



一、引言:
1.1语言模型的发展历程:
- 统计语言模型(SLM):统计语言模型使用马尔科夫假设建立语言序列的预测模型,通常是根据词序列中若干个连续的上下文单词来预测下一个词的出现概率,即根据一个固定长度的前缀俩预测目标单词。其被广泛应用于信息检索(IR)和自然语言处理(NLP)等领域。
- 神经语言模型(NLM):神经语言模型使用神经网络来建模文本序列的生成,如循环神经网络(RNN)
- 预训练语言模型(PLM):与早期的词嵌入式模型相比,预训练语言模型在训练架构与训练数据两个方面进行了改进与创新。但是对于早期的预训练语言模型来说,传统的序列神经网络的长文本建模能力较弱,大大的限制了与训练语言模型(如ELMo)的性能。
- 大语言模型(LLM):大语言模型是大型与训练语言模型模型。考虑到通过规模扩展(如增加模型参数规模或数据规模)通常会带来下游任务的模型性能提升(这种现象通常被成为“扩展法则”)。与传统的小模型相比,大语言模型具有一些小模型不具有的能力,通常被称为“涌现能力”。
回顾以上历程可以看出,早期的语言模型主要面向自然语言的建模和生成任务,而最新的语言模型(如GPT-4)则侧重于复杂任务的求解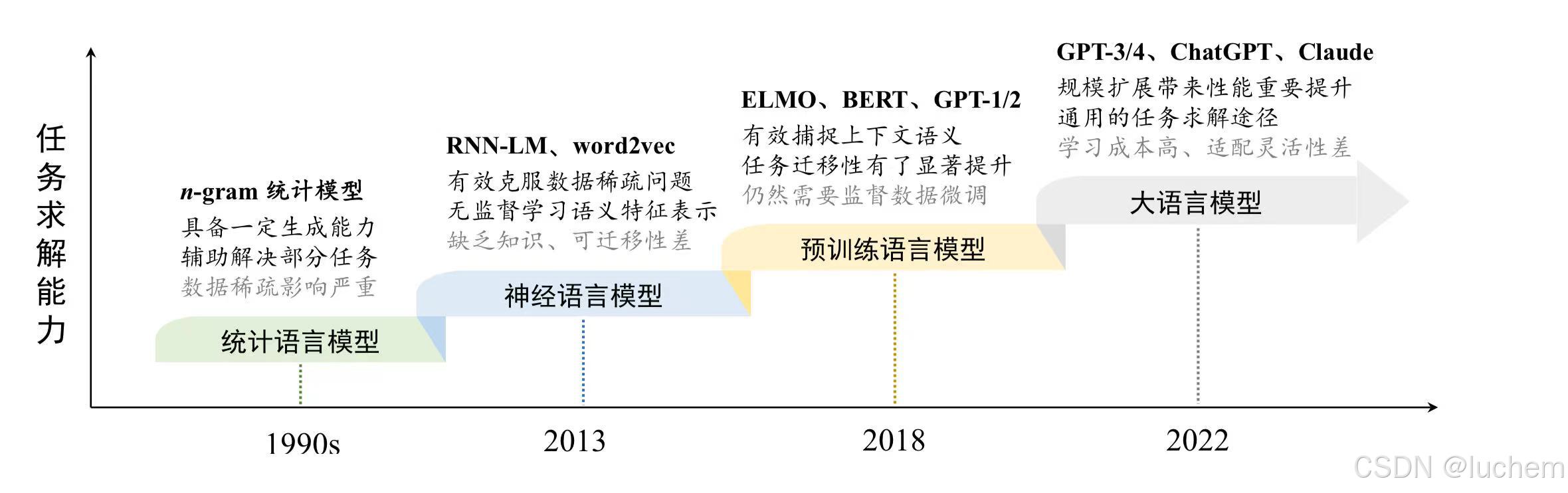
1.2大语言模型的能力特点
- 具有较为丰富的世界知识:大模型语言经过超大规模文本数据预训练后能够学习到较为丰富的世界知识。最早可以追溯到到专家系统。
- 具有较强的通用任务解决能力:大语言模型主要通过预测下一个词元的预训练任务进行学习,虽然并没有针对特定的下游任务进行优化,却能够建立远强于传统模型的通用任务求解能力。
- 具有较好的复杂任务推理能力:大语言模型能够回答知识关系复杂的推理问题,还可以解决涉及复杂数学推理过程的数学题目。
- 具有较强的人类指令遵循能力:大语言模型建立了自然语言形式的统一任务解决模式:任务输入与执行结果均通过自然语言进行表达。通过预训练与微调两个阶段的学习,大语言模型具备了较好的人类指令遵循能力,能够直接通过自然语言描述下达任务指令(又称为“提示学习”)。
- 具有较好的人类对齐能力:目前广泛采用的对齐方式是基于人类反馈的强化学习技术,通过强化学习使得模型进行正确行为的加强以及错误行为的规避,进而建立较好的人类对齐能力。
- 具有可拓展的工具使用能力:工具的有效使用对于模型的任务理解能力和推理能力有着较高的要求,因此传统模型以及没有经过特殊微调的大语言模型往往不能很好地使用丰富的工具库。
1.3大语言模型关键技术概览
- 规模扩展:规模扩展是大语言模型的一个关键成功因素。在较早期的研究中,OpenAI 从参数、数据、算力三个方面深入地研究了规模扩展对于模型性能所带来的影响,建立了定量的函数关系,称之为“扩展法则”(Scaling Law)。
- 数据工程:当前大语言模型的技术路线图就是通过在海量文本上进行下一个词预测的优化,使得模型能够学习到丰富的语义知识信息,进而通过文本补全的方式解决各种下游任务。
- 高效预训练:大模型的训练极具挑战性,由于参数规模巨大,需要使用大规模分布式训练算法优化大语言模型的神经网络参数。在训练过程中,需要联合使用各种并行策略以及效率优化方法,包括3D 并行(数据并行、流水线并行、张量并行)、ZeRO(内存冗余消除技术)等。
- 能力激发:为了提升模型的任务求解能力,需要设计合适的指令微调以及提示策略进行激发或诱导。在指令微调方面,可以使用自然语言表达的任务描述以及期望的任务输出对于大语言模型进行指令微调,从而增强大语言模型的通用任务求解能力,提升模型在未见任务上的泛化能力。
- 人类对齐:互联网上开放的无标注文本数据的内容覆盖范围较广,可能包含低质量、个人隐私、事实错误的数据信息。因此,经过海量无标注文本预训练的大语言模型可能会生成有偏见、泄露隐私甚至对人类有害的内容。在实践应用中,需要保证大语言模型能够较好地符合人类的价值观。目前,比较具有代表性的对齐标准是“3 H 对齐标准”,即Helpfulness(有用性)、Honesty(诚实性)和Harmlessness(无害性)。
- 工具使用:工具学习成为一种扩展大语言模型能力的关键技术,通过让大语言模型学会使用各种工具的调用方式,进而利用合适的工具去实现特定的功能需求。
尽管大语言模型技术已经取得了显著进展,但是对于它的基本原理仍然缺乏
深入的探索,很多方面还存在局限性或者提升空间。
1.4大语言模型对于科技发展的影响
大语言模型真正令我们震撼的地方是,它与小型预训练语言模型采用了相似的网络架构以及训练方法,但通过扩展模型参数规模、数据数量以及算力资源,却带来了令人意料之外的模型性能跃升。大语言模型首次实现了单一模型可以有效解决众多复杂任务,人工智能算法从未如此强大。
- 自然语言处理:在自然语言处理领域,大语言模型可以作为一种通用的语言任务解决技术,能够通过特定的提示方式解决不同类型的任务,并且能够取得较为领先的效果。
- 信息检索:在信息检索领域,传统搜索引擎受到了人工智能信息助手(即ChatGPT)这一新型信息获取方式的冲击。在基于大语言模型的信息系统中,人们可以通过自然语言对话的形式获得复杂问题的答案。
- 计算机视觉:在计算机视觉领域,研究人员为了更好地解决跨模态或多模态任务,正着力研发类ChatGPT 的视觉-语言联合对话模型,GPT-4 已经能够支持图文多模态信息的输入。
- 人工智能赋能的科学研究(AI4Science):近年来,AI4Science 受到了学术界的广泛关注,目前大语言模型技术已经广泛应用于数学、化学、物理、生物等多个领域,基于其强大的模型能力赋能科学研究。
除了在特定学科领域的应用,大语言模型对于整体的科研范式也正产生着重要影响。为了有效提升大模型的性能,研究人员需要深入了解大模型相关的工程技术,对于理论与实践的结合提出了更高的需求。
此外,大语言模型对于产业应用带来了变革性的技术影响,将会催生一个基于大语言模型的应用生态系统。例如微软365的Copilot、OpenAI的Agent研发。
二、基础介绍
大语言模型是指在海量无标注文本数据上进行预训练得到的大型预训练语言模型,例如GPT-3,PaLM和LLaMA ,但目前对于大语言模型的训练的最小参数规模还没有一个明确的参考标准。
2.1大语言模型的构建过程
从机器学习的观点来说,神经网络是一种具有特定模型结构的函数形式,而大语言模型则是一种基于Transformer 结构的神经网络模型。因此,可以将大语言模型看作一种拥有大规模参数的函数,它的构建过程就是使用训练数据对于模型参数的拟合过程。尽管所采用的训练方法与传统的机器学习模型(如多元线性回归模型的训练)可能存在不同,但是本质上都是在做模型参数的优化。与传统的机器学习模型相比,大语言模型的构建过程需要更为复杂、精细的训练方法。一般来说,这个训练过程可以分为大规模预训练和指令微调与人类对齐两个阶段
2.1.1大规模预训练
一般来说,预训练是指使用与下游任务无关的大规模数据进行模型参数的初始训练,可以认为是为模型参数找到一个较好的“初值点”。早期的预训练技术还是聚焦于解决下游某一类的特定任务,如传统的自然语言处理任务。
