




 本文介绍了如何在Spark中进行数据统计和排序操作。通过在XShell中上传文件`wagzhe`,将数据转换为RDD模式进行处理。首先,统计了每个区的总收入,接着进一步统计每个玩家在每个区的花费。最后,展示了如何按照玩家和区的花费进行排序,详细解释了排序的逻辑和步骤。
本文介绍了如何在Spark中进行数据统计和排序操作。通过在XShell中上传文件`wagzhe`,将数据转换为RDD模式进行处理。首先,统计了每个区的总收入,接着进一步统计每个玩家在每个区的花费。最后,展示了如何按照玩家和区的花费进行排序,详细解释了排序的逻辑和步骤。
在xshell里面创建一个文件,并且上传
(a,b,c,d)代表的是玩家,(r1,r2,r3)代表的是区,数字代表花的钱数

上传文件,(文件的名字叫wagzhe)

打开文件,转成RDD模式,然后输出一下看看是否正确

输出结果:

统计一下每个区转了多少钱(每个人花了多少钱和这个例子一样就是把玩家作为键 把钱数作为值)
先用map(lambda x:x.split(","))给它拆分开,拆分后的样式就是[(a,r1,87),(a,r2,50)......],x[1]是区(键),x[2]是钱数(是值)
用redecuByKey()统计一下结果就出来了
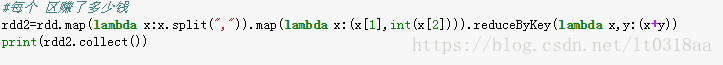
输出结果:
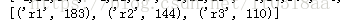
统计一下
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 249
249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









