



1.导入相关库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib.pyplot import errorbar
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
2.导入数据
#导入数据
df_2=pd.read_csv('(sample)sam_tianchi_mum_baby_trade_history.csv')
df_2.head()
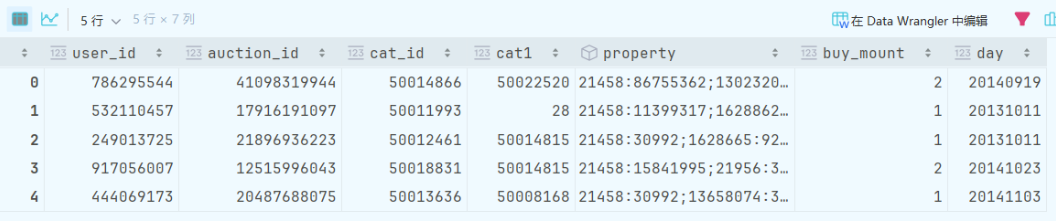 df_2.info()
df_2.info()
 df_2.dexcribe()
df_2.dexcribe()
🍎除了buy_mount和day,其他的都是使用序号代表商品
3.清洗数据
①查看缺失值并处理
df_2.isnull().sum()
df_2.fillna(0,inplace=True)
②查看重复值并处理
df_2.duplicated.sum()
//没有重复值
③删除无用的列,修改列名属性
df_2.drop(columns='property',inplace=True)
df_2.rename(columns={'auction_id':'item_id'},inplace=True)
④清理异常值
df_2=df_2[(df_2['buy_mount']<=195)&(df_2['buy_mount']>=1)]
⑤改变日期格式
#最常用的就是先转化为字符串格式
df_2['day']=pd.to_datetime(df_2['day'].astype(str))
df_2['year']=df_2['day'].dt.year
df_2['month']=df_2['day'].dt.month
df_2['quarter']=df_2['day'].dt.quarter
4.数据分析与画图
①根据年月查看销量趋势
temp1=df_2.groupby(['year','month'])['buy_mount'].sum().reset_index()
//也可以使用数据透视表--字段后续不好处理
temp2=df_2.pivot_table(index='year',columns='month',values='buy_mount',aggfunc='sum')
//进入画图
plt.figure(figsize(5,3))
sns.barplot(x='year',y='buy_mount',data=temp1)
plt.title('按照年份统计销量')

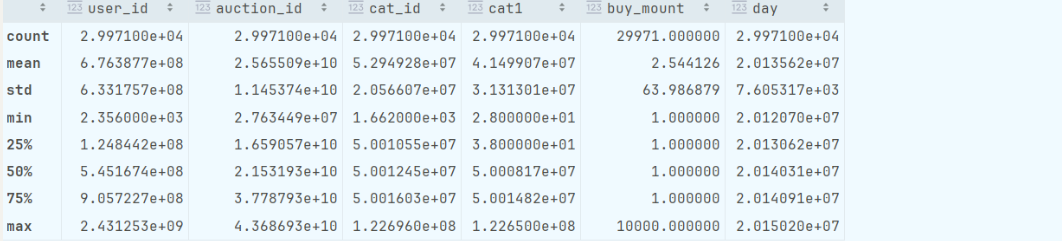
对最高年份进行发掘
ans=temp1.loc[temp1['year']==2014]
plt.figure(figsize=(5,3))