为了预训练大语言模型,需要准备大规模的文本数据,并且进行严格的清洗,去除掉可能包含有毒有害的内容,最后将清洗后的数据进行词元化(Tokenization)流,并且切分成批次(Batch),用于大语言模型的预训练。由于大语言模型的能力基础主要来源于预训练数据,因此数据的收集与清洗对于模型性能具有重要的影响。收集高质量、多源化的数据以及对于数据进行严格的清洗是构建大语言模型关键能力的重中之重,需要大模型研发人员的高度关注。
尽管整体的预训练技术框架非常直观,但是实施过程中涉及到大量需要深入探索的经验性技术,如数据如何进行配比、如何进行学习率的调整、如何早期发现模型的异常行为等。
2.1.2指令微调与人类对齐
经过大规模数据预训练后的语言模型已经具备较强的模型能力,能够编码丰富的世界知识,但是由于预训练任务形式所限,这些模型更擅长于文本补全,并不适合直接解决具体的任务。尽管可以通过上下文学习(In-Context Learning, ICL)等提示学习技术进行适配,但是模型自身对于任务的感知与解决能力仍然较为局限。
目前来说,比较广泛使用的微调技术是“指令微调”(也叫做有监督微调,Supervised Fine-tuning, SFT),通过使用任务输入与输出的配对数据进行模型训练,可以使得语言模型较好地掌握通过问答形式进行任务求解的能力。这种模仿示例数据进行学习的过程本质属于机器学习中的模仿学习(Imitation Learning)。但需要注意的一点是,模仿学习旨在加强对于标准答案(即师傅的示范动作)的复刻学习,而非学习新的知识。
除了提升任务的解决能力外,还需要将大语言模型与人类的期望、需求以及价值观对(Alignment),这对于大模型的部署与应用具有重要的意义。OpenAI在2022年引入了基于人类反馈的强化学习对齐方法RLHF(Reinforcement Learning from Human Feedback),在指令微调后使用强化学习加强模型的对齐能力。在RLHF 算法中,需要训练一个符合人类价值观的奖励模型
(Reward Model)。为此,需要标注人员针对大语言模型所生成的多条输出进行偏好排序,并使用偏好数据训练奖励模型,用于判断模型的输出质量。由于强化学习需要维护更多的辅助模型进行训练,通常来说对于资源的消耗会多于指令微调,但是也远小于预训练阶段所需要的算力资源。
经历上述两个过程后,大语言模型就能够具备较好的人机交互能力,通过问答形式解决人类所提出的问题。这个构建过程需要大量的算力资源支持,也需要具有良好洞察力和训练经验的研发人员进行相关技术路线的设计与执行。因此,实现具有ChatGPT 或者GPT-4 能力的大语言模型绝非易事,需要进行深入的探索与实践。
2.2扩展法则
大语言模型获得成功的关键在于对“规模扩展”(Scaling)的充分探索与利用。在实现上,大语言模型采用了与小型预训练语言模型相似的神经网络结构(基于注意力机制的Transformer 架构)和预训练方法(如语言建模)。但是通过扩展参数规模、数据规模和计算算力,大语言模型的能力显著超越了小型语言模型的能力。
2.2.1KM扩展法则
2020 年,Kaplan 等人(OpenAI 团队)首次建立了神经语言模型性能与三个主要因素——模型规模(𝑁)、数据规模(𝐷)和计算算力(𝐶)之间的幂律关系(Power-Law Relationship)。即在给定算力预算𝑐的条件下,可以近似得到以下三个基本指数公式来描述扩展法则:
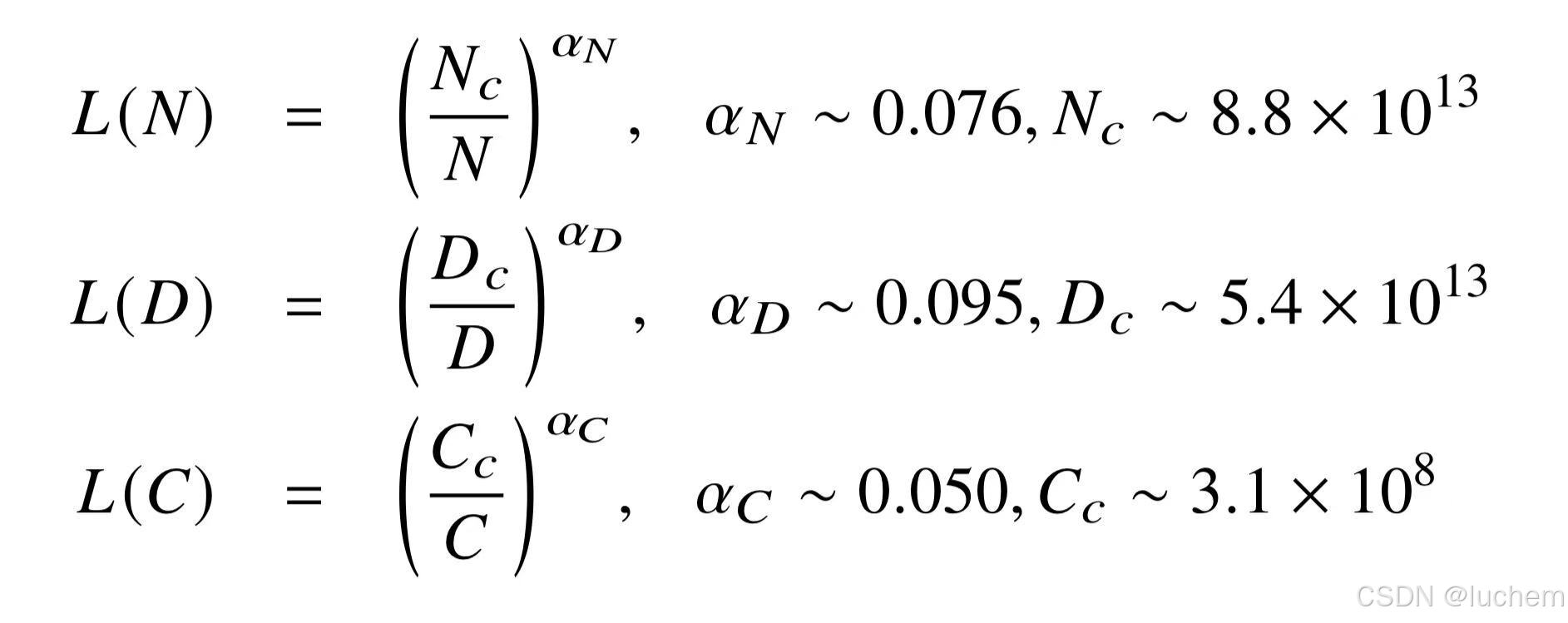
这三个公式是通过模型在不同数据规模(22M 到23B 词元)、模型规模(768M到1.5B 非嵌入参数)和算力规模下的性能表现拟合推导得到的。为了推导这些公式,需要约定一些基本假设:一个因素的分析不会受到其他两个因素的限制,如当变动模型参数规模的时候,需要保证数据资源是充足的。
由以上公式可见,模型性能与这三个因素之间存在着较强的依赖关系,可以近似刻画为指数关系。
为了便于理解扩展法则对于模型性能的影响,OpenAI 的研究团队又将这里的损失函数进一步分解为两部分,包括不可约损失(真实数据分布的熵)和可约损失(真实分布和模型分布之间KL 散度的估计):

这里𝑥是一个占位符号,可以指代第一个公式中的𝑁、𝐷和𝐶。其中,不可约损失由数据自身特征确定,无法通过扩展法则或者优化算法进行约减;模型性能的优化只能减小可约损失部分。
2.2.2Chinchilla扩展法则
Hoffmann 等人(DeepMind 团队)于2022 年提出了一种可选的扩展法则,旨在指导大语言模型充分利用给定的算力资源进行优化训练。研究人员拟合得到了另一种关于模型性能的幂律关系:
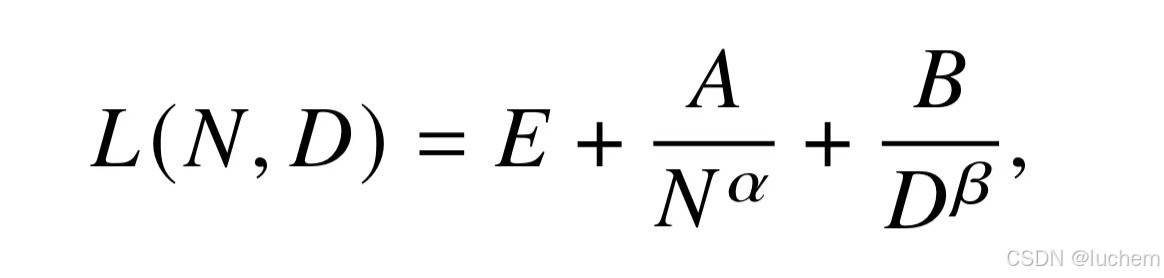
其中𝐸= 1.69,𝐴= 406.4,𝐵= 410.7,𝛼= 0.34 和𝛽= 0.28。进一步,利用约束条件𝐶 ≈6𝑁𝐷对于损失函数𝐿(𝑁,𝐷)进行推导,能够获得算力资源固定情况下模型规模与数据规模的最优分配方案(如下所示):
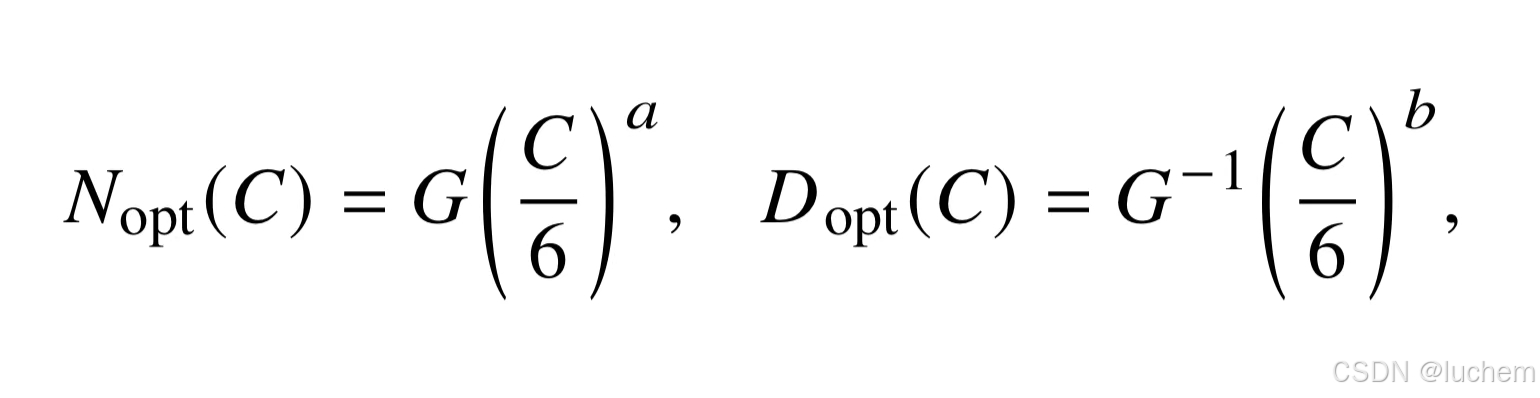
进一步,研究人员发现KM 扩展法则和Chinchilla 扩展法则都可以近似表示成上述算力为核心的公式(公式2.4):
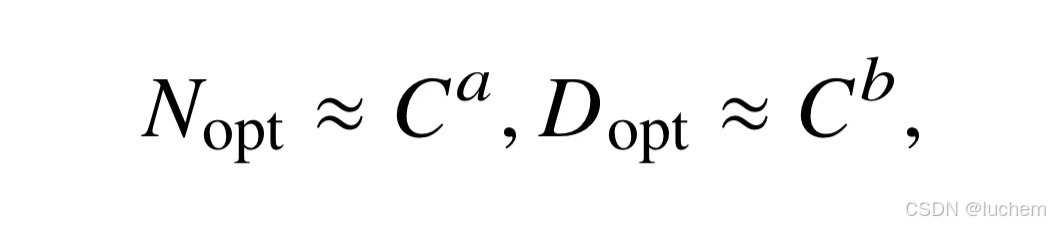
即当算力𝐶给定的情况下,最优的模型参数规模和数据规模由指数系数𝑎和𝑏分别确定。可以看到,𝑎和𝑏决定了参数规模和数据规模的资源分配优先级:当𝑎 >𝑏时,应该用更多的算力去提高参数规模;当𝑏 > 𝑎时,应该用更多的算力去提高数据规模。
2.2.3关于扩展法则的讨论
综上所述,我们围绕可预测的扩展以及任务层面的可预测性展开深入讨论。
- 可预测的扩展 (Predictable Scaling):在实践中,扩展法则可以用于指导大语言模型的训练,通过较小算力资源可靠地估计较大算力资源投入后的模型性能,这被称为可预测的扩展。可预测扩展对于大模型训练具有两个主要的指导作用。首先,对于大语言模型来说,详细进行各种训练技巧或变体的测试需要耗费巨大的算力资源。因此,一个较为理想的经验性方法是,基于小模型获得训练经验然后应用于大模型的训练,从而减少实验成本。其次,大语言模型的训练过程较长,经常面临着训练损失波动情况,扩展法则可以用于监控大语言模型的训练状态,如在早期识别异常性能。
- 任务层面的可预测性:现有关于扩展法则的研究大多数是基于语言建模损失开展的,例如预测下一个词元的平均交叉熵损失,这一度量本身是平滑的,是对于模型整体能力的宏观度量。整体上来说,语言建模损失较小的模型往往在下游任务中表现更好,因为语言建模的能力可以被认为是一种模型整体能力的综合度量。然而,语言建模损失的减少并不总是意味着模型在下游任务上的性能改善。对于某些特殊任务,甚至会出现“逆向扩展”(Inverse Scaling)现象,即随着语言建模损失的降低,任务性能却出人意料地变差。
2.3涌现能力
根据现有的文献,大语言模型的涌现能力被非形式化定义为“在小型模型中不存在但在大模型中出现的能力”,具体是指当模型扩展到一定规模时,模型的特定任务性能突然出现显著跃升的趋势,远超过随机水平。
2.3.1代表性的涌现能力
尽管涌现能力可以定义为解决某些复杂任务的能力水平,但我们更关注可以用来解决各种任务的普适能力。
