




01 引子
生成式人工智能(Generative AI)包含文字,影像,声音三个方面,其中,文字由 Token 组成、影像由 Pixel(像素)组成,声音由 Sample(取样点)组成。因此,生成式人工智能的核心问题是,如何给一段输出,让其利用基本单位组合成一段输出。
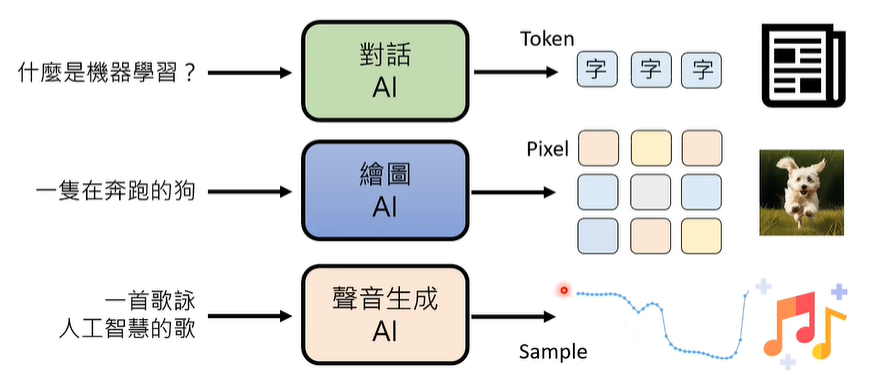
02 Autoregressive Generation (AR)
① 文字接龙
② 图像“接龙”

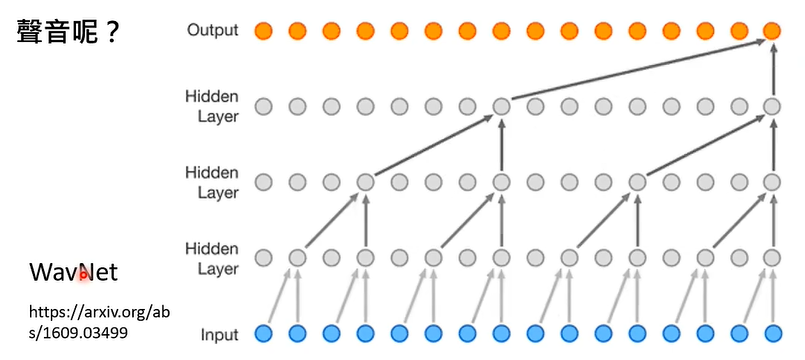
③ 声音“接龙”
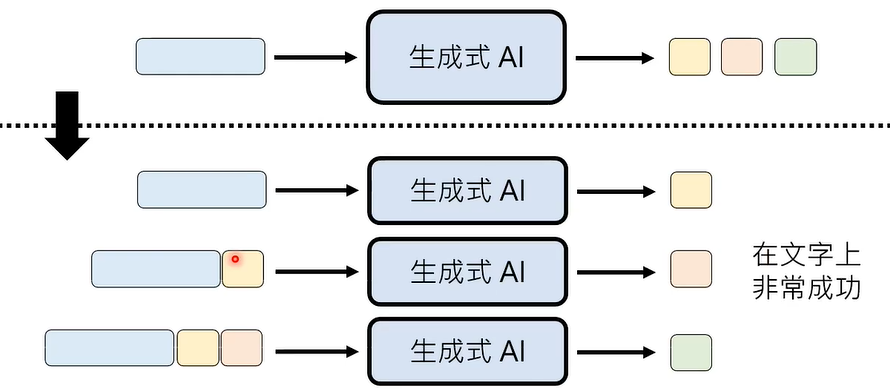
接龙有一个本质的陷阱,即我们需要按部就班的,按照某种特定的顺序,生成越来越长的输出。假设我们要生成一张 1024 * 1024 解析度的图片,需要大约 100 万次接龙!
那么,如何解决这一问题呢,我们可以让模型一次性输出多个位置的答案!
03 Non-autoregressive Generation (NAR)
Au
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 745
745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









