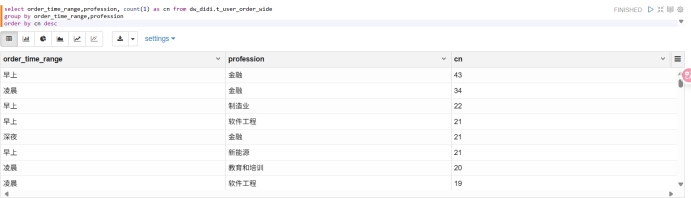
4.不同时间段不同年龄段结合分析统计订单个数:
select age_range ,order_time_range ,count(1) as cn2
from dw_didi.t_user_order_wide
group by age_range,order_time_range;
5、不同地区订单占比:
select province, city, count(*) as order_cnt
from dw_didi.t_user_order_wide
group by province,city;
6.不同职业订单量top5:
select * from(
select *, row_number() over(order by cn desc)row1 from
(select profession, count(1)as cn from dw_didi.t_user_order_wide group by profession)t1
)t2 where t2.row1<=5;
我这里只是特意使用了开窗函数,实际方法有很多
7.用户取消的订单占比:
和预约非预约一样
六、把数据通过sqoop导入到mysql数据库
模板:
/export/server/sqoop-1.4.7/bin/sqoop export \
--connect jdbc:mysql://192.168.88.100:3306/app_didi \
--username root \
--password 123456 \
--table t_order_total \
--export-dir /user/hive/warehouse/app_didi.db/t_order_total/month=2020-04
使用时只需要修改参数
七、可视化
可视化就没啥好说了吧,给图
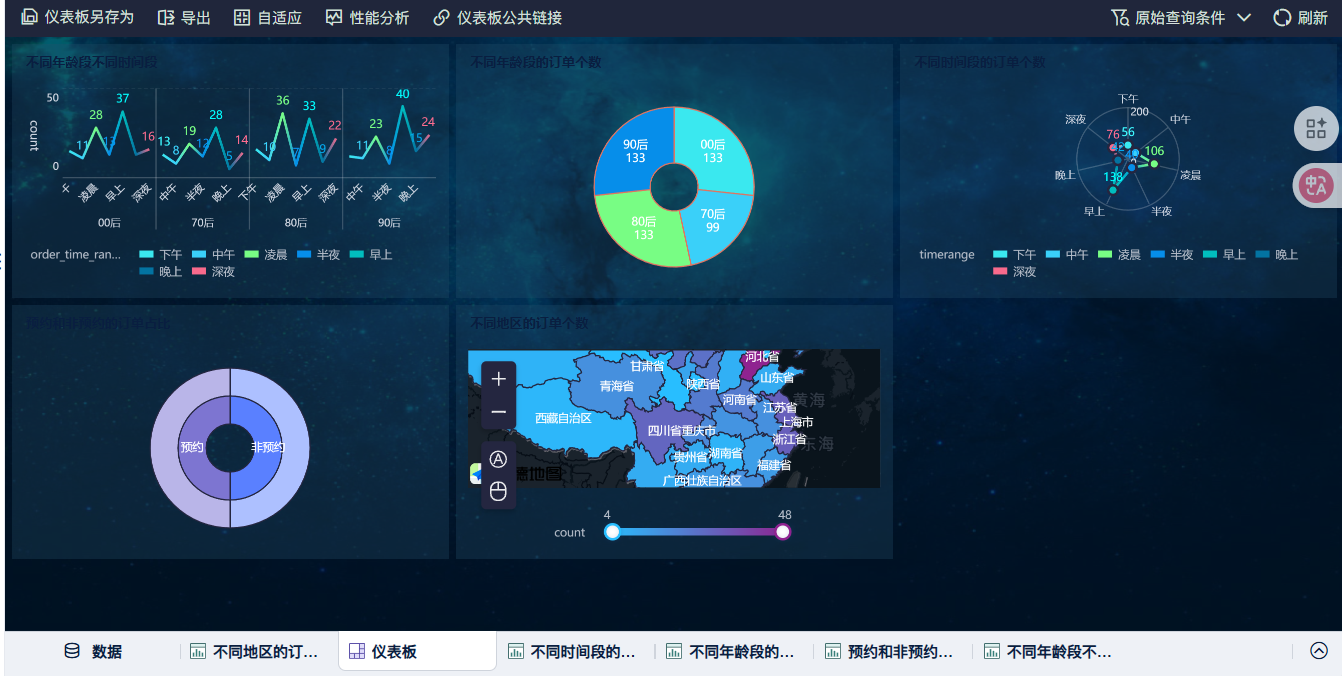
最后奉上源码,前面的只是介绍一下

















 1752
1752




 到【灌水乐园】发言
到【灌水乐园】发言