- 上下文学习(In-context Learning,ICL):在提示中为语言模型提供自然语言指令和多个任务示例(Demonstration),无需显式的训练或梯更新,仅输入文本的单词序列就能为测试样本生成预期的输出。
- 指令遵循(Instruction Following):指令遵循能力是指大语言模型能够按照自然语言指令来执行对应的任务。为了获得这一能力,通常需要使用自然语言描述的多任务示例数据集进行微调,称为指令微调(Instruction Tuning)或监督微调(Supervised Fine-tuning)。通过指令微调,大语言模型可以在没有使用显式示例的情况下按照任务指令完成新任务,有效提升了模型的泛化能力。
- 逐步推理(Step-by-step Reasoning):大语言模型可以在提示中引入任务相关的中间推理步骤来加强复杂任务的求解,从而获得更为可靠的答案。
通常来说,很难统一界定大语言模型出现这些上述能力的临界规模(即具备某种能力的最小规模),因为能力涌现会受到多种因素或者任务设置的影响。
2.3.2涌现能力与扩展法则的关系
扩展法则和涌现能力提供了两种不同观点来理解大模型相对于小模型的优势,但是刻画了较为不同的扩展效应趋势。扩展法则使用语言建模损失来衡量语言模型的整体性能,整体上展现出了较为平滑的性能提升趋势,具有较好的可预测性,但是指数形式暗示着可能存在的边际效益递减现象;而涌现能力通常使用任务性能来衡量模型性能,整体上展现出随规模扩展的骤然跃升趋势,不具有可预测性,但是一旦出现涌现能力则意味着模型性能将会产生大幅跃升。但目前还缺少对于大语言模型涌现机理的基础性解释研究工作。
2.4GPT系列模型的技术演变
GPT 系列模型的基本原理是训练模型学习恢复预训练文本数据,将广泛的世界知识压缩到仅包含解码器(Decoder-Only)的Transformer 模型中,从而使模型能够学习获得较为全面的能力。其中,两个关键要素是:(I)训练能够准确预测下一个词的Transformer (只包含解码器)语言模型;(II)扩展语言模型的规模以及扩展预训练数据的规模。截止到目前,OpenAI 对大语言模型的研发历程大致可分为四个阶段:早期探索阶段、路线确立阶段、能力增强阶段以及能力跃升阶段。
2.4.1早期探索
- GPT-1 基于生成式、仅有解码器的Transformer架构开发,奠定了GPT 系列模型的核心架构与基于自然语言文本的预训练方式,即预测下一个词元。
- GPT-2 沿用了GPT-1 的类似架构,将参数规模扩大到1.5B,并使用大规模网页数据集WebText 进行预训练。与GPT-1 不同,GPT-2 旨在探索通过扩大模型参数规模来提升模型性能,并且尝试去除针对特定任务所需要的微调环节。
2.4.2规模扩展
- 在GPT-2 基础上,GPT-3 针对(几乎相同的)模型参数规模进行了大幅扩展,在下游任务中初步展现出了一定的通用性(通过上下文学习技术适配下游任务),为后续打造更为强大的模型确立了关键的技术发展路线。与GPT-2 相比,GPT-3 直接将参数规模提升了100 余倍,对于模型扩展在当时给出了一个极限尝试,其雄心、魄力可见一斑。在GPT-3 的论文中,它正式提出了“上下文学习”这一概念,使得大语言模型可以通过少样本学习的方式来解决各种任务。上下文学习可以指导大语言模型学会“理解”自然语言文本形式描述的新任务,从而消除了针对新任务进行微调的需要。基于这一学习范式,大语言模型的训练与利用可以通过语言建模的形式进行统一描述:模型预训练是在给定上下文条件下预测后续文本序列,模型使用则是根据任务描述以及示例数据来推理正确的任务解决方案。GPT-3 可以被看作从预训练语言模型到大语言模型演进过程中的一个重要里程碑,它证明了将神经网络扩展到超大规模可以带来大幅的模型性能提升,并且建立了以提示学习方法为基础技术路线的任务求解范式。
2.4.3能力增强
OpenAI 探索了两种主要途径来改进GPT-3 模型,即代码数据训练和人类偏好对齐。
- 代码数据训练:原始的GPT-3 模型的复杂推理任务能力仍然较弱,如对于编程问题和数学问题的求解效果不好。为了解决这一问题,OpenAI 于2021 年7 月推出了Codex ,这是一个在大量GitHub 代码数据集合上微调的GPT 模型。
- 人类对齐:2022 年1 月,OpenAI 正式推出InstructGPT 这一具有重要影响力的学术工作,旨在改进GPT-3 模型与人类对齐的能力,正式建立了基于人类反馈的强化学习算法,即RLHF 算法。
2.4.4性能跃升
在历经上述近五年的重要探索,OpenAI 自2022 年底开始发布了一系列重要的技术升级,其中具有代表性的模型是ChatGPT、GPT-4 以及GPT-4V/GPT-4 Turbo,这些模型极大提高了现有人工智能系统的能力水平,成为了大模型发展历程中的重要里程碑。
- ChatGPT:2022 年11 月,OpenAI 发布了基于GPT 模型的人工智能对话应用
服务ChatGPT。 - GPT-4:继ChatGPT 后,OpenAI 于2023 年3 月发布了GPT-4 ,它首次将GPT 系列模型的输入由单一文本模态扩展到了图文双模态。总体来说,GPT-4 在解决复杂任务方面的能力显著强于GPT-3.5,在一系列面向人类的考试中都获得了非常优异的结果。GPT-4 搭建了完备的深度学习训练基础架构,进一步引入了可预测扩展的训练机制,可以在模型训练过程中通过较少计算开销来准确预测模型的最终性能。
- GPT-4V、GPT-4 Turbo以及多模态支持模型:在2023 年11 月,OpenAI 在开发者大会上发布了升级版的GPT-4 模型,称为GPT-4 Turbo,引入了一系列技术升级:提升了模型的整体能力(比GPT-4 更强大),扩展了知识来源(拓展到2023 年4 月),支持更长上下文窗口(达到128K),优化了模型性能(价格更便宜),引入了若干新的功能(如函数调用、可重复输出
等)。
尽管GPT 系列模型取得了巨大的科研进展,这些最前沿的大语言模型仍然存
在一定的局限性。
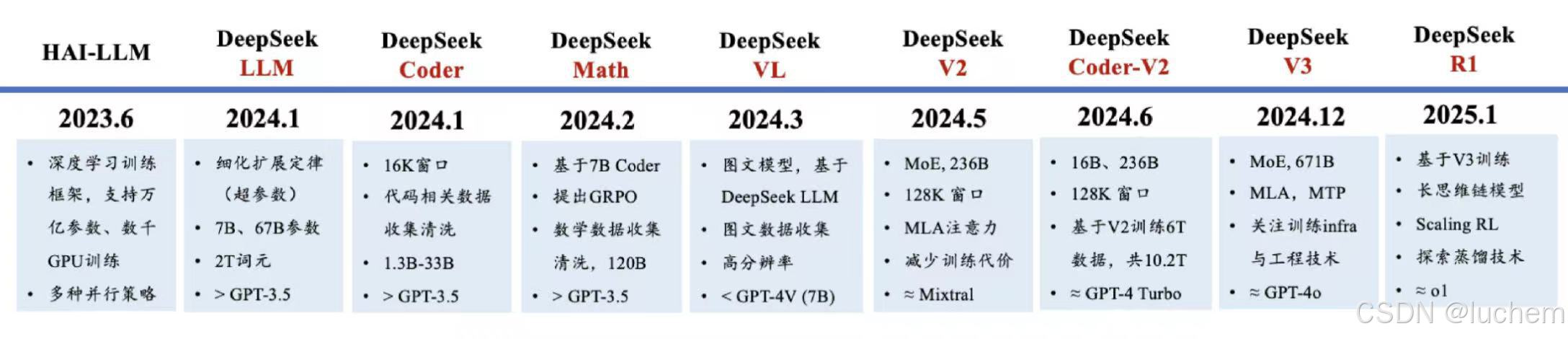
2.5DeepSeek系列模型的技术演变
- 训练框架:HAI-LLM:大规模深度学习训练框架,支持多种并行策略
- 语言模型:DeepSeek LLM/V2/V3、Coder/Coder-V2、Math
- 多模态大模型:DeepSeek-VL
- 推理大模型:DeepSeek- R1
2.5.1训练框架与数据准备
- V1和math的报告表明清晰了大规模Common Crawl,具备超大规模的数据处理能力
- Coder的技术报告表明收集了大量的代码数据
- Math的技术报告表明清洗收集了大量的数学数据
- VL的技术报告表明清洗收集了大量多模态、图片数据
2.5.2网络架构、训练算法、性能优化探索
- V1探索了scaling law分析(考虑了数据质量的影响),用于估计超参数性能
- V2突出了MLA高效注意力机制,提升推理性能
- V2、V3都针对MoE架构提出了相关稳定性训练策略
- V3使用了MTP(多token预测)训练
