



 Flume是一个高可用、高可靠、分布式的海量日志采集系统,用于数据收集、聚合和传输。本文介绍了如何配置和启动Flume,包括网络监听和文件监听的设置,以及如何验证其工作状态。
Flume是一个高可用、高可靠、分布式的海量日志采集系统,用于数据收集、聚合和传输。本文介绍了如何配置和启动Flume,包括网络监听和文件监听的设置,以及如何验证其工作状态。
flume
(日志收集系统)
编辑
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Flume版本:
apache-flume-1.8.0-bin.tar.gz
把解压包放在HADOOP 的opt/下
解压 apache_flume-1.8.0-bin.tar.gz:
tar -zxvf apache-flume-1.8.0-bin.tar.gz
然后进入到opt下 放flume文件中的conf目录下,创建一个a1.conf文件
进去之后定义:sinks,channels,sources
#定义agent的source channel sinksa1.sources = sr1
a1.channels = ch1
a1.sinks = log1
#设置source的参数
a1.sources.sr1.type = netcat #对网络监听
a1.sources.sr1.bind = python5 #主机名
a1.sources.sr1.port = 44444
#设置sink参数
a1.sinks.log1.type = logger
#设置channel的参数
a1.channels.ch1.type = memory
#把source和sink 通过channel连接在一起
a1.sources.sr1.channels = ch1
a1.sinks.log1.channel = ch1
然后启动agent,复制这段代码: ./bin/flume-ng agent -c conf -f conf/a1.conf -n a1-Dflume.root.logger=INFO,console然后回车

然后新建一个新的选项卡 ,输入telnet python5 44444
就可以随便输入进行网络监听,如果时间过长会自动断开
接下来文件监听:
1.在hadoop下创建一个目录,我的目录叫zhangsong:

2.在conf 里打开a1.conf
修改成以下:
会发现我们只修改了 sources
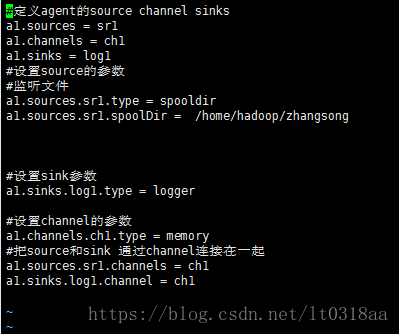
3.回到flume目录下然后启动agent还是执行刚才的代码:

4复制一个ssh通道,拷贝一个文件到 zhangsong目录下

5监听文件成功:

去zhangsong目录下会发现 t8这个文件:
监听目录:
监听目录和以上不一样,需要我们在conf里新建一个文件 a2.conf
1 复制a1.conf里的代码过去,然后修改sink:
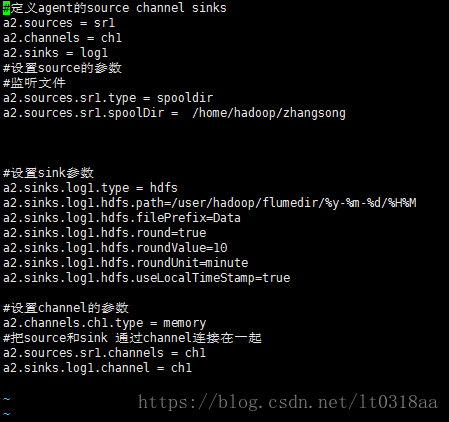
2重新启动agent,启动的时候注意名字 我们现在叫a2.conf
3拷贝一个文件到zhangsong目录下,打开python/50070,去user/hadoop/会发现多了一个flumedir的目录

















 289
289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