sns.barplot(x='month',y='buy_mount',data=ans)
plt.title('2014年销量分析')
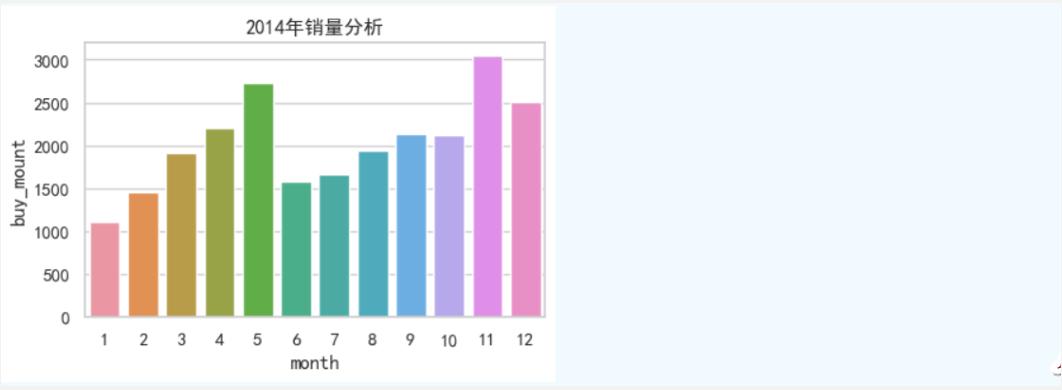
②探寻一二月销量下降的原因
#探索1-2月销量下滑主要原因
plt.figure(figsize=(12, 7))
sns.lineplot(x='month', y='buy_mount', hue='year', data=temp1, palette='viridis')
plt.title('各年月度总销量对比')
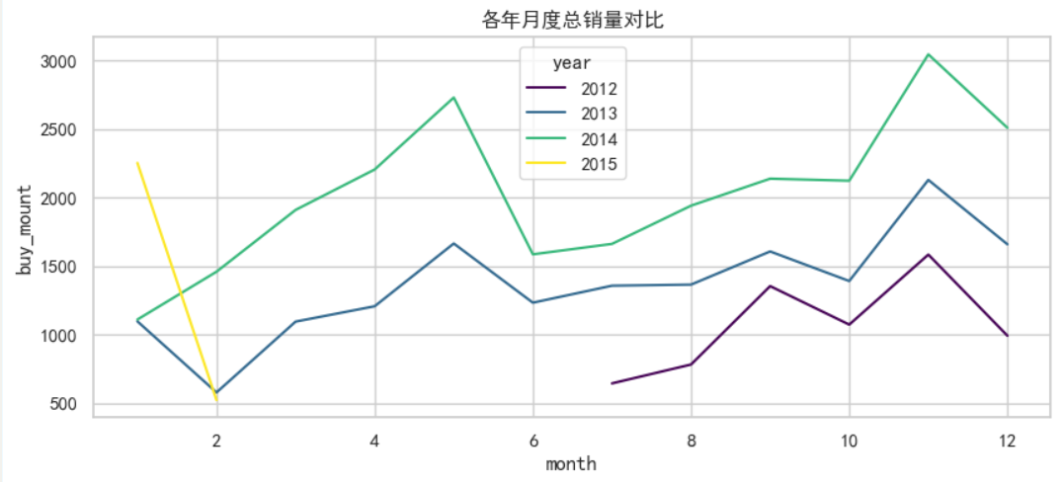
猜测是因为春节假期
1️⃣导入节假日的日期,使用字典的格式对应年份
cny_eve_dates={
2013:pd.to_datetime('2013-02-09'),
2014:pd.to_datetime('2014-01-30')
}
2️⃣定义函数,计算距离除夕的天数,并打上标签
🍎计划通过这个函数,添加两列数据,一列是标签,一列是相差的天数
🍎两个时间戳相减得到一个时间差类型
#定义函数
def analyze_cny(row):
year=row.year
if year in cny_eve_dates:
#通过字典获取具体日期
eve_date=cny_eve_dates[year]
delta=row-eve_date
#定义标签
period_tag='常规'
if -14<=delta<0:
period_tag='节前'
elif 0<=delta<=6:
period_tag='节中'
elif 7<=delta<=21:
period_tag='节后'
return pd.Series([delta,period_tag])
return pd.Series([None,period_tag])
df_2[['delta',eve']]=df_2['day'].apply(analyze_cny)
3️⃣筛选春节前后一个月的数据进行画图
eve_date=df_2[df_2['delta'].between(-14,21)].copy()
#画图
sns.set_theme(style='whitegrid')
plt.figure(figsize=(12,6))
sns.lineplot(data=eve_day,x='delta',y='buy_mount',hue='year',palette='tab10') #一种配色方案
plt.title('春节前后的销量分析',fontproperties='SimHei')
plt.xlabel('举例除夕的天数',fontproperties='SimHei')
plt.ylabel('销量',fontproperties='SimHei')