- Math提出了PPO的改进算法GRPO
- V3详细介绍了Infrastructure的搭建方法、并提出了高效的FP8训练方法
五、模型架构
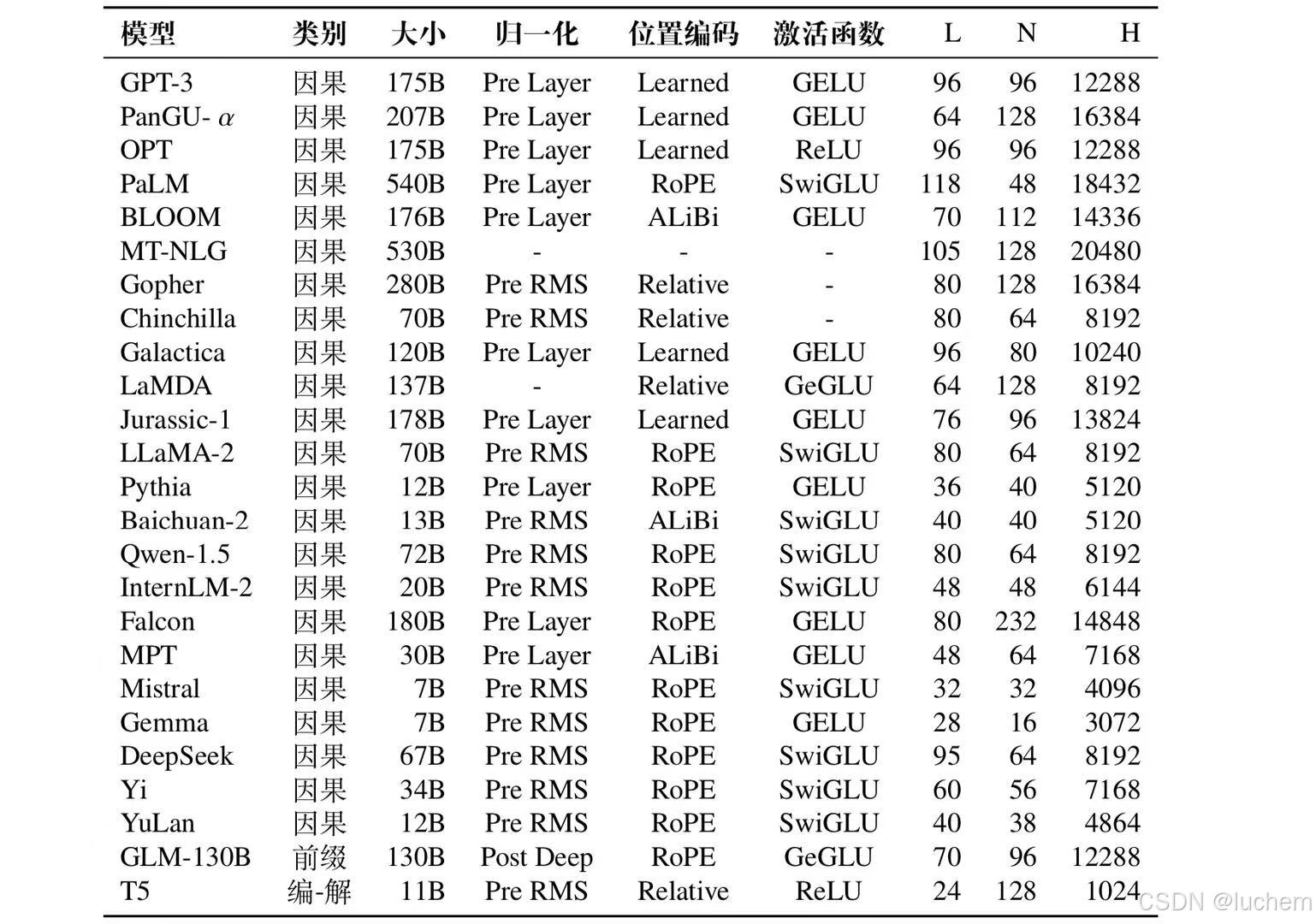
一些大语言模型的详细配置:
5.1Transformer模型
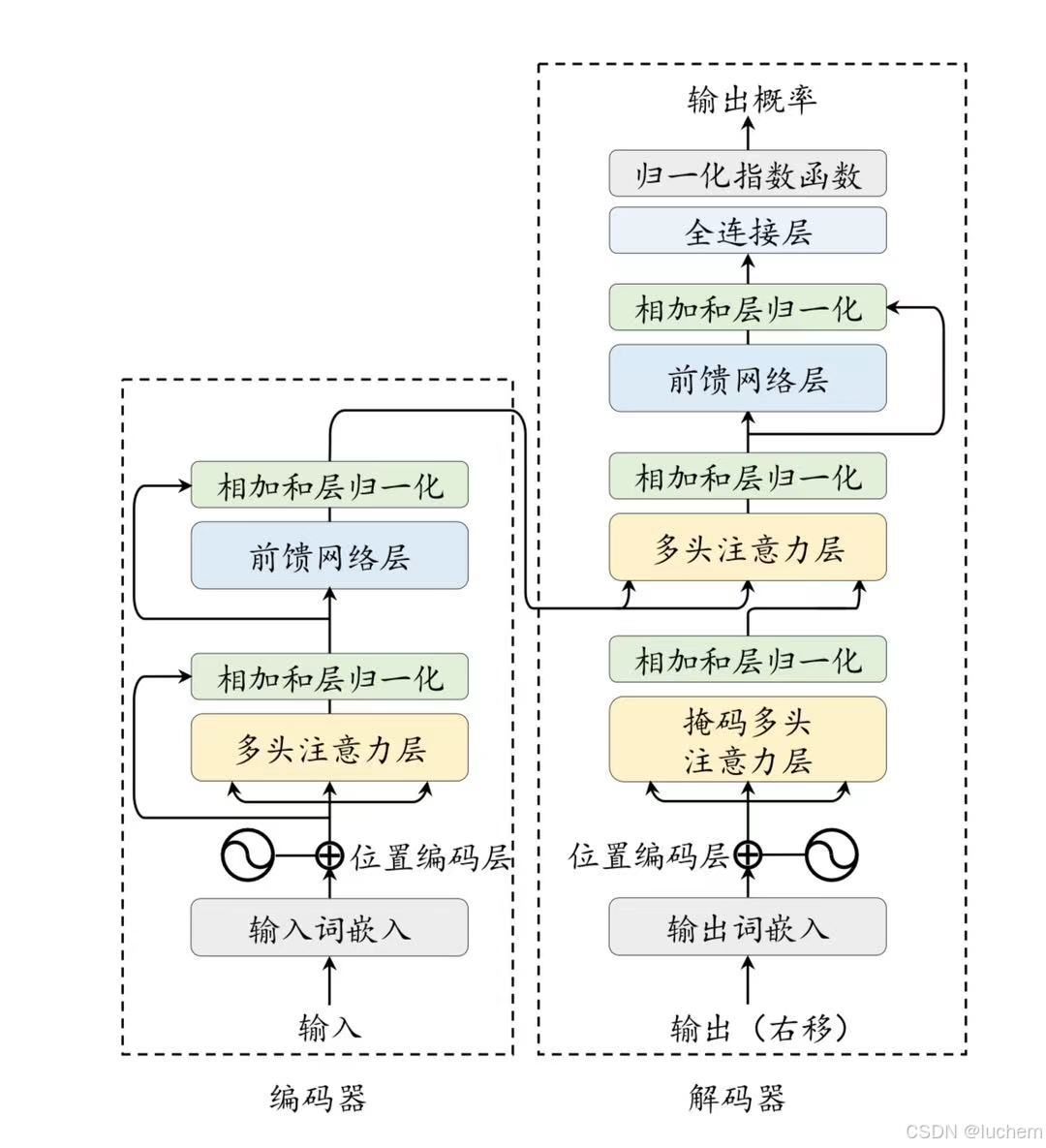
当前主流的大语言模型都基于Transformer 模型进行设计的。Transformer 是由多层的多头自注意力(Multi-head Self-attention)模块堆叠而成的神经网络模型。原始的Transformer 模型由编码器和解码器两个部分构成,而这两个部分实际上可以独立使用大语言模型的特点是使用了更长的向量维度、更深的层数,进而包含了更大规模的模型参数,并主要使用解码器架构,对于Transformer 本身的结构与配置改变并不大。
5.1.1输入编码
在Transformer 模型中,输入的词元序列(u = [u1,u2,u3...ur]) 首先经过一个输入嵌入模块(Input Embedding Module)转化成词向量序列。具体来说,为了捕获词汇本身的语义信息,每个词元在输入嵌入模块中被映射成为一个可学习的、具有固定维度的词向量pt ∈R。
通过这种建模方法的表示,Transformer 模型可以利用位置编码pt建模不同词元的位置信息。由于不同词元的位置编码仅由其位置唯一决定,因此这种位置建模方式被称为绝对位置编码。
5.1.2多头注意力机制
多头自注意力是Transformer 模型的核心创新技术。相比于循环神经网络(Re-current Neural Network, RNN)和卷积神经网络(Convolutional Neural Network, CNN)等传统神经网络,多头自注意力机制能够直接建模任意距离的词元之间的交互关系。
头自注意力机制通常由多个自注意力模块组成。在每个自注意力模块中,对于输入的词元序列,将其映射为相应的查询(Query, Q)、键(Key,K)和值(Value,V)三个矩阵。然后,对于每个查询,将和所有没有被掩盖的键之间计算点积。这些点积值进一步除以√D进行缩放(D是键对应的向量维度),被传入到softmax函数中用于权重的计算。进一步,这些权重将作用于与键相关联的值,通过加权和的形式计算得到最终的输出。在数学上,上述过程可以表示为:
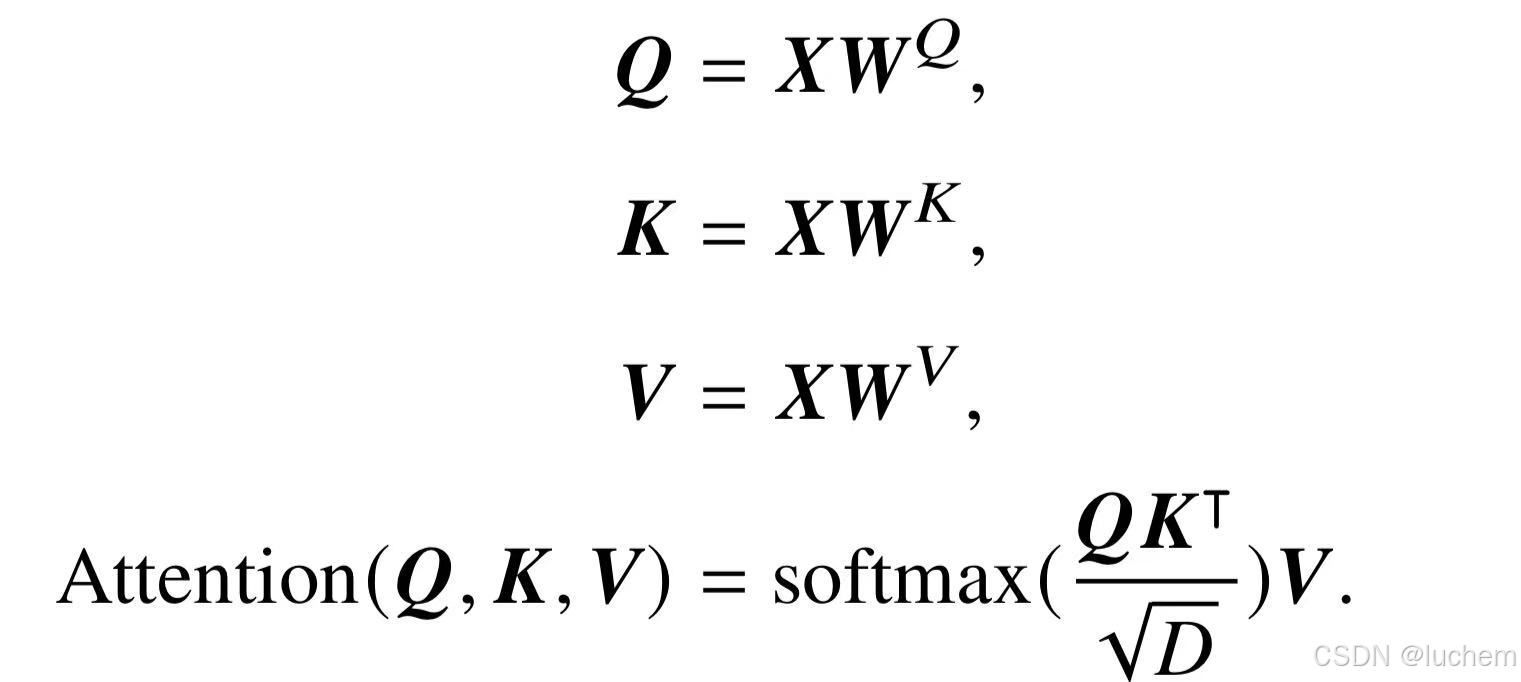
与单头注意力相比,多头注意力机制的主要区别在于它使用了H组结构相同,映射参数不同的自注意力模块。输入序列首先通过不同的权重矩阵被映射为一组查询、键和值。每组查询、键和值的映射构成一个“头”,并独立地计算自注意力的输出。最后,不同头的输出被拼接在一起,并通过一个权重矩阵W ∈RH×H进行映射,产生最终的输出。如下面的公式所示:
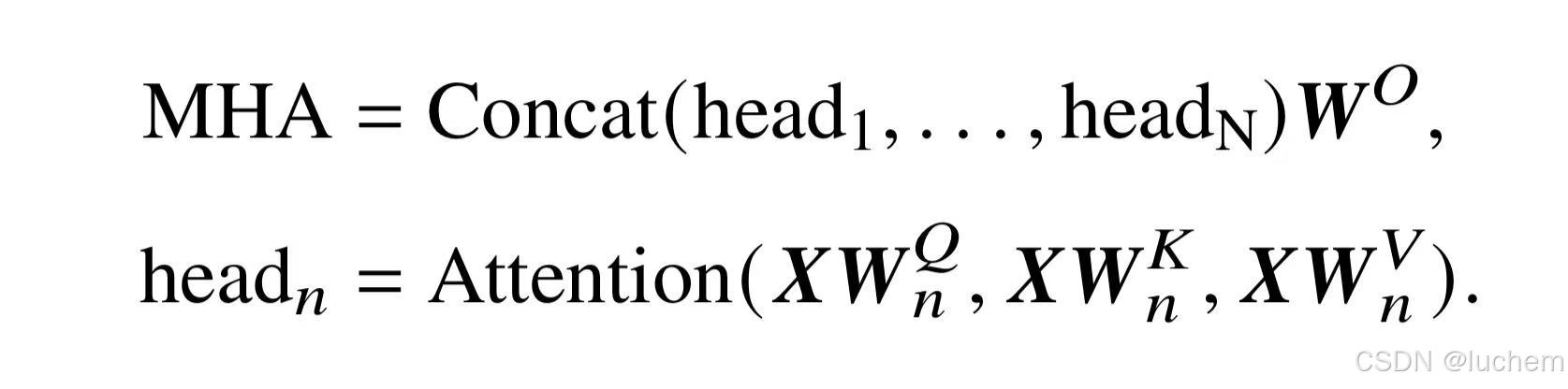
5.1.3前馈网络层
Transformer 模型引入了一个前馈网络层(Feed Forward Netwok, FFN),对于每个位置的隐藏状态进行非线性变换和特征提取。具体来说,给定输入x,Transformer 中的前馈神经网络由两个线性变换和一个非线性激活函数组成: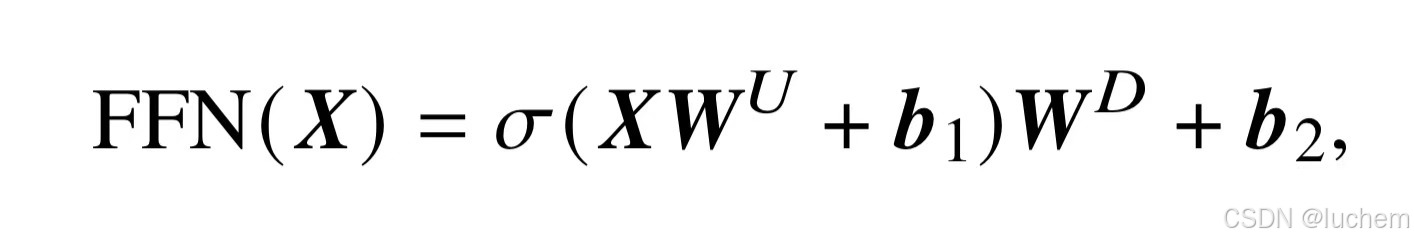
其中WU∈RH×H′ 和WD∈RH′×H 分别是第一层和第二层的线性变换权重矩阵,b1 ∈RH′ 和b2 ∈RH 是偏置项,sigma是激活函数(在原始的Transformer 中,采用ReLU 作为激活函数)。前馈网络层通过激活函数引入了非线性映射变换,提升了模型的表达能力,从而更好地捕获复杂的交互关系。
5.1.4编码器
在Transformer 模型中,编码器(Encoder)的作用是将每个输入词元都编码成一个上下文语义相关的表示向量。编码器结构由多个相同的层堆叠而成,其中每一层都包含多头自注意力模块和前馈网络模块。在注意力和前馈网络后,模型使用层归一化和残差连接来加强模型的训练稳定度。其中,残差连接(Residual Connection)将输入与该层的输出相加,实现了信息在不同层的跳跃传递,从而缓解梯度爆炸和消失的问题。而LayerNorm 则对数据进行重新放缩,提升模型的训练稳定性。编码器接受经过位置编码层的词嵌入序列X作为输入,通过多个堆叠的编码器层来建模上下文信息,进而对于整个输入序列进行编码表示。由于输入数据是完全可见的,编码器中的自注意力模块通常采用双向注意力,每个位置的词元表示能够有效融合上下文的语义关系。在编码器-解码器架构中,编码器的输出将作为解码器(Decoder)的输入,进行后续计算。形式化来说,第l层(l ∈{1,...,L})的编码器的数据处理过程如下所示:

其中,Xl−1和Xl分别是该Transformer 层的输入和输出,X′l 是该层中输入经过多头注意力模块后的中间表示,LayerNorm 表示层归一化。
5.1.5解码器
Transformer 架构中的解码器基于来自编码器编码后的最后一层的输出表示以及已经由模型生成的词元序列,执行后续的序列生成任务。与编码器不同,解码器需要引入掩码自注意力(Masked Self-attention)模块,用来在计算注意力分数的时候掩盖当前位置之后的词,以保证生成目标序列时不依赖于未来的信息。
除了建模目标序列的内部关系,解码器还引入了与编码器相关联的多头注意力层,从而关注编码器输出的上下文信息XL。同编码器类似,在每个模块之后,Transformer 解码器也采用了层归一化和残差连接。在经过解码器之后,模型会通过一个全连接层将输出映射到大小为V的目标词汇表的概率分布,并基于某种解码策略生成对应的词元。在训练过程中,解码器可以通过一次前向传播,让每个词元的输出用于预测下一个词元。而在解码过程,解码器需要经过一个逐步的生成过程,将自回归地生成完整的目标序列。解码器的数据流程如下所示:

其中,Yl−1和Yl分别是该Transformer 层的输入和输出,Yl′ 和Yl′′ 是该层中输入经过掩码多头注意力MaskedMHA 和交叉多头注意力CrossMHA 模块后的中间表示,LayerNorm 表示层归一化。然后将最后一层的输入WLYL映射到词表的维度上:
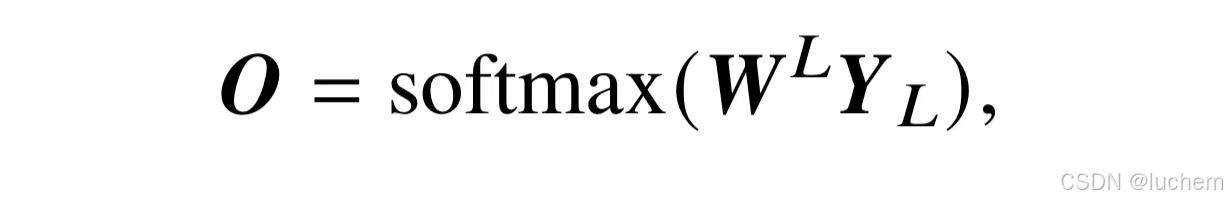
其中,O∈RH×V 是模型最终的输出,代表下一个词在词表上的概率分布;WL ∈RH×V是将输入表示映射到词汇表维度的参数矩阵,而WLYL是概率化前的中间值,通常被称为logits。
5.2详细配置
Transformer 模型四个核心组件的配置,包括归一化、位置、激活函数和注意力机制,并介绍混合专家结构。
5.2.1归一化方法
大语言模型的预训练过程中经常会出现不稳定的问题。为了应对这一问题,深度学习方法通常会采用特定的归一化策略来加强神经网络训练过程的稳定性。原始的Transformer 模型主要使用了层归一化方法(Layer Normalization, LN)。随着研究工作的不断深入,基于层归一化的改进技术不断涌现,例如均方根层归一化(Root Mean Square Layer Normalization, RMSNorm)和DeepNorm,这些新技术已经在一些大语言模型中得到应用。
- LayerNorm:层归一化会计算每一层中所有激活值的均值miu和方差sigma,从而重新调整激活值的中心和缩放比例:
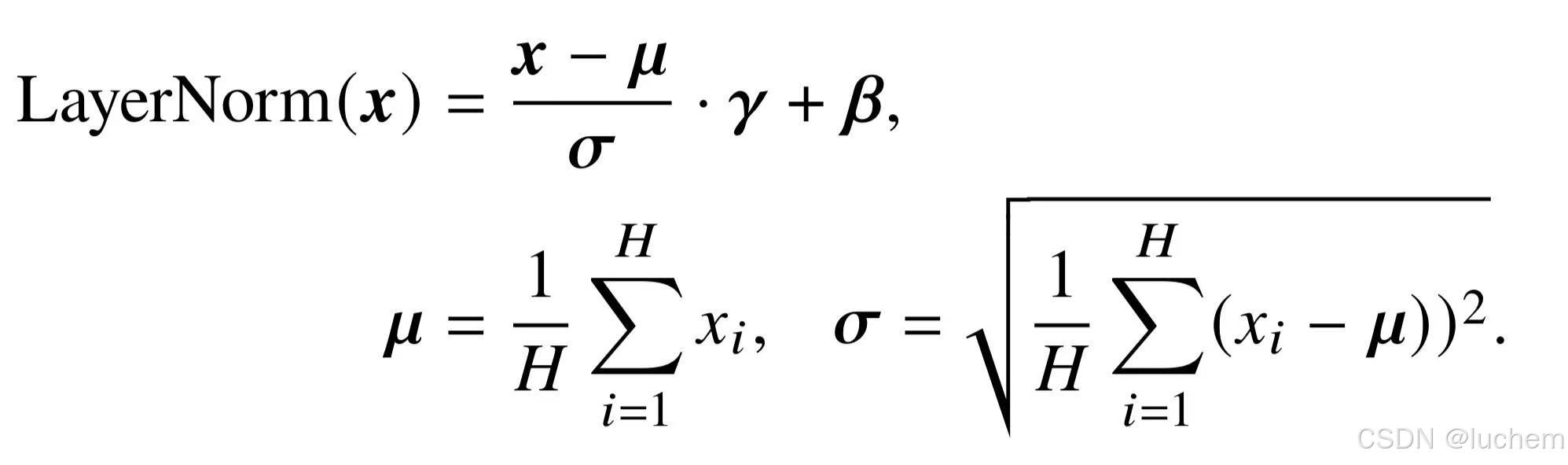
- RMSNorm:为了提高层归一化的训练速度,RMSNorm [159] 仅利用激活值总和的均方根RMS(x)对激活值进行重新缩放。使用RMSNorm 的Transformer 模型相比于之前LayerNorm 训练的模型在训练速度和性能上均具有一定优势。采用RMSNorm 的代表性模型包括Gopher和Chinchilla。其计算公式如下所示:
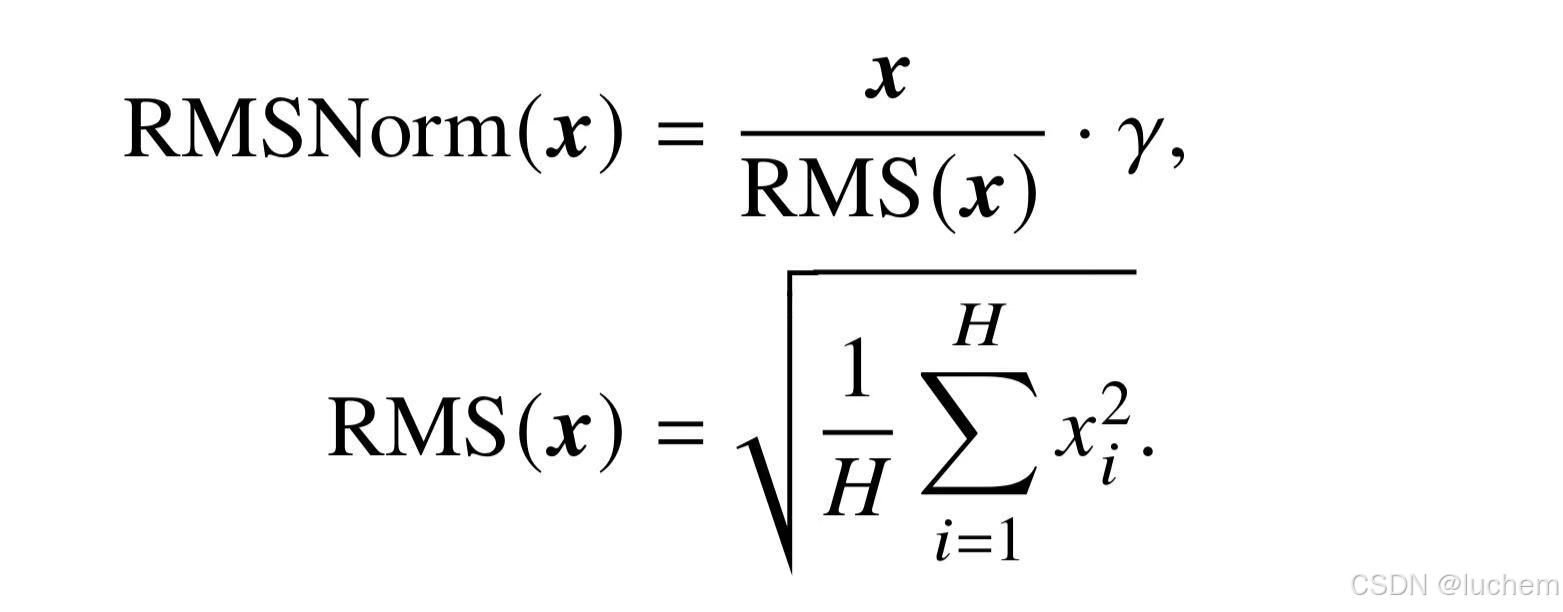
- DeepNorm:DeepNorm 在LayerNorm 的基础上,在残差连接中对之前的激活值x按照一定比例alpha进行放缩。通过这一简单的操作,Transformer 的层数可以被成功地扩展至1,000 层[160],进而有效提升了模型性能与训练稳定性。其计算公式如下:

- 其中,Sublayer 表示Transformer 层中的前馈神经网络或自注意力模块。
-
5.2.2归一化模型
-
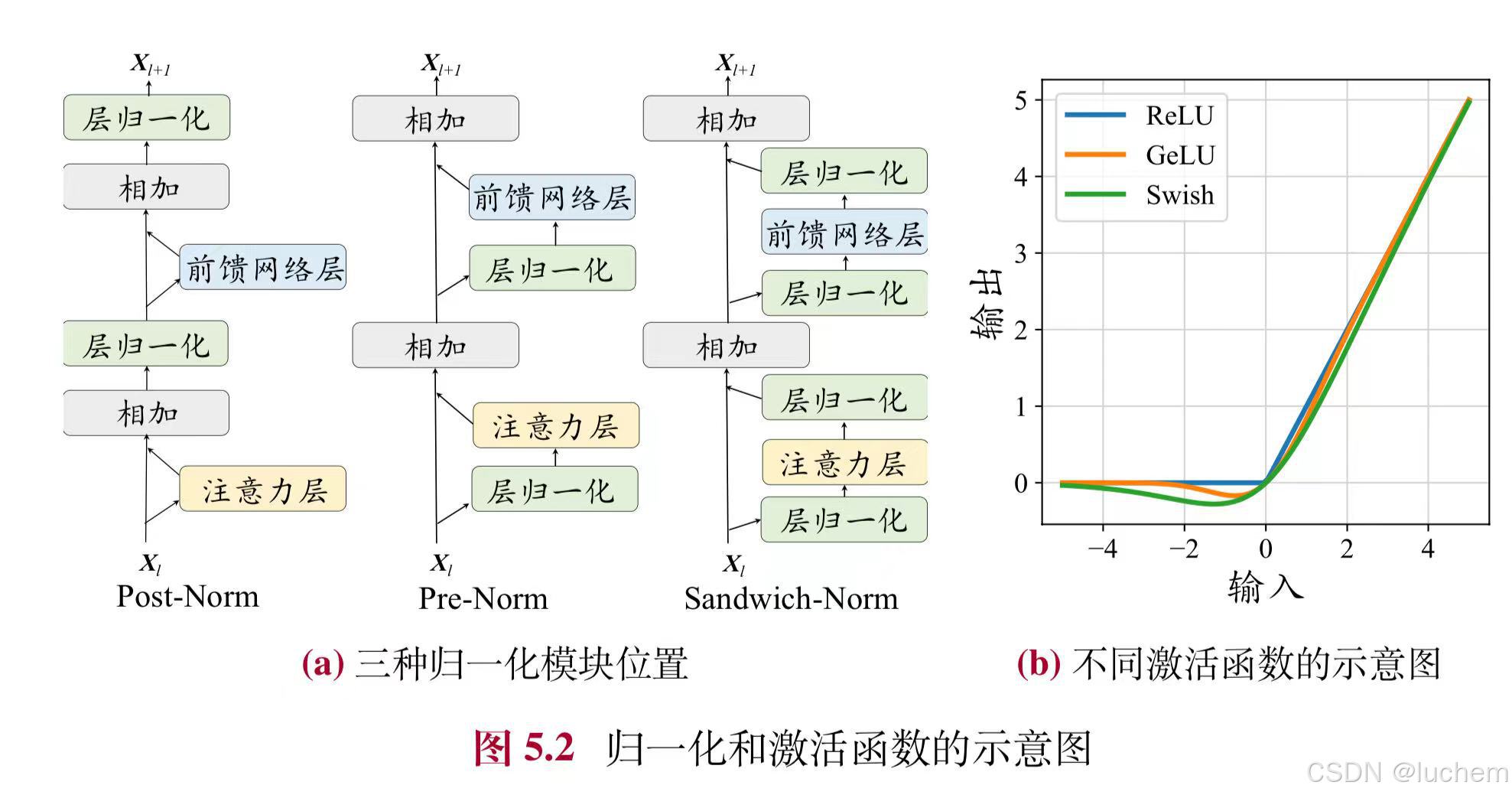
为了加强大语言模型训练过程的稳定性,除了归一化方法外,归一化模块的位置也具有重要的影响。归一化模块的位置通常有三种选择,分别是层后归一化(Post-Layer Normalization, Post-Norm)、层前归一化(Pre-LayerNormalization, Pre-Norm)和夹心归一化(Sandwich-Layer Normalization, Sandwich-Norm)。
- Post-Norm:Post-Norm 是在原始Transformer 模型中所使用的一种归一化技术。其中,归一化模块被放置于残差计算之后。其计算公式如下:
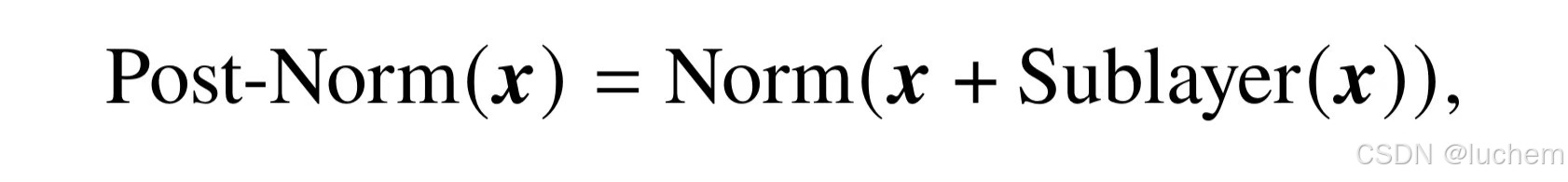
- 其中,Norm 表示任意一种归一化方法。在原理上,后向归一化具有很多优势。首先,有助于加快神经网络的训练收敛速度,使模型可以更有效地传播梯度,从而减少训练时间。其次,后向归一化可以降低神经网络对于超参数(如学习率、初始化参数等)的敏感性,使得网络更容易调优,并减少了超参数调整的难度。
- Pre-Norm:与Post-Norm 不同,Pre-Norm将归一化模块应用在每个子层之前。其计算公式如下:
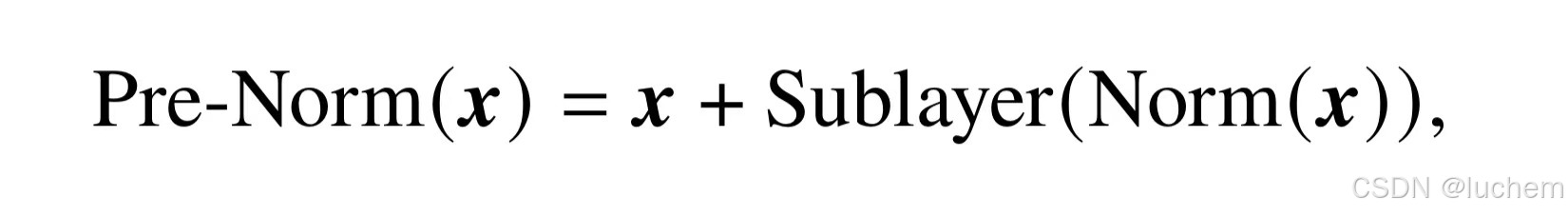
- 此处的Norm 泛指任意一种归一化方法。此外,Pre-Norm 在最后一个Transformer层后还额外添加了一个LayerNorm。相较于Post-Norm,Pre-Norm 直接把每个子层加在了归一化模块之后,仅仅对输入的表示进行了归一化,从而可以防止模型的梯度爆炸或者梯度消失现象。
- Sandwich-Norm:在Pre-Norm 的基础上,Sandwich-Norm [165] 在残差连接之前增加了额外的LayerNorm,旨在避免Transformer 层的输出出现数值爆炸的情况。具体的实现方式如下所示:
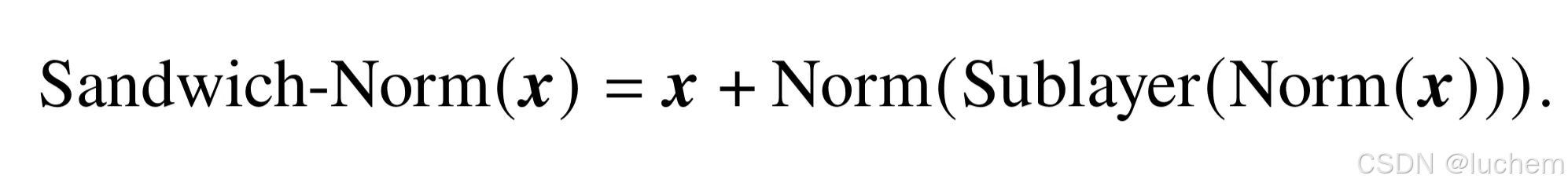
- 本质上,Sandwich-Norm 可以看作是Pre-Norm 和Post-Norm 两种方法的组合,理论上具有更加灵活的表达能力。但是研究人员发现,Sandwich-Norm 有时仍然无法保证大语言模型的稳定训练,甚至会引发训练崩溃的问题
-
5.2.3激活函数
-
激活函数主要是为神经网络中引入非线性变化,从而提升神经网络的模型能力。在原始的Transformer 中采用了ReLU(Rectified Linear Unit)激活函数:
-
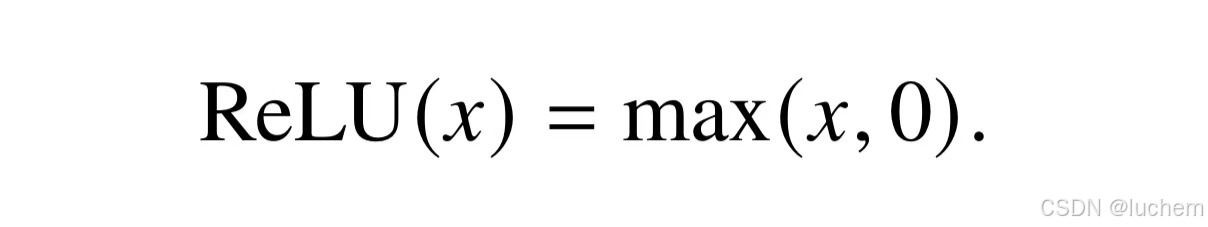
-
Swish 激活函数将神经元和该神经元的sigmoid 激活的乘积作为新的激活函数。而GELU(Gaussian Error Linear Unit) 则利用标准高斯累积分布函数作为激活函数,被很多的Transformer 模型所采用。相比于原始的ReLU 函数,这些新的激活函数通常能够带来更好的性能并且收敛性更好,但是计算过程更为复杂。Swish 和GELU 的数学表示如下:
-
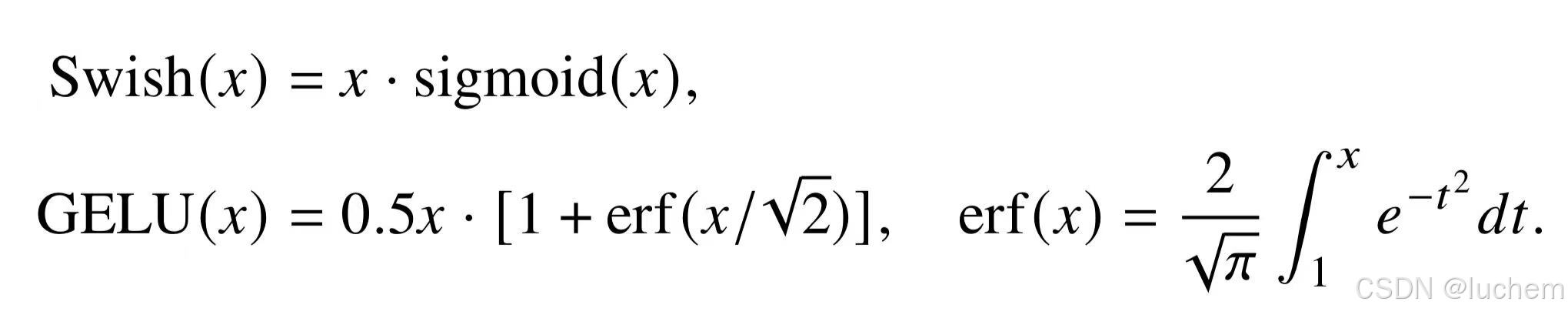
-
大语言模型(例如PaLM 和LaMDA)也经常采用GLU(Gated LinearUnit)激活函数以及它的变种,特别是SwiGLU 和GeGLU。不同于其他激活函数,GLU 激活函数引入了两个不同的线性层。其中一个线性层的输出将被输入到一个激活函数(例如,GeGLU 采用GELU 激活函数)中,其结果将和另一个线性层的输出进行逐元素相乘作为最终的输出。SwiGLU 和GeGLU 激活函数的计算公式如下所示:
-
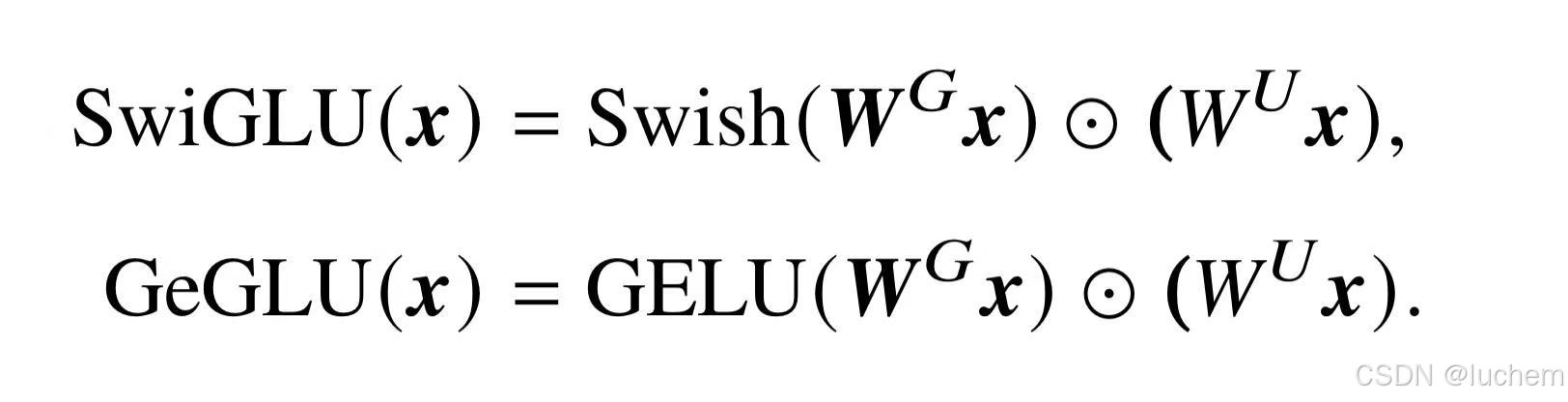
-
5.2.4位置编码
-
由于Transformer 模型中自注意力模块具有置换不变性,因此仅使用注意力机制无法捕捉序列中的顺序关系,从而退化为“词袋模型”。为了解决这一问题,需要引入位置编码(Position Embedding, PE)对于序列信息进行精确建模,从而将绝对或相对位置信息整合到模型中。
- 绝对位置编码:在编码器和解码器的输入端,根据输入的词元在序列中的绝对位置生成唯一的位置嵌入,并与词元的嵌入表示进行相加来注入位置信息。绝对位置编码的公式如下所示:
- xt = vt + pt
- 其中,pt表示位置t的位置嵌入,vt是该位置词元对应的词向量。原始的Trans-former 采用了正余弦位置编码。该位置编码在不同维度上预先定义了特定的正弦或余弦函数,通过将词元的绝对位置作为输入代入这些函数,从而为这些维度赋予相应的值。对于维度大小为H的位置嵌入,其第i ∈{1,...,H}维的值按照如下方法进行设置:
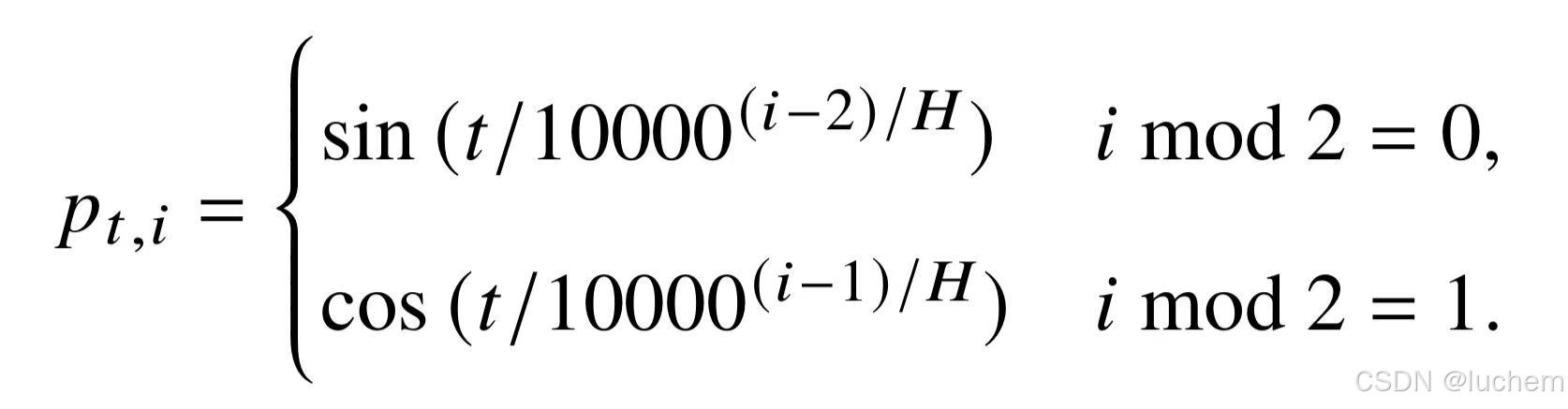
- 相对位置编码:相对位置编码是根据键和查询之间的偏移量计算得来的。计算得到的相对位置编码通常应用于注意力矩阵的计算中,而不是直接与词元本身的位置编码进行相加。其中,Transformer-XL提出了一种相对位置编码方法,在计算键和查询之间的注意力分数时引入了相对位置信息。对于使用绝对位置编码的模型,其注意力值可以进行进一步的分解:
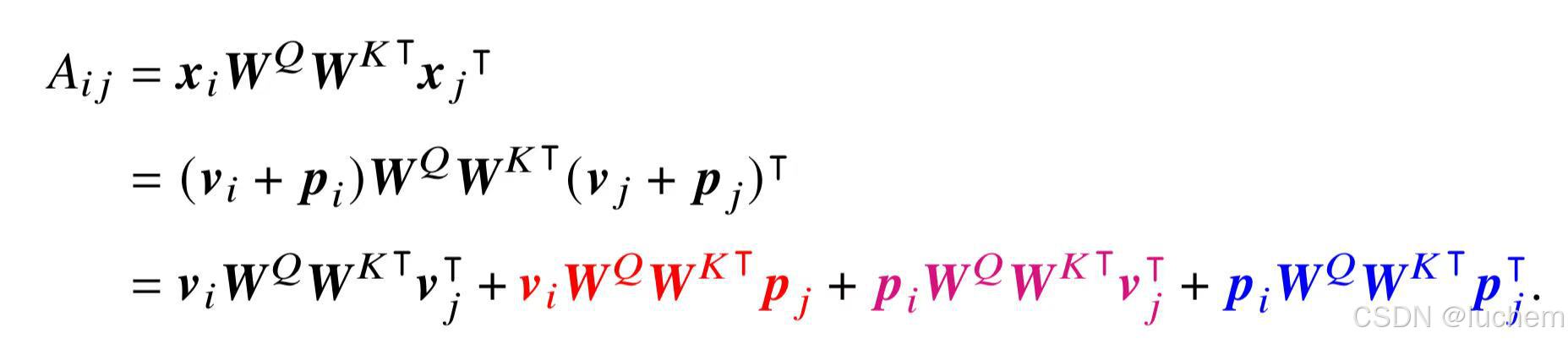
- 而Transformer-XL 对上述注意力值进行了改写,使用相对位置信息代替绝对位置信息:

- 其中,xi是每个词元对应的词向量(对应没有显式加入位置编码的词向量vi),而ri-j 表示相对位置编码,u 和v 是两个可学习的表示全局信息的参数。相比于绝对位置编码,注意力值的第二项中和第四项键对应的绝对位置编码WKTpj 被替换为相对位置编码rj,以引入相对位置信息;而第三和第四项中则使用全局参数u 和v 替换查询对应的绝对位置编码piWQ,用于衡量键的语义信息和相对位置信息本身的重要程度。T5提出了一种较为简化的相对位置编码。具体来说,它在注意力分数中引入了可学习的标量,这些标量是基于查询和键的位置之间的距离计算的。与绝对位置编码相比,应用了相对位置编码的Transformer模型常常可以对比训练序列更长的序列进行建模,即具备一定的外推能力:
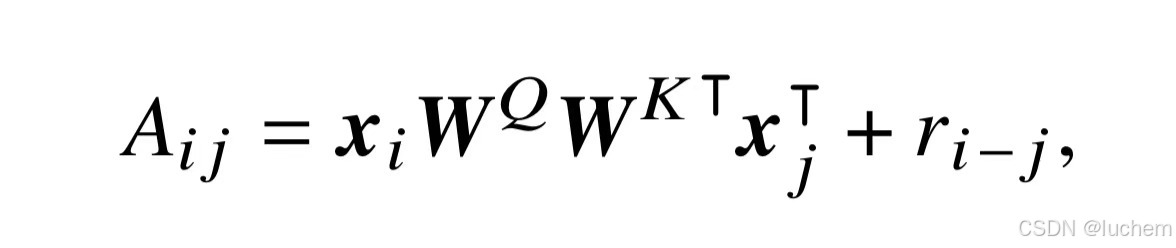
- 旋转位置编码(Rotary Position Embedding ,RoPE):RoPE 巧妙地使用了基于绝对位置信息的旋转矩阵来表示注意力中的相对位置信息。RoPE 根据位置信息为序列中每个词元所对应的设置了独有的旋转矩阵,并和对应的查询和键进行相乘进行融合。形式化,位置索引为t对应的旋转矩阵定义如下所示:
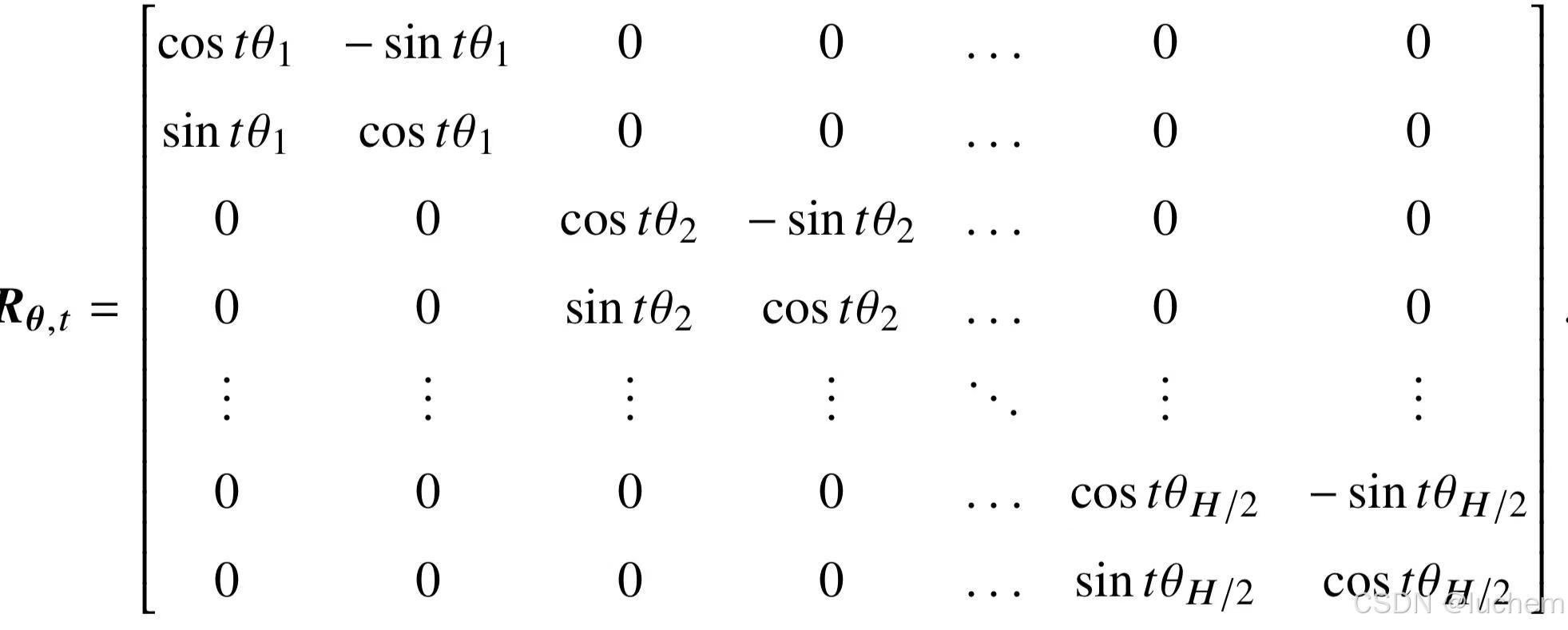
- 利用旋转矩阵中三角函数的特性,位置索引为i的旋转矩阵和位置索引为j的旋转矩阵的转置的乘积等同于位置索引为它们相对距离i−j的旋转矩阵。通过这种方式,键和查询之间的注意力分数能够有效融入相对位置信息。注意力矩阵的公式可以进一步变为如下形式:
-
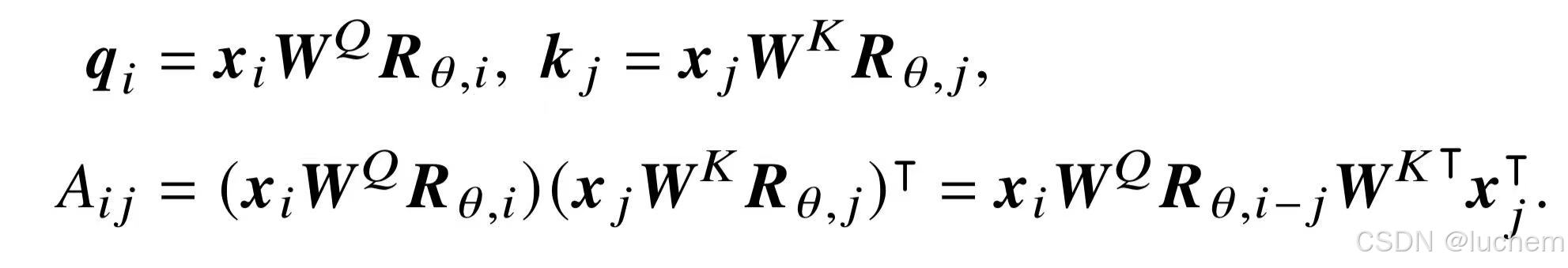
- 根据旋转矩阵的定义,RoPE 在处理查询和键向量的时候,将每对连续出现的两个元素视为一个子空间。因此,对于一个长度为H的向量来说,将会形成H/2 个这样的子空间。在这些子空间中,每一个子空间i ∈{1,...,H/2}所对应的两个元素都会根据一个特定的旋转角度t·sita 进行旋转,其中t代表位置索引,而sita表示该子空间中的基。与正弦位置嵌入类似,RoPE 将基sita 定义为底数b(默认值是10000)的指数:
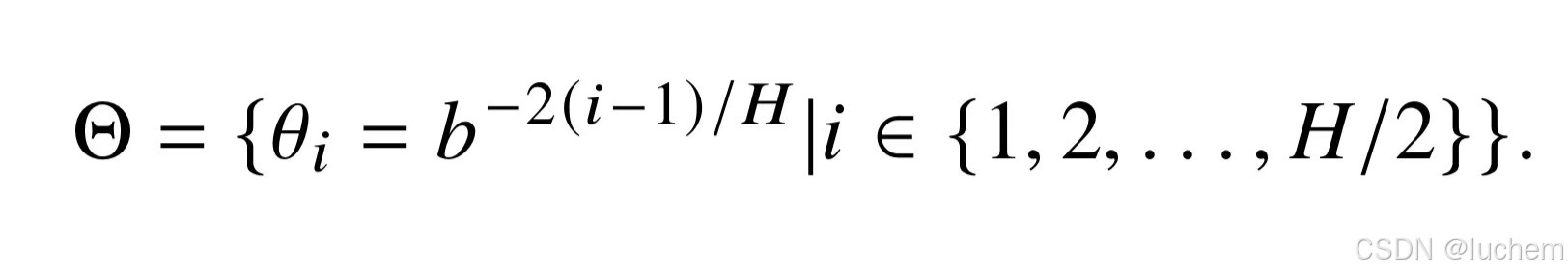
- 进一步,每个子空间定义了波长lamata,即在该子空间上完成一个完整周期(2pi)旋转所需的距离:
-
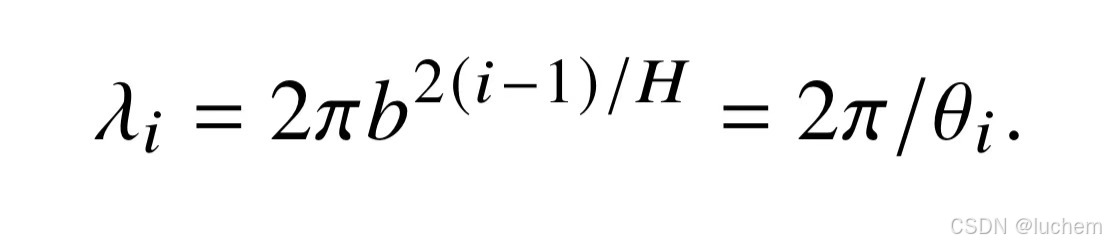
- ALiBi位置编码:ALiBi 是一种特殊的相对位置编码,主要用于增强Transformer 模型的外推能力。具体来说,ALiBi 通过在键和查询之间的距离上施加相对距离相关的惩罚来调整注意力分数。其计算公式如下:
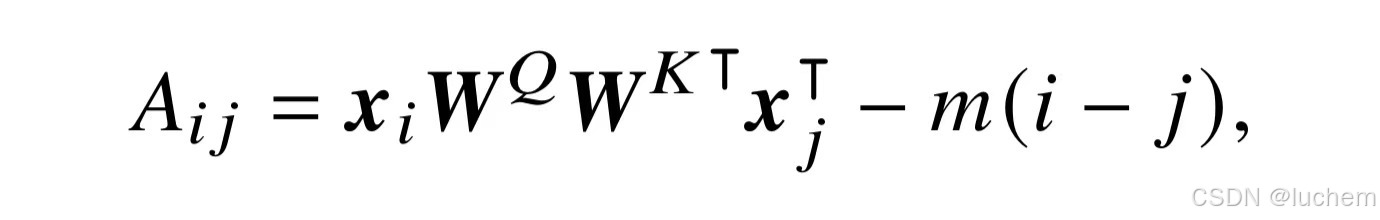
- 其中,i−j是查询和键之间的位置偏移量,m是每个注意力头独有的惩罚系数。与T5 等模型中的相对位置编码不同,ALiBi 中的惩罚分数是预先设定的,不需要引入任何可训练的参数。此外,ALiBi 展现出了优秀的外推性能,能够对于超过上下文窗口更远距离的词元进行有效建模。
-
5.2.5注意力机制
-
注意力机制是Transformer 架构中的核心技术,它能够针对序列中的词元对构建交互关系,聚合来自于不同位置的语义信息。
- 完整自注意力机制:在原始的Transformer 模型中,注意力机制通过成对的方式进行序列数据的语义建模,充分考虑了序列中所有词元之间的相互关系。其中,每个词元在注意力计算中都需要对于其前序的所有词元的键值对予以访问,因此对于序列长度为T的序列需要O(T^2)的计算复杂度。此外,Transformer 还引入了多头注意力机制,将查询、键和值在不同的语义空间进行线性投影,然后将每个头的输出进行聚合形成最终的输出。
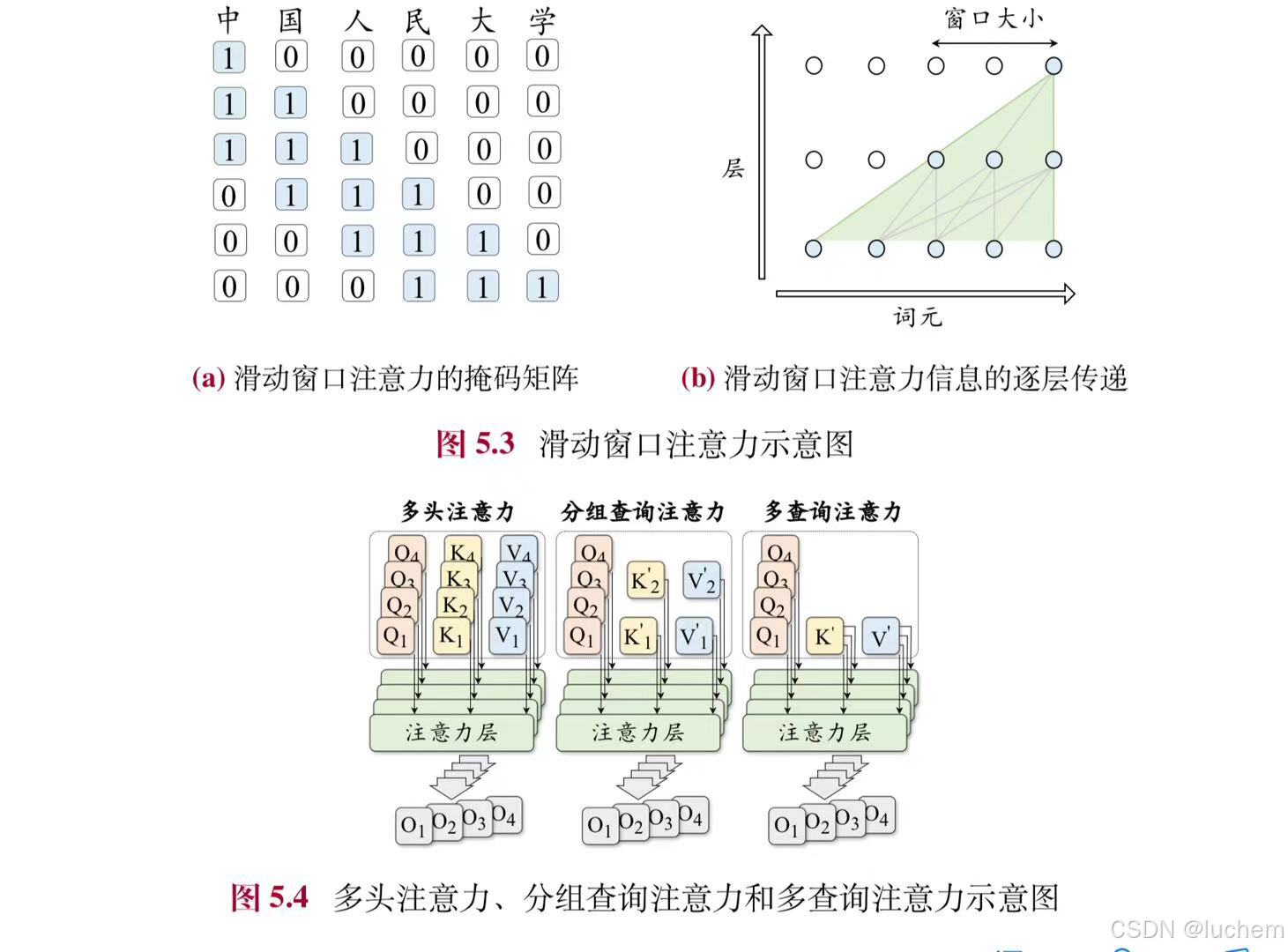
- 稀疏注意力机制:尽管完整自注意力机制具有较强的建模能力,但是它需要平方级的计算复杂性。在处理长序列时较为显著,带来了较大的计算和存储开销。为了降低注意力机制的计算复杂度,研究人员提出了多种高效的注意力变种。其中,滑动窗口注意力机制(Sliding Window Attention, SWA)是大语言模型中使用最多的一种稀疏注意力机制。不同于完整的注意力机制,滑动窗口注意力根据词元位置,仅仅将位置索引上距离该词元一定范围内的词元考虑到注意力的计算中。具体来说,滑动窗口注意力设置了一个大小为w的窗口,对每个词元ut,只对窗口内的词元[ut-w+1,...,ut]进行注意力计算,从而将复杂度降低到O(wT)。
- 多查询/分组查询注意力:为了提升注意力机制的效率,多查询注意力(Multi-Query Attention, MQA)提出针对不同的头共享相同的键和值变换矩阵。这种方法减少了访存量,提高了计算强度,从而实现了更快的解码速度并且对于模型性能产生的影响也比较小。
- 硬件优化的注意力机制:两个具有代表性的工作是FlashAttention与PagedAttention 。相比于传统的注意力实现方式,FlashAttention 通过矩阵分块计算以及减少内存读写次数的方式,提高注意力分数的计算效率;PagedAttention 则针对增量解码阶段,对于KV 缓存进行分块存储,并优化了计算方式,增大了并行计算度,从而提高了计算效率。
-
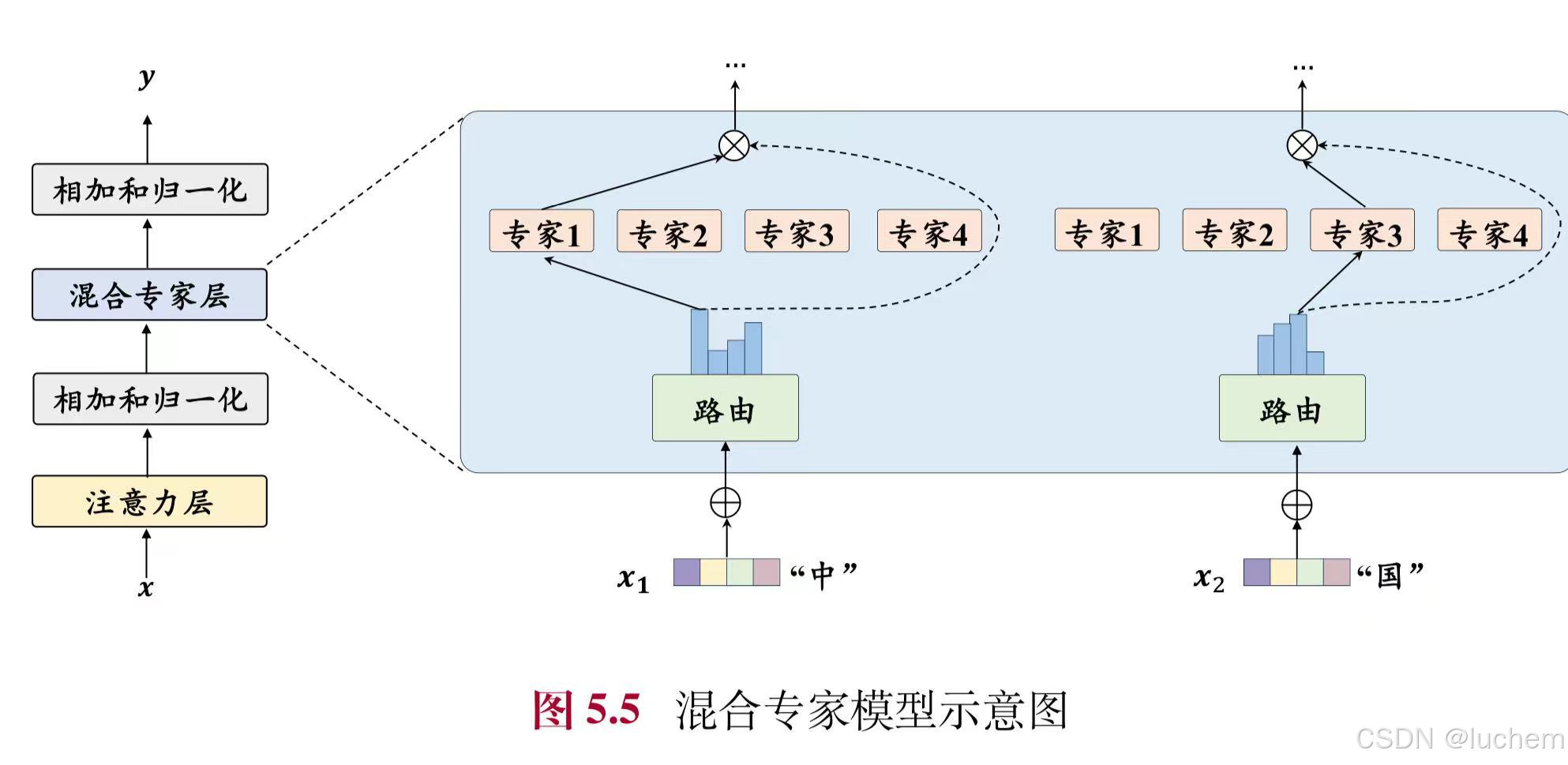
5.2.6混合专家模式
-
在混合专家架构中,每个混合专家层包含K个专家组件,记为[E1,E2,...,EK],其中每个专家组件Ei都是一个前馈神经网络。对于输入的每个词元表示xt,模型通过一个路由网络(或称为门控函数)G来计算该词元对应于各个专家的权重。在路由函数中,首先通过线性层WG∈RH×K 映射为K 个专家的得分,并基于此选择出概率最高的k个专家进行激活。随后,这k个专家的得分将被送入softmax函数计算出它们的权重G(xt)= [G(xt)1,...,G(xt)k],没有被选择的专家权重将被置为0。上述路由网络的计算过程如下式所示:
-
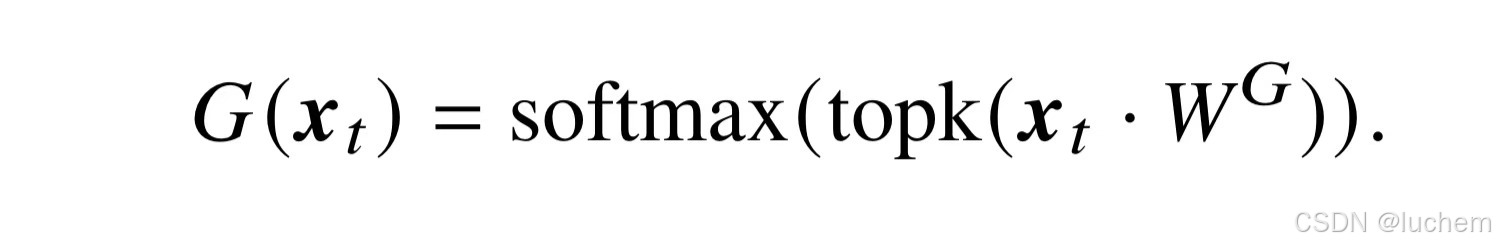
-
之后,每个被选择的词元的输出的加权和将作为该混合专家网络层的最终输出ot:
-
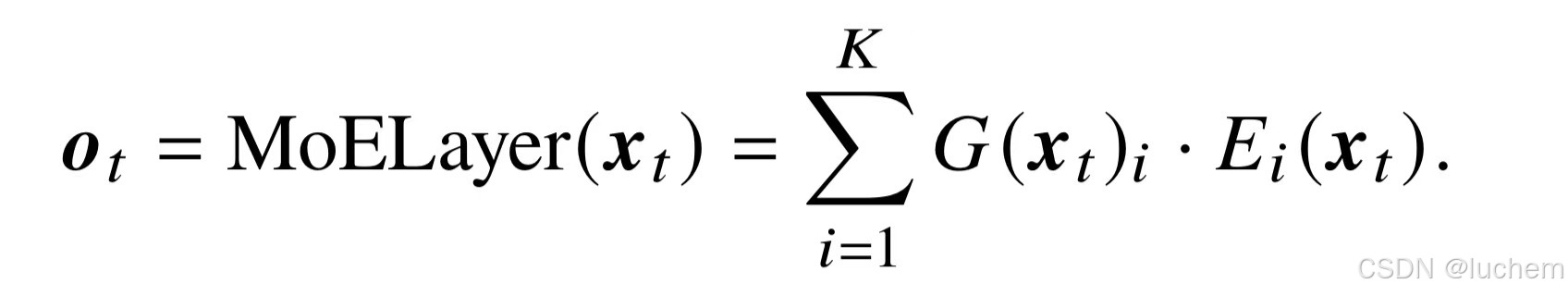
-
5.2.7LLaMa的详细配置
-
首先,为了增强模型的训练稳定性,建议采用前置的RMSNorm 作为层归一化方法。其次,在选择激活函数时,为了获得更优的模型性能,可以优先考虑使用SwiGLU 或GeGLU。最后,对于位置编码,可以优先选择RoPE 或者ALiBi,这两种位置编码方法在建模长序列数据时通常能够具有较好的性能。
-
对于一个LLaMA 模型,其首先将输入的词元序列通过词嵌入矩阵转化为词向量序列。之后,词向量序列作为隐状态因此通过L 个解码器层,并在最后使用RMSNorm 进行归一化。归一化后的最后一层隐状态将作为输出。在每个解码器层中,隐状态首先通过层前的RMSNorm 归一化并被送入注意力模块。注意力模块的输出将和归一化前的隐状态做残差连接。之后,新的隐状态进行RMSNorm 归一化,并送入前馈网络层。和上面一样,前馈网络层的输出同样做残差连接,并且作为解码器层的输出.