plt.grid(True) #添加网格线
plt.show()
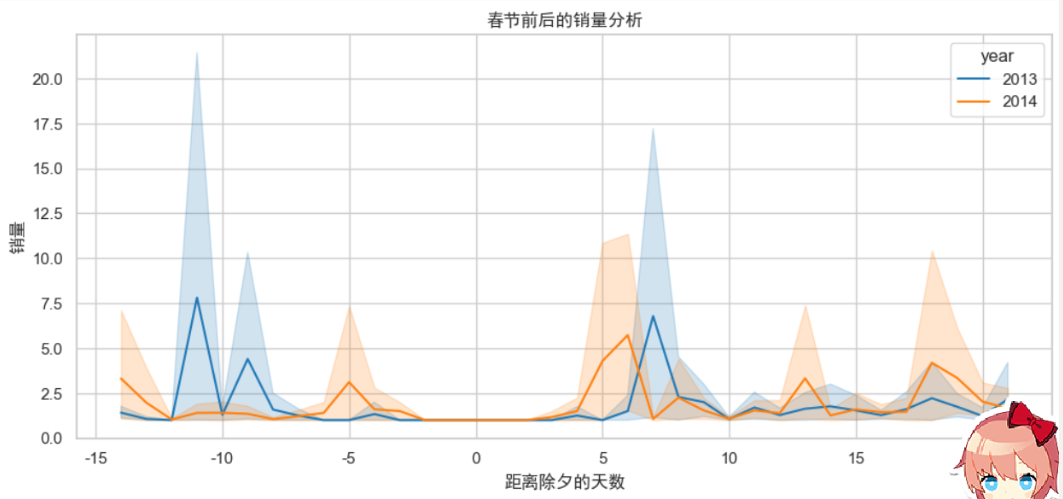
得出结论:
临近春节可能存在部分企业提早放假,快递停运,销售低谷时段与春节假期基本吻合,假期结束后购买量和用户量上升,所以可以认为第一季度销量下降是由春节假期造成的
③计算复购率
🍎按用户计算:在特定时间段内,购买超过一次的用户占总购买用户的比例--这是常用的
1️⃣筛选所需的数据
"""
筛选出某一年的所有购买记录。
统计在每个月里,每个用户 (user_id) 购买了多少次。
计算购买次数 > 1 的用户数(复购用户数)。
计算总的购买用户数。
用 复购用户数 / 总购买用户数 得到复购率。
"""
data_i=df_2[df_2['year'].isin([2013,2014])].copy()
2️⃣对用户进行年月分组,并统计次数
🍎nunique--统计不重复出现次数
data_tag=data_i.groupby(['year','month'])['user_id'].agg(
total_num='nunique',
tag_num=month
).reset_index()
"""
这里的 ['user_id'] 只是指定“我要对 user_id 这一列做聚合”。
但是 .agg() 允许你 同时定义多个聚合计算,并且给它们取名字,所以虽然输入只有 user_id,输出却能有多列(total_num、tag_num)
"""
3️⃣定义函数统计每个月的重复购买的用户
#使用函数对每个月进行独立计算
def month(id):
counts=id.value_counts()
return(counts>1).sum()
4️⃣计算复购率
data_tag['rate']=data_tag['tag_num']/data_tag['total_num']
#可以对year和month联系起来
data_tag['year_month']=data_tag['year'].astype(str)+'-'+data_tag['month'].astype(str)
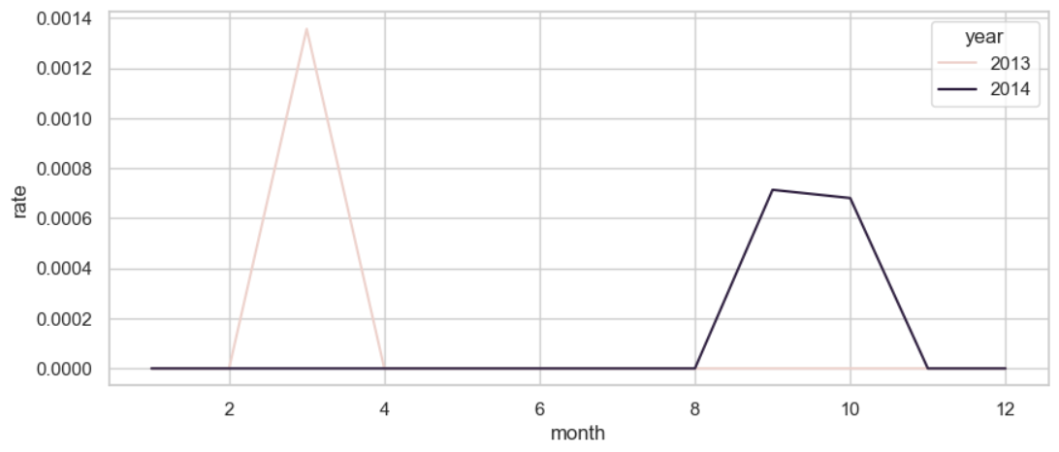
5️⃣画图
#画图
plt.figure(figsize=(10, 4))
sns.set_theme(style="whitegrid") #创建主题--白背景,灰网格
sns.lineplot(data=data_tag,x='month',y='rate',hue='year')
plt.grid(True)
plt.show()

















 2309
2309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