-
5.3主流架构
-
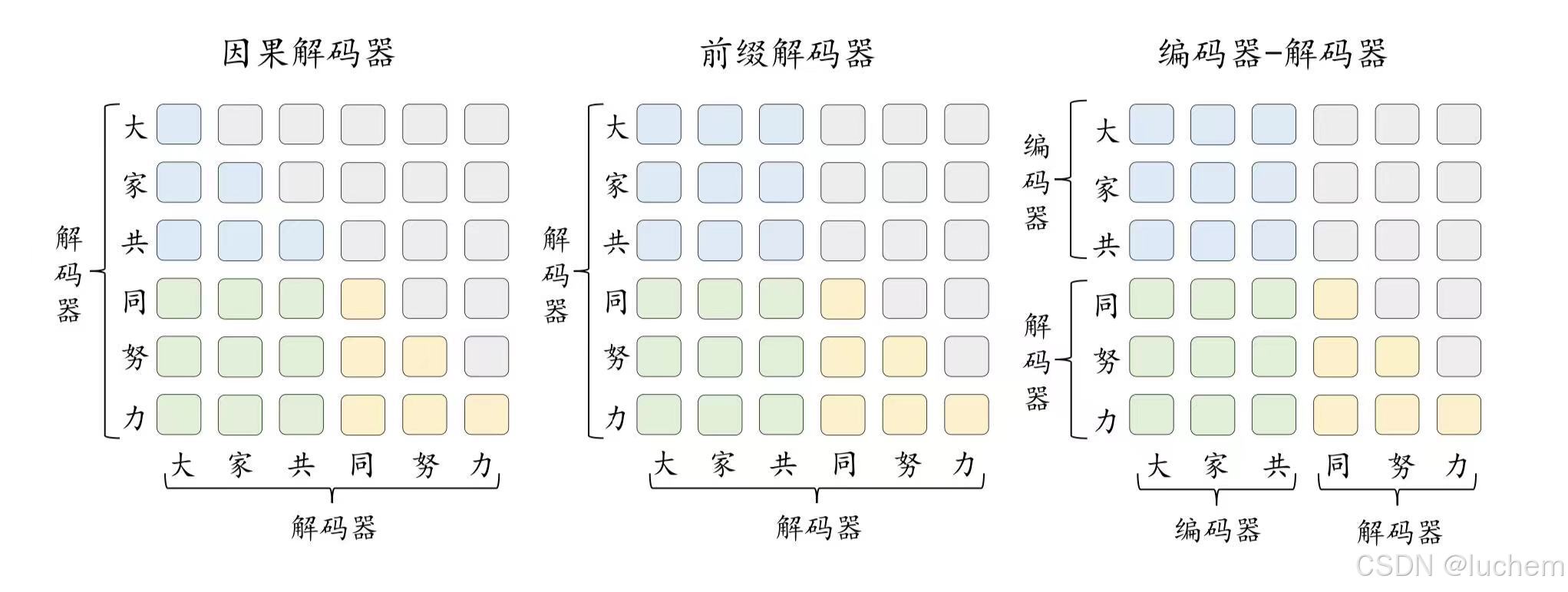
在预训练语言模型时代,自然语言处理领域广泛采用了预训练+ 微调的范式,并诞生了以BERT 为代表的编码器(Encoder-only)架构、以GPT 为代表的解码器(Decoder-only)架构和以T5 为代表的编码器-解码器(Encoder-decoder)架构的大规模预训练语言模型。随着GPT 系列模型的成功发展,当前自然语言处理领域走向了生成式大语言模型的道路,解码器架构已经成为了目前大语言模型的主流架构。进一步,解码器架构还可以细分为两个变种架构,包括因果解码器(CausalDecoder)架构和前缀解码器(Prefix Decoder)架构。
-
-
5.3.1编码器-解码器架构
-
编码器-解码器架构是自然语言处理领域里一种经典的模型结构,广泛应用于如机器翻译等多项任务。原始的Transformer 模型也使用了这一架构,组合了两个分别担任编码器和解码器的Transformer 模块.
-
5.3.2因果解码器架构
-
当前,绝大部分主流的大语言模型采用了因果解码器架构。因果解码器采用了Transformer 中的解码器组件,同时做出了几点重要改动。首先,因果解码器没有显式地区分输入和输出部分。该架构采用了单向的掩码注意力机制,使得每个输入的词元只关注序列中位于它前面的词元和它本身,进而自回归地预测输出的词元。此外,由于不含有编码器部分,因果解码器删除了关注编码器表示的交叉注意力模块。经过自注意力模块后的词元表示将直接送入到前馈神经网络中。
-
5.3.3前缀解码器架构
-
前缀解码器架构也被称为非因果解码器架构,对于因果解码器的掩码机制进行了修改。该架构和因果解码器一样,仅仅使用了解码器组件。与之不同的是,该架构参考了编码器-解码器的设计,对于输入和输出部分进行了特定处理。
-
5.4长上下文模型
-
目前,增强大语言模型长文本建模能力的研究主要集中在两个方向:一是扩展位置编码,二是调整上下文窗口。
-
5.4.1扩展位置编码
-
在基于Transformer 架构的大语言模型中,模型的上下文建模能力通常受到训练集中文本数据长度分布的限制。一旦超出这个分布范围,模型的位置编码往往无法得到充分训练,从而导致模型处理长文本的性能下降。因此,当大语言模型面临超出其最大训练长度的任务时,需要对于位置编码进行扩展,以适应更长的绝对或相对位置。
-
实际上,某些特定的位置编码在超出原始上下文窗口的文本上,也能够表现出较好的建模能力,这种能力通常被称为外推(Extrapolation)能力。
-
值得注意的是,尽管这种外推能力可以确保模型在长文本上继续生成流畅的文本,但模型对长文本本身的理解能力可能无法达到与短文本相同的水平。为了真正增强长文本建模能力,通常还需要在更长的文本上进行一定的训练。
-
然而,目前比较主流的位置编码方法RoPE 在未经特殊修改的情况下并不具备良好的外推能力。具体来说,在处理更长的文本时,RoPE 在每个子空间上需要处理更大的旋转角度,而这些旋转角度可能会超过其训练中的角度分布范围。
- 直接微调
-
为了使大语言模型适应更长的上下文长度,一种直接的策略是使用相应的长文本数据对于模型进行微调。在这种情况下,模型可以直接根据相对位置计算出对应的位置编码,而无需对RoPE 本身进行任何修改。旋转角度的计算方式依旧和之前相同:
-
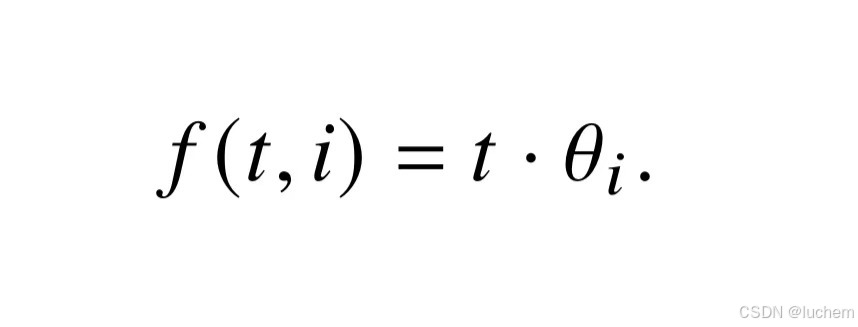
- 位置索引修改
-
鉴于直接微调可能引发旋转角度增大和注意力值爆炸的问题,有必要对旋转角度施加限制,以确保拓展后的上下文窗口中的旋转角度得到充分且有效的训练。为实现这一目标,可以通过修改位置索引T'max(sita)来调整所有子空间的旋转角度,从而保证其不超过原始上下文窗口所允许的最大值。具体来说,位置索引的修改可采用以下两种方法:
- 位置内插:
-
位置内插方法对于位置索引进行特定比例的缩放,以保证旋转角度不会超过原始上下文窗口的最大值。具体来说,该策略将所有位置索引乘以一个小于1 的系数Tmax/T′max(其中Tmax <T′max),Tmax 和T′max 分别表示原始上下文窗口和拓展后的上下文窗口的长度。通过进行这样的缩放,新的旋转角度计算公式变为:
-
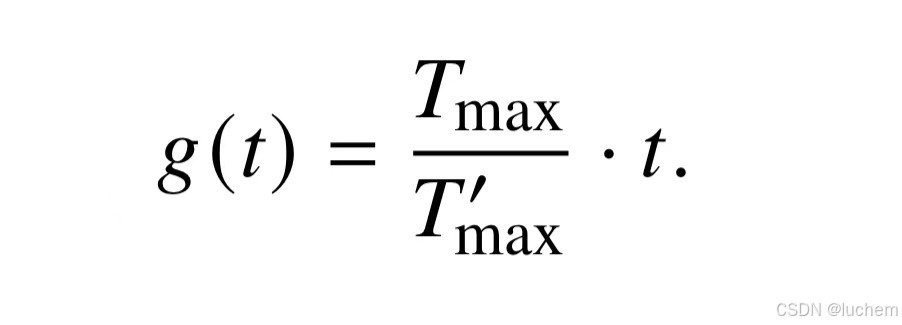
- 位置截断:
-
不同于位置内插,位置截断针对不同距离采用了不同的处理方式。该方法依据语言建模的局部性原理,对模型中近距离敏感的位置索引进行保留,同时截断或插值处理远距离的位置索引,确保其不超出预设的最大旋转角度。具体来说,采用位置截断的ReRoPE 和LeakyReRoPE [177] 方法首先设定一个不大于原始上下文窗口长度的窗口大小w (w ≤Tmax)。在此窗口范围内的部分,仍使用原始相对位置索引;对于超出此窗口的部分,位置索引则会被截断至窗口大小,即g(t)= w;或通过线性插值方式,将目标上下文窗口长度的位置索引映射回原始上下文窗口长度.上述位置截断方法可通过以下公式表达:
-
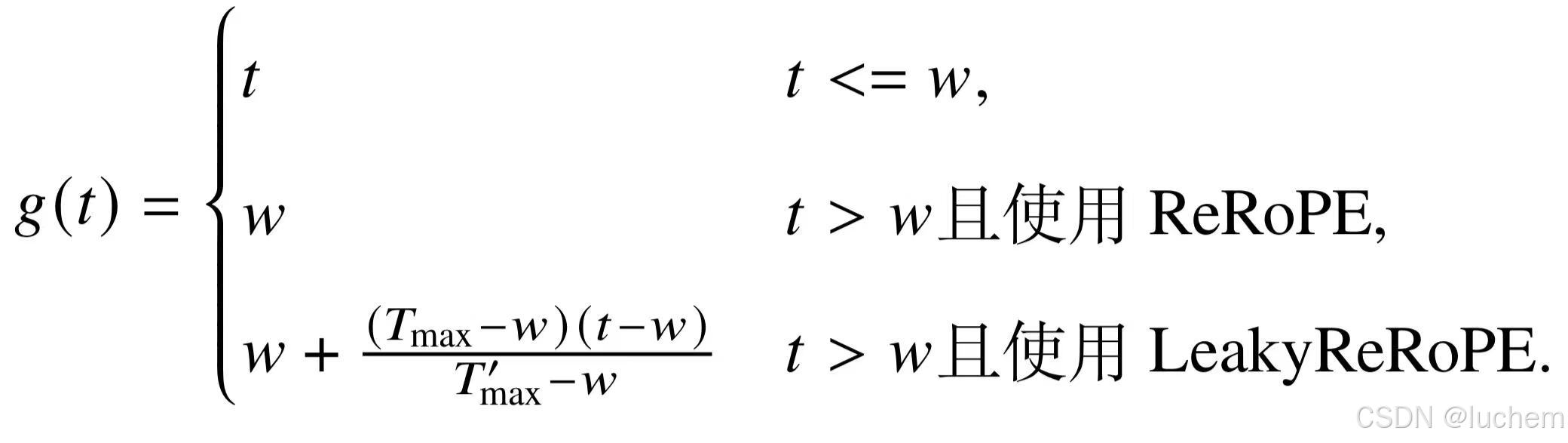
- 基修改:
-
每个子空间i都有一个对应的波长lamatai,表示在该子空间上旋转一周所需要的距离。然而,某些子空间的波长可能会超过上下文窗口的长度(lamata >Tmax),导致模型在这些子空间上无法对完整的旋转周期进行训练。这些子空间通常被称为关键子空间。在面临更长的文本时,RoPE 关键子空间的旋转角度对应的正余弦函数值并没有在训练阶段出现过,这就容易导致注意力值出现异常。因此,如果想要调整这些子空间的旋转角度分布,另一种方法是针对这些子空间的基ℎ(i)进行缩放:
-
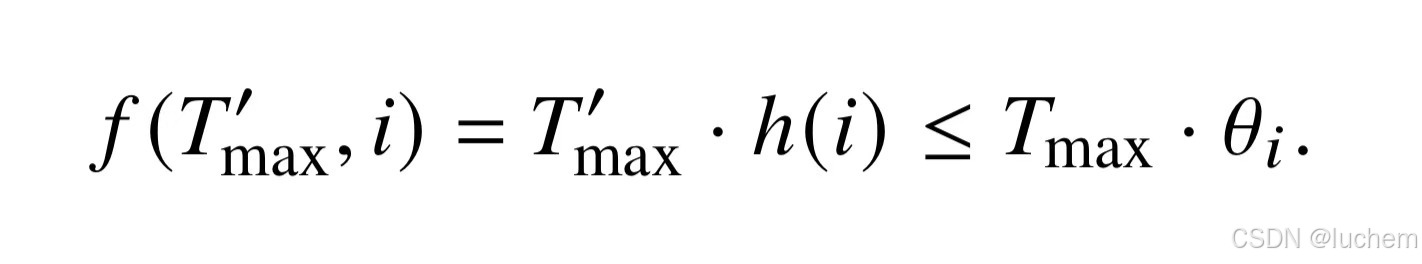
-
对基的修改可以通过对基的底数修改以及对基的截断实现,下面介绍这些修改方法。
- 底数调整:依据公式sita = b−2(i−1)/H,通过调整底数可以改变旋转的角度。具体来说,按照一定比例增大底数可以对基进行缩小,从而缩小旋转的角度,使得模型在不经过额外训练的情况下能够处理更长的上下文窗口。在这种情况下,每个子空间的旋转角度由下式给出:
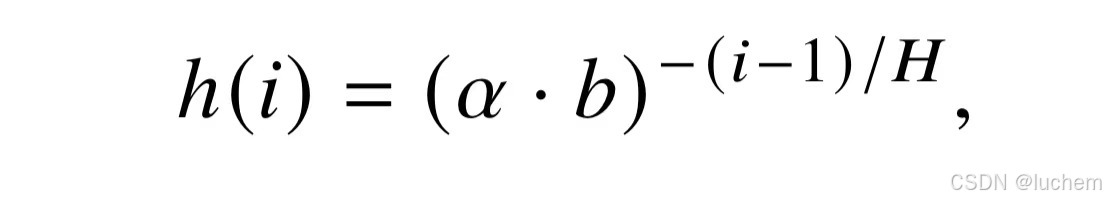
- 其中,alpha是一个大于等于放缩比例的数,通过对底数进行增大,实现缩小基来处理更长文本的能力。
- 基截断:基截断方法通过修改关键子空间来避免产生过大的旋转角度。这种方法首先设定两个阈值a和c。根据每个子空间上的基sita与这两个阈值的比较结果,可以选择相应的调整策略来对基进行调整:当sita ≥c时,基的值会被保持不变;当sita ≤a时,基会被设置为零;当a < sita < c时,基会被截断为一个较小的固定数值。通过上述的基截断操作,可以有效地防止在位置索引较大时出现超出预期分布的旋转角度,从而有助于实现更好的模型外推性能:
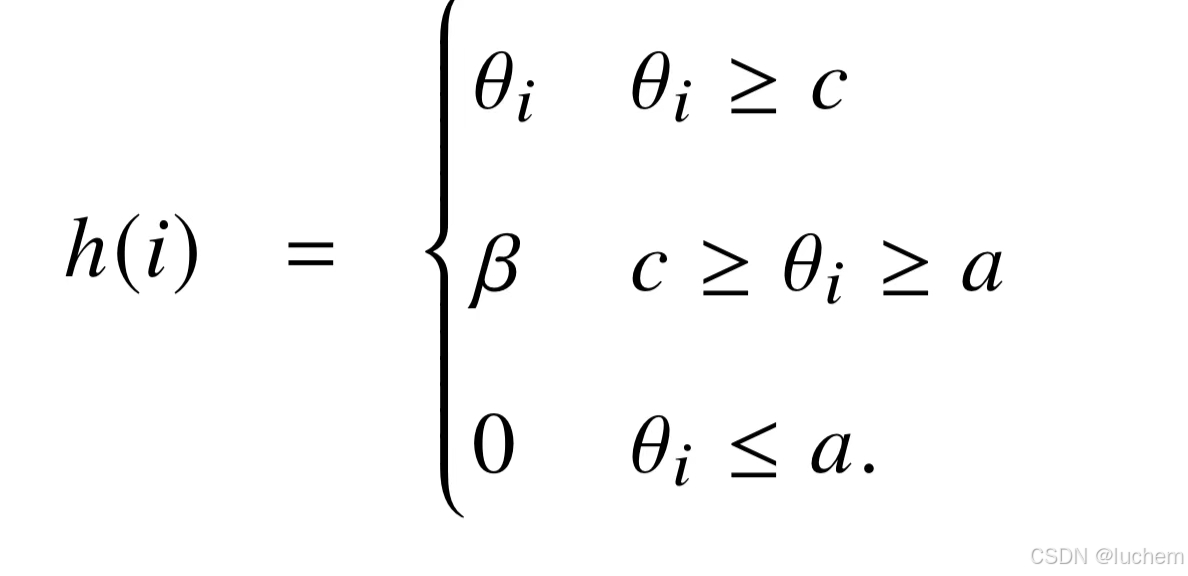
-
5.4.2调整上下文窗口
-
为了解决Transformer 架构对于上下文窗口的限制,除了使用扩展位置编码来拓宽上下文窗口外,另一种行之有效的策略是采用受限的注意力机制来调整原始的上下文窗口,从而实现对更长文本的有效建模。
- 并行上下文窗口:并行上下文窗口方法采用了一种分而治之的策略来处理输入文本。具体来说,该方法将输入文本划分为若干个片段,每个片段都进行独立的编码处理,并共享相同的位置编码信息。在生成阶段,通过调整注意力掩码,使得后续生成的词元能够访问到前序的所有词元。
- Λ 形上下文窗口:在处理长文本时,大语言模型有时会表现出一种不均匀关注的现象:它们倾向于对序列起始位置以及邻近的词元赋予更高的注意力权重。基于这一观察,StreamingLLM等工作引入了“Λ 形” 注意力掩码方法,能够有选择性地关注每个查询的邻近词元以及序列起始的词元,同时忽略超出这一范围的其他词元。在给定的有限内存资源下,这种方法能够生成几乎无限长的流畅文本。
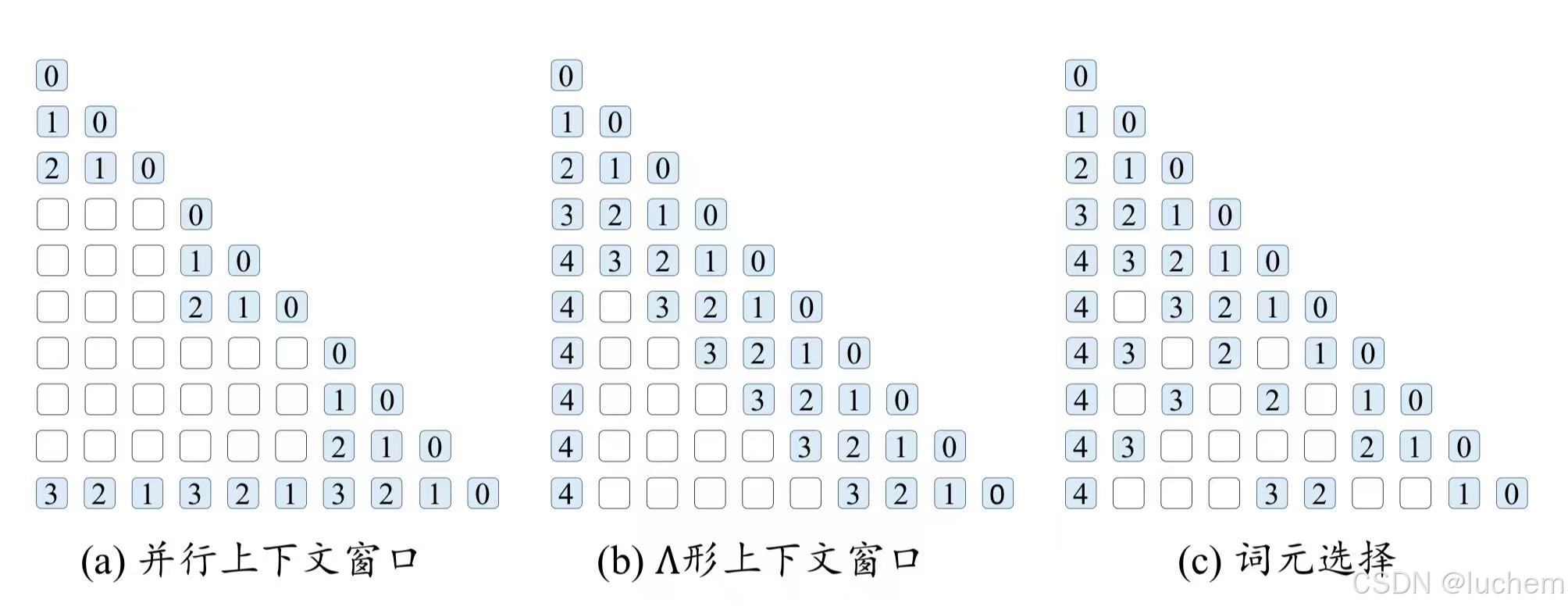
- 词元选择:在Transformer 的注意力模块中,对于每个词元的预测,并非所有先前词元都提供等量的贡献。实际上,小部分紧密相关词元的注意力分数总和就能够接近所有词元的注意力分数总和。基于这样的一个实践观察,相关研究工作提出了词元选择方法,旨在挑选出最重要的k个词元,以实现对于完整注意力的有效拟合。词元选择方法可以通过查询与词元相似度和查询与词元所在分块的相似度实现。
- (1)查询与词元相似度:根据位置索引和上下文窗口,词元被划分为窗口内的近距离词元和窗口外的远距离词元。对于窗口外的远距离词元,通常利用外部存储保存它们的键值对,并采用k 近邻搜索方法来获取当前生成所需的Tmax 个最相关词元。
- (2)查询与分块相似度:分块级别的词元选择将序列划分为不同的长度固定的分块,并从分块序列中选择出最相关的部分分块。具体来说,模型首先将每个分块中所有的隐状态压缩为一个键向量表示,然后利用k近邻方法选出与查询最相关的k 个分块,并保证这些块中的总词元数目至多为Tmax。这些分块中所有的词元将按照它们在整个输入序列中的出现的顺序进行排序,并按照排序后的位置赋予位置编码。随后,这些词元被送入注意力模块中处理。
-
5.4.3长文本数据
-
为了有效拓展模型的长文本建模能力,通常需要使用特殊准备的数据对于模型进行继续预训练。
- 长文本数据量:标准的预训练任务通常需要使用大量的文本数据。而对于面向长文本建模的继续预训练来说,可以采用少量长文本数据进行轻量化的继续预训练。这一方法需要模型在初始预训练阶段已经学会了利用远程词元信息的能力,仅需使模型适应更长的上下文窗口。
- 长文本数据混合:除了数据总量外,训练数据集中不同数据的混合也是影响模型性能的关键因素,主要包括长文本的领域分布和长文本的类型。为了提升模型的泛化能力,长文本数据的领域应尽可能多样化,并且与预训练数据集的分布保持相似。除了数据的领域分布外,数据本身的语义特性也是数据混合需要考虑的问题。在LongWanjuan 中,研究人员基于连贯性、衔接性和复杂性将长文本数据分为整体型(完整的有意义的长文)、聚合型(多篇相关文本的聚合)和杂乱型(杂乱无章的文本)。
5.5新型模型架构
-
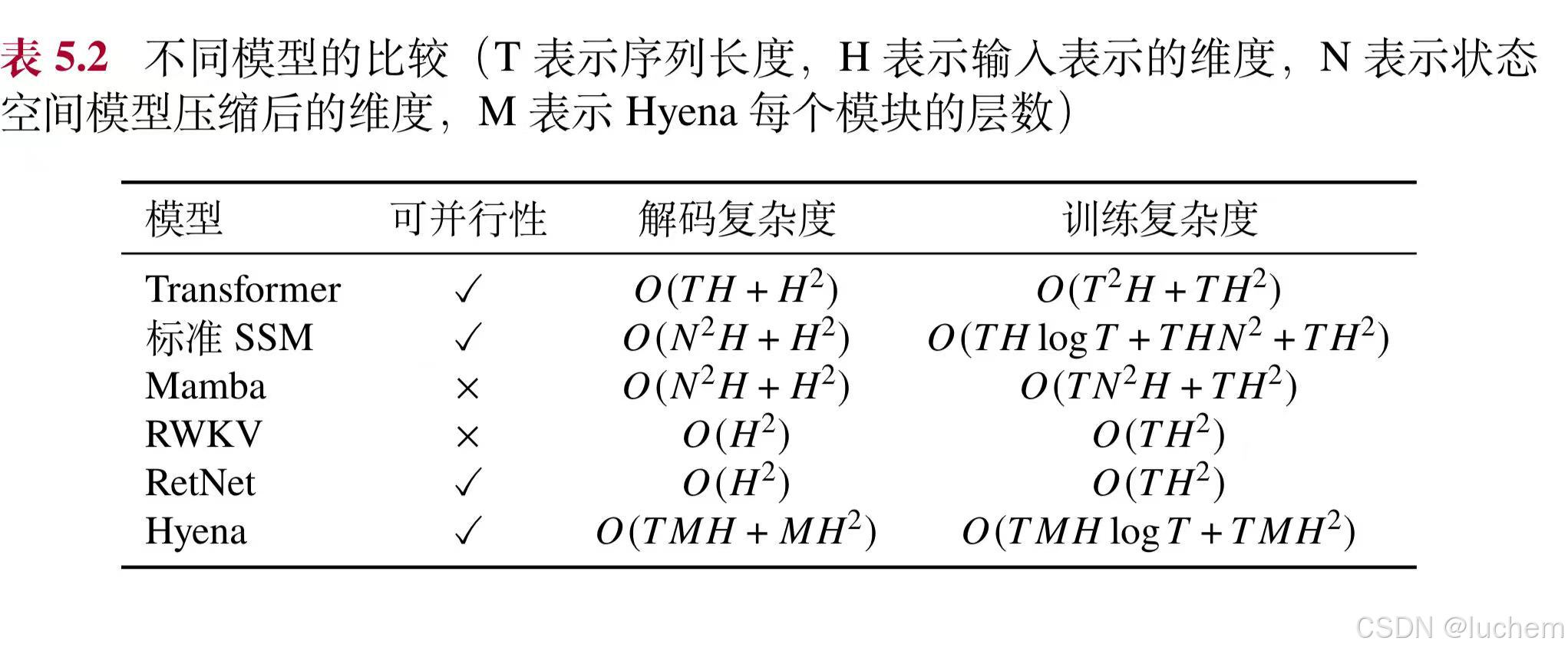
Transformer 的自注意力机制在计算每个词元时都需要利用到序列中所有词元的信息,这导致计算和存储复杂度随输入序列长度的平方级别增长。在处理长序列时,这种复杂性会消耗大量的计算资源与存储空间。研究人员致力于新型模型架构的设计。这些新型模型大多基于参数化状态空间模型(State Space Model, SSM)进行设计,在长文本建模效率方面相比Transformer 有了大幅改进,同时也保持了较好的序列建模能力。
-
-
5.5.1参数化状态空间模型
-
通俗来说,参数化状态空间模型可以看作是循环神经网络和卷积神经网络的“结合体”。一方面,该模型可以利用卷积计算对输入进行并行化编码。另一方面,该模型在计算中不需要访问前序的所有词元,仅仅利用前一个词元就可以自回归地进行预测。因此,该模型在解码时展现出了更高的计算效率。
-
为了同时实现并行化计算和循环解码,状态空间模型在输入和输出之间引入了额外的状态变量。在循环计算中,状态空间模型首先循环地利用当前时刻的输入xt 和前一个时刻的状态St−1 对当前时刻的状态St 进行计算。然后,该模型将当前时刻的状态St进一步映射为输出yt:
-
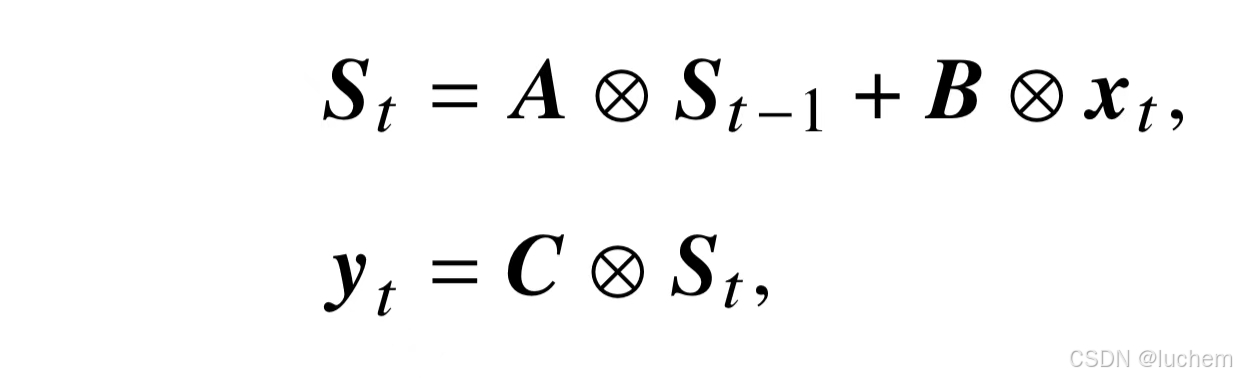
-
其中,A ∈RH×N×N、B ∈RH×N×1 和R ∈RH×1×N 是可学习参数,而⊗表示批量矩阵乘法。针对上述公式,当前时刻的输出可以通过循环的方式进行分解,进而表示为如下的数学形式:
-
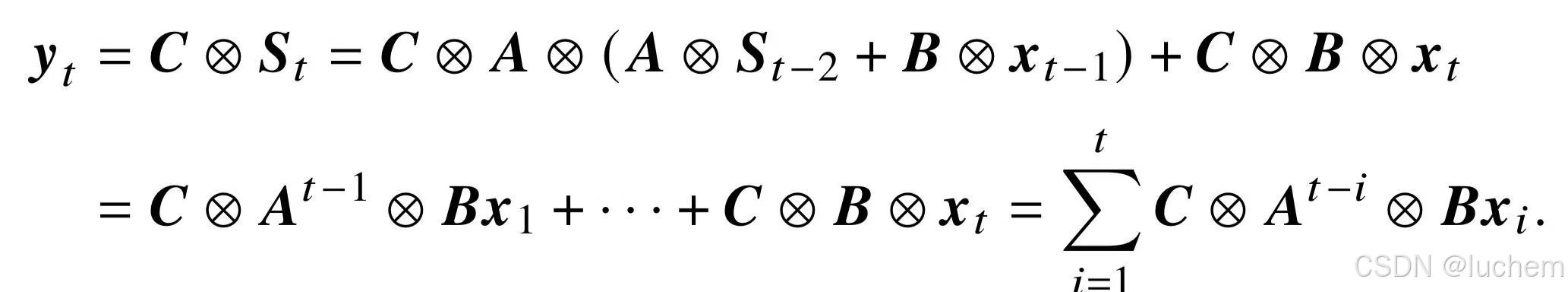
-
根据卷积计算的定义,对输出yt的计算可以看作是对输入的卷积,其中卷积核为K。这一计算可以表示为:
-
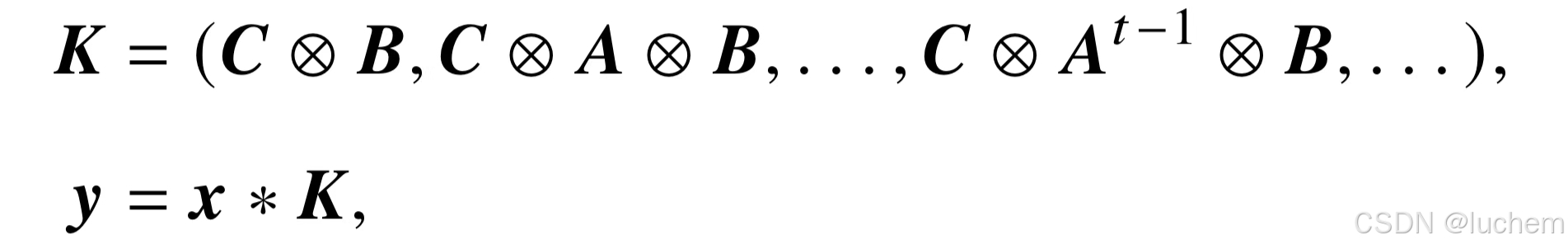
-
其中,“∗”表示卷积计算。在使用卷积计算时,状态空间模型可以利用快速傅里叶变换加速计算效率,从而通过O(THlog T+THN^2 +TH^2)的复杂度建模整个序列。在循环计算的时候,状态空间模型不需要和Transformer 一样对前面所有时刻的状态进行访问,而是仅仅需要前一个时刻的状态。
-
5.5.2状态空间模型变种
-
尽管状态空间模型计算效率较高,但是在文本任务上的表现相比Transformer模型仍有一定的差距。为此,一系列研究工作对于状态空间模型进行了性能改进,在保证计算效率的同时提高其语言建模的能力。代表性模型包括Mamba、RWKV(Receptance Weighted Key Value)、RetNet(Retentive Network)和Hyena等。
- Mamba:Mamba是一种状态空间模型的变种,主要思想是在状态空间模型的状态更新中引入了基于当前输入的信息选择(Selection)机制,来确定当前时刻状态如何从前一时刻状态以及当前输入中提取信息,从而提升其在语言建模上的性能。标准的状态空间模型在每次更新状态St 的时候,都对输入xt 和前一个时刻的状态St−1 使用相同的线性映射参数。相比于标准状态空间模型,Mamba 展现出了更好的文本建模性能,但是由于引入了关于xt 的非线性关系,Mamba 无法利用快速傅里叶变换实现高效卷积计算。
- RWKV:RWKV 尝试将RNN 和Transformer 的优点进行结合,继承了Transformer 的建模优势和RNN 的计算效率。作为一个主要技术创新,RWKV 在每层的计算中使用词元偏移(Token Shift)来代替词元表示。在每一步的状态计算中,它显示地引入了上一个词元xt−1,通过两个相邻的词元xt 和xt−1进行线性插值来代替xt作为后续模块的输入。进一步,RWKV 将Transformer 中的多头注意力模块和前馈网络模块分别替换为时间混合(Time-mixing)模块和频道混合(Channel-mixing)模块。
- RetNet:RetNet提出使用多尺度保留(Multi-scale Retention, MSR)机制来代替多头注意力模块,从而提升计算效率。多尺度保留机制是在标准状态空间模型的基础上,在状态更新的线性映射中引入了输入相关信息来提升序列建模能力。每个保留模块中,输入词元被映射为查询向量qt、键向量kt和值向量vt ,并通过kt⊺vt 和前一个时刻的状态St−1 进行线性相加,得到当前的状态:St = ASt−1 +kt⊺vt。最后,RetNet 使用查询qt将当前状态St映射为输出ot = qtSt。
- Hyena:Hyena提出使用长卷积模块(Long Convolution)来替换Trans-former 架构中的注意力模块,从而借助卷积的快速傅里叶变换来提高计算效率。Hyena 在每层的长卷积模块中包含了M 个滤波器,即每个相对位置t有一个相应的滤波器h(t),然后将这些滤波器组合成卷积核K= (h(1),...,h(T))。利用该卷积核与输入序列[x1,...,xt]进行卷积,可以对序列中不同位置的信息进行聚合,得到每个位置的中间表示zt。最后,再使用门控函数g(t)(基于输入xt )对中间表示zt 进行加权,得到该模块的最终输出。

















 3367
3367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









